

MetroCluster IP構成での単一サイトの電源オフと電源オン
 変更を提案
変更を提案
MetroCluster IP構成でサイトのメンテナンスを実施したり、単一サイトを再配置したりする必要がある場合は、サイトの電源をオフにしてオンにする方法を把握しておく必要があります。
サイトを再配置して再設定する必要がある場合(4ノードクラスタから8ノードクラスタに拡張する必要がある場合など)は、これらのタスクを同時に実行することはできません。この手順では、サイトのメンテナンスを実行するため、またはサイトの構成を変更せずにサイトを再配置するために必要な手順のみを説明します。
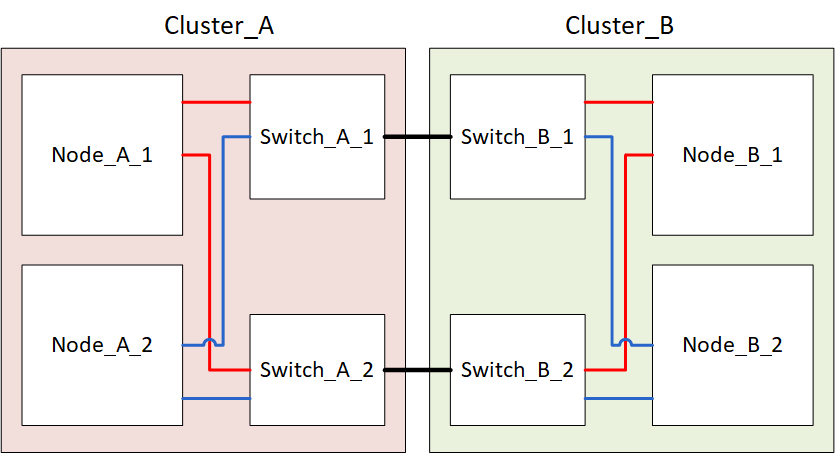
次の図は、 MetroCluster 構成を示しています。メンテナンスのためにcluster_Bの電源がオフになっています。
MetroClusterサイトの電源をオフにする
サイトのメンテナンスや再配置を開始する前に、サイトとすべての機器の電源をオフにする必要があります。
次の手順のすべてのコマンドは、電源をオンにしたままのサイトから実行されます。
-
開始する前に、ミラーされていないアグリゲートがサイトですべてオフラインになっていることを確認します。
-
ONTAP で MetroCluster 構成の動作を確認します。
-
システムがマルチパスかどうかを確認します。
'node run -node _node-name_sysconfig -a
-
ヘルスアラートがないかどうかを両方のクラスタで確認します。
「 system health alert show 」というメッセージが表示されます
-
MetroCluster 構成と運用モードが正常な状態であることを確認します。
「 MetroCluster show 」
-
MetroCluster チェックを実行します + MetroCluster チェックを実行します
-
MetroCluster チェックの結果を表示します。
MetroCluster チェックショー
-
スイッチにヘルスアラートがないかどうかを確認します(ある場合)。
「 storage switch show 」と表示されます
-
Config Advisor を実行します。
-
Config Advisor の実行後、ツールの出力を確認し、推奨される方法で検出された問題に対処します。
-
-
稼働したままにするサイトから、スイッチオーバーを実施します。
MetroCluster スイッチオーバー
cluster_A::*> metrocluster switchover
この処理が完了するまでに数分かかることがあります。
-
スイッチオーバーの完了を監視して確認します。
「 MetroCluster operation show 」を参照してください
cluster_A::*> metrocluster operation show Operation: Switchover Start time: 10/4/2012 19:04:13 State: in-progress End time: - Errors: cluster_A::*> metrocluster operation show Operation: Switchover Start time: 10/4/2012 19:04:13 State: successful End time: 10/4/2012 19:04:22 Errors: - -
ONTAP 9.6 以降を実行している MetroCluster IP 構成がある場合は、ディザスタサイトのプレックスがオンラインになり、修復処理が自動的に完了するまで待ちます。
ONTAP 9.5以前を実行しているMetroCluster IP構成では、ディザスタサイトのノードはONTAPで自動的にブートせず、プレックスはオフラインのままです。
-
ミラーされていないアグリゲートに属するボリュームとLUNをすべてオフラインにします。
-
ボリュームをオフラインにします。
cluster_A::* volume offline <volume name>
-
LUNをオフラインにします。
cluster_A::* lun offline lun_path <lun_path>
-
-
ミラーされていないアグリゲートをオフラインにします:「storage aggregate offline
cluster_A*::> storage aggregate offline -aggregate <aggregate-name>
-
構成と ONTAP のバージョンに応じて、ディザスタサイト( cluster_B )にあるオフラインの影響を受けるプレックスを特定して移動します。
次のプレックスをオフラインにする必要があります。
-
ディザスタサイトにあるディスクにあるミラーリングされていないプレックス
ディザスタサイトのミラーされていないプレックスをオフラインにしないと、あとでディザスタサイトの電源をオフにしたときにシステムが停止する可能性があります。
-
ディザスタサイトのディスクにあるミラーされたプレックスを使用してアグリゲートをミラーリングする。オフラインにすると、プレックスにアクセスできなくなります。
-
影響を受けるプレックスを特定します。
サバイバーサイトのノードが所有するプレックスは、プール 1 のディスクで構成されます。ディザスタサイトのノードが所有するプレックスは、プール 0 のディスクで構成されます。
Cluster_A::> storage aggregate plex show -fields aggregate,status,is-online,Plex,pool aggregate plex status is-online pool ------------ ----- ------------- --------- ---- Node_B_1_aggr0 plex0 normal,active true 0 Node_B_1_aggr0 plex1 normal,active true 1 Node_B_2_aggr0 plex0 normal,active true 0 Node_B_2_aggr0 plex5 normal,active true 1 Node_B_1_aggr1 plex0 normal,active true 0 Node_B_1_aggr1 plex3 normal,active true 1 Node_B_2_aggr1 plex0 normal,active true 0 Node_B_2_aggr1 plex1 normal,active true 1 Node_A_1_aggr0 plex0 normal,active true 0 Node_A_1_aggr0 plex4 normal,active true 1 Node_A_1_aggr1 plex0 normal,active true 0 Node_A_1_aggr1 plex1 normal,active true 1 Node_A_2_aggr0 plex0 normal,active true 0 Node_A_2_aggr0 plex4 normal,active true 1 Node_A_2_aggr1 plex0 normal,active true 0 Node_A_2_aggr1 plex1 normal,active true 1 14 entries were displayed. Cluster_A::>
影響を受けるプレックスは、クラスタ A のリモートにあるプレックスです次の表に、ディスクがクラスタ A に対してローカルかリモートかを示します。
ノード
プール内のディスク
ディスクをオフラインにする必要があるか
オフラインにするプレックスの例を指定します
Node_a_1 および Node_a_2
プール 0 内のディスク
いいえディスクはクラスタ A に対してローカルです
-
プール 1 内のディスク
はい。ディスクはクラスタ A に対してリモートです
node_A_1 の aggr0 / プレックス 4 を使用します
node_A_1 の aggr1 / plex1
node_a_2_aggr0/plex4
Node_a_2_aggr1 / plex1 です
Node_B_1 および Node_B_2
プール 0 内のディスク
はい。ディスクはクラスタ A に対してリモートです
node_B_1 の aggr1 / plex0
node_B_1 の aggr0/plex0
node_B_2 の aggr0 / plex0
node_B_2 の aggr1 / plex0
プール 1 内のディスク
-
影響を受けるプレックスをオフラインにします。
「ストレージアグリゲートのプレックスはオフライン」です
storage aggregate plex offline -aggregate Node_B_1_aggr0 -plex plex0
+

この手順は、Cluster_Aに対してリモートのディスクを含むすべてのプレックスに対して実行します。 -
-
スイッチタイプに応じて、ISLスイッチポートを永続的にオフラインにします。
-
各ノードで次のコマンドを実行して、ノードを停止します。
node halt -inhibit-takeover true -skip-lif-migration true -node <node-name> -
ディザスタサイトの機器の電源をオフにします。
次の機器の電源を、記載されている順序でオフにする必要があります。
-
ストレージコントローラ-ストレージコントローラは現在、
LOADERプロンプトが表示されたら、電源を完全にオフにする必要があります。 -
MetroCluster IP スイッチ
-
ストレージシェルフ
-
電源がオフになっている MetroCluster サイトの再配置
サイトの電源をオフにしたら、メンテナンス作業を開始できます。手順は、 MetroCluster コンポーネントを同じデータセンター内で再配置する場合も、別のデータセンターに再配置する場合も同じです。
-
ハードウェアは、前のサイトと同じ方法でケーブル接続する必要があります。
-
スイッチ間リンク( ISL )の速度、長さ、または数が変わった場合は、すべて再設定する必要があります。
-
新しい場所で正しく再接続できるように、すべてのコンポーネントのケーブル配線が慎重に記録されていることを確認します。
-
すべてのハードウェア、ストレージ コントローラ、IP スイッチ、およびストレージ シェルフを物理的に再配置します。
-
ISL ポートを設定し、サイト間接続を確認します。
-
IPスイッチの電源をオンにします。
他の機器の電源はオンにしないでください。
-
-
スイッチのツールを使用して(使用可能な場合)、サイト間接続を確認します。
リンクが正しく設定され、安定している場合にのみ続行してください。 -
リンクが安定していることがわかった場合は、リンクを再度無効にします。
MetroCluster 構成の電源をオンにして通常動作に戻します
メンテナンスを完了、またはサイトを移動したら、サイトの電源をオンにして MetroCluster 構成を再確立する必要があります。
次の手順のすべてのコマンドは、電源をオンにしたサイトから実行します。
-
スイッチの電源をオンにします。
最初にスイッチの電源をオンにする必要があります。サイトを再配置した場合は、前の手順で電源がオンになっている可能性があります。
-
必要に応じて、または再配置中に実行されていない場合は、スイッチ間リンク( ISL )を再設定します。
-
フェンシングが完了した場合、 ISL を有効にします。
-
ISL を確認します。
-
-
ストレージコントローラの電源をオンにし、
LOADERプロンプト。コントローラが完全にブートしないようにする必要があります。自動起動が有効になっている場合は、
Ctrl+Cコントローラの自動ブートを停止します。
コントローラの電源を入れる前にシェルフの電源を入れないでください。これにより、コントローラが意図しないONTAPでブートされるのを防ぐことができます。 -
シェルフの電源をオンにし、電源が完全にオンになるまで十分な時間を確保します。
-
メンテナンス モードからストレージが表示可能であることを確認します。
-
メンテナンス モードで起動します。
「 boot_ontap maint 」を使用してください
-
残存サイトからストレージが見えることを確認します。
-
メンテナンス モードのノードからローカル ストレージとリモート ストレージが表示されていることを確認します:
「ディスクショー V 」
-
-
ノードを停止します。
「 halt 」
-
MetroCluster 構成を再確立します。
の手順に従います "スイッチバックに向けたシステムの事前チェック" MetroCluster 構成に応じて修復処理とスイッチバック処理を実行します。