

 MetroClusterリリースノート
MetroClusterリリースノート
ストレージシェルフを撤去する際の、 MetroCluster FC から MetroCluster IP への停止を伴う移行( ONTAP 9.8 以降)
 変更を提案
変更を提案
ONTAP 9.8 以降では、 2 ノードの MetroCluster FC 構成を 4 ノードの MetroCluster IP 構成に無停止で移行し、既存のストレージシェルフを撤去できます。手順には、既存のドライブシェルフから新しい構成にデータを移動し、古いシェルフを撤去する手順が含まれています。
-
この手順は、既存のストレージシェルフを撤去し、 MetroCluster IP 構成内の新しいシェルフにすべてのデータを移動する場合に使用します。
-
既存のストレージシェルフモデルが新しい MetroCluster IP ノードでサポートされている必要があります。
-
この手順は、 ONTAP 9.8 以降を実行しているシステムでサポートされています。
-
この手順はシステムの停止を伴います。
-
この手順は、 2 ノード MetroCluster FC 構成にのみ適用されます。
4 ノード MetroCluster FC 構成の場合は、を参照してください "移行する手順を選択します"。
-
すべての要件を満たし、手順のすべての手順に従う必要があります。
古いシェルフを撤去する場合の移行要件
移行プロセスを開始する前に、既存の MetroCluster FC 構成が要件を満たしていることを確認する必要があります。
-
2 ノードのファブリック接続またはストレッチ MetroCluster 構成で、すべてのノードで ONTAP 9.8 以降が実行されている必要があります。
新しい MetroCluster IP コントローラモジュールは、同じバージョンの ONTAP 9.8 を実行している必要があります。
-
既存のプラットフォームと新しいプラットフォームの組み合わせは、移行対象としてサポートされている必要があります。
-
MetroCluster インストールおよび設定ガイド _ に記載されているすべての要件とケーブル接続を満たしている必要があります。
新しい構成は、次の要件も満たす必要があります。
-
新しい MetroCluster IP プラットフォームモデルで古いストレージシェルフモデルがサポートされている必要があります。
-
既存のシェルフで使用可能なスペアディスクに応じて、ドライブを追加する必要があります。
必要なドライブシェルフがほかにもあります。
各コントローラに 14~18 本のドライブを追加する必要があります。
-
プール 0 ドライブ × 3
-
プール 1 ドライブ × 3
-
2 本のスペアドライブ
-
システムボリューム用に 6 ~ 10 台のドライブ
-
-
新しいノードを含む構成が、ドライブ数、ルートアグリゲートのサイズ容量など、構成のプラットフォーム制限を超えないようにする必要があります
この情報は、各プラットフォームモデルので確認できます "NetApp Hardware Universe の略"
MetroCluster サイトから 6 つのすべてのノードのリモートコンソールアクセスが必要です。または、手順で必要に応じてサイト間の移動を計画しておく必要があります。
データを移動する場合や古いストレージシェルフを撤去する場合の、停止を伴う移行ワークフロー
移行を成功させるには、特定のワークフローに従う必要があります。
移行を準備する際は、サイト間の移動を計画します。リモートノードがラックに設置されてケーブル接続されたら、ノードへのシリアルターミナルアクセスが必要です。ノードが設定されるまでサービスプロセッサへのアクセスは許可されません。
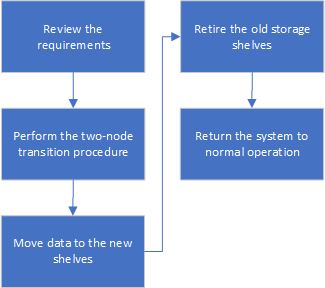
構成を移行しています
詳細な移行手順に従う必要があります。
次の手順では、他の手順に進みます。参照されている各手順で、指定された順序で手順を実行する必要があります。
-
の手順に従って、ポートマッピングを計画します "MetroCluster FC ノードから MetroCluster IP ノードへのポートのマッピング"。
-
の手順に従って、 MetroCluster IP コントローラを準備します "MetroCluster IP コントローラの準備"。
-
MetroCluster FC 構成の健常性を確認
の手順を実行します "MetroCluster FC 構成の健全性の確認"。
-
MetroCluster FC 構成から情報を収集
の手順を実行します "移行前に既存のコントローラモジュールから情報を収集"。
-
必要に応じて Tiebreaker による監視を削除
の手順を実行します "Tiebreaker またはその他の監視ソフトウェアから既存の設定を削除します"。
-
既存の MetroCluster FC ノードを準備して削除
の手順を実行します "MetroCluster FC ノードを移行します"。
-
新しい MetroCluster IP ノードを接続します。
の手順を実行します "MetroCluster IP コントローラモジュールを接続します"。
-
新しい MetroCluster IP ノードを設定し、移行を完了します。
の手順を実行します "新しいノードの設定と移行の完了"。
ルートアグリゲートを移行します
移行が完了したら、残りの既存のルートアグリゲートを MetroCluster FC 構成から MetroCluster IP 構成の新しいシェルフに移行します。
このタスクでは、 node_A_1 の FC および node_B_1 のルートアグリゲートを、新しい MetroCluster IP コントローラが所有するディスクシェルフに移動します。
-
新しいローカルストレージシェルフのプール 0 のディスクを、移動するルートのあるコントローラに割り当てます(例: node_A_1 のルートを移行する場合は、新しいシェルフのプール 0 のディスクを node_A_1 の IP に割り当てます)。
migrate_Removes はルート・ミラー _ を再作成しないため 'migrate コマンドを実行する前にプール 1 のディスクを割り当てる必要はありません
-
権限モードを advanced に設定します。
'set priv advanced'
-
ルートアグリゲートを移行します。
system node migrate-root -node node_name -disklist disk-id1 、 disk-id2 、 diskn -raid-type raid-type `
-
node-name は、ルートアグリゲートの移行先のノードです。
-
disk-id は、新しいシェルフのプール 0 ディスクを識別します。
-
通常、 RAID タイプは既存のルートアグリゲートの RAID タイプと同じです。
-
移行ステータスを確認するには、コマンド「 job show -idjob-id-instance 」を使用します。ここで、 job-id は、 migrate-root コマンドの実行時に指定された値です。
たとえば、 node_A_1 の FC のルートアグリゲートの構成が、 RAID-DP を使用して 3 本のディスクで構成されていた場合は、次のコマンドを使用して、ルートを新しいシェルフ 11 に移行します。
system node migrate-root -node node_A_1-IP -disklist 3.11.0,3.11.1,3.11.2 -raid-type raid_dp
-
-
移行処理が完了してノードが自動的にリブートするまで待ちます。
-
リモートクラスタに直接接続した新しいシェルフのルートアグリゲートのプール 1 のディスクを割り当てます。
-
移行されたルートアグリゲートをミラーリングします。
-
ルートアグリゲートの再同期が完了するまで待ちます。
storage aggregate show コマンドを使用して、アグリゲートの同期ステータスを確認できます。
-
もう一方のルートアグリゲートに対して同じ手順を繰り返します。
データアグリゲートを移行する
新しいシェルフにデータアグリゲートを作成し、ボリューム移動を使用して、古いシェルフから新しいシェルフ上のアグリゲートにデータボリュームを転送します。
-
新しいコントローラ上のアグリゲートに、一度に 1 つのボリュームずつデータボリュームを移動します。
撤去するシェルフは node_A_1 から FC 、 node_A_1 から FC を移行
元の MetroCluster FC 構成から古いストレージシェルフを撤去します。これらのシェルフの所有者は、もともと node_A_1 の FC と node_A_1 の FC です。
-
削除が必要な cluster_B の古いシェルフ上のアグリゲートを特定します。
この例では、 MetroCluster FC cluster_B によってホストされている次のデータアグリゲートを削除する必要があります。 aggr_data_A1 と aggr_data_A2 。

シェルフ上のデータアグリゲートを特定、オフライン、および削除するには、次の手順を実行する必要があります。この例は、 1 つのクラスタだけを対象としています。 cluster_B::> aggr show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ aggr0_node_A_1-FC 349.0GB 16.83GB 95% online 1 node_A_1-IP raid_dp, mirrored, normal aggr0_node_A_2-IP 349.0GB 16.83GB 95% online 1 node_A_2-IP raid_dp, mirrored, normal ... 8 entries were displayed. cluster_B::> -
データアグリゲートに MDV_AUD ボリュームが含まれているかどうかを確認し、アグリゲートを削除する前にそれらを削除してください。
MDV_AUD ボリュームは移動できないため、削除する必要があります。
-
各アグリゲートをオフラインにしてから削除します。
-
アグリゲートをオフラインにします。
「 storage aggregate offline-aggregate aggregate-name 」の形式で指定します
次の例は、アグリゲート node_B_1 をオフラインにします。
cluster_B::> storage aggregate offline -aggregate node_B_1_aggr0 Aggregate offline successful on aggregate: node_B_1_aggr0
-
アグリゲートを削除します。
「 storage aggregate delete -aggregate aggregate-name 」の形式で指定します
プロンプトが表示されたら、プレックスを破棄できます。
次の例は、削除するアグリゲート node_B_1 の aggr0 を示しています。
cluster_B::> storage aggregate delete -aggregate node_B_1_aggr0 Warning: Are you sure you want to destroy aggregate "node_B_1_aggr0"? {y|n}: y [Job 123] Job succeeded: DONE cluster_B::> -
-
すべてのアグリゲートを削除したら、電源をオフにし、シェルフを切断して取り外します。
-
上記の手順を繰り返して、 cluster_A シェルフを撤去します。
移行を完了しています
古いコントローラモジュールを取り外した状態で、移行プロセスを完了できます。
-
移行プロセスを完了します。
の手順を実行します "システムを通常動作に戻します"。