

スイッチオーバーとスイッチバックを使用して、 MetroCluster FC 構成のコントローラをアップグレードします
 変更を提案
変更を提案
MetroCluster スイッチオーバー処理を使用すると、パートナークラスタのコントローラモジュールのアップグレード中もクライアントに無停止でサービスを提供できます。この手順の一部として他のコンポーネント(ストレージシェルフやスイッチなど)をアップグレードすることはできません。
サポートされるプラットフォームの組み合わせ
MetroCluster FC構成では、スイッチオーバーとスイッチバックの処理を使用して特定のプラットフォームをアップグレードできます。
サポートされるプラットフォームのアップグレードの組み合わせについては、のMetroCluster FCアップグレードの表を参照してください "コントローラのアップグレード手順 を選択します"。
を参照してください "アップグレードまたは更新方法を選択します" を参照してください。
このタスクについて
-
この手順は、コントローラのアップグレードにのみ使用できます。
ストレージシェルフやスイッチなど、構成内の他のコンポーネントは同時にアップグレードできません。
-
この手順 は、特定のバージョンのONTAP で使用できます。
-
ONTAP 9.3 以降では 2 ノード構成がサポートされます。
-
ONTAP 9.8以降では、4ノード構成と8ノード構成がサポートされます。
ONTAP 9.8 より前のバージョンを実行している 4 ノードまたは 8 ノード構成では、この手順を使用しないでください。
-
-
元のプラットフォームと新しいプラットフォームに互換性があり、サポートされている必要があります。

元のプラットフォームまたは新しいプラットフォームがFAS8020またはAFF8020システムでは、FC-VIモードのポート1cと1dを使用する場合は、ナレッジベースの記事を参照してください "既存のFAS8020またはAFF8020ノードでFCVI接続にポート1cと1dを使用する場合は、コントローラをアップグレードします。" -
両方のサイトでライセンスが一致している必要があります。から新しいライセンスを取得できます "ネットアップサポート"。
-
この 手順 環境 コントローラモジュールは、MetroCluster FC構成(2ノードのストレッチMetroCluster 構成または2ノード、4ノード、または8ノードのファブリック接続MetroCluster 構成)で使用します。
-
同じDRグループ内のすべてのコントローラは、同じメンテナンス期間にアップグレードする必要があります。
同じDRグループに種類の異なるコントローラを含むMetroCluster 構成の運用は、このメンテナンス作業以外ではサポートされません。8ノードMetroCluster 構成では、DRグループ内のコントローラは同じである必要がありますが、両方のDRグループで異なる種類のコントローラを使用できます。
-
元のノードと新しいノードの間のストレージ、 FC 、イーサネット接続をあらかじめマッピングしておくことを推奨します。
-
新しいプラットフォームのスロット数が元のシステムのスロット数より少ない場合、またはポートのタイプが異なる場合は、新しいシステムにアダプタを追加しなければならないことがあります。
詳細については、を参照してください "NetApp Hardware Universe の略"
この手順では、次の名前が使用されています。
-
site_A
-
アップグレード前:
-
node_A_1 - 古い
-
Node_a_2-old
-
-
アップグレード後:
-
node_A_1 - 新規
-
Node_a_2 - 新規
-
-
-
site_B
-
アップグレード前:
-
node_B_1 - 古い
-
node_B_2 - 古い
-
-
アップグレード後:
-
node_B_1 - 新規
-
node_B_2 - 新規
-
-
コンソールログを有効にする
NetAppでは、使用しているデバイスでコンソールロギングをイネーブルにし、この手順を実行する際に次のアクションを実行することを強く推奨します。
-
メンテナンス中はAutoSupportを有効のままにします。
-
メンテナンスの前後にメンテナンスAutoSupportメッセージをトリガーして、メンテナンスアクティビティ中にケースの作成を無効にします。
ナレッジベースの記事を参照してください "スケジュールされたメンテナンス時間中にケースの自動作成を停止する方法"。
-
任意のCLIセッションのセッションロギングをイネーブルにします。セッションログを有効にする方法については、ナレッジベースの記事の「セッション出力のログ」セクションを参照してください "ONTAPシステムへの接続を最適化するためのPuTTYの設定方法"。
アップグレードを準備
既存の MetroCluster 構成に変更を加える前に、構成の健全性を確認し、新しいプラットフォームを準備し、その他のタスクを実行する必要があります。
MetroCluster 構成の健全性を確認
アップグレードを実行する前に、MetroCluster 構成の健全性と接続性を確認します。

|
最初のサイトでコントローラをアップグレードした後、2番目のサイトをアップグレードする前に、 `metrocluster check run`に続く `metrocluster check show`エラーを返します `config-replication`フィールド。このエラーは、各サイトのノード間でNVRAMのサイズが一致していないことを示しています。これは、両サイトで異なるプラットフォームモデルが存在する場合に想定される動作です。DRグループ内のすべてのノードでコントローラーのアップグレードが完了するまで、このエラーは無視できます。 |
-
ONTAP で MetroCluster 構成の動作を確認します。
-
ノードがマルチパスであるかどうかを確認します。 +
node run -node node_name sysconfig -aこのコマンドは、 MetroCluster 構成のノードごとに問題で実行する必要があります。
-
構成に破損ディスクがないことを確認します。
「 storage disk show -broken 」
このコマンドは、 MetroCluster 構成の各ノードで問題を実行する必要があります。
-
ヘルスアラートがないかどうかを確認します。
「 system health alert show 」というメッセージが表示されます
このコマンドは、各クラスタで問題を実行する必要があります。
-
クラスタのライセンスを確認します。
「 system license show 」を参照してください
このコマンドは、各クラスタで問題を実行する必要があります。
-
ノードに接続されているデバイスを確認します。
「 network device-discovery show 」のように表示されます
このコマンドは、各クラスタで問題を実行する必要があります。
-
両方のサイトでタイムゾーンと時間が正しく設定されていることを確認します。
cluster date show
このコマンドは、各クラスタで問題を実行する必要があります。時刻とタイムゾーンを設定するには 'cluster date コマンドを使用します
-
-
スイッチにヘルスアラートがないかどうかを確認します(ある場合)。
「 storage switch show 」と表示されます
このコマンドは、各クラスタで問題を実行する必要があります。
-
MetroCluster 構成の運用モードを確認し、 MetroCluster チェックを実行
-
MetroCluster 構成と運用モードが正常な状態であることを確認します。
「 MetroCluster show 」
-
想定されるすべてのノードが表示されることを確認します。
MetroCluster node show
-
次のコマンドを問題に設定します。
「 MetroCluster check run 」のようになります
-
MetroCluster チェックの結果を表示します。
MetroCluster チェックショー
-
-
Config Advisor ツールを使用して MetroCluster のケーブル接続を確認します。
-
Config Advisor をダウンロードして実行します。
-
Config Advisor の実行後、ツールの出力を確認し、推奨される方法で検出された問題に対処します。
-
古いノードから新しいノードへのポートのマッピング
古いノードの物理ポートと新しいノードの物理ポートのマッピングを計画する必要があります。
アップグレードプロセスで最初に新しいノードがブートされると、交換前の古いノードの最新の設定が再生されます。node_A_1 を新規にブートすると、 ONTAP は node_A_1 の古いポートで使用されていた LIF をホストしようとします。そのため、アップグレードの一環として、ポートと LIF の設定を古いノードと互換性があるように調整する必要があります。アップグレード手順では、クラスタ LIF 、管理 LIF 、およびデータ LIF の構成が正しくなるように、古いノードと新しいノードの両方で手順を実行します。
次の表に、新しいノードのポート要件に関連する設定変更の例を示します。
クラスタインターコネクトの物理ポート |
||
古いコントローラ |
新しいコントローラ |
必要なアクション |
e0a 、 e0b |
e3a 、 e3b |
一致するポートがありません。アップグレード後に、クラスタポートを再作成します。"既存のコントローラモジュールのクラスタポートを準備" |
e0c 、 e0d |
e0a 、 e0b 、 e0c 、 e0d |
e0c と e0d は同じポートです。構成を変更する必要はありませんが、アップグレード後は、使用可能なクラスタポートにクラスタ LIF を分散させることができます。 |
-
新しいコントローラで使用できる物理ポートとポートでホストできる LIF を確認します。
コントローラのポートの用途は、プラットフォームモジュールおよび MetroCluster IP 構成で使用するスイッチによって異なります。新しいプラットフォームのポート使用量をから収集できます "NetApp Hardware Universe の略"。
また、 FC-VI カードスロットの用途も示します。
-
ポートの使用状況を計画し、必要に応じて次の表に新しいノードそれぞれを記載します。
この表は、アップグレード手順を実行するときに参照します。
node_A_1 - 古い
node_A_1 - 新規
LIF
ポート
IPspace
ブロードキャストドメイン
ポート
IPspace
ブロードキャストドメイン
クラスタ 1
クラスタ 2
クラスタ 3
クラスタ 4
ノード管理
クラスタ管理
データ 1
データ 2.
データ 3
データ 4.
SAN
クラスタ間ポート
アップグレード前に情報を収集
アップグレードの前に、古い各ノードの情報を収集し、必要に応じてネットワークブロードキャストドメインを調整し、VLANとインターフェイスグループを削除し、暗号化情報を収集する必要があります。
このタスクは、既存の MetroCluster FC 構成で実行します。
-
新しいコントローラをセットアップするときにケーブルを簡単に識別できるように、既存のコントローラのケーブルにラベルを付けます。
-
MetroCluster 構成内のノードのシステム ID を収集します。
MetroCluster node show -fields node-systemid 、 dr-partner-systemid'
手順のアップグレード時に、これらの古いシステムIDを新しいコントローラモジュールのシステムIDに置き換えます。
この 4 ノード MetroCluster FC 構成の例では、次の古いシステム ID が取得されます。
-
node_A_1 - 古い: 4068741258
-
node_A_2 - 古い: 4068741260
-
node_B_1 - 古い: 4068741254
-
node_B_2 - 古い: 4068741256
metrocluster-siteA::> metrocluster node show -fields node-systemid,ha-partner-systemid,dr-partner-systemid,dr-auxiliary-systemid dr-group-id cluster node node-systemid ha-partner-systemid dr-partner-systemid dr-auxiliary-systemid ----------- ------------------------- ------------------ ------------- ------------------- ------------------- --------------------- 1 Cluster_A Node_A_1-old 4068741258 4068741260 4068741256 4068741256 1 Cluster_A Node_A_2-old 4068741260 4068741258 4068741254 4068741254 1 Cluster_B Node_B_1-old 4068741254 4068741256 4068741258 4068741260 1 Cluster_B Node_B_2-old 4068741256 4068741254 4068741260 4068741258 4 entries were displayed.
この 2 ノード MetroCluster FC 構成の例では、次の古いシステム ID が取得されます。
-
node_A_1 : 4068741258
-
node_B_1 : 4068741254
metrocluster node show -fields node-systemid,dr-partner-systemid dr-group-id cluster node node-systemid dr-partner-systemid ----------- ---------- -------- ------------- ------------ 1 Cluster_A Node_A_1-old 4068741258 4068741254 1 Cluster_B node_B_1-old - - 2 entries were displayed.
-
-
古い各ノードのポートとLIFの情報を収集します。
ノードごとに次のコマンドの出力を収集する必要があります。
-
'network interface show -role cluster, node-mgmt
-
'network port show -node node_name -type physical ’
-
'network port vlan show -node -node-name _`
-
「 network port ifgrp show -node node_name 」 - instance 」を指定します
-
「 network port broadcast-domain show 」
-
「 network port reachability show-detail` 」と表示されます
-
network ipspace show
-
volume show
-
「 storage aggregate show
-
「 system node run -node _node-name_sysconfig -a 」のように入力します
-
-
MetroCluster ノードが SAN 構成になっている場合は、関連情報を収集します。
次のコマンドの出力を収集する必要があります。
-
「 fcp adapter show -instance 」のように表示されます
-
「 fcp interface show -instance 」の略
-
「 iscsi interface show 」と表示されます
-
ucadmin show
-
-
ルートボリュームが暗号化されている場合は、 key-manager に使用するパスフレーズを収集して保存します。
「 securitykey-manager backup show 」を参照してください
-
MetroCluster ノードがボリュームまたはアグリゲートに暗号化を使用している場合は、キーとパスフレーズに関する情報をコピーします。
追加情報の場合は、を参照してください "オンボードキー管理情報の手動でのバックアップ"。
-
オンボードキーマネージャが設定されている場合:
「 securitykey manager onboard show-backup 」を参照してください
パスフレーズは、あとでアップグレード手順で必要になります。
-
Enterprise Key Management ( KMIP )が設定されている場合は、次のコマンドを問題で実行します。
「 securitykey-manager external show -instance 」
「セキュリティキーマネージャのキークエリ」
-
Tiebreaker またはその他の監視ソフトウェアから既存の設定を削除します
スイッチオーバーを開始できる MetroCluster Tiebreaker 構成や他社製アプリケーション( ClusterLion など)で既存の構成を監視している場合は、移行の前に Tiebreaker またはその他のソフトウェアから MetroCluster 構成を削除する必要があります。
-
Tiebreaker ソフトウェアから既存の MetroCluster 設定を削除します。
-
スイッチオーバーを開始できるサードパーティ製アプリケーションから既存の MetroCluster 構成を削除します。
アプリケーションのマニュアルを参照してください。
カスタム AutoSupport メッセージをメンテナンス前に送信する
メンテナンスを実行する前に、 AutoSupport an 問題 message to notify NetApp technical support that maintenance is maintenancing (メンテナンスが進行中であることをネットアップテクニカルサポートに通知する)を実行システム停止が発生したとみなしてテクニカルサポートがケースをオープンしないように、メンテナンスが進行中であることを通知する必要があります。
このタスクは MetroCluster サイトごとに実行する必要があります。
-
サポートケースが自動で生成されないようにするには、メンテナンスが進行中であることを示す AutoSupport メッセージを送信します。
-
次のコマンドを問題に設定します。
「 system node AutoSupport invoke -node * -type all -message MAINT= maintenance-window-in-hours 」というメッセージが表示されます
「メンテナンス時間」では、メンテナンス時間の長さを最大 72 時間指定します。この時間が経過する前にメンテナンスが完了した場合は、メンテナンス期間が終了したことを通知する AutoSupport メッセージを起動できます。
「 system node AutoSupport invoke -node * -type all -message MAINT= end 」というメッセージが表示されます
-
パートナークラスタに対してこのコマンドを繰り返します。
-
MetroCluster 構成をスイッチオーバーします
site_B のプラットフォームをアップグレードできるように、設定を site_A にスイッチオーバーする必要があります。
このタスクは site_A で実行する必要があります
このタスクを完了すると、 cluster_A はアクティブになり、両方のサイトでデータを提供します。cluster_B は非アクティブで、次の図に示すようにアップグレードプロセスを開始できます。
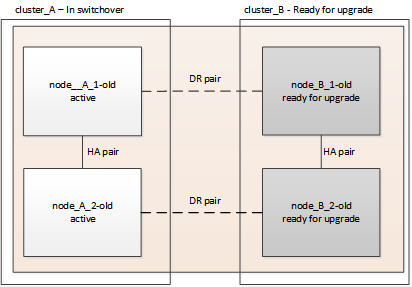
-
site_B のノードをアップグレードできるように、 MetroCluster 構成を site_A にスイッチオーバーします。
-
構成に一致するオプションを選択し、cluster_Aの正しいコマンドを問題 します。
オプション1:ONTAP 9.8以降を実行する4ノードまたは8ノードのFC構成次のコマンドを実行します。
metrocluster switchover -controller-replacement trueオプション2:ONTAP 9.3以降を実行する2ノードFC構成次のコマンドを実行します。
metrocluster switchoverこの処理が完了するまでに数分かかることがあります。
-
スイッチオーバー処理を監視します。
「 MetroCluster operation show 」を参照してください
-
処理が完了したら、ノードがスイッチオーバー状態であることを確認します。
「 MetroCluster show 」
-
MetroCluster ノードのステータスを確認します。
MetroCluster node show
-
-
データアグリゲートを修復します。
-
データアグリゲートを修復します。
MetroCluster は ' データ・アグリゲートを修復します
-
正常なクラスタで MetroCluster operation show コマンドを実行して、修復操作が完了したことを確認します。
cluster_A::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/29/2020 20:54:41 End Time: 7/29/2020 20:54:42 Errors: -
-
-
ルートアグリゲートを修復します。
-
データアグリゲートを修復します。
MetroCluster はルートアグリゲートを修復します
-
正常なクラスタで MetroCluster operation show コマンドを実行して、修復操作が完了したことを確認します。
cluster_A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2020 20:58:41 End Time: 7/29/2020 20:59:42 Errors: -
-
古いコントローラのネットワーク構成を準備
新しいコントローラでネットワークが正常に再開されるようにするには、 LIF を共通ポートに移動して、古いコントローラのネットワーク設定を削除する必要があります。
-
このタスクは、古いノードごとに実行する必要があります。
-
で収集した情報を使用します "古いノードから新しいノードへのポートのマッピング"。
-
古いノードをブートし、ノードにログインします。
「 boot_ontap 」
-
古いコントローラのすべてのデータ LIF のホームポートを、新旧両方のコントローラモジュールで同じ共通ポートに割り当てます。
-
LIF を表示します。
「 network interface show 」を参照してください
SAN と NAS を含むすべてのデータ LIF は、スイッチオーバーサイト( cluster_A )で稼働しているため、管理上および運用上のダウン状態になります。
-
の出力を確認して、クラスタポートとして使用されていない新旧両方のコントローラで同じ共通の物理ネットワークポートを特定します。
たとえば、 e0d は古いコントローラの物理ポートで、新しいコントローラにも存在します。e0d は、クラスタポート、または新しいコントローラ上で使用されません。
プラットフォームモデルのポートの用途については、を参照してください "NetApp Hardware Universe の略"
-
すべてのデータ LIF で共通ポートをホームポートとして使用するように変更します。
「 network interface modify -vserver svm -name _ -lif data -lif lif _ -home-port_port -id 」と入力します
次の例では、これは「 e0d 」です。
例:
network interface modify -vserver vs0 -lif datalif1 -home-port e0d
-
-
ブロードキャストドメインを変更して、削除する必要がある VLAN と物理ポートを削除します。
「 broadcast-domain remove-ports -broadcast-domain_domain-name-name_ports_node-name : port-id_` 」
すべての VLAN ポートと物理ポートについて、この手順を繰り返します。
-
クラスタポートをメンバーポートとして使用し、 ifgrp をメンバーポートとして使用している VLAN ポートを削除します。
-
VLAN ポートを削除します。
「 network port vlan delete -node-node-name-vlan-name_portid -vlandid_ 」のように指定します
例:
network port vlan delete -node node1 -vlan-name e1c-80
-
インターフェイスグループから物理ポートを削除します。
「 network port ifgrp remove-port -node-node_name -ifgrp_interface-group-name _ port_portid 」の形式で指定します
例:
network port ifgrp remove-port -node node1 -ifgrp a1a -port e0d
-
ブロードキャストドメインから VLAN ポートとインターフェイスグループポートを削除します。
'network port broadcast-domain remove-ports -ipspace_ipspace -broadcast-domain_domain-name_ports_nodename : portname 、 nodename : portname _ 、
-
必要に応じて、他の物理ポートをメンバーとして使用するようにインターフェイスグループポートを変更します。
ifgrp add-port -node node_name -ifgrp interface -group-name_port_port-id`
-
-
ノードを停止します。
halt -inhibit-takeover true -node node_name `
この手順は両方のノードで実行する必要があります。
古いプラットフォームを削除する
古いコントローラを構成から削除しておく必要があります。
このタスクは site_B で実行します
-
site_B の古いコントローラのシリアルコンソール( node_B_1 古いコントローラと node_B_2 古いコントローラ)に接続し、 LOADER プロンプトが表示されていることを確認します。
-
node_B_1 古いと node_B_2 のストレージ接続とネットワーク接続を切断し、新しいノードに再接続できるようにケーブルにラベルを付けます。
-
node_B_1 から古いおよび node_B_2 から電源ケーブルを外します。
-
node_B_1 古いコントローラと node_B_2 の古いコントローラをラックから取り外します。
新しいコントローラを設定します
コントローラをラックに設置して設置し、メンテナンスモードで必要なセットアップを実行してから、コントローラをブートし、コントローラの LIF の設定を確認する必要があります。
新しいコントローラをセットアップ
新しいコントローラをラックに設置してケーブルを接続する必要があります。
-
必要に応じて、新しいコントローラモジュールとストレージシェルフの配置を計画します。
ラックスペースは、コントローラモジュールのプラットフォームモデル、スイッチのタイプ、構成内のストレージシェルフ数によって異なります。
-
自身の適切な接地対策を行います
-
コントローラモジュールをラックまたはキャビネットに設置します。
-
新しいコントローラモジュールに固有の FC-VI カードがない場合、および古いコントローラの FC-VI カードに新しいコントローラの互換性がある場合は、 FC-VI カードを交換し、正しいスロットに取り付けます。
を参照してください "NetApp Hardware Universe の略" を参照してください。
-
コントローラの電源、シリアルコンソール、および管理接続を、 MetroCluster インストールおよび設定ガイド _ の説明に従ってケーブル接続します。
この時点で古いコントローラから切断されていた他のケーブルは接続しないでください。
-
新しいノードに電源を投入し、 LOADER プロンプトを表示するよう求められたら Ctrl+C キーを押します。
新しいコントローラをネットブート
新しいノードを設置したら、ネットブートを実行して、新しいノードが元のノードと同じバージョンの ONTAP を実行するようにする必要があります。ネットブートという用語は、リモート・サーバに保存された ONTAP イメージからブートすることを意味します。ネットブートの準備を行うときは、システムがアクセスできる Web サーバに、 ONTAP 9 ブート・イメージのコピーを配置する必要があります。
このタスクは、新しい各コントローラモジュールで実行します。
-
にアクセスします "ネットアップサポートサイト" システムのネットブートの実行に使用するファイルをダウンロードするには、次の手順を実行します。
-
ネットアップサポートサイトのソフトウェアダウンロードセクションから該当する ONTAP ソフトウェアをダウンロードし、 Web にアクセスできるディレクトリに image.tgz ファイルを保存します。
-
Web にアクセスできるディレクトリに移動し、必要なファイルが利用可能であることを確認します。
プラットフォームモデル
作業
FAS/AFF8000 シリーズシステム
ターゲットディレクトリに version_image.tgzfile の内容を展開します。 tar -zxvf ONTAP-version _image.tgz 注: Windows で内容を展開する場合は、 7-Zip または WinRAR を使用してネットブートイメージを展開します。ディレクトリの一覧に、カーネルファイル netboot/ kernel を含むネットブートフォルダが表示される必要があります
その他すべてのシステム
ディレクトリの一覧に、カーネルファイルがあるネットブートフォルダを含める必要があります。 ONTAP-version _image.tgz ファイルを展開する必要はありません。
-
LOADER プロンプトで、管理 LIF のネットブート接続を設定します。
-
IP アドレスが DHCP の場合は、自動接続を設定します。
ifconfig e0M -auto
-
IP アドレスが静的な場合は、手動接続を設定します。
ifconfig e0M -addr= ip_addr-mask= netmask `-gw= gateway `
-
-
ネットブートを実行します。
-
プラットフォームが 80xx シリーズシステムの場合は、次のコマンドを使用します。
netboot\http://web_server_ip/path_to_web-accessible_directory/netboot/kernel`
-
プラットフォームが他のシステムの場合は、次のコマンドを使用します。
netboot\http://web_server_ip/path_to_web-accessible_directory/ontap-version_image.tgz`
-
-
ブートメニューからオプション * ( 7 ) Install new software first * を選択し、新しいソフトウェアイメージをダウンロードしてブートデバイスにインストールします。
Disregard the following message: "This procedure is not supported for Non-Disruptive Upgrade on an HA pair". It applies to nondisruptive upgrades of software, not to upgrades of controllers. . 手順を続行するかどうかを確認するメッセージが表示されたら、「 y 」と入力し、パッケージの入力を求められたらイメージファイルの URL 「 ¥ http://web_server_ip/path_to_web-accessible_directory/ontap-version_image.tgz` 」を入力します
Enter username/password if applicable, or press Enter to continue.
-
入力
n次のようなプロンプトが表示されたら、バックアップの回復をスキップします。Do you want to restore the backup configuration now? {y|n} n -
次のようなプロンプトが表示されたら 'y' と入力して再起動します
The node must be rebooted to start using the newly installed software. Do you want to reboot now? {y|n} y
新しくインストールされたソフトウェアを使用するには、ノードを再起動する必要があります。
コントローラモジュールの設定をクリアします
MetroCluster 構成で新しいコントローラモジュールを使用する前に、既存の構成をクリアする必要があります。
-
必要に応じて、ノードを停止してプロンプトを表示し `LOADER`ます。
「 halt 」
-
`LOADER`プロンプトで、環境変数をデフォルト値に設定します。
「デフォルト設定」
-
環境を保存します。
'aveenv
-
`LOADER`プロンプトでブートメニューを起動します。
「 boot_ontap menu
-
ブートメニューのプロンプトで、設定を消去します。
wipeconfig
確認プロンプトに「 yes 」と応答します。
ノードがリブートし、もう一度ブートメニューが表示されます。
-
ブートメニューでオプション * 5 * を選択し、システムをメンテナンスモードでブートします。
確認プロンプトに「 yes 」と応答します。
HBA 構成をリストア
コントローラモジュールに HBA カードが搭載されているかどうかや設定によっては、サイトで使用するために正しく設定する必要があります。
-
メンテナンスモードで、システム内の HBA の設定を行います。
-
ucadmin show と入力し、各ポートの現在の設定を確認します
-
必要に応じてポートの設定を更新します。
HBA のタイプと目的のモード
使用するコマンド
CNA FC
ucadmin modify -m fc -t initiator_adapter-name _ `
CNA イーサネット
ucadmin modify -mode cna_adapter-name_`
FC ターゲット
fcadmin config -t target_adapter-name_`
FC イニシエータ
fcadmin config -t initiator_adapter-name_`
-
-
メンテナンスモードを終了します。
「 halt 」
コマンドの実行後、ノードが LOADER プロンプトで停止するまで待ちます。
-
ノードをブートしてメンテナンスモードに戻り、設定の変更が反映されるようにします。
「 boot_ontap maint 」を使用してください
-
変更内容を確認します。
HBA のタイプ
使用するコマンド
CNA
ucadmin show
FC
fcadmin show`
新しいコントローラとシャーシで HA 状態を設定
コントローラとシャーシの HA 状態を確認し、必要に応じてシステム構成に合わせて更新する必要があります。
-
メンテナンスモードで、コントローラモジュールとシャーシの HA 状態を表示します。
「 ha-config show 」
すべてのコンポーネントの HA の状態が mcc である必要があります。
MetroCluster 構成の内容
HA の状態
2 ノード
mcc-2n
4 ノードまたは 8 ノード
MCC
-
表示されたコントローラのシステム状態が正しくない場合は、コントローラモジュールとシャーシの HA 状態を設定します。
MetroCluster 構成の内容
問題コマンド
-
2 ノード *
「 ha-config modify controller mcc-2n 」という形式で指定します
「 ha-config modify chassis mcc-2n 」というようになりました
-
4 ノードまたは 8 ノード *
「 ha-config modify controller mcc 」
「 ha-config modify chassis mcc 」
-
ルートアグリゲートディスクを再割り当てします
前の手順で確認したシステム ID を使用して、ルートアグリゲートディスクを新しいコントローラモジュールに再割り当てします
このタスクはメンテナンスモードで実行します。
古いシステムIDはで特定しました "アップグレード前に情報を収集"。
この手順の例では、次のシステム ID を持つコントローラを使用します。
ノード |
古いシステム ID |
新しいシステム ID |
node_B_1 |
4068741254 |
1574774970 |
-
他のすべての接続を新しいコントローラモジュール( FC-VI 、ストレージ、クラスタインターコネクトなど)にケーブル接続します。
-
システムを停止し、 LOADER プロンプトからメンテナンスモードでブートします。
「 boot_ontap maint 」を使用してください
-
node_B_1 古いが所有するディスクを表示します。
「ディスクショー - A` 」
コマンド出力に、新しいコントローラモジュール( 1574774970 )のシステム ID が表示されます。ただし、ルートアグリゲートディスクは古いシステム ID ( 4068741254 )で所有されます。この例で表示されているのは、 MetroCluster 構成の他のノードが所有するドライブではありません。
*> disk show -a Local System ID: 1574774970 DISK OWNER POOL SERIAL NUMBER HOME DR HOME ------------ ------------- ----- ------------- ------------- ------------- ... rr18:9.126L44 node_B_1-old(4068741254) Pool1 PZHYN0MD node_B_1-old(4068741254) node_B_1-old(4068741254) rr18:9.126L49 node_B_1-old(4068741254) Pool1 PPG3J5HA node_B_1-old(4068741254) node_B_1-old(4068741254) rr18:8.126L21 node_B_1-old(4068741254) Pool1 PZHTDSZD node_B_1-old(4068741254) node_B_1-old(4068741254) rr18:8.126L2 node_B_1-old(4068741254) Pool0 S0M1J2CF node_B_1-old(4068741254) node_B_1-old(4068741254) rr18:8.126L3 node_B_1-old(4068741254) Pool0 S0M0CQM5 node_B_1-old(4068741254) node_B_1-old(4068741254) rr18:9.126L27 node_B_1-old(4068741254) Pool0 S0M1PSDW node_B_1-old(4068741254) node_B_1-old(4068741254) ...
-
ドライブシェルフのルートアグリゲートディスクを新しいコントローラに再割り当てします。
「ディスクの再割り当て -s old-sysid-d_new-sysid_`
次の例は、ドライブの再割り当てを示しています。
*> disk reassign -s 4068741254 -d 1574774970 Partner node must not be in Takeover mode during disk reassignment from maintenance mode. Serious problems could result!! Do not proceed with reassignment if the partner is in takeover mode. Abort reassignment (y/n)? n After the node becomes operational, you must perform a takeover and giveback of the HA partner node to ensure disk reassignment is successful. Do you want to continue (y/n)? Jul 14 19:23:49 [localhost:config.bridge.extra.port:error]: Both FC ports of FC-to-SAS bridge rtp-fc02-41-rr18:9.126L0 S/N [FB7500N107692] are attached to this controller. y Disk ownership will be updated on all disks previously belonging to Filer with sysid 4068741254. Do you want to continue (y/n)? y
-
すべてのディスクが想定どおりに再割り当てされていることを確認します。
「ディスクショー」
*> disk show Local System ID: 1574774970 DISK OWNER POOL SERIAL NUMBER HOME DR HOME ------------ ------------- ----- ------------- ------------- ------------- rr18:8.126L18 node_B_1-new(1574774970) Pool1 PZHYN0MD node_B_1-new(1574774970) node_B_1-new(1574774970) rr18:9.126L49 node_B_1-new(1574774970) Pool1 PPG3J5HA node_B_1-new(1574774970) node_B_1-new(1574774970) rr18:8.126L21 node_B_1-new(1574774970) Pool1 PZHTDSZD node_B_1-new(1574774970) node_B_1-new(1574774970) rr18:8.126L2 node_B_1-new(1574774970) Pool0 S0M1J2CF node_B_1-new(1574774970) node_B_1-new(1574774970) rr18:9.126L29 node_B_1-new(1574774970) Pool0 S0M0CQM5 node_B_1-new(1574774970) node_B_1-new(1574774970) rr18:8.126L1 node_B_1-new(1574774970) Pool0 S0M1PSDW node_B_1-new(1574774970) node_B_1-new(1574774970) *>
-
アグリゲートのステータスを表示します。
「 aggr status 」を入力します
*> aggr status Aggr State Status Options aggr0_node_b_1-root online raid_dp, aggr root, nosnap=on, mirrored mirror_resync_priority=high(fixed) fast zeroed 64-bit -
パートナーノードで上記の手順を繰り返します( node_B_2 - 新規)。
新しいコントローラをブートします
コントローラのフラッシュイメージを更新するには、ブートメニューからコントローラをリブートする必要があります。暗号化が設定されている場合は、追加の手順が必要です。
このタスクはすべての新しいコントローラで実行する必要があります。
-
ノードを停止します。
「 halt 」
-
外部キー管理ツールが設定されている場合は、関連する bootargs を設定します。
'setenv bootarg.kmip.init.ipaddr ip-address'
'setenv bootarg.kmip.init.netmask netmask`
'setenv bootarg.kmip.init.gateway gateway-address
'setenv bootarg.kmip.init.interface interface-id
-
ブートメニューを表示します。
「 boot_ontap menu
-
ルート暗号化を使用する場合は、使用している ONTAP のバージョンに応じて、キー管理設定のブートメニューオプションまたは問題 the boot menu コマンドを選択します。
ONTAP 9.8以降ONTAP 9.8 以降では、ブート・メニュー・オプションを選択します。
使用するポート
選択するブートメニューオプション
オンボードキー管理
オプション "10 `"
プロンプトに従って、キー管理ツールの構成をリカバリおよびリストアするために必要な入力を指定します。
外部キー管理
オプション "11`"
プロンプトに従って、キー管理ツールの構成をリカバリおよびリストアするために必要な入力を指定します。
ONTAP 9.7以前ONTAP 9.7以前の場合は、ブートメニューコマンドを問題します。
使用するポート
問題ブートメニュープロンプトでのコマンド
オンボードキー管理
「 recover _onboard keymanager 」を参照してください
外部キー管理
「 RE_EXTERNAL_KEYmanager 」と入力します
-
AUTOBOOT が有効になっている場合は、 CTRL-C を押して AUTOBOOT を中断します
-
ブートメニューからオプション "6`" を実行します
オプション "6`" を選択すると ' 完了前にノードが 2 回再起動されます システム ID 変更プロンプトに「 y 」と入力します。2 回目のリブートメッセージが表示されるまで待ちます。
Successfully restored env file from boot media... Rebooting to load the restored env file...
-
partner-sysid が正しいことを確認します。
printenv partner-sysid
partner-sysid が正しくない場合は、次のように設定します。
'setenv partner-sysid_partner-SysID_`
-
ルート暗号問題化を使用する場合は、使用している ONTAP のバージョンに応じて、キー管理設定に対してブートメニューオプションを選択するか、ブートメニューコマンドを再度実行します。
ONTAP 9.8以降ONTAP 9.8 以降では、ブート・メニュー・オプションを選択します。
使用するポート
選択するブートメニューオプション
オンボードキー管理
オプション "10 `"
プロンプトに従って、キー管理ツールの構成をリカバリおよびリストアするために必要な入力を指定します。
外部キー管理
オプション "11`"
プロンプトに従って、キー管理ツールの構成をリカバリおよびリストアするために必要な入力を指定します。
キー・マネージャの設定に応じて '10 またはオプション 11 を選択し ' 最初のブート・メニュー・プロンプトでオプション 6 を選択して 'recovery 手順を実行しますノードを完全にブートするには ' オプション "1" によって続行されるリカバリ手順 ( 通常のブート ) を繰り返す必要がある場合があります
ONTAP 9.7以前ONTAP 9.7以前の場合は、ブートメニューコマンドを問題します。
使用するポート
問題ブートメニュープロンプトでのコマンド
オンボードキー管理
「 recover _onboard keymanager 」を参照してください
外部キー管理
「 RE_EXTERNAL_KEYmanager 」と入力します
ノードが完全にブートするまで、ブートメニュープロンプトで「 recover_xxxxxxxx_keymanager 」コマンドを何度も問題に接続する必要がある場合があります。
-
ノードをブートします。
「 boot_ontap 」
-
交換したノードがブートするまで待ちます。
いずれかのノードがテイクオーバーモードの場合は、ギブバックを実行します。
「 storage failover giveback 」を参照してください
-
すべてのポートがブロードキャストドメインに属していることを確認します。
-
ブロードキャストドメインを表示します。
「 network port broadcast-domain show 」
-
必要に応じて、ブロードキャストドメインにポートを追加します。
-
インタークラスタ LIF をホストする物理ポートを対応するブロードキャストドメインに追加します。
-
新しい物理ポートをホームポートとして使用するようにクラスタ間 LIF を変更します。
-
クラスタ間 LIF が起動したら、クラスタピアのステータスを確認し、必要に応じてクラスタピアリングを再確立します。
クラスタピアリングの再設定が必要になる場合があります。
-
必要に応じて、 VLAN とインターフェイスグループを再作成します。
VLAN およびインターフェイスグループのメンバーシップは、古いノードと異なる場合があります。
-
-
暗号化を使用する場合は、キー管理設定に対応したコマンドを使用してキーをリストアします。
使用するポート
使用するコマンド
オンボードキー管理
「セキュリティキーマネージャオンボード同期」
詳細については、を参照してください "オンボードキー管理の暗号化キーのリストア"。
外部キー管理
「 securitykey manager external restore -vserver svm-node __ key -server_host_name
LIF の設定を確認
スイッチバックの前に、 LIF が適切なノード / ポートにホストされていることを確認します。次の手順を実行する必要があります
このタスクは site_B で実行します。ノードはルートアグリゲートでブートされています。
-
スイッチバックの前に、 LIF が適切なノードとポートにホストされていることを確認します。
-
advanced 権限レベルに切り替えます。
「 advanced 」の権限が必要です
-
ポート設定を無視して LIF が適切に配置されるようにします。
「 vserver config override command 」 network interface modify -vserver vserver_name __ -home-node _active_port_after_upgrade _ -lif LIF_name -home-node _new_node_name _
「 vserver config override 」コマンド内で「 network interface modify 」コマンドを入力する場合、 Tab autoccomplete 機能は使用できません。autoccomplete を使用して「 network interface modify 」を作成し、「 vserver config override 」コマンドで囲むことができます。
-
admin 権限レベルに戻ります。 +
set -privilege admin
-
-
インターフェイスをホームノードにリバートします。
「 network interface revert * -vserver_vserver-name に指定します
必要に応じて、すべての SVM でこの手順を実行します。
新しいライセンスをインストールします
スイッチバック処理の前に、新しいコントローラのライセンスをインストールする必要があります。
MetroCluster 構成をスイッチバックします
新しいコントローラを設定したら、 MetroCluster 構成をスイッチバックして構成を通常動作に戻します。
このタスクでは、スイッチバック処理を実行して MetroCluster 構成を通常動作に戻します。site_A のノードはまだアップグレード待ちです。
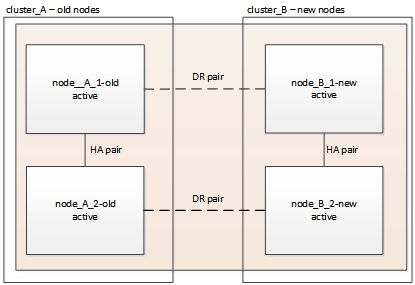
-
site_B の MetroCluster node show コマンドを問題し ' 出力を確認します
-
新しいノードが正しく表示されることを確認します。
-
新しいノードの状態が「 Waiting for switchback 」であることを確認します。
-
-
クラスタをスイッチバックします。
MetroCluster スイッチバック
-
スイッチバック処理の進捗を確認します。
「 MetroCluster show 」
出力に「 waiting-for-switchback 」と表示されたら、スイッチバック処理はまだ進行中です。
cluster_B::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode switchover AUSO Failure Domain - Remote: cluster_A Configuration state configured Mode waiting-for-switchback AUSO Failure Domain -出力に「 normal 」と表示された場合、スイッチバック処理は完了しています。
cluster_B::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode normal AUSO Failure Domain - Remote: cluster_A Configuration state configured Mode normal AUSO Failure Domain -スイッチバックが完了するまでに時間がかかる場合は、「 MetroCluster config-replication resync-status show 」コマンドを使用することで、進行中のベースラインのステータスを確認できます。このコマンドは、 advanced 権限レベルで実行します。
MetroCluster 構成の健全性を確認します
コントローラモジュールをアップグレードしたら、 MetroCluster 構成の健全性を確認する必要があります。
このタスクは、 MetroCluster 構成の任意のノードで実行できます。
-
MetroCluster 構成の動作を確認します。
-
MetroCluster 構成と運用モードが正常な状態であることを確認します。
「 MetroCluster show 」
-
MetroCluster チェックを実行します。
「 MetroCluster check run 」のようになります
-
MetroCluster チェックの結果を表示します。
MetroCluster チェックショー
MetroCluster check runとMetroCluster check showを実行すると'次のようなエラーメッセージが表示されます
例Failed to validate the node and cluster components before the switchover operation. Cluster_A:: node_A_1 (non-overridable veto): DR partner NVLog mirroring is not online. Make sure that the links between the two sites are healthy and properly configured.+ これは、アップグレードプロセス時にコントローラが一致しないことが原因で想定される動作であり、エラーメッセージが無視しても問題ありません。
-
cluster_Aのノードをアップグレードします。
cluster_A についてもアップグレード手順を繰り返す必要があります
-
cluster_Aのノードをアップグレードするために、上記の手順を繰り返し"アップグレードを準備"ます。
手順を繰り返すと、クラスターとノードへの参照がすべて逆になります。例えば、cluster_Aからのスイッチオーバーの例は、cluster_Bからのスイッチオーバーになります。
カスタム AutoSupport メッセージをメンテナンス後に送信します
アップグレードの完了後、ケースの自動作成を再開できるように、メンテナンスの終了を通知する AutoSupport メッセージを送信する必要があります。
-
サポートケースの自動生成を再開するには、メンテナンスが完了したことを示す AutoSupport メッセージを送信します。
-
次のコマンドを問題に設定します。
「 system node AutoSupport invoke -node * -type all -message MAINT= end 」というメッセージが表示されます
-
パートナークラスタに対してこのコマンドを繰り返します。
-
Tiebreaker による監視をリストアします
MetroCluster 構成が Tiebreaker ソフトウェアで監視するように設定されている場合は、 Tiebreaker 接続をリストアできます。
-
以下の手順で "MetroCluster 構成を追加" MetroCluster Tiebreaker のインストールと構成 を参照してください。