

 Note di rilascio di MetroCluster
Note di rilascio di MetroCluster
Aggiornamento dei controller in una configurazione MetroCluster FC mediante switchover e switchback
 Suggerisci modifiche
Suggerisci modifiche
È possibile utilizzare l'operazione di switchover MetroCluster per fornire un servizio senza interruzioni ai client mentre i moduli controller sul cluster partner vengono aggiornati. Altri componenti (ad esempio shelf di storage o switch) non possono essere aggiornati come parte di questa procedura.
Combinazioni di piattaforme supportate
È possibile aggiornare alcune piattaforme utilizzando le operazioni di switchover e switchback in una configurazione MetroCluster FC.
Per informazioni sulle combinazioni di upgrade della piattaforma supportate, consultare la tabella di upgrade MetroCluster FC in "Scegliere una procedura di aggiornamento del controller".
Fare riferimento a. "Scelta di un metodo di aggiornamento o refresh" per ulteriori procedure.
A proposito di questa attività
-
Questa procedura può essere utilizzata solo per l'aggiornamento del controller.
Gli altri componenti della configurazione, come gli shelf di storage o gli switch, non possono essere aggiornati contemporaneamente.
-
È possibile utilizzare questa procedura con alcune versioni di ONTAP:
-
Le configurazioni a due nodi sono supportate in ONTAP 9.3 e versioni successive.
-
Le configurazioni a quattro e otto nodi sono supportate in ONTAP 9.8 e versioni successive.
Non utilizzare questa procedura su configurazioni a quattro o otto nodi con versioni di ONTAP precedenti alla 9.8.
-
-
Le piattaforme originali e nuove devono essere compatibili e supportate.

Se le piattaforme originali o nuove sono sistemi FAS8020 o AFF8020 che utilizzano le porte 1c e 1d in modalità FC-VI, consultare l'articolo della Knowledge base "Aggiornamento dei controller quando le connessioni FCVI su nodi FAS8020 o AFF8020 esistenti utilizzano le porte 1c e 1d." -
Le licenze di entrambi i siti devono corrispondere. È possibile ottenere nuove licenze da "Supporto NetApp".
-
Questa procedura si applica ai moduli controller in una configurazione MetroCluster FC (Stretch MetroCluster a due nodi o una configurazione Fabric-Attached MetroCluster a due, quattro o otto nodi).
-
Tutti i controller dello stesso gruppo di DR devono essere aggiornati durante lo stesso periodo di manutenzione.
L'utilizzo della configurazione MetroCluster con diversi tipi di controller nello stesso gruppo DR non è supportato al di fuori di questa attività di manutenzione. Per le configurazioni MetroCluster a otto nodi, i controller all'interno di un gruppo DR devono essere gli stessi, ma entrambi i gruppi DR possono utilizzare diversi tipi di controller.
-
Si consiglia di eseguire il mapping delle connessioni storage, FC ed Ethernet tra i nodi originali e i nuovi nodi in anticipo.
-
Se la nuova piattaforma ha meno slot rispetto al sistema originale o se ha un numero inferiore o diversi tipi di porte, potrebbe essere necessario aggiungere un adattatore al nuovo sistema.
Per ulteriori informazioni, consultare "NetApp Hardware Universe"
In questa procedura vengono utilizzati i seguenti nomi di esempio:
-
Sito_A.
-
Prima dell'aggiornamento:
-
Node_A_1-old
-
Node_A_2-old
-
-
Dopo l'aggiornamento:
-
Node_A_1-new
-
Node_A_2-new
-
-
-
Sito_B
-
Prima dell'aggiornamento:
-
Node_B_1-old
-
Node_B_2-old
-
-
Dopo l'aggiornamento:
-
Node_B_1-new
-
Node_B_2-new
-
-
Preparazione per l'aggiornamento
Prima di apportare modifiche alla configurazione MetroCluster esistente, è necessario controllare lo stato della configurazione, preparare le nuove piattaforme ed eseguire altre attività varie.
Verifica dello stato della configurazione MetroCluster
Prima di eseguire l'aggiornamento, è necessario verificare lo stato e la connettività della configurazione di MetroCluster.
-
Verificare il funzionamento della configurazione MetroCluster in ONTAP:
-
Verificare che i nodi siano multipathing:
node run -node node-name sysconfig -aEseguire questo comando per ogni nodo della configurazione MetroCluster.
-
Verificare che non vi siano dischi rotti nella configurazione:
storage disk show -brokenEseguire questo comando su ciascun nodo della configurazione MetroCluster.
-
Verificare la presenza di eventuali avvisi sullo stato di salute:
system health alert showEseguire questo comando su ciascun cluster.
-
Verificare le licenze sui cluster:
system license showEseguire questo comando su ciascun cluster.
-
Verificare i dispositivi collegati ai nodi:
network device-discovery showEseguire questo comando su ciascun cluster.
-
Verificare che il fuso orario e l'ora siano impostati correttamente su entrambi i siti:
cluster date show
Eseguire questo comando su ciascun cluster. È possibile utilizzare
cluster datecomandi per configurare l'ora e il fuso orario. -
-
Verificare la presenza di eventuali avvisi sullo stato di salute sugli switch (se presenti):
storage switch showEseguire questo comando su ciascun cluster.
-
Confermare la modalità operativa della configurazione MetroCluster ed eseguire un controllo MetroCluster.
-
Verificare la configurazione MetroCluster e che la modalità operativa sia normale:
metrocluster show -
Verificare che siano visualizzati tutti i nodi previsti:
metrocluster node show -
Immettere il seguente comando:
metrocluster check run -
Visualizzare i risultati del controllo MetroCluster:
metrocluster check show
-
-
Controllare il cablaggio MetroCluster con lo strumento Config Advisor.
-
Scaricare ed eseguire Config Advisor.
-
Dopo aver eseguito Config Advisor, esaminare l'output dello strumento e seguire le raccomandazioni nell'output per risolvere eventuali problemi rilevati.
-
Mappatura delle porte dai vecchi nodi ai nuovi nodi
È necessario pianificare la mappatura delle LIF sulle porte fisiche dei vecchi nodi alle porte fisiche dei nuovi nodi.
Quando il nuovo nodo viene avviato per la prima volta durante il processo di aggiornamento, riproduce la configurazione più recente del vecchio nodo che sta sostituendo. Quando si avvia Node_A_1-new, ONTAP tenta di ospitare le LIF sulle stesse porte utilizzate su Node_A_1-old. Pertanto, come parte dell'aggiornamento, è necessario regolare la configurazione della porta e della LIF in modo che sia compatibile con quella del vecchio nodo. Durante la procedura di aggiornamento, verranno eseguiti i passaggi sul vecchio e sul nuovo nodo per garantire la corretta configurazione LIF di cluster, gestione e dati.
La seguente tabella mostra esempi di modifiche alla configurazione relative ai requisiti di porta dei nuovi nodi.
Porte fisiche di interconnessione cluster |
||
Vecchio controller |
Nuovo controller |
Azione richiesta |
e0a, e0b |
e3a, e3b |
Nessuna porta corrispondente. Dopo l'aggiornamento, è necessario ricreare le porte del cluster."Preparazione delle porte del cluster su un modulo controller esistente" |
e0c, e0d |
e0a,e0b,e0c,e0d |
e0c e e0d corrispondono alle porte. Non è necessario modificare la configurazione, ma dopo l'aggiornamento è possibile distribuire le LIF del cluster tra le porte del cluster disponibili. |
-
Determinare quali porte fisiche sono disponibili sui nuovi controller e quali LIF possono essere ospitate sulle porte.
L'utilizzo della porta del controller dipende dal modulo della piattaforma e dagli switch che verranno utilizzati nella configurazione IP di MetroCluster. È possibile ottenere l'utilizzo delle porte delle nuove piattaforme da "NetApp Hardware Universe".
Identificare anche l'utilizzo dello slot per schede FC-VI.
-
Pianificare l'utilizzo delle porte e, se necessario, compilare le seguenti tabelle come riferimento per ciascuno dei nuovi nodi.
Durante l'esecuzione della procedura di aggiornamento, fare riferimento alla tabella.
Node_A_1-old
Node_A_1-new
LIF
Porte
IPspaces
Domini di broadcast
Porte
IPspaces
Domini di broadcast
Cluster 1
Cluster 2
Cluster 3
Cluster 4
Gestione dei nodi
Gestione del cluster
Dati 1
Dati 2
Dati 3
Dati 4
SAN
Porta intercluster
Raccolta di informazioni prima dell'aggiornamento
Prima di eseguire l'aggiornamento, è necessario raccogliere informazioni per ciascuno dei vecchi nodi e, se necessario, regolare i domini di broadcast di rete, rimuovere eventuali VLAN e gruppi di interfacce e raccogliere informazioni sulla crittografia.
Questa attività viene eseguita sulla configurazione MetroCluster FC esistente.
-
Etichettare i cavi per i controller esistenti, per consentire una facile identificazione dei cavi durante la configurazione dei nuovi controller.
-
Raccogliere gli ID di sistema dei nodi nella configurazione MetroCluster:
metrocluster node show -fields node-systemid,dr-partner-systemidDurante la procedura di aggiornamento, sostituisci questi vecchi ID di sistema con gli ID di sistema dei nuovi moduli controller.
In questo esempio, per una configurazione MetroCluster FC a quattro nodi, vengono recuperati i seguenti vecchi ID di sistema:
-
Node_A_1-old: 4068741258
-
Node_A_2-old: 4068741260
-
Node_B_1-old: 4068741254
-
Node_B_2-old: 4068741256
metrocluster-siteA::> metrocluster node show -fields node-systemid,ha-partner-systemid,dr-partner-systemid,dr-auxiliary-systemid dr-group-id cluster node node-systemid ha-partner-systemid dr-partner-systemid dr-auxiliary-systemid ----------- ------------------------- ------------------ ------------- ------------------- ------------------- --------------------- 1 Cluster_A Node_A_1-old 4068741258 4068741260 4068741256 4068741256 1 Cluster_A Node_A_2-old 4068741260 4068741258 4068741254 4068741254 1 Cluster_B Node_B_1-old 4068741254 4068741256 4068741258 4068741260 1 Cluster_B Node_B_2-old 4068741256 4068741254 4068741260 4068741258 4 entries were displayed.
In questo esempio, per una configurazione MetroCluster FC a due nodi, vengono recuperati i seguenti vecchi ID di sistema:
-
Node_A_1: 4068741258
-
Node_B_1: 4068741254
metrocluster node show -fields node-systemid,dr-partner-systemid dr-group-id cluster node node-systemid dr-partner-systemid ----------- ---------- -------- ------------- ------------ 1 Cluster_A Node_A_1-old 4068741258 4068741254 1 Cluster_B node_B_1-old - - 2 entries were displayed.
-
-
Raccogliere informazioni su porta e LIF per ciascun nodo precedente.
Per ciascun nodo, è necessario raccogliere l'output dei seguenti comandi:
-
network interface show -role cluster,node-mgmt -
network port show -node node-name -type physical -
network port vlan show -node node-name -
network port ifgrp show -node node_name -instance -
network port broadcast-domain show -
network port reachability show -detail -
network ipspace show -
volume show -
storage aggregate show -
system node run -node node-name sysconfig -a
-
-
Se i nodi MetroCluster si trovano in una configurazione SAN, raccogliere le informazioni pertinenti.
Si dovrebbe ottenere l'output dei seguenti comandi:
-
fcp adapter show -instance -
fcp interface show -instance -
iscsi interface show -
ucadmin show
-
-
Se il volume root è crittografato, raccogliere e salvare la passphrase utilizzata per il gestore delle chiavi:
security key-manager backup show -
Se i nodi MetroCluster utilizzano la crittografia per volumi o aggregati, copiare le informazioni relative alle chiavi e alle passphrase.
Per ulteriori informazioni, vedere "Backup manuale delle informazioni di gestione delle chiavi integrate".
-
Se Onboard Key Manager è configurato:
security key-manager onboard show-backupLa passphrase sarà necessaria più avanti nella procedura di aggiornamento.
-
Se la gestione delle chiavi aziendali (KMIP) è configurata, eseguire i seguenti comandi:
security key-manager external show -instance
security key-manager key query -
Rimozione della configurazione esistente dal software di monitoraggio o dallo spareggio
Se la configurazione esistente viene monitorata con la configurazione di MetroCluster Tiebreaker o altre applicazioni di terze parti (ad esempio ClusterLion) che possono avviare uno switchover, è necessario rimuovere la configurazione MetroCluster dal Tiebreaker o da un altro software prima della transizione.
-
Rimuovere la configurazione MetroCluster esistente dal software Tiebreaker.
-
Rimuovere la configurazione MetroCluster esistente da qualsiasi applicazione di terze parti in grado di avviare lo switchover.
Consultare la documentazione dell'applicazione.
Invio di un messaggio AutoSupport personalizzato prima della manutenzione
Prima di eseguire la manutenzione, devi inviare un messaggio AutoSupport per informare il supporto tecnico NetApp che la manutenzione è in corso. Informare il supporto tecnico che la manutenzione è in corso impedisce loro di aprire un caso partendo dal presupposto che si sia verificata un'interruzione.
Questa attività deve essere eseguita su ciascun sito MetroCluster.
-
Per impedire la generazione automatica del caso di supporto, inviare un messaggio AutoSupport per indicare che la manutenzione è in corso.
-
Immettere il seguente comando:
system node autosupport invoke -node * -type all -message MAINT=maintenance-window-in-hoursmaintenance-window-in-hoursspecifica la lunghezza della finestra di manutenzione, con un massimo di 72 ore. Se la manutenzione viene completata prima che sia trascorso il tempo, è possibile richiamare un messaggio AutoSupport che indica la fine del periodo di manutenzione:
system node autosupport invoke -node * -type all -message MAINT=end-
Ripetere il comando sul cluster partner.
-
Passaggio alla configurazione MetroCluster
È necessario passare alla configurazione Site_A in modo che le piattaforme sul sito_B possano essere aggiornate.
Questa attività deve essere eseguita sul sito_A.
Al termine di questa attività, cluster_A è attivo e fornisce dati per entrambi i siti. Cluster_B è inattivo e pronto per iniziare il processo di aggiornamento, come mostrato nell'illustrazione seguente.
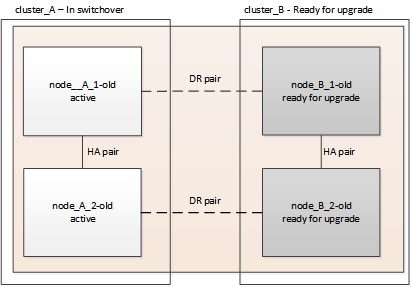
-
Passare alla configurazione MetroCluster del sito_A in modo che i nodi del sito_B possano essere aggiornati:
-
Selezionare l'opzione che corrisponde alla configurazione ed eseguire il comando corretto sul cluster_A:
Opzione 1: Configurazione FC a quattro o otto nodi con ONTAP 9.8 o versione successivaEseguire il comando:
metrocluster switchover -controller-replacement trueOpzione 2: Configurazione FC a due nodi con ONTAP 9.3 e versioni successiveEseguire il comando:
metrocluster switchoverIl completamento dell'operazione può richiedere alcuni minuti.
-
Monitorare il funzionamento dello switchover:
metrocluster operation show -
Al termine dell'operazione, verificare che i nodi siano in stato di switchover:
metrocluster show -
Controllare lo stato dei nodi MetroCluster:
metrocluster node show
-
-
Riparare gli aggregati di dati.
-
Riparare gli aggregati di dati:
metrocluster heal data-aggregates -
Verificare che l'operazione di riparazione sia completa eseguendo il
metrocluster operation showcomando sul cluster integro:cluster_A::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/29/2020 20:54:41 End Time: 7/29/2020 20:54:42 Errors: -
-
-
Riparare gli aggregati root.
-
Riparare gli aggregati di dati:
metrocluster heal root-aggregates -
Verificare che l'operazione di riparazione sia completa eseguendo il
metrocluster operation showcomando sul cluster integro:cluster_A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2020 20:58:41 End Time: 7/29/2020 20:59:42 Errors: -
-
Preparazione della configurazione di rete dei vecchi controller
Per garantire che la rete riprenda correttamente sui nuovi controller, è necessario spostare i file LIF su una porta comune e rimuovere la configurazione di rete dei vecchi controller.
-
Questa attività deve essere eseguita su ciascuno dei vecchi nodi.
-
Verranno utilizzate le informazioni raccolte in "Mappatura delle porte dai vecchi nodi ai nuovi nodi".
-
Avviare i vecchi nodi e quindi accedere ai nodi:
boot_ontap -
Assegnare la porta home di tutti i file LIF di dati sul vecchio controller a una porta comune identica sia sul vecchio che sul nuovo modulo controller.
-
Visualizzare le LIF:
network interface showTutti i dati LIFS, inclusi SAN e NAS, verranno gestiti e non verranno gestiti dal sistema operativo poiché sono attivi nel sito di switchover (cluster_A).
-
Esaminare l'output per trovare una porta di rete fisica comune che sia la stessa sui controller vecchi e nuovi che non sia utilizzata come porta del cluster.
Ad esempio, e0d è una porta fisica sui vecchi controller ed è presente anche sui nuovi controller. e0d non viene utilizzato come porta del cluster o in altro modo sui nuovi controller.
Per informazioni sull'utilizzo delle porte per i modelli di piattaforma, consultare "NetApp Hardware Universe"
-
Modificare tutti i dati LIFS per utilizzare la porta comune come porta home:
network interface modify -vserver svm-name -lif data-lif -home-port port-idNell'esempio seguente, questo è "e0d".
Ad esempio:
network interface modify -vserver vs0 -lif datalif1 -home-port e0d
-
-
Modificare i domini di broadcast per rimuovere la vlan e le porte fisiche che devono essere eliminate:
broadcast-domain remove-ports -broadcast-domain broadcast-domain-name -ports node-name:port-idRipetere questo passaggio per tutte le porte VLAN e fisiche.
-
Rimuovere tutte le porte VLAN utilizzando le porte del cluster come porte membro e ifgrps utilizzando le porte del cluster come porte membro.
-
Elimina porte VLAN:
network port vlan delete -node node-name -vlan-name portid-vlandidAd esempio:
network port vlan delete -node node1 -vlan-name e1c-80
-
Rimuovere le porte fisiche dai gruppi di interfacce:
network port ifgrp remove-port -node node-name -ifgrp interface-group-name -port portidAd esempio:
network port ifgrp remove-port -node node1 -ifgrp a1a -port e0d
-
Rimuovere le porte della VLAN e del gruppo di interfacce dal dominio di broadcast:
network port broadcast-domain remove-ports -ipspace ipspace -broadcast-domain broadcast-domain-name -ports nodename:portname,nodename:portname,.. -
Modificare le porte del gruppo di interfacce per utilizzare altre porte fisiche come membro in base alle necessità.:
ifgrp add-port -node node-name -ifgrp interface-group-name -port port-id
-
-
Arrestare i nodi:
halt -inhibit-takeover true -node node-nameQuesta operazione deve essere eseguita su entrambi i nodi.
Rimozione delle vecchie piattaforme
I vecchi controller devono essere rimossi dalla configurazione.
Questa attività viene eseguita sul sito_B.
-
Connettersi alla console seriale dei vecchi controller (Node_B_1-old e Node_B_2-old) nel sito_B e verificare che venga visualizzato il prompt DEL CARICATORE.
-
Scollegare le connessioni di storage e di rete su Node_B_1-old e Node_B_2-old ed etichettare i cavi in modo che possano essere ricollegati ai nuovi nodi.
-
Scollegare i cavi di alimentazione da Node_B_1-old e Node_B_2-old.
-
Rimuovere i controller Node_B_1-old e Node_B_2-old dal rack.
Configurazione dei nuovi controller
È necessario eseguire il rack e installare i controller, eseguire la configurazione richiesta in modalità manutenzione, quindi avviare i controller e verificare la configurazione LIF sui controller.
Configurazione dei nuovi controller
I nuovi controller devono essere montati in rack e cablati.
-
Pianificare il posizionamento dei nuovi moduli controller e degli shelf di storage in base alle necessità.
Lo spazio rack dipende dal modello di piattaforma dei moduli controller, dai tipi di switch e dal numero di shelf di storage nella configurazione.
-
Mettere a terra l'utente.
-
Installare i moduli controller nel rack o nell'armadietto.
-
Se i nuovi moduli controller non sono dotati di schede FC-VI e se le schede FC-VI dei vecchi controller sono compatibili con i nuovi controller, sostituire le schede FC-VI e installarle negli slot corretti.
Vedere "NetApp Hardware Universe" Per informazioni sugli slot per schede FC-VI.
-
Collegare l'alimentazione, la console seriale e le connessioni di gestione dei controller come descritto nelle Guide di installazione e configurazione di MetroCluster.
Non collegare altri cavi scollegati dai vecchi controller in questo momento.
-
Accendere i nuovi nodi e premere Ctrl-C quando richiesto per visualizzare il prompt DEL CARICATORE.
Avvio in rete dei nuovi controller
Dopo aver installato i nuovi nodi, è necessario eseguire il netboot per assicurarsi che i nuovi nodi eseguano la stessa versione di ONTAP dei nodi originali. Il termine netboot indica che si sta eseguendo l'avvio da un'immagine ONTAP memorizzata su un server remoto. Durante la preparazione per il netboot, è necessario inserire una copia dell'immagine di boot di ONTAP 9 su un server Web a cui il sistema può accedere.
Questa attività viene eseguita su ciascuno dei nuovi moduli controller.
-
Accedere a. "Sito di supporto NetApp" per scaricare i file utilizzati per eseguire il netboot del sistema.
-
Scaricare il software ONTAP appropriato dalla sezione di download del software del sito di supporto NetApp e memorizzare il file ontap-version_image.tgz in una directory accessibile dal Web.
-
Accedere alla directory accessibile dal Web e verificare che i file necessari siano disponibili.
Se il modello di piattaforma è…
Quindi…
Sistemi della serie FAS/AFF8000
Estrarre il contenuto del file ontap-version_image.tgznella directory di destinazione: Tar -zxvf ontap-version_image.tgz NOTA: Se si sta estraendo il contenuto su Windows, utilizzare 7-zip o WinRAR per estrarre l'immagine netboot. L'elenco delle directory deve contenere una cartella netboot con un file kernel:netboot/kernel
Tutti gli altri sistemi
L'elenco delle directory deve contenere una cartella netboot con un file del kernel: ontap-version_image.tgz non è necessario estrarre il file ontap-version_image.tgz.
-
Al prompt DEL CARICATORE, configurare la connessione netboot per una LIF di gestione:
-
Se l'indirizzo IP è DHCP, configurare la connessione automatica:
ifconfig e0M -auto -
Se l'indirizzo IP è statico, configurare la connessione manuale:
ifconfig e0M -addr=ip_addr -mask=netmask-gw=gateway
-
-
Eseguire il netboot.
-
Se la piattaforma è un sistema della serie 80xx, utilizzare questo comando:
netboot http://web_server_ip/path_to_web-accessible_directory/netboot/kernel -
Se la piattaforma è un altro sistema, utilizzare il seguente comando:
netboot http://web_server_ip/path_to_web-accessible_directory/ontap-version_image.tgz
-
-
Dal menu di avvio, selezionare l'opzione (7) installare prima il nuovo software per scaricare e installare la nuova immagine software sul dispositivo di avvio.
Disregard the following message: "This procedure is not supported for Non-Disruptive Upgrade on an HA pair". It applies to nondisruptive upgrades of software, not to upgrades of controllers. . Se viene richiesto di continuare la procedura, immettere `y`E quando viene richiesto il pacchetto, inserire l'URL del file immagine: `\http://web_server_ip/path_to_web-accessible_directory/ontap-version_image.tgz`
Enter username/password if applicable, or press Enter to continue.
-
Assicurarsi di entrare
nper ignorare il ripristino del backup quando viene visualizzato un prompt simile a quanto segue:Do you want to restore the backup configuration now? {y|n} -
Riavviare immettendo
yquando viene visualizzato un prompt simile a quanto segue:The node must be rebooted to start using the newly installed software. Do you want to reboot now? {y|n}
Cancellazione della configurazione su un modulo controller
Prima di utilizzare un nuovo modulo controller nella configurazione MetroCluster, è necessario cancellare la configurazione esistente.
-
Se necessario, arrestare il nodo per visualizzare il prompt DEL CARICATORE:
halt -
Al prompt DEL CARICATORE, impostare le variabili ambientali sui valori predefiniti:
set-defaults -
Salvare l'ambiente:
saveenv -
Al prompt DEL CARICATORE, avviare il menu di avvio:
boot_ontap menu -
Al prompt del menu di avvio, cancellare la configurazione:
wipeconfigRispondere
yesal prompt di conferma.Il nodo si riavvia e viene visualizzato di nuovo il menu di avvio.
-
Nel menu di avvio, selezionare l'opzione 5 per avviare il sistema in modalità di manutenzione.
Rispondere
yesal prompt di conferma.
Ripristino della configurazione HBA
A seconda della presenza e della configurazione delle schede HBA nel modulo controller, è necessario configurarle correttamente per l'utilizzo da parte del sito.
-
In modalità Maintenance (manutenzione), configurare le impostazioni per gli HBA presenti nel sistema:
-
Verificare le impostazioni correnti delle porte:
ucadmin show -
Aggiornare le impostazioni della porta secondo necessità.
Se si dispone di questo tipo di HBA e della modalità desiderata…
Utilizzare questo comando…
FC CNA
ucadmin modify -m fc -t initiator adapter-nameEthernet CNA
ucadmin modify -mode cna adapter-nameDestinazione FC
fcadmin config -t target adapter-nameIniziatore FC
fcadmin config -t initiator adapter-name -
-
Uscire dalla modalità di manutenzione:
haltDopo aver eseguito il comando, attendere che il nodo si arresti al prompt DEL CARICATORE.
-
Riavviare il nodo in modalità Maintenance per rendere effettive le modifiche di configurazione:
boot_ontap maint -
Verificare le modifiche apportate:
Se si dispone di questo tipo di HBA…
Utilizzare questo comando…
CNA
ucadmin showFC
fcadmin show
Impostazione dello stato ha sui nuovi controller e chassis
È necessario verificare lo stato ha dei controller e dello chassis e, se necessario, aggiornarlo in modo che corrisponda alla configurazione del sistema.
-
In modalità Maintenance (manutenzione), visualizzare lo stato ha del modulo controller e dello chassis:
ha-config showLo stato ha per tutti i componenti deve essere mcc.
Se la configurazione MetroCluster ha…
Lo stato ha deve essere…
Due nodi
mcc-2n
Quattro o otto nodi
mcc
-
Se lo stato di sistema visualizzato del controller non è corretto, impostare lo stato ha per il modulo controller e lo chassis:
Se la configurazione MetroCluster ha…
Eseguire questi comandi…
Due nodi
ha-config modify controller mcc-2nha-config modify chassis mcc-2nQuattro o otto nodi
ha-config modify controller mccha-config modify chassis mcc
Riassegnazione dei dischi aggregati root
Riassegnare i dischi aggregati root al nuovo modulo controller, utilizzando i sistemi raccolti in precedenza
Questa attività viene eseguita in modalità manutenzione.
I vecchi ID di sistema sono stati identificati in "Raccolta di informazioni prima dell'aggiornamento".
Gli esempi di questa procedura utilizzano controller con i seguenti ID di sistema:
Nodo |
Vecchio ID di sistema |
Nuovo ID di sistema |
Node_B_1 |
4068741254 |
1574774970 |
-
Collegare tutti gli altri collegamenti ai nuovi moduli controller (FC-VI, storage, interconnessione cluster, ecc.).
-
Arrestare il sistema e avviare la modalità di manutenzione dal prompt DEL CARICATORE:
boot_ontap maint -
Visualizzare i dischi di proprietà di Node_B_1-old:
disk show -aL'output del comando mostra l'ID di sistema del nuovo modulo controller (1574774970). Tuttavia, i dischi aggregati root sono ancora di proprietà del vecchio ID di sistema (4068741254). Questo esempio non mostra i dischi di proprietà di altri nodi nella configurazione MetroCluster.
*> disk show -a Local System ID: 1574774970 DISK OWNER POOL SERIAL NUMBER HOME DR HOME ------------ ------------- ----- ------------- ------------- ------------- ... rr18:9.126L44 node_B_1-old(4068741254) Pool1 PZHYN0MD node_B_1-old(4068741254) node_B_1-old(4068741254) rr18:9.126L49 node_B_1-old(4068741254) Pool1 PPG3J5HA node_B_1-old(4068741254) node_B_1-old(4068741254) rr18:8.126L21 node_B_1-old(4068741254) Pool1 PZHTDSZD node_B_1-old(4068741254) node_B_1-old(4068741254) rr18:8.126L2 node_B_1-old(4068741254) Pool0 S0M1J2CF node_B_1-old(4068741254) node_B_1-old(4068741254) rr18:8.126L3 node_B_1-old(4068741254) Pool0 S0M0CQM5 node_B_1-old(4068741254) node_B_1-old(4068741254) rr18:9.126L27 node_B_1-old(4068741254) Pool0 S0M1PSDW node_B_1-old(4068741254) node_B_1-old(4068741254) ...
-
Riassegnare i dischi aggregati root sugli shelf di dischi al nuovo controller:
disk reassign -s old-sysid -d new-sysidL'esempio seguente mostra la riassegnazione dei dischi:
*> disk reassign -s 4068741254 -d 1574774970 Partner node must not be in Takeover mode during disk reassignment from maintenance mode. Serious problems could result!! Do not proceed with reassignment if the partner is in takeover mode. Abort reassignment (y/n)? n After the node becomes operational, you must perform a takeover and giveback of the HA partner node to ensure disk reassignment is successful. Do you want to continue (y/n)? Jul 14 19:23:49 [localhost:config.bridge.extra.port:error]: Both FC ports of FC-to-SAS bridge rtp-fc02-41-rr18:9.126L0 S/N [FB7500N107692] are attached to this controller. y Disk ownership will be updated on all disks previously belonging to Filer with sysid 4068741254. Do you want to continue (y/n)? y
-
Verificare che tutti i dischi siano riassegnati come previsto:
disk show*> disk show Local System ID: 1574774970 DISK OWNER POOL SERIAL NUMBER HOME DR HOME ------------ ------------- ----- ------------- ------------- ------------- rr18:8.126L18 node_B_1-new(1574774970) Pool1 PZHYN0MD node_B_1-new(1574774970) node_B_1-new(1574774970) rr18:9.126L49 node_B_1-new(1574774970) Pool1 PPG3J5HA node_B_1-new(1574774970) node_B_1-new(1574774970) rr18:8.126L21 node_B_1-new(1574774970) Pool1 PZHTDSZD node_B_1-new(1574774970) node_B_1-new(1574774970) rr18:8.126L2 node_B_1-new(1574774970) Pool0 S0M1J2CF node_B_1-new(1574774970) node_B_1-new(1574774970) rr18:9.126L29 node_B_1-new(1574774970) Pool0 S0M0CQM5 node_B_1-new(1574774970) node_B_1-new(1574774970) rr18:8.126L1 node_B_1-new(1574774970) Pool0 S0M1PSDW node_B_1-new(1574774970) node_B_1-new(1574774970) *>
-
Visualizzare lo stato dell'aggregato:
aggr status*> aggr status Aggr State Status Options aggr0_node_b_1-root online raid_dp, aggr root, nosnap=on, mirrored mirror_resync_priority=high(fixed) fast zeroed 64-bit -
Ripetere i passaggi precedenti sul nodo partner (Node_B_2-new).
Avviare i nuovi controller
Riavviare i controller dal menu di avvio per aggiornare l'immagine flash del controller. Se la crittografia è configurata, sono necessari ulteriori passaggi.
Questa attività deve essere eseguita su tutti i nuovi controller.
-
Arrestare il nodo:
halt -
Se è configurato un gestore di chiavi esterno, impostare i relativi bootargs:
setenv bootarg.kmip.init.ipaddr ip-addresssetenv bootarg.kmip.init.netmask netmasksetenv bootarg.kmip.init.gateway gateway-addresssetenv bootarg.kmip.init.interface interface-id -
Visualizzare il menu di avvio:
boot_ontap menu -
Se viene utilizzata la crittografia root, a seconda della versione di ONTAP in uso, selezionare l'opzione del menu di avvio o immettere il comando del menu di avvio per la configurazione della gestione delle chiavi.
ONTAP 9.8 e versioni successiveA partire da ONTAP 9.8, selezionare l'opzione del menu di avvio.
Se si utilizza…
Selezionare questa opzione del menu di avvio…
Gestione delle chiavi integrata
Opzione “10”
Seguire le istruzioni per fornire gli input necessari per ripristinare la configurazione di gestione delle chiavi.
Gestione esterna delle chiavi
Opzione “11”
Seguire le istruzioni per fornire gli input necessari per ripristinare la configurazione di gestione delle chiavi.
ONTAP 9.7 e versioni precedentiPer ONTAP 9.7 e versioni precedenti, eseguire il comando del menu di avvio.
Se si utilizza…
Eseguire questo comando al prompt del menu di avvio…
Gestione delle chiavi integrata
recover_onboard_keymanagerGestione esterna delle chiavi
recover_external_keymanager -
Se l'autoboot è attivato, interrompere l'autoboot premendo CTRL-C.
-
Dal menu di boot, eseguire l'opzione “6”.
L'opzione “6” riavvia il nodo due volte prima del completamento. Rispondere “y” alle richieste di modifica dell'id di sistema. Attendere i secondi messaggi di riavvio:
Successfully restored env file from boot media... Rebooting to load the restored env file...
-
Verificare che il sistema partner sia corretto:
printenv partner-sysidSe il partner-sysid non è corretto, impostarlo:
setenv partner-sysid partner-sysID -
Se viene utilizzata la crittografia root, a seconda della versione di ONTAP in uso, selezionare l'opzione del menu di avvio oppure eseguire nuovamente il comando del menu di avvio per la configurazione della gestione delle chiavi.
ONTAP 9.8 e versioni successiveA partire da ONTAP 9.8, selezionare l'opzione del menu di avvio.
Se si utilizza…
Selezionare questa opzione del menu di avvio…
Gestione delle chiavi integrata
Opzione “10”
Seguire le istruzioni per fornire gli input necessari per ripristinare la configurazione di gestione delle chiavi.
Gestione esterna delle chiavi
Opzione “11”
Seguire le istruzioni per fornire gli input necessari per ripristinare la configurazione di gestione delle chiavi.
A seconda dell'impostazione del gestore delle chiavi, eseguire la procedura di ripristino selezionando l'opzione “10” o l'opzione “11”, quindi l'opzione “6” al primo prompt del menu di avvio. Per avviare completamente i nodi, potrebbe essere necessario ripetere la procedura di ripristino, continua con l'opzione “1” (boot normale).
ONTAP 9.7 e versioni precedentiPer ONTAP 9.7 e versioni precedenti, eseguire il comando del menu di avvio.
Se si utilizza…
Eseguire questo comando al prompt del menu di avvio…
Gestione delle chiavi integrata
recover_onboard_keymanagerGestione esterna delle chiavi
recover_external_keymanagerPotrebbe essere necessario eseguire il
recover_xxxxxxxx_keymanageral prompt del menu di boot più volte fino a quando i nodi non si avviano completamente. -
Avviare i nodi:
boot_ontap -
Attendere l'avvio dei nodi sostituiti.
Se uno dei nodi è in modalità Takeover, eseguire un giveback:
storage failover giveback -
Verificare che tutte le porte si trovino in un dominio di trasmissione:
-
Visualizzare i domini di trasmissione:
network port broadcast-domain show -
Aggiungere eventuali porte a un dominio di broadcast in base alle esigenze.
-
Aggiungere la porta fisica che ospiterà le LIF dell'intercluster al dominio Broadcast corrispondente.
-
Modificare le LIF dell'intercluster per utilizzare la nuova porta fisica come porta home.
-
Dopo aver attivato le LIF dell'intercluster, controllare lo stato del peer del cluster e ristabilire il peering del cluster secondo necessità.
Potrebbe essere necessario riconfigurare il peering del cluster.
-
Ricreare VLAN e gruppi di interfacce in base alle esigenze.
L'appartenenza alla VLAN e al gruppo di interfacce potrebbe essere diversa da quella del nodo precedente.
-
-
Se viene utilizzata la crittografia, ripristinare le chiavi utilizzando il comando corretto per la configurazione di gestione delle chiavi.
Se si utilizza…
Utilizzare questo comando…
Gestione delle chiavi integrata
security key-manager onboard syncPer ulteriori informazioni, vedere "Ripristino delle chiavi di crittografia integrate per la gestione delle chiavi".
Gestione esterna delle chiavi
`security key-manager external restore -vserver SVM -node node -key-server _host_name
Verifica della configurazione LIF in corso
Verificare che i file LIF siano ospitati su nodi/porte appropriati prima di passare al switchback. È necessario eseguire le seguenti operazioni
Questa attività viene eseguita sul sito_B, dove i nodi sono stati avviati con aggregati root.
-
Verificare che i file LIF siano ospitati sul nodo e sulle porte appropriati prima di passare al switchback.
-
Passare al livello di privilegio avanzato:
set -privilege advanced -
Eseguire l'override della configurazione della porta per garantire il corretto posizionamento di LIF:
vserver config override -command "network interface modify -vserver vserver_name -home-port active_port_after_upgrade -lif lif_name -home-node new_node_name"
Quando si accede a.
network interface modifyall'interno divserver config overridenon è possibile utilizzare la funzione di completamento automatico della scheda. È possibile crearenetwork interface modifyutilizzando il completamento automatico e quindi racchiuderlo invserver config overridecomando.-
Tornare al livello di privilegio admin:
set -privilege admin
-
-
Ripristinare le interfacce nel nodo principale:
network interface revert * -vserver vserver-nameEseguire questo passaggio su tutte le SVM secondo necessità.
Installare le nuove licenze
Prima dell'operazione di switchback, è necessario installare le licenze per i nuovi controller.
Tornare indietro alla configurazione MetroCluster
Una volta configurati i nuovi controller, si torna alla configurazione MetroCluster per ripristinare il normale funzionamento della configurazione.
Questa attività consente di eseguire l'operazione di switchback, ripristinando il normale funzionamento della configurazione MetroCluster. I nodi sul sito_A sono ancora in attesa di aggiornamento.
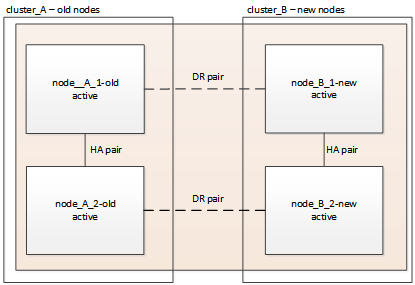
-
Eseguire il
metrocluster node showSu Site_B e controllare l'output.-
Verificare che i nuovi nodi siano rappresentati correttamente.
-
Verificare che i nuovi nodi siano nello stato "in attesa di switchback".
-
-
Switchback del cluster:
metrocluster switchback -
Controllare l'avanzamento dell'operazione di switchback:
metrocluster showL'operazione di switchback è ancora in corso quando viene visualizzato l'output
waiting-for-switchback:cluster_B::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode switchover AUSO Failure Domain - Remote: cluster_A Configuration state configured Mode waiting-for-switchback AUSO Failure Domain -L'operazione di switchback viene completata quando viene visualizzato l'output
normal:cluster_B::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode normal AUSO Failure Domain - Remote: cluster_A Configuration state configured Mode normal AUSO Failure Domain -Se il completamento di uno switchback richiede molto tempo, è possibile verificare lo stato delle linee di base in corso utilizzando
metrocluster config-replication resync-status showcomando. Questo comando si trova al livello di privilegio avanzato.
Verifica dello stato della configurazione di MetroCluster
Dopo aver aggiornato i moduli controller, è necessario verificare lo stato della configurazione MetroCluster.
Questa attività può essere eseguita su qualsiasi nodo della configurazione MetroCluster.
-
Verificare il funzionamento della configurazione MetroCluster:
-
Verificare la configurazione MetroCluster e che la modalità operativa sia normale:
metrocluster show -
Eseguire un controllo MetroCluster:
metrocluster check run -
Visualizzare i risultati del controllo MetroCluster:
metrocluster check show
Dopo aver eseguito metrocluster check rune. `metrocluster check show`viene visualizzato un messaggio di errore simile al seguente:
EsempioFailed to validate the node and cluster components before the switchover operation. Cluster_A:: node_A_1 (non-overridable veto): DR partner NVLog mirroring is not online. Make sure that the links between the two sites are healthy and properly configured.+ Si tratta di un comportamento previsto dovuto a una mancata corrispondenza del controller durante il processo di aggiornamento e il messaggio di errore può essere ignorato in modo sicuro.
-
Aggiornamento dei nodi sul cluster_A.
È necessario ripetere le attività di aggiornamento su cluster_A.
-
Ripetere i passaggi per aggiornare i nodi sul cluster_A, iniziando da "Preparazione per l'aggiornamento".
Durante l'esecuzione delle attività, tutti i riferimenti di esempio ai cluster e ai nodi vengono invertiti. Ad esempio, quando l'esempio viene dato allo switchover da cluster_A, si passa da cluster_B.
Invio di un messaggio AutoSupport personalizzato dopo la manutenzione
Una volta completato l'aggiornamento, inviare un messaggio AutoSupport che indica la fine della manutenzione, in modo da poter riprendere la creazione automatica del caso.
-
Per riprendere la generazione automatica del caso di supporto, inviare un messaggio AutoSupport per indicare che la manutenzione è stata completata.
-
Immettere il seguente comando:
system node autosupport invoke -node * -type all -message MAINT=end -
Ripetere il comando sul cluster partner.
-
Ripristino del monitoraggio di Tiebreaker
Se la configurazione MetroCluster è stata precedentemente configurata per il monitoraggio da parte del software Tiebreaker, è possibile ripristinare la connessione Tiebreaker.
-
Attenersi alla procedura descritta in "Aggiunta di configurazioni MetroCluster" In Installazione e configurazione di MetroCluster Tiebreaker.