

 MetroCluster 릴리즈 노트
MetroCluster 릴리즈 노트
새 컨트롤러에서 기존 쉘프를 지원하지 않을 때 중단 없이 전환(ONTAP 9.8 이상)
 변경 제안
변경 제안
ONTAP 9.8부터 2노드 MetroCluster FC 구성을 중단 없이 전환하고 기존 스토리지 쉘프가 새로운 MetroCluster IP 노드에서 지원되지 않는 경우에도 기존 드라이브 쉘프에서 데이터를 이동할 수 있습니다.
-
이 절차는 기존 스토리지 쉘프 모델이 새로운 MetroCluster IP 플랫폼 모델에서 지원되지 않는 경우에만 사용해야 합니다.
-
이 절차는 ONTAP 9.8 이상을 실행하는 시스템에서 지원됩니다.
-
이 절차는 중단을 따릅니다.
-
이 절차는 2노드 MetroCluster FC 구성에만 적용됩니다.
4노드 MetroCluster FC 구성이 있는 경우 를 참조하십시오 "전환 절차 선택".
-
모든 요구 사항을 충족하고 절차의 모든 단계를 따라야 합니다.
새로운 노드에서 쉘프가 지원되지 않는 경우의 전환 요구사항
전환 프로세스를 시작하기 전에 구성이 요구사항을 충족하는지 확인해야 합니다.
-
기존 구성은 2노드 패브릭 연결 또는 확장 MetroCluster 구성이어야 하며 모든 노드에서 ONTAP 9.8 이상을 실행해야 합니다.
새로운 MetroCluster IP 컨트롤러 모듈은 동일한 버전의 ONTAP 9.8을 실행해야 합니다.
-
기존 플랫폼과 새 플랫폼의 조합은 전환이 지원되는 조합이어야 합니다.
-
에 설명된 대로 모든 요구 사항 및 케이블 연결을 충족해야 합니다 "패브릭 연결 MetroCluster 설치 및 구성".
-
새 컨트롤러와 함께 제공된 새 스토리지 쉘프(node_A_1-IP, node_A_2-IP, node_B_1-IP 및 node_B_2-IP)는 이전 컨트롤러(node_A_1-FC 및 node_B_1-FC)에서 지원되어야 합니다.
-
이전 스토리지 쉘프는 새로운 MetroCluster IP 플랫폼 모델에서 지원되지 * 않습니다.
-
기존 쉘프에서 사용 가능한 스페어 디스크에 따라 추가 드라이브를 추가해야 합니다.
추가 드라이브 쉘프가 필요할 수 있습니다.
각 컨트롤러에 대해 14~18개의 드라이브를 추가해야 합니다.
-
3개의 pool0 드라이브
-
풀 1 드라이브 3개
-
스페어 드라이브 2개
-
시스템 볼륨용 드라이브 6개~10개
-
-
새 노드를 포함한 구성이 드라이브 수, 루트 애그리게이트 크기 용량 등을 포함하여 구성에 대한 플랫폼 제한을 초과하지 않도록 해야 합니다
이 정보는 _NetApp Hardware Universe_의 각 플랫폼 모델에 대해 제공됩니다.
-
절차에 따라 MetroCluster 사이트에서 6개 노드 모두에 대해 원격 콘솔 액세스 권한이 있거나 사이트 간 이동 계획이 있어야 합니다.
새로운 컨트롤러가 쉘프를 지원하지 않을 경우 운영 중단 전환을 위한 워크플로우
기존 쉘프 모델이 새 플랫폼 모델에서 지원되지 않는 경우 새 쉘프를 이전 구성에 연결하고, 데이터를 새 쉘프로 이동한 다음, 새 구성으로 전환해야 합니다.
전환을 준비할 때 사이트 간 여행을 계획하십시오. 원격 노드가 랙에 설치되고 케이블이 연결된 후에는 노드에 대한 직렬 터미널 액세스가 필요합니다. 노드가 구성될 때까지 서비스 프로세서 액세스를 사용할 수 없습니다.
새 컨트롤러 모듈 준비
새 컨트롤러 모듈과 새 스토리지 쉘프의 구성 및 디스크 소유권을 지워야 합니다.
-
새 MetroCluster IP 컨트롤러 모듈에 연결된 새 스토리지 쉘프를 사용하여 의 모든 단계를 수행하십시오 "MetroCluster IP 컨트롤러 준비".
-
새 MetroCluster IP 컨트롤러 모듈에서 새 스토리지 쉘프를 분리합니다.
기존 MetroCluster FC 컨트롤러에 새 디스크 쉘프 연결
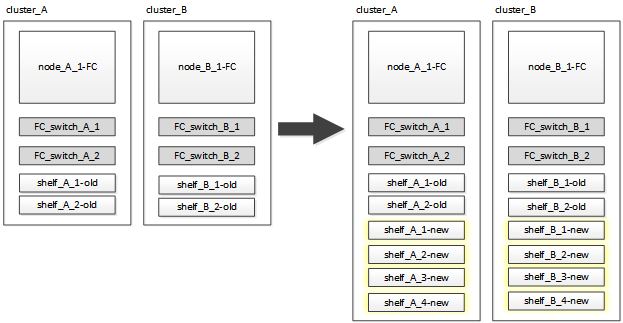
MetroCluster IP 구성으로 전환하기 전에 기존 컨트롤러 모듈에 새 드라이브 쉘프를 연결해야 합니다.
다음 그림에서는 MetroCluster FC 구성에 연결된 새 셸프를 보여 줍니다.
-
node_A_1-FC 및 node_A_2-FC에서 디스크 자동 할당을 해제합니다.
'디스크 옵션 수정 - node_node-name_-autoassign off'
이 명령은 각 노드에서 실행해야 합니다.
노드_A_1-FC 및 노드_B_1-FC에 추가할 셸프를 할당하지 않도록 디스크 자동 할당이 비활성화되었습니다. 전환의 일부로 노드 node_A_1-IP 및 node_B_2-IP에 디스크가 필요하며, 자동 할당이 허용되는 경우 나중에 디스크를 node_A_1-IP 및 node_B_2-IP에 할당하기 전에 디스크 소유권을 제거해야 합니다.
-
필요한 경우 FC-to-SAS 브리지를 사용하여 기존 MetroCluster FC 노드에 새 쉘프를 연결합니다.
의 요구사항 및 절차를 참조하십시오 "MetroCluster FC 구성에 스토리지 핫 추가"
루트 애그리게이트를 마이그레이션하여 데이터를 새 디스크 쉘프로 이동합니다
루트 애그리게이트를 이전 드라이브 쉘프에서 MetroCluster IP 노드에서 사용할 새 드라이브 쉘프로 이동해야 합니다.
이 작업은 기존 노드(node_A_1-FC 및 node_B_1-FC)에서 전환 전에 수행됩니다.
-
컨트롤러 노드_B_1-FC에서 협상된 전환 수행:
MetroCluster 절체
-
환원 애그리게이트를 수행하고 node_B_1-FC에서 복구의 루트 단계를 수정합니다.
'MetroCluster 환원 위상 집계'
MetroCluster 수정 단계 루트 집계
-
부팅 컨트롤러 노드_A_1-FC:
부트 ONTAP
-
새 쉘프의 소유되지 않은 디스크를 컨트롤러 node_A_1-FC의 적절한 풀에 할당합니다.
-
쉘프의 디스크를 식별합니다.
disk show-shelf pool_0_shelf-fields container-type, diskpathname'입니다
Disk show-shelf pool_1_shelf-fields container-type, diskpathname'입니다
-
로컬 노드에서 명령이 실행되도록 로컬 모드 입력:
'로컬 러닝'
-
디스크 할당:
디스크 할당 디스크 1disk2disk3disk… -p 0'입니다
디스크 할당 디스크 4disk5disk6disk… p 1'입니다
-
로컬 모드 종료:
종료
-
-
미러링된 새 애그리게이트를 생성하여 컨트롤러 node_A_1-FC의 새 루트 애그리게이트로 사용:
-
권한 모드를 고급으로 설정합니다.
'et priv advanced'
-
애그리게이트 생성:
'Aggregate create-aggregate new_agr-disklist disk1, disk2, disk3,… mirror-disklist disk4disk5, disk6,… raidtypesame as-existing-root-force-small-aggregate true aggr show -aggregate new_aggr-fields percent-snapshot-space'를 참조하십시오
스냅샷 공간 비율 값이 5% 미만인 경우 5% 이상으로 값을 늘려야 합니다.
'aggr modify new_aggr-percent-snapshot-space 5'
-
권한 모드를 admin으로 다시 설정합니다.
'et priv admin'
-
-
새 Aggregate가 제대로 생성되었는지 확인합니다.
'node run-node local sysconfig -r'
-
노드 및 클러스터 수준 구성 백업을 생성합니다.

전환 중에 백업이 생성될 때 클러스터는 복구 시 전환 상태를 인식합니다. 시스템 구성의 백업 및 업로드가 성공적인지 확인해야 합니다. 이 백업이 없으면 클러스터 간 MetroCluster 구성을 변경할 수 없습니다. -
클러스터 백업을 생성합니다.
'시스템 구성 백업 create-node local-backup-type cluster-backup-name_cluster-backup-name_'
-
클러스터 백업 생성을 확인합니다
job show-id job-idstatus입니다
-
노드 백업을 생성합니다.
'시스템 구성 백업 create-node local-backup-type node-backup-name_node-backup-name_'
-
클러스터 및 노드 백업을 모두 확인합니다.
'시스템 구성 백업 표시
두 백업이 모두 출력에 표시될 때까지 명령을 반복할 수 있습니다.
-
-
백업 복사본을 만듭니다.
백업은 새 루트 볼륨이 부팅될 때 로컬로 손실되기 때문에 별도의 위치에 저장해야 합니다.
FTP나 HTTP 서버로 백업본을 업로드하거나, 'CP' 명령어를 이용하여 백업본을 복사할 수 있다.
프로세스
단계
-
FTP 또는 HTTP 서버로 백업을 업로드합니다 *
-
클러스터 백업을 업로드합니다.
'System configuration backup upload-node local-backup_cluster-backup-name_-destination url
-
노드 백업을 업로드합니다.
'System configuration backup upload-node local-backup_node-backup-name_-destination url
-
보안 복제본을 사용하여 원격 서버에 백업을 복사합니다. *
원격 서버에서 다음 SCP 명령을 사용합니다.
-
클러스터 백업을 복사합니다.
'CP diagnode-mgmt-FC:/mroot/etc/backups/config/cluster-backup-name.7z.
-
노드 백업을 복사합니다.
'sCP diag@node-mgmt-FC:/mroot/etc/backups/config/node-backup-name.7z.
-
-
노드_A_1-FC 중지:
중단점 국지적-무시-quorum-warnings true
-
부팅 노드_A_1-FC를 유지 관리 모드로 전환:
boot_ONTAP maint를 선택합니다
-
유지보수 모드에서 필요에 따라 aggregate를 루트로 설정하십시오.
-
HA 정책을 CFO로 설정:
'aggr options new_aggr ha_policy CFO'
계속 진행하라는 메시지가 나타나면 "예"로 응답하십시오.
Are you sure you want to proceed (y/n)?
-
새 Aggregate를 루트로 설정합니다.
'aggr options new_aggr root'
-
LOADER 프롬프트 중지:
"중지"
-
-
컨트롤러를 부팅하고 시스템 구성을 백업합니다.
새 루트 볼륨이 감지되면 노드가 복구 모드로 부팅됩니다
-
컨트롤러를 부팅합니다.
부트 ONTAP
-
로그인하여 구성을 백업합니다.
로그인하면 다음과 같은 경고가 표시됩니다.
Warning: The correct cluster system configuration backup must be restored. If a backup from another cluster or another system state is used then the root volume will need to be recreated and NGS engaged for recovery assistance.
-
고급 권한 모드 시작:
세트 프리빌리지 고급
-
서버에 클러스터 구성 백업:
서버/cluster-backup-name.7z의 시스템 구성 백업 다운로드 노드 로컬 소스 URL
-
서버에 노드 구성 백업:
서버/node-backup-name.7z의 시스템 구성 백업 다운로드 노드 로컬 소스 URL
-
관리자 모드로 돌아가기:
'Set-Privilege admin'입니다
-
-
클러스터의 상태를 확인합니다.
-
다음 명령을 실행합니다.
'클러스터 쇼'
-
권한 모드를 고급으로 설정합니다.
세트 프리빌리지 고급
-
클러스터 구성 세부 정보를 확인합니다.
'클러스터 링 쇼'
-
관리자 권한 레벨로 돌아갑니다.
'Set-Privilege admin'입니다
-
-
MetroCluster 구성의 운영 모드를 확인하고 MetroCluster 검사를 수행합니다.
-
MetroCluster 구성을 확인하고 운영 모드가 정상인지 확인합니다.
MetroCluster 쇼
-
예상되는 모든 노드가 표시되는지 확인합니다.
'MetroCluster node show'
-
다음 명령을 실행합니다.
'MetroCluster check run
-
MetroCluster 검사 결과를 표시합니다.
MetroCluster 체크 쇼
-
-
컨트롤러 노드_B_1-FC에서 스위치백을 수행합니다.
MetroCluster 스위치백
-
MetroCluster 구성 작동을 확인합니다.
-
MetroCluster 구성을 확인하고 운영 모드가 정상인지 확인합니다.
MetroCluster 쇼
-
MetroCluster 검사를 수행합니다.
'MetroCluster check run
-
MetroCluster 검사 결과를 표시합니다.
MetroCluster 체크 쇼
-
-
볼륨 위치 데이터베이스에 새 루트 볼륨을 추가합니다.
-
권한 모드를 고급으로 설정합니다.
세트 프리빌리지 고급
-
노드에 볼륨을 추가합니다.
'Volume add-other-volumes – node_a_1-FC
-
관리자 권한 레벨로 돌아갑니다.
'Set-Privilege admin'입니다
-
-
이제 볼륨이 표시되고 mroot가 있는지 확인합니다.
-
애그리게이트 표시:
'스토리지 집계 쇼'
-
루트 볼륨에 mroot가 있는지 확인합니다.
'스토리지 집계 표시 필드에 -mroot가 있습니다.
-
볼륨 표시:
'볼륨 쇼'
-
-
System Manager에 대한 액세스를 다시 활성화하려면 새 보안 인증서를 생성하십시오.
'Security certificate create-common-name_name_-type server-size 2048
-
이전 단계를 반복하여 node_A_1-FC가 소유한 쉘프에서 애그리게이트를 마이그레이션합니다.
-
정리를 수행합니다.
이전 루트 볼륨 및 루트 애그리게이트를 제거하려면 node_A_1-FC 및 node_B_1-FC에서 다음 단계를 수행해야 합니다.
-
이전 루트 볼륨 삭제:
'로컬 러닝'
'vol offline old_vol0'
'vol destroy old_vol0'
종료
'volume remove-other-volume-vserver node_name-volume old_vol0'
-
원래 루트 애그리게이트 삭제:
'aggr offline-aggregate old_aggr0_site'
'aggr delete-aggregate old_aggr0_site'
-
-
데이터 볼륨을 새 컨트롤러의 aggregate에 한 번에 하나씩 마이그레이션합니다.
을 참조하십시오 "Aggregate 생성 및 볼륨을 새 노드로 이동"
-
의 모든 단계를 수행하여 이전 쉘프를 제거합니다 "폐기 쉘프가 node_A_1-FC 및 node_A_2-FC에서 이동되었습니다".
구성을 전환하는 중입니다
자세한 전환 절차를 따라야 합니다.
다음 단계에서는 다른 항목으로 이동합니다. 각 항목의 단계를 지정된 순서대로 수행해야 합니다.
-
포트 매핑을 계획합니다.
의 모든 단계를 수행합니다 "MetroCluster FC 노드의 포트를 MetroCluster IP 노드로 매핑".
-
MetroCluster IP 컨트롤러를 준비합니다.
의 모든 단계를 수행합니다 "MetroCluster IP 컨트롤러 준비".
-
MetroCluster 구성의 상태를 확인합니다.
의 모든 단계를 수행합니다 "MetroCluster FC 구성의 상태 확인".
-
기존 MetroCluster FC 노드를 준비하고 제거합니다.
의 모든 단계를 수행합니다 "MetroCluster FC 노드 전환".
-
새 MetroCluster IP 노드를 추가합니다.
의 모든 단계를 수행합니다 "MetroCluster IP 컨트롤러 모듈 연결".
-
새 MetroCluster IP 노드의 전환 및 초기 구성을 완료합니다.
의 모든 단계를 수행합니다 "새 노드 구성 및 전환 완료".