

監査メッセージのフローと保持
 変更を提案
変更を提案
すべての StorageGRID サービスは通常のシステム運用中に監査メッセージを生成します。これらの監査メッセージがStorageGRID システムからにどのように転送されるかを理解しておく必要があります audit.log ファイル。
監査メッセージのフロー
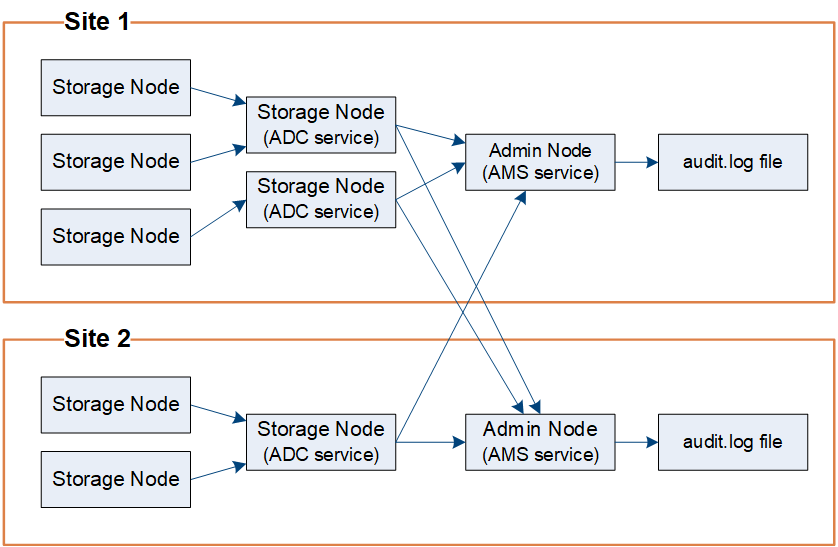
監査メッセージは、管理ノードおよび Administrative Domain Controller ( ADC )サービスが用意されているストレージノードによって処理されます。
監査メッセージのフロー図に示すように、各 StorageGRID ノードは監査メッセージをデータセンターサイトにあるいずれかの ADC サービスに送信します。ADC サービスは、各サイトに設置されている最初の 3 つのストレージノードで自動的に有効になります。
次に、各 ADC サービスはリレーとして機能し、監査メッセージの集合を StorageGRID システム内のすべての管理ノードに送信します。これにより、システムアクティビティの完全な記録が各管理ノードに提供されます。
各管理ノードでは、監査メッセージがテキストログファイルに保存されます。アクティブなログファイルの名前はです audit.log。
監査メッセージの保持
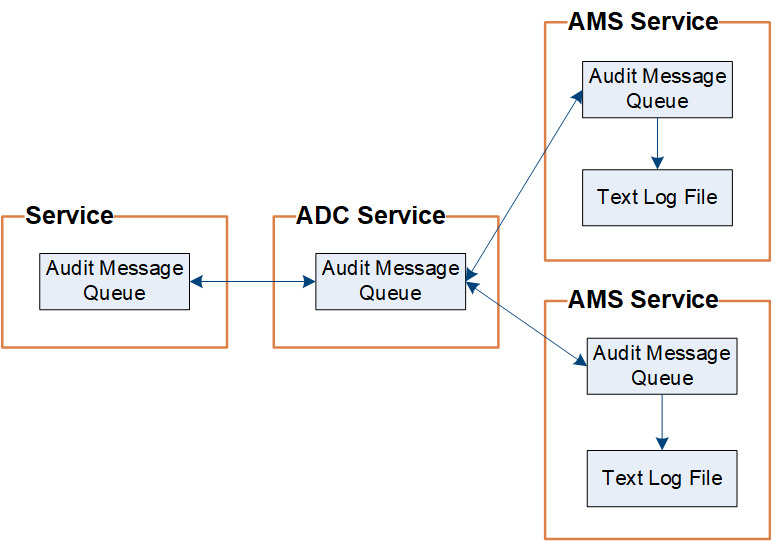
StorageGRID では、コピー / 削除プロセスを使用して、監査ログに書き込まれる前に監査メッセージが失われないようにします。
ノードが生成またはリレーした監査メッセージは、グリッドノードのシステムディスク上の監査メッセージキューに格納されます。メッセージが管理ノード内の監査ログファイルに書き込まれるまで、メッセージのコピーは常に監査メッセージキューに保持されます /var/local/audit/export ディレクトリ。これにより、監査メッセージが転送中に失われることはありません。
ネットワーク接続の問題または監査容量の不足が原因で、監査メッセージキューが一時的に増加する可能性があります。キューが増加すると、各ノードの使用可能スペースがキューによってさらに消費されます /var/local/ ディレクトリ。問題 が解除されず、ノードの監査メッセージディレクトリがいっぱいになると、個々のノードがバックログの処理の優先順位を設定し、一時的に新しいメッセージに使用できなくなります。
具体的には、次のような動作が発生することがあります。
-
状況に応じて
/var/local/audit/export管理ノードで使用されるディレクトリがいっぱいになると、ディレクトリに空きが出るまでその管理ノードを新しい監査メッセージに使用できないことを示すフラグが設定されます。S3 および Swift クライアント要求には影響しません。監査リポジトリにアクセスできない場合に XAMS ( Unreachable Audit Repositories )アラームがトリガーされます。 -
状況に応じて
/var/local/ADCサービスを採用するストレージノードで使用されるディレクトリが92%フルになると、ディレクトリが87%フルになるまでそのノードを監査メッセージに使用できないことを示すフラグが設定されます。他のノードに対する S3 および Swift クライアント要求には影響しません。監査リレーにアクセスできない場合に NRLY ( Available Audit Relays )アラームがトリガーされます。
ADCサービスを採用するストレージノードがない場合は、ストレージノードが監査メッセージをローカルに格納します。 -
状況に応じて
/var/local/ストレージノードで使用されるディレクトリが85%フルになると、ノードはS3およびSwiftクライアントの要求を拒否し始めます503 Service Unavailable。
原因 監査メッセージキューが大幅に増加すると、次のような問題が発生する可能性があります。
-
管理ノードまたは ADC サービスを採用するストレージノードの停止。システムのいずれかのノードが停止すると、残りのノードはバックログ状態になる可能性があります。
-
システムの監査キャパシティを超えるアクティビティ率の継続。
-
。
/var/local/監査メッセージには関連のない理由でADCストレージノード上ののスペースがいっぱいになる。この場合、ノードは新しい監査メッセージの受け入れを停止し、現在のバックログの優先順位を設定します。これにより、他のノードで原因 バックログが発生する可能性があります。
Large audit queue アラートと Audit Messages Queued ( AMQS )アラーム
時間の経過に伴う監査メッセージキューのサイズを監視できるように、ストレージノードキューまたは管理ノードキュー内のメッセージの数が特定のしきい値に達すると、 * Large audit queue * アラートと従来の AMQS アラームがトリガーされます。
「 Large audit queue * 」アラートまたは従来の AMQS アラームがトリガーされた場合は、最初にシステムの負荷を確認します。最近のトランザクションの数が膨大であった場合は、アラートとアラームは時間が経過すると解決するため、無視してかまいません。
アラートまたはアラームが解決せず重大度が上がった場合は、キューサイズのグラフを確認します。数時間から数日にわたって数値が増え続けている場合は、監査の負荷がシステムの監査キャパシティを超えている可能性があります。クライアントの書き込みとクライアントの読み取りでエラーまたはオフの監査レベルを変更して、クライアントの処理速度を下げるか、ログに記録される監査メッセージの数を減らしてください。「」を参照"監査メッセージレベルの変更". 」
重複メッセージです
StorageGRID システムは、ネットワークまたはノードの障害が発生した場合に保守的なアプローチを採用します。そのため、監査ログでメッセージが重複する可能性があります。