

Kubernetes 모니터링 운영자 설치 및 구성
 변경 제안
변경 제안
Data Infrastructure Insights Kubernetes 컬렉션을 위한 *Kubernetes Monitoring Operator*를 제공합니다. 새로운 운영자를 배포하려면 *Kubernetes > Collectors > +Kubernetes Collector*로 이동합니다.
Kubernetes Monitoring Operator를 설치하기 전에
를 참조하십시오"필수 조건" Kubernetes Monitoring Operator를 설치하거나 업그레이드하기 전에 설명서를 참조하세요.
Kubernetes 모니터링 운영자 설치
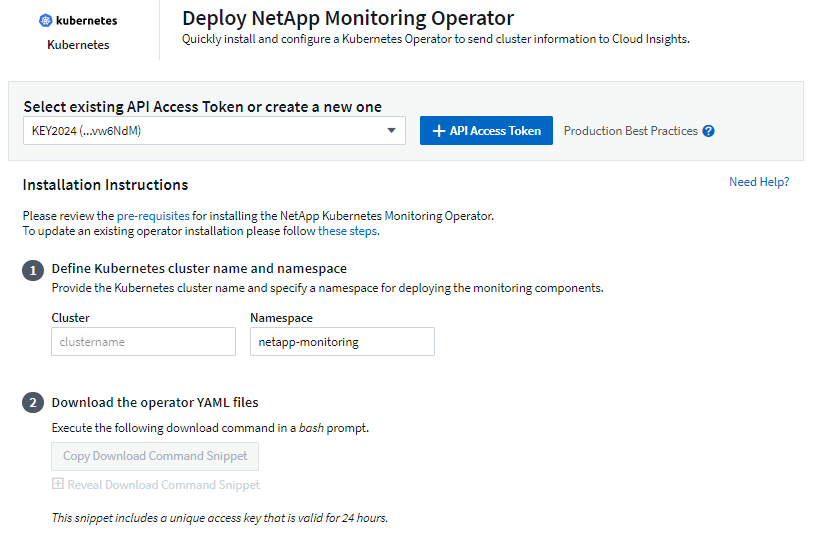
-
고유한 클러스터 이름과 네임스페이스를 입력하세요. 만약 당신이라면업그레이드 이전 Kubernetes Operator에서 동일한 클러스터 이름과 네임스페이스를 사용합니다.
-
이를 입력하면 다운로드 명령 스니펫을 클립보드에 복사할 수 있습니다.
-
스니펫을 bash 창에 붙여넣고 실행합니다. Operator 설치 파일이 다운로드됩니다. 스니펫에는 고유 키가 있으며 24시간 동안 유효합니다.
-
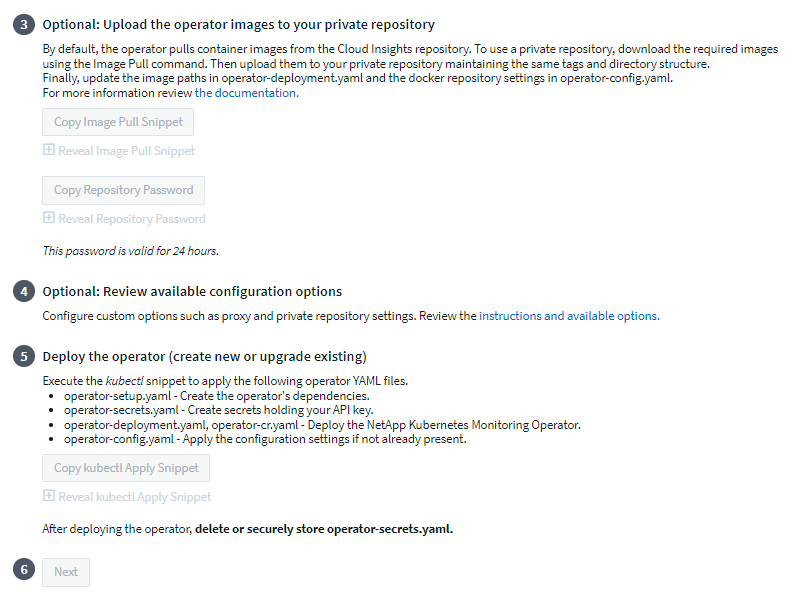
사용자 정의 또는 개인 저장소가 있는 경우 선택 사항인 이미지 풀 스니펫을 복사하여 bash 셸에 붙여넣고 실행합니다. 이미지를 가져온 후 개인 저장소에 복사하세요. 동일한 태그와 폴더 구조를 유지하세요. _operator-deployment.yaml_의 경로와 _operator-config.yaml_의 docker 저장소 설정을 업데이트합니다.
-
원하는 경우 프록시나 개인 저장소 설정 등 사용 가능한 구성 옵션을 검토하세요. 더 자세히 읽어보세요"구성 옵션" .
-
준비가 되면 kubectl Apply 스니펫을 복사하고, 다운로드하고, 실행하여 Operator를 배포합니다.
-
설치가 자동으로 진행됩니다. 완료되면 다음 버튼을 클릭하세요.
-
설치가 완료되면 다음 버튼을 클릭하세요. operator-secrets.yaml 파일도 삭제하거나 안전하게 저장하세요.
사용자 정의 저장소가 있는 경우 다음을 읽어보세요.사용자 정의/개인 Docker 저장소 사용 .
Kubernetes 모니터링 구성 요소
Data Infrastructure Insights Kubernetes Monitoring은 네 가지 모니터링 구성 요소로 구성됩니다.
-
클러스터 메트릭
-
네트워크 성능 및 맵(선택 사항)
-
이벤트 로그(선택 사항)
-
변경 분석(선택 사항)
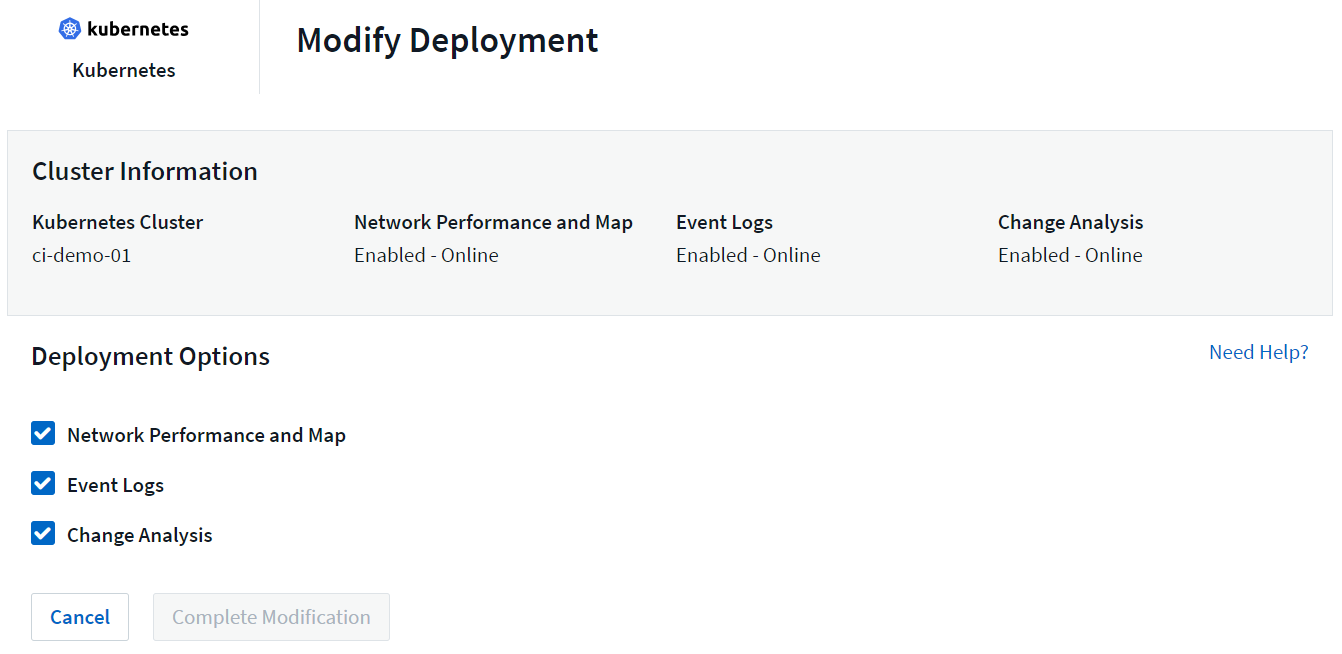
위의 선택적 구성 요소는 각 Kubernetes 수집기에서 기본적으로 활성화됩니다. 특정 수집기에 대한 구성 요소가 필요하지 않다고 판단되면 *Kubernetes > 수집기*로 이동하여 화면 오른쪽에 있는 수집기의 "세 개의 점" 메뉴에서 _배포 수정_을 선택하여 해당 구성 요소를 비활성화할 수 있습니다.
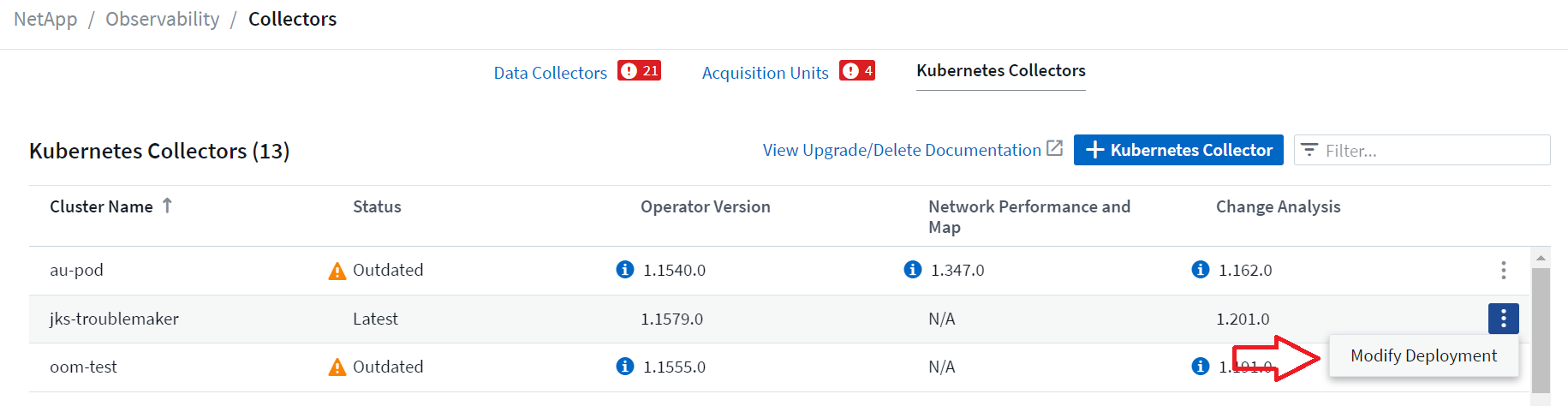
화면에는 각 구성 요소의 현재 상태가 표시되며 필요에 따라 해당 수집기의 구성 요소를 비활성화하거나 활성화할 수 있습니다.
최신 Kubernetes Monitoring Operator로 업그레이드
DII 푸시 버튼 업그레이드
DII Kubernetes Collectors 페이지를 통해 Kubernetes Monitoring Operator를 업그레이드할 수 있습니다. 업그레이드하려는 클러스터 옆에 있는 메뉴를 클릭하고 _업그레이드_를 선택하세요. 운영자는 이미지 서명을 확인하고, 현재 설치의 스냅샷을 촬영한 후 업그레이드를 수행합니다. 몇 분 안에 운영자 상태가 업그레이드 진행 중에서 최신으로 바뀌는 것을 볼 수 있습니다. 오류가 발생하면 오류 상태를 선택하여 자세한 내용을 확인하고 아래의 푸시 버튼 업그레이드 문제 해결 표를 참조하세요.

|
1.2057.0 이전 operator 버전에서는 Push-Button 업그레이드를 사용할 수 없습니다. 최신 버전으로 업그레이드하려면 아래의 수동 업그레이드 지침을 따르십시오. 업그레이드 후에는 push-button 업그레이드 기능을 사용하여 향후 업그레이드를 수행할 수 있습니다. |
개인 저장소를 사용한 푸시 버튼 업그레이드
운영자가 개인 저장소를 사용하도록 구성된 경우 운영자를 실행하는 데 필요한 모든 이미지와 해당 서명이 저장소에서 사용 가능한지 확인하세요. 업그레이드 과정에서 누락된 이미지로 인한 오류가 발생하면 해당 이미지를 저장소에 추가한 후 업그레이드를 다시 시도하세요. 이미지 서명을 저장소에 업로드하려면 다음과 같이 공동 서명 도구를 사용하고 3번 선택 사항에서 지정한 모든 이미지에 대한 서명을 업로드해야 합니다. 운영자 이미지를 개인 저장소에 업로드 > 이미지 풀 스니펫
cosign copy example.com/src:v1 example.com/dest:v1 #Example cosign copy <DII container registry>/netapp-monitoring:<image version> <private repository>/netapp-monitoring:<image version>
이전에 실행 중이던 버전으로 롤백
푸시 버튼 업그레이드 기능을 사용하여 업그레이드한 후 7일 이내에 현재 버전의 운영자를 사용하는 데 어려움이 발생하는 경우, 업그레이드 프로세스 중에 생성된 스냅샷을 사용하여 이전에 실행 중이던 버전으로 다운그레이드할 수 있습니다. 롤백하려는 클러스터 옆에 있는 메뉴를 클릭하고 _롤백_을 선택합니다.
수동 업그레이드
기존 Operator와 함께 _AgentConfiguration_이 존재하는지 확인합니다(네임스페이스가 기본값인 _netapp-monitoring_이 아닌 경우 적절한 네임스페이스로 대체하십시오):
kubectl -n netapp-monitoring get agentconfiguration netapp-ci-monitoring-configuration _AgentConfiguration_이 존재하는 경우:
-
설치하다기존 연산자보다 최신 연산자가 우선합니다.
-
당신이 있는지 확인하십시오최신 컨테이너 이미지 가져오기 사용자 정의 저장소를 사용하는 경우.
-
_AgentConfiguration_이 존재하지 않는 경우:
-
Data Infrastructure Insights 에서 인식하는 클러스터 이름을 기록해 두세요(네임스페이스가 기본 netapp-monitoring이 아닌 경우 적절한 네임스페이스로 대체하세요).
kubectl -n netapp-monitoring get agent -o jsonpath='{.items[0].spec.cluster-name}' * 기존 Operator의 백업을 만듭니다(네임스페이스가 기본 netapp-monitoring이 아닌 경우 적절한 네임스페이스로 대체).kubectl -n netapp-monitoring get agent -o yaml > agent_backup.yaml * <<to-remove-the-kubernetes-monitoring-operator,제거>>기존 운영자. * <<installing-the-kubernetes-monitoring-operator,설치하다>>최신 운영자.
-
동일한 클러스터 이름을 사용하세요.
-
최신 Operator YAML 파일을 다운로드한 후 배포하기 전에 _agent_backup.yaml_에서 찾은 모든 사용자 지정 항목을 다운로드한 _operator-config.yaml_로 이식합니다.
-
당신이 있는지 확인하십시오최신 컨테이너 이미지 가져오기 사용자 정의 저장소를 사용하는 경우.
-
Kubernetes 모니터링 운영자 중지 및 시작
Kubernetes Monitoring Operator를 중지하려면:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=0 Kubernetes Monitoring Operator를 시작하려면:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=1
제거 중
Kubernetes Monitoring Operator를 제거하려면
Kubernetes Monitoring Operator의 기본 네임스페이스는 "netapp-monitoring"입니다. 고유한 네임스페이스를 설정한 경우 이 명령과 이후의 모든 명령 및 파일에서 해당 네임스페이스를 대체합니다.
다음 명령을 사용하여 모니터링 운영자의 최신 버전을 제거할 수 있습니다.
kubectl -n <NAMESPACE> delete agent -l installed-by=nkmo-<NAMESPACE> kubectl -n <NAMESPACE> delete clusterrole,clusterrolebinding,crd,svc,deploy,role,rolebinding,secret,sa -l installed-by=nkmo-<NAMESPACE>
모니터링 운영자가 자체 전용 네임스페이스에 배포된 경우 네임스페이스를 삭제합니다.
kubectl delete ns <NAMESPACE> 참고: 첫 번째 명령에서 "리소스를 찾을 수 없습니다"라는 메시지가 반환되면 다음 지침에 따라 이전 버전의 모니터링 운영자를 제거하세요.
다음 명령을 순서대로 실행하세요. 현재 설치 환경에 따라 일부 명령은 '개체를 찾을 수 없습니다'라는 메시지를 반환할 수 있습니다. 이런 메시지는 무시해도 됩니다.
kubectl -n <NAMESPACE> delete agent agent-monitoring-netapp kubectl delete crd agents.monitoring.netapp.com kubectl -n <NAMESPACE> delete role agent-leader-election-role kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader <NAMESPACE>-agent-manager-role <NAMESPACE>-agent-proxy-role <NAMESPACE>-cluster-role-privileged kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding <NAMESPACE>-agent-manager-rolebinding <NAMESPACE>-agent-proxy-rolebinding <NAMESPACE>-cluster-role-binding-privileged kubectl delete <NAMESPACE>-psp-nkmo kubectl delete ns <NAMESPACE>
이전에 보안 컨텍스트 제약 조건이 생성된 경우:
kubectl delete scc telegraf-hostaccess
Kube-state-metrics에 대하여
NetApp Kubernetes Monitoring Operator는 다른 인스턴스와의 충돌을 피하기 위해 자체 kube-state-metrics를 설치합니다.
Kube-State-Metrics에 대한 정보는 다음을 참조하세요."이 페이지" .
운영자 구성/사용자 정의
이 섹션에는 운영자 구성 사용자 정의, 프록시 작업, 사용자 정의 또는 개인 Docker 저장소 사용, OpenShift 작업 등에 대한 정보가 포함되어 있습니다.
구성 옵션
가장 일반적으로 수정되는 설정은 AgentConfiguration 사용자 정의 리소스에서 구성할 수 있습니다. operator-config.yaml 파일을 편집하여 운영자를 배포하기 전에 이 리소스를 편집할 수 있습니다. 이 파일에는 주석 처리된 설정 예가 포함되어 있습니다. 목록을 확인하세요"사용 가능한 설정" 최신 버전의 연산자에 대해서.
다음 명령을 사용하여 운영자가 배포된 후에도 이 리소스를 편집할 수 있습니다.
kubectl -n netapp-monitoring edit AgentConfiguration 배포된 운영자 버전이 _AgentConfiguration_을 지원하는지 확인하려면 다음 명령을 실행하십시오:
kubectl get crd agentconfigurations.monitoring.netapp.com "서버 오류(찾을 수 없음)" 메시지가 표시되면 AgentConfiguration을 사용하려면 먼저 운영자를 업그레이드해야 합니다.
프록시 지원 구성
테넌트에 프록시를 사용하여 Kubernetes Monitoring Operator를 설치할 수 있는 두 곳이 있습니다. 이는 동일하거나 별도의 프록시 시스템일 수 있습니다.
-
설치 코드 조각을 실행하는 동안 필요한 프록시("curl" 사용)는 조각이 실행되는 시스템을 Data Infrastructure Insights 환경에 연결합니다.
-
대상 Kubernetes 클러스터가 Data Infrastructure Insights 환경과 통신하는 데 필요한 프록시
이 두 가지 중 하나 또는 둘 다에 프록시를 사용하는 경우 Kubernetes Operating Monitor를 설치하려면 먼저 프록시가 Data Infrastructure Insights 환경과의 원활한 통신을 허용하도록 구성되어 있는지 확인해야 합니다. 프록시가 있고 Operator를 설치하려는 서버/VM에서 Data Infrastructure Insights 에 액세스할 수 있는 경우 프록시가 올바르게 구성된 것일 가능성이 높습니다.
Kubernetes Operating Monitor를 설치하는 데 사용되는 프록시의 경우, Operator를 설치하기 전에 http_proxy/https_proxy 환경 변수를 설정하세요. 일부 프록시 환경에서는 _no_proxy 환경 변수를 설정해야 할 수도 있습니다.
변수를 설정하려면 Kubernetes Monitoring Operator를 설치하기 전에 시스템에서 다음 단계를 수행하세요.
-
현재 사용자에 대해 https_proxy 및/또는 http_proxy 환경 변수를 설정합니다.
-
설정 중인 프록시에 인증(사용자 이름/비밀번호)이 없는 경우 다음 명령을 실행합니다.
export https_proxy=<proxy_server>:<proxy_port> .. 설정 중인 프록시에 인증(사용자 이름/비밀번호)이 있는 경우 다음 명령을 실행하세요.
export http_proxy=<proxy_username>:<proxy_password>@<proxy_server>:<proxy_port>
-
Kubernetes 클러스터가 Data Infrastructure Insights 환경과 통신하는 데 사용되는 프록시의 경우, 이 지침을 모두 읽은 후 Kubernetes Monitoring Operator를 설치하세요.
Kubernetes 모니터링 오퍼레이터를 배포하기 전에 operator-config.yaml_의 _AgentConfiguration 프록시 섹션을 구성하십시오.
agent:
...
proxy:
server: <server for proxy>
port: <port for proxy>
username: <username for proxy>
password: <password for proxy>
# In the noproxy section, enter a comma-separated list of
# IP addresses and/or resolvable hostnames that should bypass
# the proxy
noproxy: <comma separated list>
isTelegrafProxyEnabled: true
isFluentbitProxyEnabled: <true or false> # true if Events Log enabled
isCollectorsProxyEnabled: <true or false> # true if Network Performance and Map enabled
isAuProxyEnabled: <true or false> # true if AU enabled
...
...
사용자 정의 또는 개인 Docker 저장소 사용
기본적으로 Kubernetes Monitoring Operator는 Data Infrastructure Insights 저장소에서 컨테이너 이미지를 가져옵니다. 모니터링 대상으로 Kubernetes 클러스터를 사용하고 해당 클러스터가 사용자 정의 또는 개인 Docker 저장소나 컨테이너 레지스트리에서만 컨테이너 이미지를 가져오도록 구성된 경우 Kubernetes Monitoring Operator에 필요한 컨테이너에 대한 액세스를 구성해야 합니다.
NetApp Monitoring Operator 설치 타일에서 "이미지 풀 스니펫"을 실행합니다. 이 명령은 Data Infrastructure Insights 저장소에 로그인하고, 운영자에 대한 모든 이미지 종속성을 끌어오고, Data Infrastructure Insights 저장소에서 로그아웃합니다. 메시지가 표시되면 제공된 저장소 임시 비밀번호를 입력하세요. 이 명령은 옵션 기능을 포함하여 운영자가 사용하는 모든 이미지를 다운로드합니다. 이 이미지가 어떤 기능에 사용되는지 아래에서 확인하세요.
핵심 운영자 기능 및 Kubernetes 모니터링
-
넷앱 모니터링
-
ci-kube-rbac-프록시
-
ci-ksm
-
ci-텔레그라프
-
distroless-root-user
이벤트 로그
-
ci-fluent-bit
-
ci-kubernetes-이벤트-내보내기
네트워크 성능 및 맵
-
ci-net-observer
변화 분석
-
ci-k8s-change-observer
회사 정책에 따라 운영자 Docker 이미지를 개인/로컬/엔터프라이즈 Docker 저장소에 푸시합니다. 저장소에 있는 이미지 태그와 해당 이미지의 디렉토리 경로가 Data Infrastructure Insights 저장소의 이미지 태그와 디렉토리 경로와 일치하는지 확인하세요.
operator-deployment.yaml에서 monitoring-operator 배포를 편집하고 모든 이미지 참조를 수정하여 개인 Docker 저장소를 사용합니다.
image: <docker repo of the enterprise/corp docker repo>/ci-kube-rbac-proxy:<ci-kube-rbac-proxy version> image: <docker repo of the enterprise/corp docker repo>/netapp-monitoring:<version>
_operator-config.yaml_의 _AgentConfiguration_을 편집하여 새 docker 리포지토리 위치를 반영하세요. 개인 리포지토리에 대한 새 imagePullSecret을 생성하세요. 자세한 내용은 _https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/_를 참조하세요.
agent: ... # An optional docker registry where you want docker images to be pulled from as compared to CI's docker registry # Please see documentation link here: link:task_config_telegraf_agent_k8s.html#using-a-custom-or-private-docker-repository[Using a custom or private docker repository] dockerRepo: your.docker.repo/long/path/to/test # Optional: A docker image pull secret that maybe needed for your private docker registry dockerImagePullSecret: docker-secret-name
장기 비밀번호용 API 액세스 토큰
일부 환경(예: 프록시 저장소)에는 Data Infrastructure Insights docker 저장소에 대한 장기 암호가 필요합니다. 설치 시 UI에서 제공되는 암호는 24시간 동안만 유효합니다. 이 암호 대신 API 액세스 토큰을 docker 저장소 암호로 사용할 수 있습니다. 이 암호는 API 액세스 토큰이 유효한 동안 유효합니다. 이 용도로 새 API 액세스 토큰을 생성하거나 기존 토큰을 사용할 수 있습니다.
"여기를 읽어보세요" 새 API 액세스 토큰 생성 지침을 참조하십시오.
다운로드한 operator-secrets.yaml 파일에서 기존 API 액세스 토큰을 추출하려면 사용자는 다음을 실행할 수 있습니다.
grep '\.dockerconfigjson' operator-secrets.yaml |sed 's/.*\.dockerconfigjson: //g' |base64 -d |jq
실행 중인 오퍼레이터 설치에서 기존 API Access Token을 추출하려면 다음 명령을 실행하면 됩니다.
kubectl -n netapp-monitoring get secret netapp-ci-docker -o jsonpath='{.data.\.dockerconfigjson}' |base64 -d |jq
OpenShift 지침
OpenShift 4.6 이상 버전을 사용하는 경우, operator-config.yaml 파일의 AgentConfiguration 설정을 수정하여 runPrivileged 설정을 활성화해야 합니다.
# Set runPrivileged to true SELinux is enabled on your kubernetes nodes runPrivileged: true
Openshift는 일부 Kubernetes 구성 요소에 대한 액세스를 차단할 수 있는 추가 보안 수준을 구현할 수 있습니다.
관용과 오염
netapp-ci-telegraf-ds, netapp-ci-fluent-bit-ds, 및 netapp-ci-net-observer-l4-ds DaemonSets는 모든 노드에서 데이터를 올바르게 수집하기 위해 클러스터의 모든 노드에 Pod를 예약해야 합니다. 해당 운영자는 잘 알려진 몇 가지 *오염*을 허용하도록 구성되었습니다. 노드에서 사용자 정의 오염을 구성하여 모든 노드에서 포드가 실행되지 않도록 한 경우 해당 오염에 대한 *허용*을 생성할 수 있습니다."_AgentConfiguration_에서" . 클러스터의 모든 노드에 사용자 정의 테인을 적용한 경우 운영자 포드를 예약하고 실행할 수 있도록 운영자 배포에 필요한 허용 범위도 추가해야 합니다.
Kubernetes에 대해 자세히 알아보기"오염과 관용" .
Kubernetes 모니터링 운영자 이미지 서명 확인
운영자의 이미지와 배포하는 모든 관련 이미지는 NetApp 에서 서명합니다. cosign 도구를 사용하여 설치 전에 이미지를 수동으로 검증하거나 Kubernetes 입장 컨트롤러를 구성할 수 있습니다. 자세한 내용은 다음을 참조하세요."쿠버네티스 문서" .
이미지 서명을 확인하는 데 사용되는 공개 키는 선택 사항: 운영자 이미지를 개인 저장소에 업로드 > 이미지 서명 공개 키 아래의 모니터링 운영자 설치 타일에서 사용할 수 있습니다.
이미지 서명을 수동으로 확인하려면 다음 단계를 수행하세요.
-
이미지 풀 스니펫을 복사하여 실행하세요.
-
메시지가 표시되면 저장소 비밀번호를 복사하여 입력하세요.
-
이미지 서명 공개 키(예시에서는 dii-image-signing.pub)를 저장합니다.
-
공동 서명을 사용하여 이미지를 확인하세요. 다음은 공동 서명 사용의 예입니다.
$ cosign verify --key dii-image-signing.pub --insecure-ignore-sct --insecure-ignore-tlog <repository>/<image>:<tag>
Verification for <repository>/<image>:<tag> --
The following checks were performed on each of these signatures:
- The cosign claims were validated
- The signatures were verified against the specified public key
[{"critical":{"identity":{"docker-reference":"<repository>/<image>"},"image":{"docker-manifest-digest":"sha256:<hash>"},"type":"cosign container image signature"},"optional":null}]
문제 해결
Kubernetes Monitoring Operator를 설정하는 데 문제가 발생하면 다음을 시도해 보세요.
| 문제: | 다음을 시도해 보세요: |
|---|---|
Kubernetes 영구 볼륨과 해당 백엔드 스토리지 장치 사이에 하이퍼링크/연결이 보이지 않습니다. 내 Kubernetes 영구 볼륨은 스토리지 서버의 호스트 이름을 사용하여 구성됩니다. |
기존 Telegraf 에이전트를 제거하는 단계를 따른 다음, 최신 Telegraf 에이전트를 다시 설치합니다. Telegraf 버전 2.0 이상을 사용해야 하며, Kubernetes 클러스터 스토리지는 Data Infrastructure Insights 에서 적극적으로 모니터링되어야 합니다. |
로그에서 다음과 유사한 메시지가 표시됩니다. E0901 15:21:39.962145 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: *v1.MutatingWebhookConfiguration을 나열하는 데 실패했습니다. 서버가 요청한 리소스를 찾을 수 없습니다. E0901 15:21:43.168161 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: *v1.Lease를 나열하는 데 실패했습니다. 서버가 요청한 리소스를 찾을 수 없습니다(get leases.coordination.k8s.io) 등. |
Kubernetes 버전이 1.20 미만인 경우 kube-state-metrics 버전 2.0.0 이상을 실행하는 경우 이러한 메시지가 나타날 수 있습니다. Kubernetes 버전을 가져오려면: kubectl version kube-state-metrics 버전을 가져오려면: kubectl get deploy/kube-state-metrics -o jsonpath='{..image}' 이러한 메시지가 발생하지 않도록 하려면 사용자는 kube-state-metrics 배포를 수정하여 다음 임대를 비활성화할 수 있습니다. mutatingwebhookconfigurations validatingwebhookconfigurations volumeattachments resources 보다 구체적으로 다음 CLI 인수를 사용할 수 있습니다. resources=certificatesigningrequests, configmaps, cronjobs, daemonsets, deployments,endpoints,horizontalpodautoscalers, ingresses, jobs, limitranges, namespaces, networkpolicies, nodes, persistentvolumeclaims, persistentvolumes, poddisruptionbudgets, pods,replicasets,replicationcontrollers,resourcequotas, secrets,services,statefulsets,storageclasses 기본 리소스 목록은 다음과 같습니다. "certificatesigningrequests, configmaps, cronjobs, daemonsets, deployments, endpoints, horizontalpodautoscalers, ingresses, jobs, leases, limitranges, mutatingwebhookconfigurations, namespaces, networkpolicies, nodes, persistentvolumeclaims, persistentvolumes, poddisruptionbudgets, pods, replicasets, replicationcontrollers, resourcequotas, secrets, services,statefulsets,storageclasses, validatingwebhookconfigurations,volumeattachments" |
Telegraf에서 다음과 유사한 오류 메시지가 표시되지만 Telegraf는 시작되고 실행됩니다. 10월 11일 14:23:41 ip-172-31-39-47 systemd[1]: InfluxDB에 메트릭을 보고하기 위한 플러그인 기반 서버 에이전트가 시작되었습니다. 10월 11일 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="캐시 디렉토리를 생성하지 못했습니다. /etc/telegraf/.cache/snowflake, err: mkdir /etc/telegraf/.ca che: 권한이 거부되었습니다. 무시되었습니다.\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" 10월 11일 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="열지 못했습니다. 무시됨. open /etc/telegraf/.cache/snowflake/ocsp_response_cache.json: 해당 파일이나 디렉토리가 없습니다.\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" 10월 11일 14:23:41 ip-172-31-39-47 telegraf[1827]: 2021-10-11T14:23:41Z 나! Telegraf 1.19.3 시작하기 |
이는 알려진 문제입니다. 참조하다"이 GitHub 문서" 자세한 내용은. Telegraf가 실행되는 동안 사용자는 이러한 오류 메시지를 무시할 수 있습니다. |
Kubernetes에서 Telegraf 포드가 다음 오류를 보고합니다. "마운트 통계 정보 처리 중 오류 발생: 마운트 통계 파일(/hostfs/proc/1/mountstats)을 열 수 없습니다. 오류: /hostfs/proc/1/mountstats를 엽니다. 권한이 거부되었습니다." |
SELinux가 활성화되어 있고 적용되어 있는 경우 Telegraf 포드가 Kubernetes 노드의 /proc/1/mountstats 파일에 액세스하지 못할 가능성이 높습니다. 이러한 제한을 극복하려면 에이전트 구성을 편집하고 runPrivileged 설정을 활성화하세요. 자세한 내용은 OpenShift 지침을 참조하세요. |
Kubernetes에서 Telegraf ReplicaSet 포드가 다음 오류를 보고합니다. [inputs.prometheus] 플러그인 오류: 키 쌍 /etc/kubernetes/pki/etcd/server.crt:/etc/kubernetes/pki/etcd/server.key를 로드할 수 없습니다. /etc/kubernetes/pki/etcd/server.crt를 엽니다. 해당 파일이나 디렉토리가 없습니다. |
Telegraf ReplicaSet 포드는 마스터 또는 etcd로 지정된 노드에서 실행되도록 설계되었습니다. 이러한 노드 중 하나에서 ReplicaSet 포드가 실행되고 있지 않으면 이러한 오류가 발생합니다. 마스터/etcd 노드에 오염이 있는지 확인하세요. 그렇다면 Telegraf ReplicaSet, telegraf-rs에 필요한 허용 범위를 추가합니다. 예를 들어, ReplicaSet을 편집합니다… kubectl edit rs telegraf-rs …그리고 사양에 적절한 허용 범위를 추가합니다. 그런 다음 ReplicaSet 포드를 다시 시작합니다. |
저는 PSP/PSA 환경을 사용하고 있습니다. 이것이 모니터링 운영자에게 영향을 미칩니까? |
Kubernetes 클러스터가 Pod 보안 정책(PSP) 또는 Pod 보안 승인(PSA)을 적용하여 실행되는 경우 최신 Kubernetes 모니터링 운영자로 업그레이드해야 합니다. PSP/PSA를 지원하는 현재 운영자로 업그레이드하려면 다음 단계를 따르세요. 1. 제거 이전 모니터링 연산자: kubectl delete agent agent-monitoring-netapp -n netapp-monitoring kubectl delete ns netapp-monitoring kubectl delete crd agents.monitoring.netapp.com kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding 2. 설치하다 모니터링 운영자의 최신 버전입니다. |
Operator를 배포하려고 하다가 문제가 발생했고, PSP/PSA를 사용 중입니다. |
1. 다음 명령을 사용하여 에이전트를 편집합니다: kubectl -n <네임스페이스> edit agent 2. 'security-policy-enabled'를 'false'로 표시합니다. 이렇게 하면 Pod 보안 정책과 Pod 보안 입장이 비활성화되고 운영자가 배포할 수 있습니다. 다음 명령을 사용하여 확인하세요. kubectl get psp(Pod 보안 정책이 제거되었음을 표시해야 함) kubectl get all -n <네임스페이스> |
grep -i psp(아무것도 발견되지 않았음을 표시해야 함) |
"ImagePullBackoff" 오류가 발생했습니다. |
사용자 지정 또는 비공개 Docker 저장소가 있고 Kubernetes 모니터링 운영자가 해당 저장소를 제대로 인식하도록 아직 구성하지 않은 경우 이러한 오류가 발생할 수 있습니다. 더 읽어보세요 사용자 지정/비공개 저장소 구성에 대한 자세한 내용은 해당 문서를 참조하십시오. |
모니터링 운영자 배포에 문제가 있는데, 현재 문서에서는 이를 해결하는 데 도움이 되지 않습니다. |
다음 명령의 출력을 캡처하거나 기록해 두고 기술 지원팀에 문의하세요. kubectl -n netapp-monitoring get all kubectl -n netapp-monitoring describe all kubectl -n netapp-monitoring logs <monitoring-operator-pod> --all-containers=true kubectl -n netapp-monitoring logs <telegraf-pod> --all-containers=true |
Operator 네임스페이스의 net-observer(워크로드 맵) 포드는 CrashLoopBackOff에 있습니다. |
이러한 포드는 네트워크 관찰을 위한 워크로드 맵 데이터 수집기에 해당합니다. 다음을 시도해 보세요. • 포드 중 하나의 로그를 확인하여 최소 커널 버전을 확인하세요. 예: ---- {"ci-tenant-id":"your-tenant-id","collector-cluster":"your-k8s-cluster-name","environment":"prod","level":"error","msg":"유효성 검사에 실패했습니다. 이유: 커널 버전 3.10.0은 최소 커널 버전 4.18.0보다 낮습니다.","time":"2022-11-09T08:23:08Z"} ---- • Net-observer 포드에는 Linux 커널 버전이 최소 4.18.0이어야 합니다. "uname -r" 명령을 사용하여 커널 버전을 확인하고 버전이 4.18.0 이상인지 확인하세요. |
Pod는 Operator 네임스페이스(기본값: netapp-monitoring)에서 실행되지만 쿼리의 워크로드 맵이나 Kubernetes 메트릭에 대한 데이터가 UI에 표시되지 않습니다. |
K8S 클러스터의 노드에서 시간 설정을 확인하세요. 정확한 감사 및 데이터 보고를 위해서는 NTP(Network Time Protocol) 또는 SNTP(Simple Network Time Protocol)를 사용하여 에이전트 컴퓨터의 시간을 동기화하는 것이 좋습니다. |
Operator 네임스페이스의 일부 net-observer 포드가 보류 상태입니다. |
Net-observer는 DaemonSet이며 k8s 클러스터의 각 노드에서 Pod를 실행합니다. • 보류 상태인 포드를 확인하고 CPU 또는 메모리 리소스 문제가 발생하는지 확인하세요. 노드에서 필요한 메모리와 CPU를 사용할 수 있는지 확인하세요. |
Kubernetes Monitoring Operator를 설치한 직후 로그에 다음과 같은 내용이 표시됩니다. [inputs.prometheus] 플러그인 오류: http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics에 대한 HTTP 요청을 만드는 중 오류가 발생했습니다. http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics를 가져옵니다. tcp 다이얼: kube-state-metrics.<namespace>.svc.cluster.local을 조회합니다. 해당 호스트가 없습니다. |
이 메시지는 일반적으로 새로운 운영자가 설치되고 ksm 포드가 작동하기 전에 telegraf-rs 포드가 작동할 때만 나타납니다. 모든 포드가 실행되면 이러한 메시지는 더 이상 표시되지 않습니다. |
내 클러스터에 있는 Kubernetes CronJob에 대해 수집된 메트릭이 보이지 않습니다. |
Kubernetes 버전을 확인하세요(예: |
운영자를 설치한 후, telegraf-ds 포드가 CrashLoopBackOff에 진입하고 포드 로그에 "su: 인증 실패"가 표시됩니다. |
_AgentConfiguration_에서 telegraf 섹션을 편집하고, _dockerMetricCollectionEnabled_를 false로 설정하세요. 자세한 내용은 operator의 "구성 옵션"를 참조하세요. … spec: … telegraf: … - name: docker run-mode: - DaemonSet substitutions: - key: DOCKER_UNIX_SOCK_PLACEHOLDER value: unix:///run/docker.sock … … |
Telegraf 로그에서 다음과 유사한 오류 메시지가 반복해서 나타납니다. E! [에이전트] outputs.http에 쓰는 중 오류가 발생했습니다. 게시물 "https://<tenant_url>/rest/v1/lake/ingest/influxdb": 컨텍스트 마감일이 초과되었습니다(헤더를 기다리는 동안 Client.Timeout이 초과되었습니다). |
_AgentConfiguration_의 telegraf 섹션을 편집하고 _outputTimeout_을 10초로 늘립니다. 자세한 내용은 운영자에게 문의하세요."구성 옵션" . |
일부 이벤트 로그에 대한 involvedobject 데이터가 없습니다. |
다음 단계를 따랐는지 확인하세요."권한" 위 섹션 참조. |
두 개의 모니터링 운영자 포드가 실행 중인 것을 보는 이유는 무엇입니까? 하나는 netapp-ci-monitoring-operator-<pod>이고 다른 하나는 monitoring-operator-<pod>입니다. |
2023년 10월 12일부터 Data Infrastructure Insights 사용자에게 더 나은 서비스를 제공하기 위해 운영자를 리팩토링했습니다. 이러한 변경 사항을 완전히 적용하려면 다음을 수행해야 합니다.이전 연산자를 제거하세요 그리고새로운 것을 설치하다 . |
내 Kubernetes 이벤트가 예기치 않게 Data Infrastructure Insights 에 보고를 중단했습니다. |
이벤트 내보내기 포드의 이름을 검색합니다. `kubectl -n netapp-monitoring get pods |
grep event-exporter |
awk '{print $1}' |
sed 's/event-exporter./event-exporter/'` |
Kubernetes Monitoring Operator가 배포한 Pod가 리소스가 부족하여 충돌하는 현상이 발생합니다. |
Kubernetes Monitoring Operator를 참조하세요."구성 옵션" 필요에 따라 CPU 및/또는 메모리 한도를 늘립니다. |
이미지가 누락되었거나 구성이 잘못되어 netapp-ci-kube-state-metrics 포드가 시작되지 않거나 준비되지 않았습니다. 이제 StatefulSet이 멈춰 있고 구성 변경 사항이 netapp-ci-kube-state-metrics 포드에 적용되지 않습니다. |
StatefulSet은 다음과 같습니다."고장난" 상태. 모든 구성 문제를 해결한 후 netapp-ci-kube-state-metrics 포드를 반송합니다. |
Kubernetes Operator 업그레이드를 실행한 후 netapp-ci-kube-state-metrics 포드가 시작되지 않고 ErrImagePull(이미지를 가져오는 데 실패) 오류가 발생합니다. |
포드를 수동으로 재설정해보세요. |
Kubernetes 클러스터의 로그 분석에서 "maxEventAgeSeconds보다 오래되어 이벤트가 삭제되었습니다"라는 메시지가 관찰되었습니다. |
Operator agentconfiguration_을 수정하고 _event-exporter-maxEventAgeSeconds(즉, 60초), event-exporter-kubeQPS(즉, 100), event-exporter-kubeBurst(즉, 500)를 늘립니다. 이러한 구성 옵션에 대한 자세한 내용은 다음을 참조하세요."구성 옵션" 페이지. |
Telegraf는 잠글 수 있는 메모리가 부족하여 경고하거나 충돌합니다. |
기본 운영 체제/노드에서 Telegraf의 잠금 가능 메모리 한도를 늘려보세요. 한도를 늘리는 것이 불가능한 경우 NKMO 에이전트 구성을 수정하고 unprotected_를 _true_로 설정하세요. 이렇게 하면 Telegraf는 잠긴 메모리 페이지를 예약하지 않습니다. 복호화된 비밀이 디스크로 옮겨갈 수 있으므로 보안 위험이 발생할 수 있지만, 잠긴 메모리를 예약할 수 없는 환경에서 실행할 수 있습니다. _보호되지 않은 구성 옵션에 대한 자세한 내용은 다음을 참조하세요."구성 옵션" 페이지. |
Telegraf에서 다음과 유사한 경고 메시지를 보았습니다: _W! [inputs.diskio] "vdc"에 대한 디스크 이름을 수집할 수 없습니다. /dev/vdc를 읽는 중 오류가 발생했습니다. 해당 파일이나 디렉토리가 없습니다. |
Kubernetes 모니터링 오퍼레이터의 경우 이러한 경고 메시지는 무해하며 무시해도 됩니다. 또는 AgentConfiguration에서 telegraf 섹션을 편집하고 _runDsPrivileged_를 true로 설정하십시오. 자세한 내용은 "운영자 구성 옵션"을(를) 참조하십시오. |
내 fluent-bit pod가 다음 오류로 인해 실패하고 있습니다. [2024/10/16 14:16:23] [오류] [/src/fluent-bit/plugins/in_tail/tail_fs_inotify.c:360 errno=24] 열려 있는 파일이 너무 많습니다. [2024/10/16 14:16:23] [오류] 입력 tail.0을 초기화하지 못했습니다. [2024/10/16 14:16:23] [오류] [엔진] 입력 초기화에 실패했습니다. |
클러스터에서 fsnotify 설정을 변경해보세요. sudo sysctl fs.inotify.max_user_instances (take note of setting) sudo sysctl fs.inotify.max_user_instances=<something larger than current setting> sudo sysctl fs.inotify.max_user_watches (take note of setting) sudo sysctl fs.inotify.max_user_watches=<something larger than current setting> Fluent-bit를 다시 시작합니다. 참고: 노드 재시작 시에도 이러한 설정을 유지하려면 _/etc/sysctl.conf_에 다음 줄을 넣어야 합니다. fs.inotify.max_user_instances=<something larger than current setting> fs.inotify.max_user_watches=<something larger than current setting> |
Telegraf DS Pod는 TLS 인증서의 유효성을 검사할 수 없어 Kubernetes 입력 플러그인이 HTTP 요청을 수행하지 못한다는 오류를 보고하고 있습니다. 예를 들어: E! [inputs.kubernetes] 플러그인 오류: HTTP 요청을 만드는 중 오류가 발생했습니다."https://<kubelet_IP>:10250/stats/summary": 얻다"https://<kubelet_IP>:10250/stats/summary": tls: 인증서 확인에 실패했습니다: x509: IP SAN이 포함되어 있지 않으므로 <kubelet_IP>에 대한 인증서를 확인할 수 없습니다. |
이는 kubelet이 자체 서명된 인증서를 사용하거나 지정된 인증서에 인증서 Subject Alternative Name 목록에 <kubelet_IP>가 포함되지 않은 경우 발생합니다. 이를 해결하려면 사용자가 다음을 수정할 수 있습니다."에이전트 구성" , _telegraf:insecureK8sSkipVerify_를 _true_로 설정합니다. 이렇게 하면 Telegraf 입력 플러그인이 검증을 건너뛰도록 구성됩니다. 또는 사용자는 kubelet을 구성할 수 있습니다."서버TLS부트스트랩" 그러면 'certificates.k8s.io' API에서 인증서 요청이 트리거됩니다. |
Fluent-bit 포드에서 다음과 같은 오류가 발생하고 포드를 시작할 수 없습니다: 026/01/12 20:20:32] [error] [sqldb] error=unable to open database file [2026/01/12 20:20:32] [error] [input:tail:tail.0] db: could not create 'in_tail_files' table [2026/01/12 20:20:32] [error] [input:tail:tail.0] could not open/create database [2026/01/12 20:20:32] [error] failed initialize input tail.0 [2026/01/12 20:20:32] [error] [engine] input initialization failed |
DB 파일이 있는 호스트 디렉터리에 적절한 읽기/쓰기 권한이 있는지 확인하십시오. 특히, 호스트 디렉터리는 루트가 아닌 사용자에게 읽기/쓰기 권한을 부여해야 합니다. 기본 DB 파일 위치는 fluent-bit-dbFile agentconfiguration 옵션으로 재정의하지 않는 한 /var/log/입니다. SELinux가 활성화된 경우 fluent-bit-seLinuxOptionsType agentconfiguration 옵션을 'spc_t'로 설정해 보십시오. |
Telegraf에서 다음과 유사한 오류 메시지가 표시되지만 Telegraf는 정상적으로 시작되고 실행됩니다. E! [inputs.kubernetes] 플러그인 오류: https://<IP>>:<port>>/pods HTTP 상태 403 Forbidden 반환 |
Kubernetes 버전이 1.33 미만인 경우 이러한 메시지가 나타날 수 있습니다. telegraf에서 사용하는 "nodes/pods" RBAC 리소스가 해당 버전에는 존재하지 않습니다. 이전 버전에서 필요한 RBAC 리소스에 대한 자세한 내용은 operator-additional-permissions.yaml 파일의 "For Kubernetes versions < 1.33" 섹션을 참조하십시오. |
추가 정보는 다음에서 찾을 수 있습니다."지원하다" 페이지 또는"데이터 수집기 지원 매트릭스" .