

Configurar o serviço de integração de pesquisa StorageGRID
 Sugerir alterações
Sugerir alterações
Este guia fornece instruções detalhadas para configurar o serviço de integração de pesquisa do NetApp StorageGRID com o serviço Amazon OpenSearch ou o Elasticsearch no local.
Introdução
O StorageGRID é compatível com três tipos de serviços de plataforma.
-
Replicação do StorageGRID CloudMirror. Espelhe objetos específicos de um bucket do StorageGRID para um destino externo especificado.
-
Notificações. Notificações de eventos por bucket para enviar notificações sobre ações específicas executadas em objetos para um Amazon Simple Notification Service (Amazon SNS) externo especificado.
-
Serviço de integração de pesquisa. Envie metadados de objeto Simple Storage Service (S3) para um índice Elasticsearch especificado, onde você pode pesquisar ou analisar os metadados usando o serviço externo.
Os serviços de plataforma são configurados pelo locatário do S3 por meio da IU do Tenant Manager. Para obter mais informações, "Considerações sobre o uso de serviços de plataforma"consulte .
Este documento serve como um suplemento ao "Guia do Locatário do StorageGRID 11,6" e fornece instruções passo a passo e exemplos para a configuração de endpoint e bucket para serviços de integração de pesquisa. As instruções de configuração do Amazon Web Services (AWS) ou do Elasticsearch no local incluídas aqui são apenas para fins básicos de teste ou demonstração.
Os públicos-alvo devem estar familiarizados com o Gerenciador de Grade, o Gerenciador do Locatário e ter acesso ao navegador S3 para executar operações básicas de upload (PUT) e download (GET) para o teste de integração de pesquisa do StorageGRID.
Crie inquilino e habilite serviços de plataforma
-
Crie um locatário S3 usando o Gerenciador de Grade, insira um nome de exibição e selecione o protocolo S3.
-
Na página permissão, selecione a opção permitir Serviços de Plataforma. Opcionalmente, selecione outras permissões, se necessário.
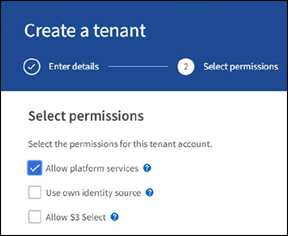
-
Configure a senha inicial do usuário raiz do locatário ou, se a federação identificar estiver habilitada na grade, selecione qual grupo federado tem permissão de acesso raiz para configurar a conta do locatário.
-
Clique em entrar como root e selecione Bucket: Create and Manage Buckets.
Isso o leva à página do Gerenciador de Locações.
-
No Gerenciador do Tenant, selecione Minhas chaves de acesso para criar e baixar a chave de acesso S3 para testes posteriores.
PESQUISE serviços de integração com o Amazon OpenSearch
Configuração do serviço Amazon OpenSearch (anteriormente Elasticsearch)
Use este procedimento para uma configuração rápida e simples do serviço OpenSearch apenas para fins de teste/demonstração. Se você estiver usando o Elasticsearch no local para serviços de integração de pesquisa, consulte a PESQUISE serviços de integração com o Elasticsearch no localseção .

|
Você deve ter um login válido no console da AWS, chave de acesso, chave de acesso secreta e permissão para assinar o serviço OpenSearch. |
-
Crie um novo domínio usando as instruções do "AWS OpenSearch Service Introdução ao AWS OpenSearch Service", exceto o seguinte:
-
Passo 4. Nome de domínio: Sgdemo
-
Passo 10. Controle de acesso refinado: Desmarque a opção Ativar Controle de Acesso fino com Grained.
-
Passo 12. Política de acesso: Selecione Configurar política de acesso de nível, selecione a guia JSON para modificar a política de acesso usando o exemplo a seguir:
-
Substitua o texto realçado pelo seu próprio ID e nome de usuário do AWS Identity and Access Management (IAM).
-
Substitua o texto destacado (o endereço IP) pelo endereço IP público do computador local usado para acessar o console da AWS.
-
Abra uma guia do navegador para "https://checkip.amazonaws.com" encontrar seu IP público.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": {"AWS": "arn:aws:iam:: nnnnnn:user/xyzabc"}, "Action": "es:*", "Resource": "arn:aws:es:us-east-1:nnnnnn:domain/sgdemo/*" }, { "Effect": "Allow", "Principal": {"AWS": "*"}, "Action": [ "es:ESHttp*" ], "Condition": { "IpAddress": { "aws:SourceIp": [ "nnn.nnn.nn.n/nn" ] } }, "Resource": "arn:aws:es:us-east-1:nnnnnn:domain/sgdemo/*" } ] }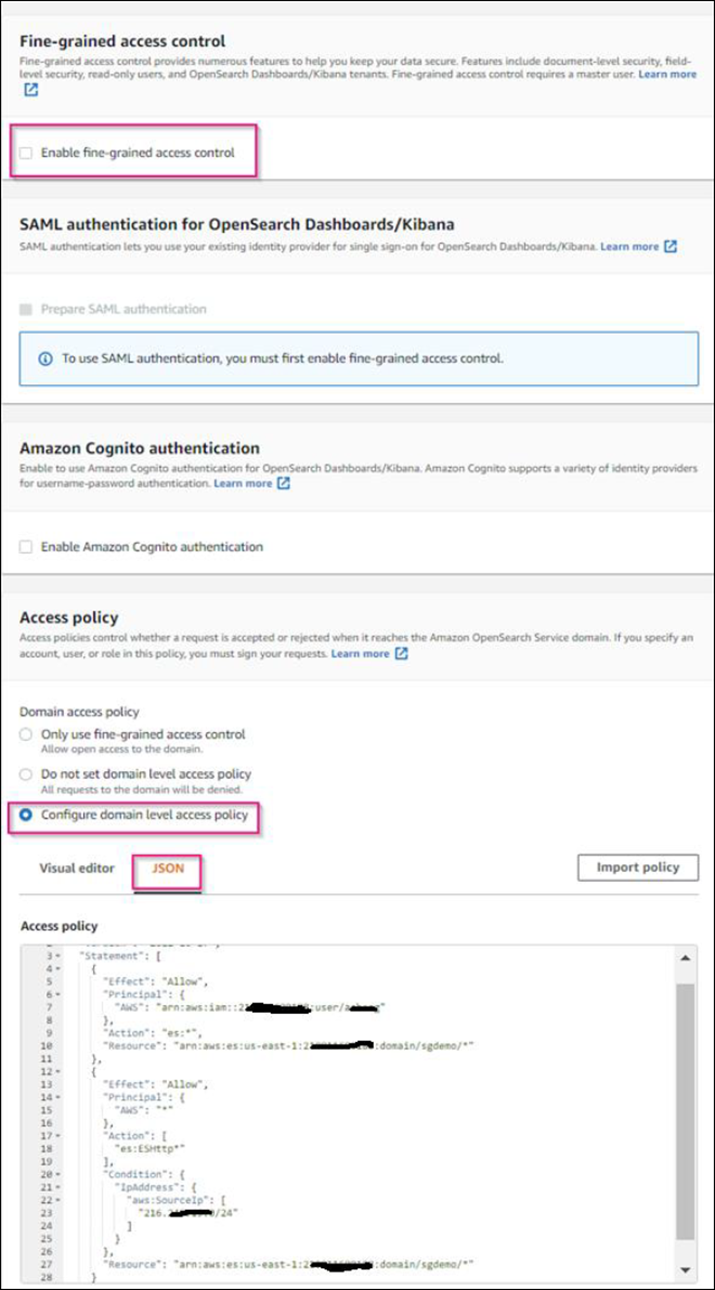
-
-
-
Aguarde de 15 a 20 minutos para que o domínio fique ativo.
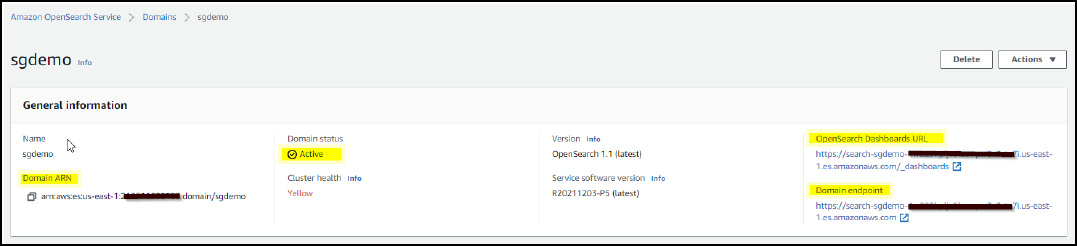
-
Clique em OpenSearch Dashboards URL para abrir o domínio em uma nova guia para acessar o painel. Se você receber um erro de acesso negado, verifique se o endereço IP de origem da diretiva de acesso está corretamente definido para o IP público do computador para permitir o acesso ao painel do domínio.
-
Na página de boas-vindas do painel, selecione explorar por conta própria. No menu, aceda a Gestão → Ferramentas de desenvolvimento
-
Em Ferramentas de desenvolvimento → Console , digite
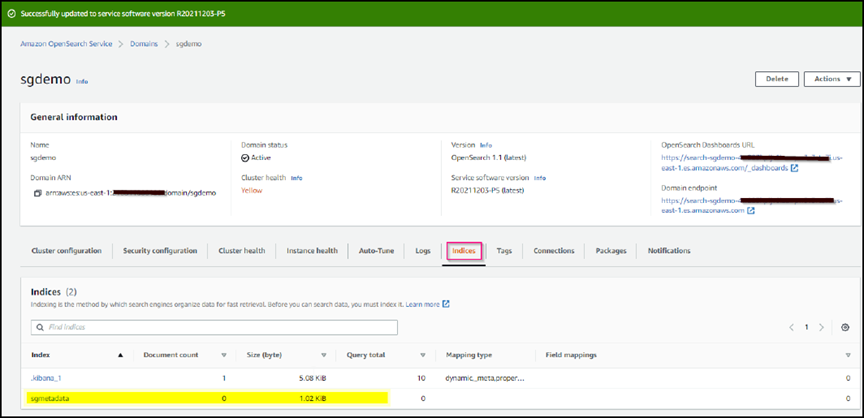
PUT <index>onde você usa o índice para armazenar metadados de objetos StorageGRID. Usamos o nome do índice 'sgmetadata' no exemplo a seguir. Clique no símbolo de triângulo pequeno para executar o comando PUT. O resultado esperado é exibido no painel direito, como mostrado no exemplo de captura de tela a seguir.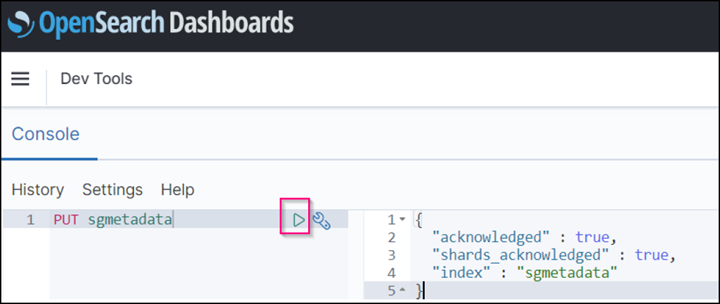
-
Verifique se o índice está visível a partir da IU do Amazon OpenSearch em sgdomain > índices.
Configuração de endpoint de serviços de plataforma
Para configurar os endpoints de serviços da plataforma, siga estas etapas:
-
No Tenant Manager, vá para STORAGE(S3) > endpoints de serviços de plataforma.
-
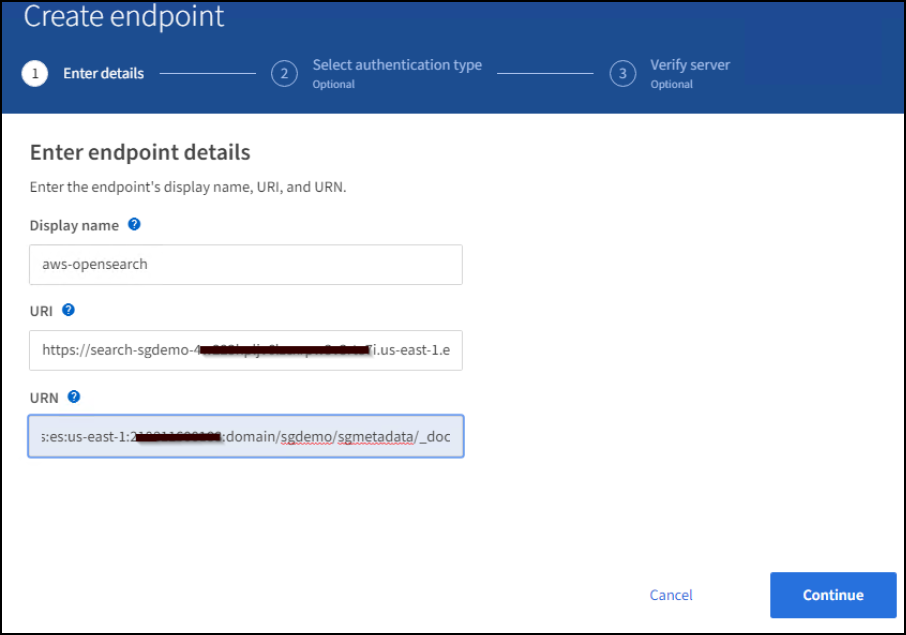
Clique em criar ponto final, introduza o seguinte e, em seguida, clique em continuar:
-
Exemplo de nome de exibição
aws-opensearch -
O endpoint do domínio na captura de tela de exemplo na Etapa 2 do procedimento anterior no campo URI.
-
O ARN de domínio utilizado na Etapa 2 do procedimento anterior no campo URNA e adicione
/<index>/_docao final do ARN.Neste exemplo, A URNA torna
arn:aws:es:us-east-1:211234567890:domain/sgdemo /sgmedata/_doc-se .
-
-
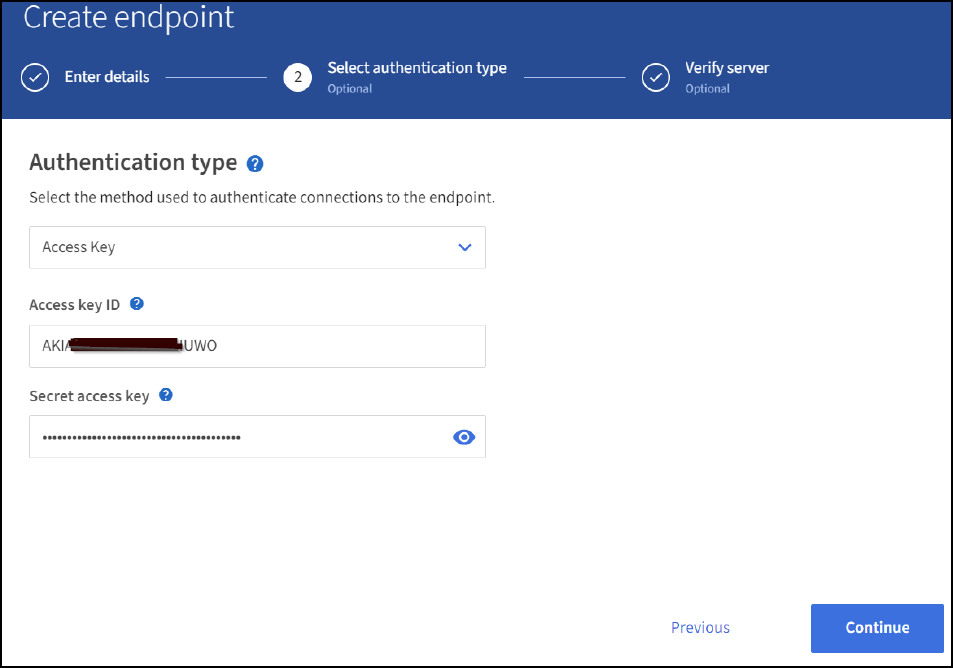
Para acessar o sgdomain do Amazon OpenSearch, escolha chave de acesso como o tipo de autenticação e insira a chave de acesso e chave secreta do Amazon S3. Para ir para a página seguinte, clique em continuar.
-
Para verificar o endpoint, selecione usar certificado e teste da CA do sistema operacional e criar endpoint. Se a verificação for bem-sucedida, é apresentado um ecrã de ponto de extremidade semelhante à figura seguinte. Se a verificação falhar, verifique se a URN inclui no final do caminho e se
/<index>/_doca chave de acesso da AWS e a chave secreta estão corretas.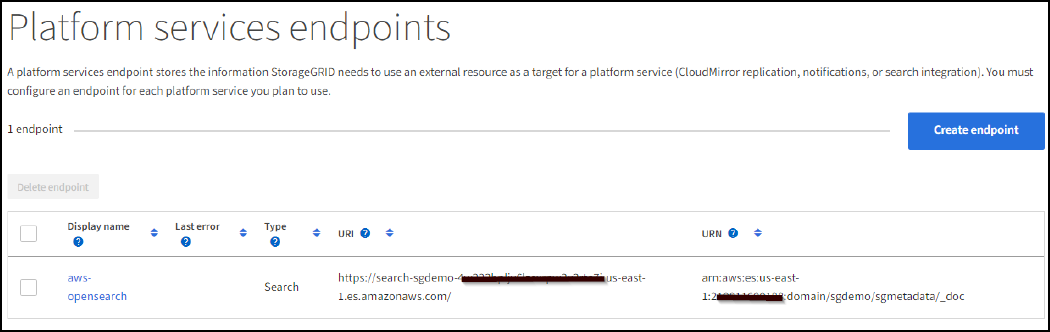
PESQUISE serviços de integração com o Elasticsearch no local
Configuração do Elasticsearch no local
Este procedimento é para uma configuração rápida do Elasticsearch no local e do Kibana usando o docker apenas para fins de teste. Se o servidor Elasticsearch e Kibana já existir, vá para a Etapa 5.
-
Siga isso "Procedimento de instalação do Docker" para instalar o docker. Usamos o "Procedimento de instalação do Docker do CentOS"nesta configuração.
sudo yum install -y yum-utils sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo yum install docker-ce docker-ce-cli containerd.io sudo systemctl start docker
-
Para iniciar o docker após a reinicialização, digite o seguinte:
sudo systemctl enable docker
-
Defina o
vm.max_map_countvalor como 262144:sysctl -w vm.max_map_count=262144
-
Para manter a configuração após a reinicialização, digite o seguinte:
echo 'vm.max_map_count=262144' >> /etc/sysctl.conf
-
-
Siga a "Elasticsearch Guia de início rápido"seção autogerenciada para instalar e executar o Elasticsearch e o Kibana docker. Neste exemplo, instalamos a versão 8,1.

Observação abaixo o nome de usuário/senha e token criados pelo Elasticsearch, você precisa deles para iniciar a autenticação de endpoint da plataforma Kibana UI e StorageGRID. 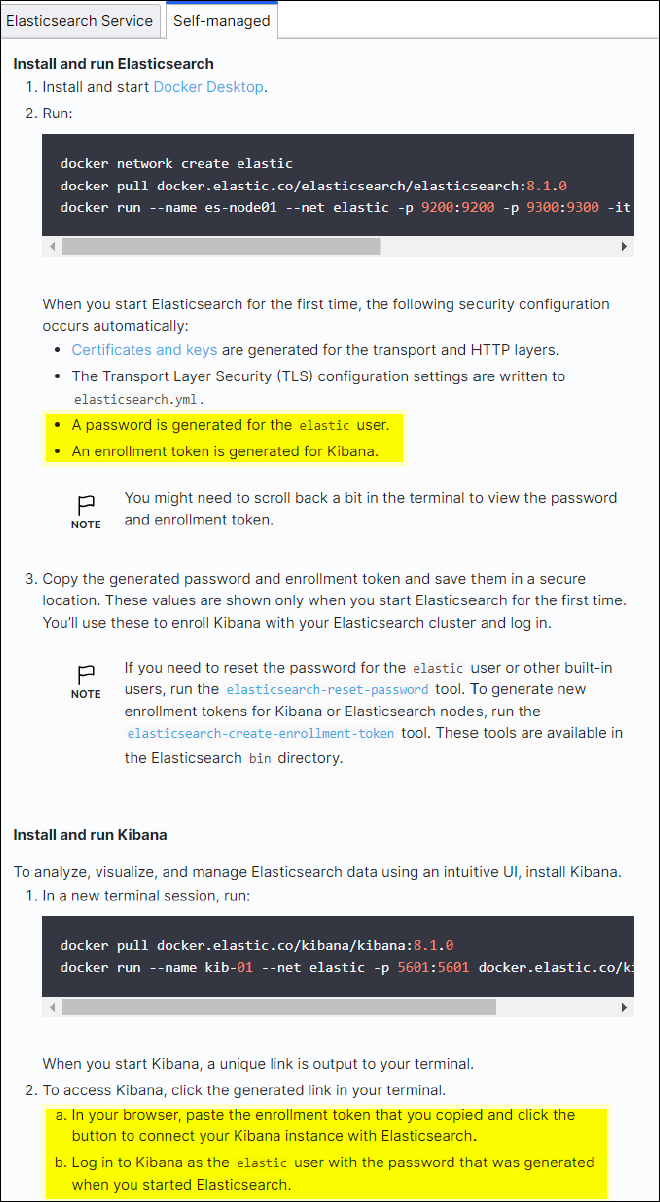
-
Depois que o contentor do Kibana docker for iniciado, o link URL
https://0.0.0.0:5601será exibido no console. Substitua 0.0.0.0 pelo endereço IP do servidor no URL. -
Faça login na IU do Kibana usando o nome de
elasticusuário e a senha gerada pelo Elastic na etapa anterior. -
Para iniciar sessão pela primeira vez, na página de boas-vindas do painel, selecione explorar por conta própria. No menu, selecione Gestão > Ferramentas de desenvolvimento.
-
Na tela Console de Ferramentas de Desenvolvimento, digite
PUT <index>onde você usa esse índice para armazenar metadados de objetos do StorageGRID. Usamos o nome do índicesgmetadataneste exemplo. Clique no símbolo de triângulo pequeno para executar o comando PUT. O resultado esperado é exibido no painel direito, como mostrado no exemplo de captura de tela a seguir.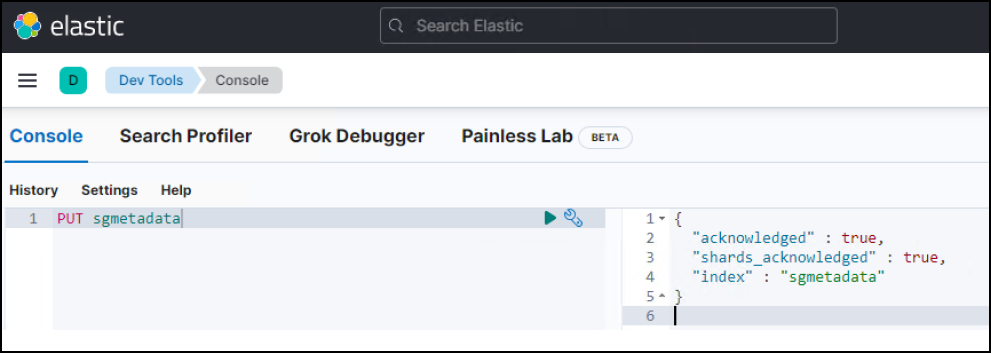
Configuração de endpoint de serviços de plataforma
Para configurar endpoints para serviços de plataforma, siga estas etapas:
-
No Tenant Manager, vá para STORAGE(S3) > endpoints de serviços de plataforma
-
Clique em criar ponto final, introduza o seguinte e, em seguida, clique em continuar:
-
Exemplo de nome de exibição:
elasticsearch -
URI:
https://<elasticsearch-server-ip or hostname>:9200 -
URN:
urn:<something>:es:::<some-unique-text>/<index-name>/_docOnde o nome do índice é o nome que você usou no console do Kibana. Exemplo:urn:local:es:::sgmd/sgmetadata/_doc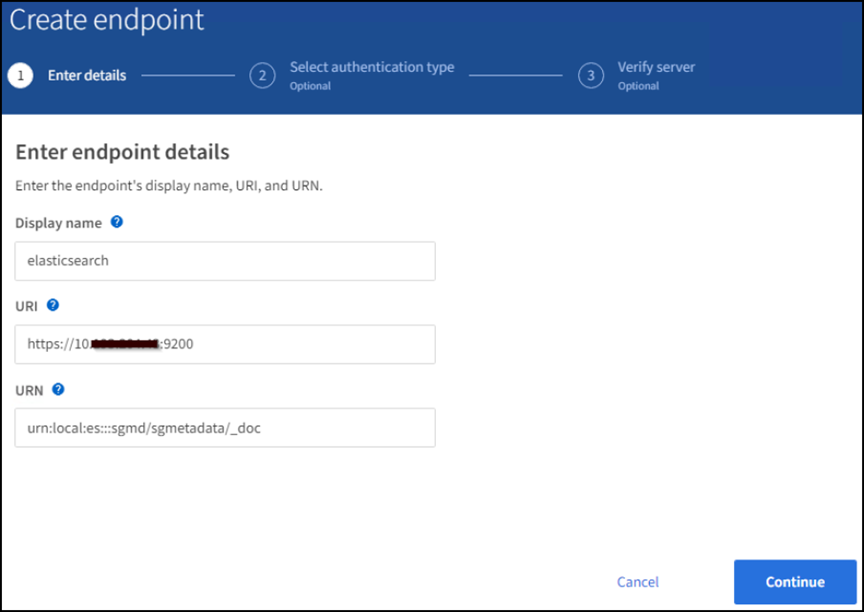
-
-
Selecione HTTP básico como o tipo de autenticação, insira o nome de
elasticusuário e a senha gerados pelo processo de instalação do Elasticsearch. Para ir para a página seguinte, clique em continuar.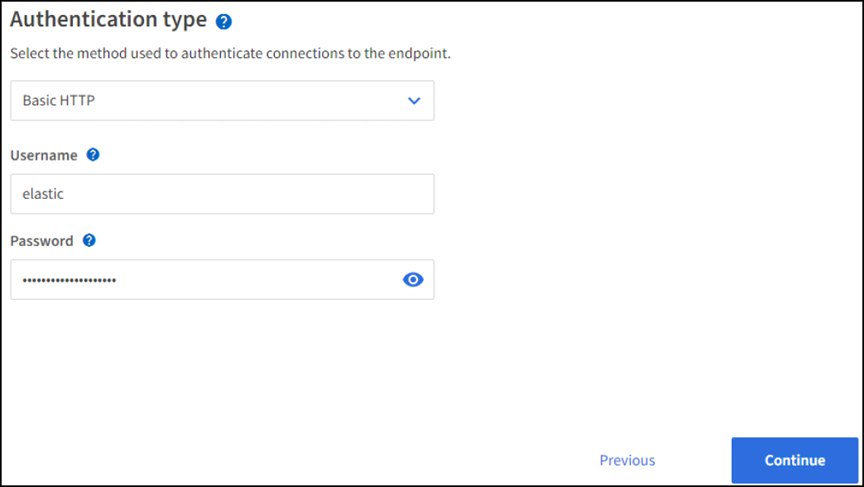
-
Selecione não verificar certificado e teste e criar endpoint para verificar o endpoint. Se a verificação for bem-sucedida, uma tela de ponto final semelhante à seguinte captura de tela é exibida. Se a verificação falhar, verifique se as entradas URN, URI e nome de usuário/senha estão corretas.
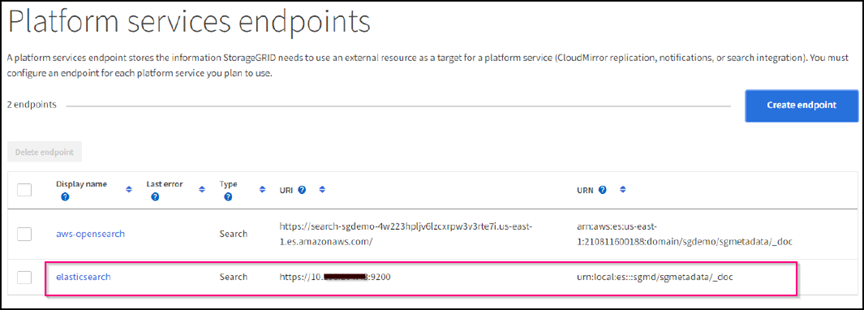
Configuração do serviço de integração de pesquisa de bucket
Depois que o endpoint do serviço da plataforma é criado, a próxima etapa é configurar esse serviço no nível do bucket para enviar metadados de objeto para o endpoint definido sempre que um objeto é criado, excluído ou seus metadados ou tags são atualizados.
Você pode configurar a integração de pesquisa usando o Gerenciador do locatário para aplicar um XML de configuração StorageGRID personalizado a um bucket da seguinte forma:
-
No Tenant Manager, aceda a STORAGE(S3) > baldes
-
Clique em criar balde, introduza o nome do balde (por exemplo,
sgmetadata-test) e aceite a região predefinidaus-east-1. -
Clique em continuar > criar balde.
-
Para abrir a página Visão geral do bucket, clique no nome do bucket e selecione Serviços da plataforma.
-
Selecione a caixa de diálogo Ativar integração de pesquisa. Na caixa XML fornecida, insira o XML de configuração usando essa sintaxe.
A URNA realçada deve corresponder ao endpoint de serviços da plataforma que você definiu. Você pode abrir outra guia do navegador para acessar o Gerenciador do Locatário e copiar a URN do endpoint de serviços da plataforma definido.
Neste exemplo, não usamos nenhum prefixo, o que significa que os metadados de cada objeto neste intervalo são enviados para o endpoint Elasticsearch definido anteriormente.
<MetadataNotificationConfiguration> <Rule> <ID>Rule-1</ID> <Status>Enabled</Status> <Prefix></Prefix> <Destination> <Urn> urn:local:es:::sgmd/sgmetadata/_doc</Urn> </Destination> </Rule> </MetadataNotificationConfiguration> -
Use o navegador S3 para se conetar ao StorageGRID com a chave de acesso do locatário/segredo, carregue objetos de teste para
sgmetadata-testbucket e adicione tags ou metadados personalizados a objetos.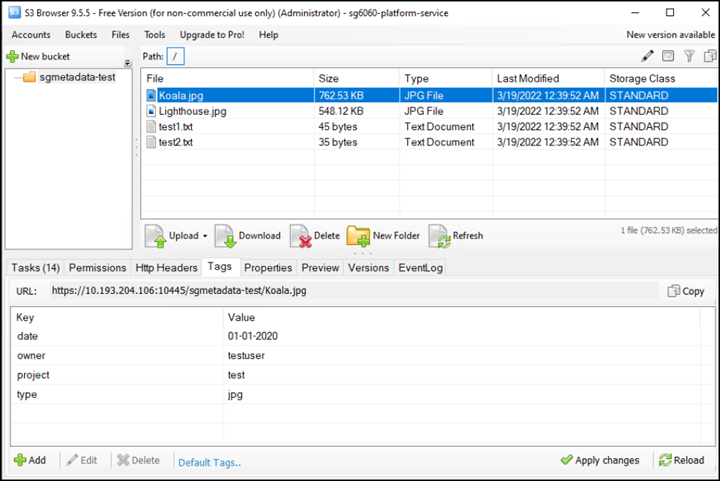
-
Use a IU do Kibana para verificar se os metadados do objeto foram carregados para o índice do sgmetadata.
-
No menu, selecione Gestão > Ferramentas de desenvolvimento.
-
Cole a consulta de exemplo no painel do console à esquerda e clique no símbolo do triângulo para executá-la.
O resultado da amostra da consulta 1 na captura de tela de exemplo a seguir mostra quatro Registros. Isto corresponde ao número de objetos no balde.
GET sgmetadata/_search { "query": { "match_all": { } } }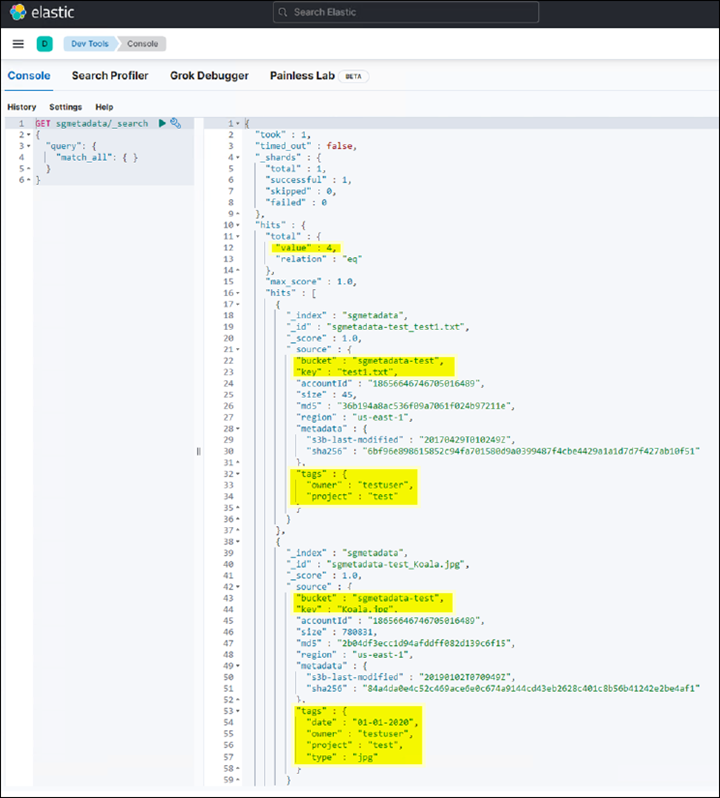
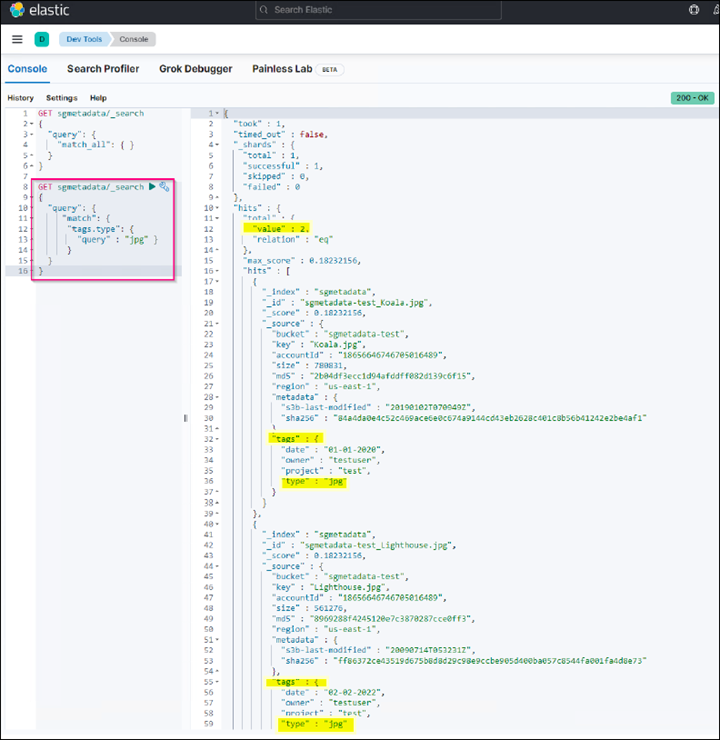
O resultado da amostra da consulta 2 na captura de tela a seguir mostra dois Registros com o tipo de tag jpg.
GET sgmetadata/_search { "query": { "match": { "tags.type": { "query" : "jpg" } } } }+
-
Onde encontrar informações adicionais
Para saber mais sobre as informações descritas neste documento, consulte os seguintes documentos e/ou sites:
Por Angela Cheng