

Solucione problemas dos serviços da plataforma StorageGRID
 Sugerir alterações
Sugerir alterações
Os endpoints usados nos serviços da plataforma são criados e mantidos pelos usuários do tenant no Tenant Manager. No entanto, se um tenant tiver problemas para configurar ou usar os serviços da plataforma, você pode usar o Grid Manager para ajudar a resolver o problema.
Problemas com novos endpoints
Antes que um locatário possa usar os serviços da plataforma, ele deve criar um ou mais pontos de extremidade usando o Gerenciador do locatário. Cada endpoint representa um destino externo para um serviço de plataforma, como um bucket do StorageGRID S3, um bucket do Amazon Web Services, um tópico do Amazon Simple Notification Service, um tópico do Kafka ou um cluster do Elasticsearch hospedado localmente ou na AWS. Cada endpoint inclui a localização do recurso externo e as credenciais necessárias para acessar esse recurso.
Quando um locatário cria um endpoint, o sistema StorageGRID valida que o endpoint existe e que ele pode ser alcançado usando as credenciais especificadas. A conexão com o endpoint é validada a partir de um nó em cada local.
Se a validação do endpoint falhar, uma mensagem de erro explica por que a validação do endpoint falhou. O usuário do locatário deve resolver o problema e tentar criar o endpoint novamente.

|
A criação do endpoint falhará se os serviços da plataforma não estiverem habilitados para a conta do locatário. |
Problemas com endpoints existentes
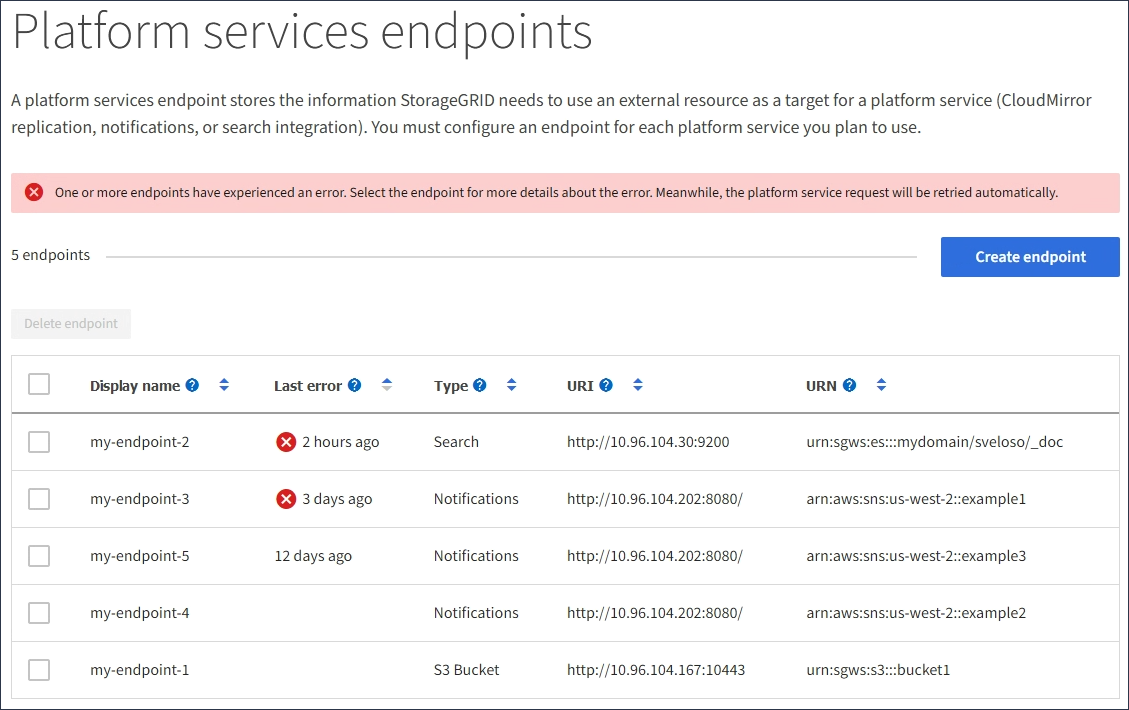
Se ocorrer um erro quando o StorageGRID tenta alcançar um endpoint existente, uma mensagem é exibida no painel no Gerenciador de inquilinos.

Os usuários locatários podem acessar a página de Endpoints para revisar a mensagem de erro mais recente de cada endpoint e determinar há quanto tempo o erro ocorreu. A coluna Último erro exibe a mensagem de erro mais recente de cada endpoint e indica há quanto tempo o erro ocorreu. Erros que incluem o ícone ![]() ocorreram nos últimos 7 dias.
ocorreram nos últimos 7 dias.
|
|
Algumas mensagens de erro na coluna último erro podem incluir um LOGID entre parênteses. Um administrador de grade ou suporte técnico pode usar esse ID para localizar informações mais detalhadas sobre o erro no bycast.log. |
Problemas relacionados aos servidores proxy
Se você configurou um"proxy de storage" entre os nós de armazenamento e os pontos de extremidade do serviço de plataforma, podem ocorrer erros se o serviço de proxy não permitir mensagens do StorageGRID. Para resolver esses problemas, verifique as configurações do seu servidor proxy para garantir que as mensagens relacionadas ao serviço da plataforma não estejam bloqueadas.
Determine se ocorreu um erro
Se algum erro de endpoint tiver ocorrido nos últimos 7 dias, o painel no Gerenciador de inquilinos exibirá uma mensagem de alerta. Pode aceder à página Endpoints para ver mais detalhes sobre o erro.
Falha nas operações do cliente
Alguns problemas de serviços de plataforma podem causar falha nas operações do cliente no bucket do S3. Por exemplo, as operações do cliente S3 falharão se o serviço interno da Máquina de Estado replicado (RSM) parar ou se houver muitas mensagens de serviços de plataforma enfileiradas para entrega.
Para verificar o status dos serviços:
-
Selecione Nós > site > Nó de Armazenamento > Visão Geral.
-
Verifique se há alertas ativos na tabela Alertas.
-
Resolva quaisquer alertas ativos. Se necessário, entre em contato com o suporte técnico.
Erros de endpoint recuperáveis e irrecuperáveis
Após a criação de endpoints, os erros de solicitação de serviço da plataforma podem ocorrer por vários motivos. Alguns erros são recuperáveis com a intervenção do usuário. Por exemplo, erros recuperáveis podem ocorrer pelos seguintes motivos:
-
As credenciais do usuário foram excluídas ou expiraram.
-
O bucket de destino não existe.
-
A notificação não pode ser entregue.
Se o StorageGRID encontrar um erro recuperável, a solicitação de serviço da plataforma será tentada novamente até que seja bem-sucedida.
Outros erros são irrecuperáveis. Por exemplo, erros irrecuperáveis podem ocorrer pelos seguintes motivos:
-
O ponto final é excluído.
-
Um destino de ponto de extremidade do webhook responde a uma solicitação de notificação com um
400 Bad Requesterro.
Se o StorageGRID encontrar um erro de endpoint irrecuperável:
-
No Gerenciador de Grade, vá para suporte > Ferramentas > métricas > Grafana > Visão geral dos Serviços de Plataforma para ver os detalhes do erro.
-
No Gerenciador do Locatário, vá para STORAGE (S3) > Platform Services Endpoints para ver os detalhes do erro.
-
Verifique se existem erros relacionados no
/var/local/log/bycast-err.log. Os nós de storage que têm o serviço ADC contêm esse arquivo de log.
As mensagens dos serviços da plataforma não podem ser entregues
Se o destino encontrar um problema que o impeça de aceitar mensagens de serviços de plataforma, a operação do cliente no bucket será bem-sucedida, mas a mensagem de serviços de plataforma não será entregue. Por exemplo, esse erro pode ocorrer se as credenciais forem atualizadas no destino de forma que o StorageGRID não consiga mais se autenticar no serviço de destino.
Verifique se existem alertas relacionados.
Desempenho mais lento para solicitações de serviço de plataforma
O software StorageGRID pode controlar as solicitações recebidas do S3 para um bucket se a taxa na qual as solicitações estão sendo enviadas exceder a taxa na qual o endpoint de destino pode receber as solicitações. O estrangulamento só ocorre quando há um backlog de solicitações aguardando para serem enviadas para o endpoint de destino.
O único efeito visível é que as solicitações S3 recebidas demorarão mais tempo para serem executadas. Se você começar a detetar desempenho significativamente mais lento, você deve reduzir a taxa de ingestão ou usar um endpoint com maior capacidade. Se o backlog de solicitações continuar a crescer, as operações do cliente S3 (como SOLICITAÇÕES PUT) acabarão falhando.
As solicitações do CloudMirror são mais propensas a serem afetadas pelo desempenho do endpoint de destino, pois essas solicitações geralmente envolvem mais transferência de dados do que solicitações de integração de pesquisa ou notificação de eventos.
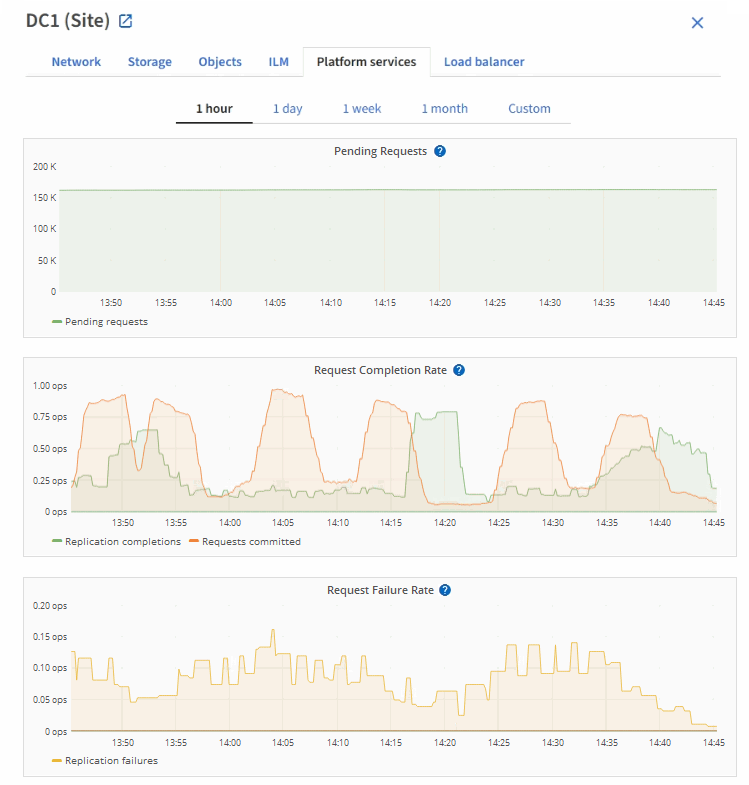
As solicitações de serviço da plataforma falham
Para visualizar a taxa de falha da solicitação para serviços de plataforma:
-
Selecione Nós.
-
Selecione site > Serviços de Plataforma.
-
Veja o gráfico de taxa de erro de solicitação.
Alerta de serviços de plataforma indisponíveis
O alerta Platform services unavailable indica que nenhuma operação de serviço de plataforma pode ser executada em um local porque poucos nós de storage com o serviço RSM estão em execução ou disponíveis.
O serviço RSM garante que as solicitações de serviço da plataforma sejam enviadas para seus respetivos endpoints.
Para resolver esse alerta, determine quais nós de storage no local incluem o serviço RSM. (O serviço RSM está presente nos nós de storage que também incluem o serviço ADC.) Em seguida, certifique-se de que uma maioria simples desses nós de storage esteja em execução e disponível.
|
|
Se mais de um nó de storage que contém o serviço RSM falhar em um local, você perderá quaisquer solicitações de serviço de plataforma pendentes para esse site. |
Orientação adicional para solução de problemas para endpoints de serviços de plataforma
Para obter informações adicionais, "Usar uma conta de locatário > solucionar problemas de endpoints de serviços de plataforma"consulte .