

重新掛載並重新格式化裝置儲存磁碟區(手動步驟)
 建議變更
建議變更
您必須手動執行兩個腳本來重新掛載保留的儲存磁碟區並重新格式化任何失敗的儲存磁碟區。第一個腳本重新掛載正確格式化為StorageGRID儲存磁碟區的磁碟區。第二個腳本重新格式化所有未安裝的捲,重建 Cassandra 資料庫(如果需要),並啟動服務。
-
您已經更換了所有您知道需要更換的故障儲存磁碟區的硬體。
運行 `sn-remount-volumes`腳本可能會幫助您識別其他失敗的儲存磁碟區。
-
您已檢查儲存節點退役未正在進行,或您已暫停節點退役程序。(在網格管理員中,選擇 維護 > 任務 > 退役。)
-
您已檢查擴充功能是否尚未進行。(在網格管理員中,選擇 維護 > 任務 > 擴充。)

|
如果多個儲存節點處於離線狀態,或此網格中的儲存節點在過去 15 天內已重建,請聯絡技術支援。不要運行 `sn-recovery-postinstall.sh`腳本。在 15 天內在兩個或多個儲存節點上重建 Cassandra 可能會導致資料遺失。 |
要完成此過程,請執行以下高級任務:
-
登入恢復的儲存節點。
-
運行 `sn-remount-volumes`腳本重新掛載格式正確的儲存磁碟區。當此腳本運行時,它會執行以下操作:
-
掛載和卸載每個儲存磁碟區以重播 XFS 日誌。
-
執行 XFS 檔案一致性檢查。
-
如果檔案系統一致,則確定儲存磁碟區是否為格式正確的StorageGRID儲存磁碟區。
-
如果儲存磁碟區格式化正確,則重新掛載儲存磁碟區。卷上的任何現有數據均保持不變。
-
-
檢查腳本輸出並解決任何問題。
-
運行 `sn-recovery-postinstall.sh`腳本。當此腳本運行時,它會執行以下操作。
在運行之前,請勿在恢復期間重新啟動儲存節點 sn-recovery-postinstall.sh(步驟 4)重新格式化故障的儲存磁碟區並還原物件元資料。重新啟動儲存節點 `sn-recovery-postinstall.sh`完成會導致嘗試啟動的服務發生錯誤,並導致StorageGRID設備節點退出維護模式。-
重新格式化任何儲存卷 `sn-remount-volumes`腳本無法安裝或被發現格式不正確。

如果重新格式化儲存卷,則該磁碟區上的所有資料都會遺失。您必須執行額外的程序來從網格中的其他位置還原物件數據,假設 ILM 規則配置為儲存多個物件副本。 -
如果需要,請在節點上重建 Cassandra 資料庫。
-
啟動儲存節點上的服務。
-
-
登入恢復的儲存節點:
-
輸入以下命令:
ssh admin@grid_node_IP -
輸入 `Passwords.txt`文件。
-
輸入以下命令切換到root:
su - -
輸入 `Passwords.txt`文件。
當您以 root 身分登入時,提示字元將從
$`到 `#。 -
-
執行第一個腳本來重新掛載任何正確格式化的儲存磁碟區。
如果所有儲存磁碟區都是新的並且需要格式化,或者所有儲存磁碟區都發生故障,則可以跳過此步驟並執行第二個腳本來重新格式化所有未掛載的儲存磁碟區。 -
運行腳本:
sn-remount-volumes該腳本可能需要幾個小時才能在包含資料的儲存卷上運行。
-
當腳本運行時,檢查輸出並回答任何提示。
根據需要,您可以使用 tail -f`命令來監視腳本日誌檔案的內容(/var/local/log/sn-remount-volumes.log`)。日誌檔案包含比命令列輸出更詳細的資訊。root@SG:~ # sn-remount-volumes The configured LDR noid is 12632740 ====== Device /dev/sdb ====== Mount and unmount device /dev/sdb and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sdb: Mount device /dev/sdb to /tmp/sdb-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12632740, volume number 0 in the volID file Attempting to remount /dev/sdb Device /dev/sdb remounted successfully ====== Device /dev/sdc ====== Mount and unmount device /dev/sdc and checking file system consistency: Error: File system consistency check retry failed on device /dev/sdc. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policies. Don't continue to the next step if you believe that the data remaining on this volume can't be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sdd ====== Mount and unmount device /dev/sdd and checking file system consistency: Failed to mount device /dev/sdd This device could be an uninitialized disk or has corrupted superblock. File system check might take a long time. Do you want to continue? (y or n) [y/N]? y Error: File system consistency check retry failed on device /dev/sdd. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policies. Don't continue to the next step if you believe that the data remaining on this volume can't be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sde ====== Mount and unmount device /dev/sde and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sde: Mount device /dev/sde to /tmp/sde-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12000078, volume number 9 in the volID file Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
在範例輸出中,一個儲存磁碟區已成功重新安裝,而三個儲存磁碟區出現錯誤。
-
`/dev/sdb`通過了 XFS 檔案系統一致性檢查,並且具有有效的磁碟區結構,因此已成功重新掛載。腳本重新安裝的設備上的資料將被保留。
-
`/dev/sdc`由於儲存磁碟區是新的或已損壞,XFS 檔案系統一致性檢查失敗。
-
`/dev/sdd`無法掛載,因為磁碟未初始化或磁碟的超級區塊已損壞。當腳本無法掛載儲存磁碟區時,它會詢問您是否要執行檔案系統一致性檢查。
-
如果儲存磁碟區連接到新磁碟,請對提示回答 N。您不需要檢查新磁碟上的檔案系統。
-
如果儲存磁碟區附加到現有磁碟,請對提示回答 Y。您可以使用檔案系統檢查的結果來確定損壞的來源。結果保存在 `/var/local/log/sn-remount-volumes.log`記錄檔.
-
-
`/dev/sde`通過了 XFS 檔案系統一致性檢查,並且具有有效的磁碟區結構;但是, `volID`檔案與此儲存節點的 ID 不符( `configured LDR noid`顯示在頂部)。此訊息表示該磁碟區屬於另一個儲存節點。
-
-
-
檢查腳本輸出並解決任何問題。
如果儲存磁碟區未透過 XFS 檔案系統一致性檢查或無法掛載,請仔細檢查輸出中的錯誤訊息。你必須理解運行 `sn-recovery-postinstall.sh`這些磁碟區上的腳本。 -
檢查以確保結果包含您預期的所有磁碟區的條目。如果未列出任何捲,請重新運行腳本。
-
查看所有已安裝設備的消息。確保沒有錯誤表明儲存卷不屬於此儲存節點。
在範例中,/dev/sde 的輸出包含以下錯誤訊息:
Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
如果報告儲存卷屬於另一個儲存節點,請聯絡技術支援。如果你運行 `sn-recovery-postinstall.sh`腳本,儲存卷將被重新格式化,這可能會導致資料遺失。 -
如果無法安裝任何儲存設備,請記下設備名稱,然後修復或更換該設備。
您必須修復或更換任何無法安裝的儲存裝置。 您將使用設備名稱來查找磁碟區 ID,這是運行 `repair-data`腳本將物件資料還原到磁碟區(下一個過程)。
-
修復或更換所有無法安裝的設備後,運行 `sn-remount-volumes`再次執行腳本以確認所有可以重新掛載的儲存磁碟區已重新掛載。
如果無法安裝儲存磁碟區或儲存磁碟區格式不正確,且您繼續執行下一步,則該磁碟區及其上的任何資料都會被刪除。如果您有兩個物件資料副本,則在完成下一個程序(恢復物件資料)之前,您將只有一個副本。
不要運行 `sn-recovery-postinstall.sh`如果您認為無法從網格中的其他位置重建故障儲存磁碟區上剩餘的資料(例如,如果您的 ILM 策略使用僅製作一個副本的規則,或磁碟區在多個節點上發生故障),請執行腳本。相反,請聯絡技術支援以確定如何恢復您的資料。 -
-
運行
sn-recovery-postinstall.sh`腳本: `sn-recovery-postinstall.sh此腳本重新格式化任何無法安裝或格式不正確的儲存磁碟區;如果需要,重建節點上的 Cassandra 資料庫;並啟動儲存節點上的服務。
請注意以下事項:
-
該腳本可能需要幾個小時才能運行。
-
一般來說,腳本運行時您應該不要管 SSH 會話。
-
SSH 會話處於活動狀態時,請勿按 Ctrl+C。
-
如果發生網路中斷並終止 SSH 會話,腳本將在背景執行,但您可以從恢復頁面查看進度。
-
如果儲存節點使用 RSM 服務,則在節點服務重新啟動時腳本可能會停滯 5 分鐘。 RSM 服務首次啟動時預計會出現 5 分鐘的延遲。
RSM 服務存在於包含 ADC 服務的儲存節點上。
一些StorageGRID恢復程序使用 Reaper 來處理 Cassandra 修復。一旦相關或所需的服務開始,修復就會自動進行。您可能會注意到腳本輸出中提到了“reaper”或“Cassandra repair”。如果您看到指示修復失敗的錯誤訊息,請執行錯誤訊息中指示的命令。 -
-
作為 `sn-recovery-postinstall.sh`腳本運行時,監視網格管理器中的復原頁面。
復原頁面上的進度列和階段列提供了復原過程的進階狀態 `sn-recovery-postinstall.sh`腳本。
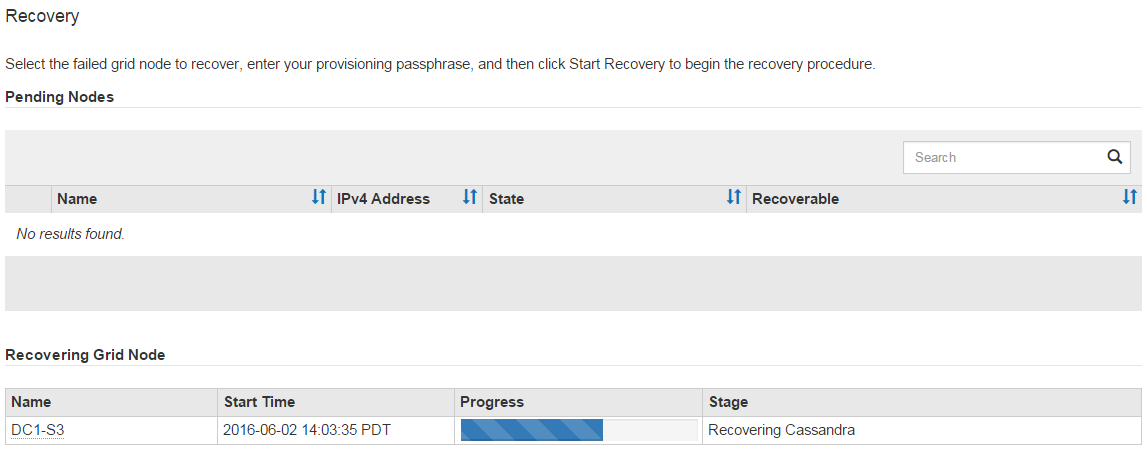
-
之後 `sn-recovery-postinstall.sh`腳本已在節點上啟動服務,您可以將物件資料還原到由腳本格式化的任何儲存磁碟區。
腳本詢問您是否要使用網格管理器磁碟區復原程序。
-
在大多數情況下,你應該"使用網格管理器恢復物件數據"。回答 `y`使用網格管理器。
-
在極少數情況下,例如在技術支援的指導下,或者當您知道替換節點可用於物件儲存的磁碟區比原始節點少時,您必須"手動恢復對象數據"使用
repair-data`腳本。如果其中一種情況適用,請回答 `n。
如果你回答 `n`使用網格管理器磁碟區復原過程(手動還原物件資料):
-
您無法使用網格管理器還原物件資料。
-
您可以使用網格管理器監控手動恢復作業的進度。
做出選擇後,腳本將完成並顯示恢復物件資料的後續步驟。查看這些步驟後,按任意鍵返回命令列。
-
-