

Erfahren Sie mehr über die NetApp Data Classification
 Änderungen vorschlagen
Änderungen vorschlagen
NetApp Data Classification ist ein Data-Governance-Service für die NetApp Console , der Ihre unternehmenseigenen Datenquellen vor Ort und in der Cloud scannt, um Daten zuzuordnen und zu klassifizieren und private Informationen zu identifizieren. Dies kann dazu beitragen, Ihr Sicherheits- und Compliance-Risiko zu verringern, die Speicherkosten zu senken und Ihre Datenmigrationsprojekte zu unterstützen.

|
Ab Version 1.31 ist die Datenklassifizierung als Kernfunktion in der NetApp Console verfügbar. Es fallen keine zusätzlichen Kosten an. Es ist keine Klassifizierungslizenz oder kein Abonnement erforderlich. + Wenn Sie die Vorgängerversion 1.30 oder früher verwendet haben, ist diese Version verfügbar, bis Ihr Abonnement abläuft. |
NetApp Console
Auf die Datenklassifizierung kann über die NetApp Console zugegriffen werden.
Die NetApp Console ermöglicht eine zentrale Verwaltung von NetApp -Speicher- und Datendiensten in lokalen und Cloud-Umgebungen auf Unternehmensebene. Die Konsole ist für den Zugriff auf und die Nutzung der NetApp -Datendienste erforderlich. Als Verwaltungsschnittstelle ermöglicht es Ihnen, viele Speicherressourcen über eine Schnittstelle zu verwalten. Konsolenadministratoren können den Zugriff auf Speicher und Dienste für alle Systeme innerhalb des Unternehmens steuern.
Sie benötigen weder eine Lizenz noch ein Abonnement, um die NetApp Console zu verwenden. Es fallen nur dann Kosten an, wenn Sie Konsolenagenten in Ihrer Cloud bereitstellen müssen, um die Konnektivität zu Ihren Speichersystemen oder NetApp -Datendiensten sicherzustellen. Einige NetApp -Datendienste, auf die über die Konsole zugegriffen werden kann, sind jedoch lizenz- oder abonnementbasiert.
Erfahren Sie mehr über die"NetApp Console" .
Features
Bei der Datenklassifizierung werden künstliche Intelligenz (KI), natürliche Sprachverarbeitung (NLP) und maschinelles Lernen (ML) verwendet, um die gescannten Inhalte zu verstehen, Entitäten zu extrahieren und die Inhalte entsprechend zu kategorisieren. Dadurch kann die Datenklassifizierung die folgenden Funktionsbereiche bereitstellen.
Die Datenklassifizierung bietet mehrere Tools, die Sie bei Ihren Compliance-Bemühungen unterstützen können. Sie können die Datenklassifizierung für Folgendes verwenden:
-
Identifizieren Sie personenbezogene Daten (PII).
-
Identifizieren Sie ein breites Spektrum sensibler personenbezogener Daten gemäß den Datenschutzbestimmungen DSGVO, CCPA, PCI und HIPAA.
-
Beantworten Sie Anfragen zum Zugriff auf personenbezogene Daten (DSAR) basierend auf Name oder E-Mail-Adresse.
Durch die Datenklassifizierung können Daten identifiziert werden, bei denen das Risiko besteht, dass für kriminelle Zwecke auf sie zugegriffen wird. Sie können die Datenklassifizierung für Folgendes verwenden:
-
Identifizieren Sie alle Dateien und Verzeichnisse (Freigaben und Ordner) mit offenen Berechtigungen, die Ihrer gesamten Organisation oder der Öffentlichkeit zugänglich sind.
-
Identifizieren Sie vertrauliche Daten, die sich außerhalb des ursprünglichen, dedizierten Speicherorts befinden.
-
Halten Sie die Richtlinien zur Datenaufbewahrung ein.
-
Verwenden Sie Richtlinien, um neue Sicherheitsprobleme automatisch zu erkennen, damit das Sicherheitspersonal sofort Maßnahmen ergreifen kann.
Die Datenklassifizierung bietet Tools, die Ihnen bei der Reduzierung der Gesamtbetriebskosten (TCO) Ihres Speichers helfen können. Sie können die Datenklassifizierung für Folgendes verwenden:
-
Steigern Sie die Speichereffizienz, indem Sie doppelte oder nicht geschäftsbezogene Daten identifizieren.
-
Sparen Sie Speicherkosten, indem Sie inaktive Daten identifizieren, die Sie in einen kostengünstigeren Objektspeicher verschieben können. "Erfahren Sie mehr über das Tiering von Cloud Volumes ONTAP -Systemen" . "Erfahren Sie mehr über das Tiering von On-Premises ONTAP -Systemen" .
Unterstützte Systeme und Datenquellen
Die Datenklassifizierung kann strukturierte und unstrukturierte Daten aus den folgenden Systemtypen und Datenquellen scannen und analysieren:
Systeme
-
Amazon FSx for NetApp ONTAP -Verwaltung
-
Azure NetApp Files
-
Cloud Volumes ONTAP (bereitgestellt in AWS, Azure oder GCP)
-
Google Cloud NetApp Volumes
-
On-Premises- ONTAP -Cluster
-
StorageGRID
Datenquellen
-
NetApp -Dateifreigaben
-
Datenbanken:
-
Amazon Relational Database Service (Amazon RDS)
-
MongoDB
-
MySQL
-
Orakel
-
PostgreSQL
-
SAP HANA
-
SQL Server (MSSQL)
-
Die Datenklassifizierung unterstützt die NFS-Versionen 3.x, 4.0 und 4.1 sowie die CIFS-Versionen 1.x, 2.0, 2.1 und 3.0.
Kosten
Die Nutzung der Datenklassifizierung ist kostenlos. Es ist keine Klassifizierungslizenz oder kostenpflichtiges Abonnement erforderlich.
Infrastrukturkosten
-
Für die Installation der Datenklassifizierung in der Cloud ist die Bereitstellung einer Cloud-Instanz erforderlich, wofür vom Cloud-Anbieter, bei dem die Instanz bereitgestellt wird, Gebühren anfallen. Sehen der Instanztyp, der für jeden Cloud-Anbieter bereitgestellt wird . Wenn Sie Data Classification auf einem lokalen System installieren, fallen keine Kosten an.
-
Für die Datenklassifizierung müssen Sie einen Konsolenagenten bereitgestellt haben. In vielen Fällen verfügen Sie aufgrund anderer Speicher und Dienste, die Sie in der Konsole verwenden, bereits über einen Konsolenagenten. Für die Konsolen-Agentinstanz fallen Gebühren seitens des Cloud-Anbieters an, bei dem sie bereitgestellt wird. Siehe die "Typ der Instanz, die für jeden Cloud-Anbieter bereitgestellt wird" . Wenn Sie den Konsolenagenten auf einem lokalen System installieren, fallen keine Kosten an.
Kosten für die Datenübertragung
Die Kosten für die Datenübertragung hängen von Ihrer Konfiguration ab. Wenn sich die Datenklassifizierungsinstanz und die Datenquelle in derselben Verfügbarkeitszone und Region befinden, fallen keine Datenübertragungskosten an. Wenn sich die Datenquelle, beispielsweise ein Cloud Volumes ONTAP -System, jedoch in einer anderen Availability Zone oder Region befindet, werden Ihnen von Ihrem Cloud-Anbieter die Kosten für die Datenübertragung in Rechnung gestellt. Weitere Einzelheiten finden Sie unter diesen Links:
Die Datenklassifizierungsinstanz
Wenn Sie die Datenklassifizierung in der Cloud bereitstellen, stellt die Konsole die Instanz im selben Subnetz wie der Konsolenagent bereit. "Erfahren Sie mehr über den Konsolenagenten."
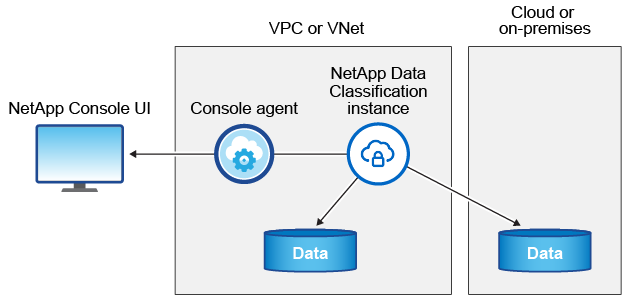
Beachten Sie Folgendes zur Standardinstanz:
-
In AWS läuft die Datenklassifizierung auf einem "m6i.4xlarge-Instanz" mit einer 500 GiB GP2-Festplatte. Das Betriebssystem-Image ist Amazon Linux 2.
-
In Azure läuft die Datenklassifizierung auf einem"Standard_D16s_v3 VM" mit einer 500-GiB-Festplatte. Das Betriebssystem-Image ist Ubuntu 22.04.
-
In GCP läuft die Datenklassifizierung auf einem"n2-standard-16 VM" mit einer persistenten 500-GiB-Standardfestplatte. Das Betriebssystem-Image ist Ubuntu 22.04.
-
In Regionen, in denen die Standardinstanz nicht verfügbar ist, wird die Datenklassifizierung auf einer alternativen Instanz ausgeführt. "Alternative Instance-Typen anzeigen" .
-
Die Instanz trägt den Namen CloudCompliance und ist mit einem generierten Hash (UUID) verknüpft. Beispiel: CloudCompliance-16bb6564-38ad-4080-9a92-36f5fd2f71c7
-
Pro Konsolenagent wird nur eine Datenklassifizierungsinstanz bereitgestellt.
Sie können die Datenklassifizierung auch auf einem Linux-Host in Ihren Räumlichkeiten oder auf einem Host bei Ihrem bevorzugten Cloud-Anbieter bereitstellen. Die Software funktioniert unabhängig von der gewählten Installationsmethode auf genau dieselbe Weise. Upgrades der Datenklassifizierungssoftware werden automatisiert, solange die Instanz über einen Internetzugang verfügt.

|
Die Instanz sollte ständig ausgeführt werden, da die Datenklassifizierung die Daten kontinuierlich scannt. |
Auf verschiedenen Instanztypen bereitstellen
Überprüfen Sie die folgenden Spezifikationen für Instanztypen:
| Systemgröße | Technische Daten | Einschränkungen |
|---|---|---|
Extragroß |
32 CPUs, 128 GB RAM, 1 TiB SSD |
Kann bis zu 500 Millionen Dateien scannen. |
Groß (Standard) |
16 CPUs, 64 GB RAM, 500 GiB SSD |
Kann bis zu 250 Millionen Dateien scannen. |
Funktionsweise des Datenklassifizierungsscans
Im Großen und Ganzen funktioniert das Scannen der Datenklassifizierung folgendermaßen:
-
Sie stellen eine Instanz der Datenklassifizierung in der Konsole bereit.
-
Sie aktivieren Scans für eine oder mehrere Datenquellen.
-
Bei der Datenklassifizierung werden Daten mithilfe eines KI-Lernprozesses gescannt.
-
Sie verwenden die bereitgestellten Dashboards und Berichtstools, um Ihre Compliance- und Governance-Bemühungen zu unterstützen.
Nachdem Sie die Datenklassifizierung aktiviert und die zu scannenden Repositories ausgewählt haben (das sind die Volumes, Datenbankschemata oder andere Benutzerdaten), beginnt das Programm sofort mit dem Scannen der Daten, um persönliche und vertrauliche Daten zu identifizieren. In den meisten Fällen sollten Sie sich auf das Scannen von Live-Produktionsdaten konzentrieren, anstatt auf Backups, Spiegel oder DR-Sites. Anschließend ordnet die Datenklassifizierung Ihre Organisationsdaten zu, kategorisiert jede Datei und identifiziert und extrahiert Entitäten und vordefinierte Muster in den Daten. Das Ergebnis des Scans ist ein Index mit persönlichen Informationen, sensiblen persönlichen Informationen, Datenkategorien und Dateitypen.
Data Classification stellt wie jeder andere Client eine Verbindung zu den Daten her, indem es NFS- und CIFS-Volumes einbindet. Auf NFS-Volumes wird automatisch schreibgeschützt zugegriffen, während Sie zum Scannen von CIFS-Volumes Active Directory-Anmeldeinformationen angeben müssen.
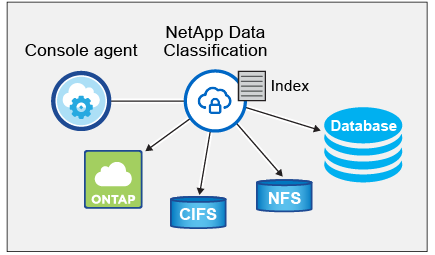
Nach dem ersten Scan scannt die Datenklassifizierung Ihre Daten kontinuierlich im Round-Robin-Verfahren, um inkrementelle Änderungen zu erkennen. Aus diesem Grund ist es wichtig, die Instanz am Laufen zu halten.
Sie können Scans auf Volume- oder Datenbankschemaebene aktivieren und deaktivieren.

|
Die Datenklassifizierung setzt keine Begrenzung für die Menge der Daten, die gescannt werden kann. Jeder Konsolenagent unterstützt das Scannen und Anzeigen von 500 TiB Daten. Um mehr als 500 TiB Daten zu scannen,"einen anderen Konsolenagenten installieren" Dann"eine weitere Data Classification-Instanz bereitstellen" . + Die Konsolen-Benutzeroberfläche zeigt Daten von einem einzelnen Connector an. Tipps zum Anzeigen von Daten von mehreren Konsolenagenten finden Sie unter"Arbeiten mit mehreren Konsolenagenten" . |
Kartierung und vollständige Scans
Sie können in der Datenklassifizierung zwei Arten von Scans durchführen:
-
Nur-Karten-Scans bieten lediglich einen groben Überblick über Ihre Daten und werden auf ausgewählten Datenquellen durchgeführt. Nur-Karten-Scans benötigen weniger Zeit als vollständige Scans, da sie nicht auf die Dateien zugreifen, um die darin enthaltenen Daten einzusehen. Sie können dies zunächst nutzen, um Forschungsbereiche zu identifizieren und anschließend einen vollständigen Scan dieser Bereiche durchzuführen.
-
Vollständige Scans ermöglichen eine tiefgehende Überprüfung Ihrer Daten. Ein vollständiger Scan umfasst eine reine Kartierung und eine Klassifizierung der Daten innerhalb der Dateien.
Eine detaillierte Aufschlüsselung der Unterschiede zwischen reinen Kartenscans und vollständigen Scans finden Sie unter "Was ist der Unterschied zwischen Mapping- und Klassifizierungsscans?".
Informationen, die durch die Datenklassifizierung kategorisiert werden
Die Datenklassifizierung sammelt, indiziert und ordnet die folgenden Daten Kategorien zu:
-
Standardmetadaten zu Dateien: Dateityp, Größe, Erstellungs- und Änderungsdatum usw.
-
Personenbezogene Daten: Persönlich identifizierbare Informationen (PII) wie E-Mail-Adressen, Identifikationsnummern oder Kreditkartennummern, die durch die Datenklassifizierung anhand bestimmter Wörter, Zeichenfolgen und Muster in den Dateien identifiziert werden. "Erfahren Sie mehr über personenbezogene Daten" .
-
Sensible personenbezogene Daten: Besondere Arten sensibler personenbezogener Daten (SPII), wie Gesundheitsdaten, ethnische Herkunft oder politische Meinungen, wie in der Datenschutz-Grundverordnung (DSGVO) und anderen Datenschutzbestimmungen definiert. "Erfahren Sie mehr über sensible personenbezogene Daten" .
-
Kategorien: Die Datenklassifizierung nimmt die gescannten Daten und unterteilt sie in verschiedene Kategorien. Kategorien sind Themen, die auf einer KI-Analyse des Inhalts und der Metadaten jeder Datei basieren. "Mehr über Kategorien erfahren".
-
Namensentitätserkennung: Die Datenklassifizierung verwendet KI, um die natürlichen Namen von Personen aus Dokumenten zu extrahieren. "Erfahren Sie mehr über die Beantwortung von Auskunftsersuchen betroffener Personen" .
Netzwerkübersicht
Data Classification stellt einen einzelnen Server oder Cluster bereit, wo immer Sie möchten: in der Cloud oder vor Ort. Die Server stellen über Standardprotokolle eine Verbindung zu den Datenquellen her und indizieren die Ergebnisse in einem Elasticsearch-Cluster, der ebenfalls auf denselben Servern bereitgestellt wird. Dies ermöglicht die Unterstützung von Multi-Cloud-, Cross-Cloud-, Private-Cloud- und On-Premises-Umgebungen.
Die Konsole stellt die Datenklassifizierungsinstanz mit einer Sicherheitsgruppe bereit, die eingehende HTTP-Verbindungen vom Konsolenagenten ermöglicht.
Wenn Sie die Konsole im SaaS-Modus verwenden, wird die Verbindung zur Konsole über HTTPS bereitgestellt und die privaten Daten, die zwischen Ihrem Browser und der Datenklassifizierungsinstanz gesendet werden, werden mit einer End-to-End-Verschlüsselung unter Verwendung von TLS 1.2 gesichert, was bedeutet, dass NetApp und Dritte sie nicht lesen können.
Die Outbound-Regeln sind völlig offen. Für die Installation und Aktualisierung der Datenklassifizierungssoftware sowie zum Senden von Nutzungsmetriken ist ein Internetzugang erforderlich.
Wenn Sie strenge Netzwerkanforderungen haben,"Erfahren Sie mehr über die Endpunkte, die die Datenklassifizierung kontaktiert" .