

Instalar NetApp Data Classification en un host Linux sin acceso a Internet
 Sugerir cambios
Sugerir cambios
La instalación de NetApp Data Classification en un host Linux en un sitio local que no tiene acceso a Internet se conoce como modo privado. Este tipo de instalación, que utiliza un script de instalación, no tiene conectividad con la capa SaaS de la NetApp Console .

|
Para las implementaciones locales de VMware vSphere, NetApp Data Classification admite una "despliegue con OVA" simplificada. |
El script de instalación de Clasificación de datos comienza verificando si el sistema y el entorno cumplen los requisitos previos requeridos. Si se cumplen todos los requisitos previos, se inicia la instalación. Si desea verificar los requisitos previos independientemente de ejecutar la instalación de Clasificación de datos, hay un paquete de software separado que puede descargar que solo prueba los requisitos previos. "Vea cómo comprobar si su host Linux está listo para instalar la Clasificación de Datos" .
Fuentes de datos compatibles
Cuando se instala en modo privado (a veces llamado sitio "sin conexión" u "oscuro"), Data Classification solo puede escanear datos de fuentes de datos que también sean locales al sitio local en las instalaciones. En este momento, Data Classification puede escanear las siguientes fuentes de datos locales:
-
Sistemas ONTAP locales
-
Esquemas de bases de datos
Actualmente no hay soporte para escanear Cloud Volumes ONTAP, Azure NetApp Files o FSx for ONTAP accounts cuando Data Classification está desplegado en modo privado.
Limitaciones
La mayoría de las funciones de Data Classification funcionan cuando se instala en un sitio sin acceso a internet. Sin embargo, ciertas funciones que requieren acceso a internet no son compatibles, por ejemplo:
-
Establecer funciones de la consola para diferentes usuarios (por ejemplo, Account Admin o Compliance Viewer)
-
Copiar y sincronizar archivos de origen usando NetApp Copy and Sync
-
Actualizaciones automáticas de software desde la Console
Tanto el agente de Console como Data Classification requieren actualizaciones manuales periódicas para habilitar nuevas funciones. Puedes ver la versión de Data Classification en la parte inferior de las páginas de la interfaz de usuario de Data Classification. Consulta el "Notas de la versión de Data Classification" para ver las nuevas funciones en cada versión y decidir si quieres esas funciones. Luego puedes seguir los pasos para "actualiza el agente de la consola" y actualiza tu software de clasificación de datos.
Inicio rápido
Comience rápidamente siguiendo estos pasos o desplácese hacia abajo hasta las secciones restantes para obtener detalles completos.
 Instala el agente de la consola
Instala el agente de la consolaSi aún no tienes un agente de Console instalado en modo privado, "despliega el agente Console" en un host Linux ahora.
 Revisa los requisitos previos de la clasificación de datos
Revisa los requisitos previos de la clasificación de datosAsegúrate de que tu sistema Linux cumple con los requisitos del anfitrión, que tiene todo el software necesario instalado y que tu entorno offline cumple con los permisos y conectividad requeridos.
 Descargar e implementar la clasificación de datos
Descargar e implementar la clasificación de datosDescarga el software de Data Classification desde el sitio de soporte de NetApp y copia el archivo del instalador en el host Linux que planeas usar. Luego, inicia el asistente de instalación y sigue las indicaciones para desplegar la instancia de Data Classification.
Instala el agente de la consola
Si aún no tienes un agente de Console instalado en modo privado, "despliega el agente Console" en un host Linux en tu sitio fuera de línea.
Preparar el sistema host Linux
El software de clasificación de datos debe ejecutarse en un host que cumpla requisitos específicos de sistema operativo, RAM, requisitos de software y así sucesivamente.
-
La clasificación de datos debe realizarse en un host dedicado. El host no se puede compartir con otras aplicaciones o software de terceros, como antivirus.
-
Elija el tamaño que se alinee con el conjunto de datos que planea escanear con Clasificación de datos.
Tamaño del sistema UPC RAM (la memoria de intercambio debe estar deshabilitada) Disco Extra grande
32 CPU
128 GB de RAM
-
SSD de 1 TiB en /, o 100 GiB disponibles en /opt
-
895 GiB disponibles en /var/lib/docker
-
5 GiB en /tmp
-
Para Podman, 30 GB en /var/tmp
Grande
16 CPU
64 GB de RAM
-
SSD de 500 GiB en /, o 100 GiB disponibles en /opt
-
400 GiB disponibles en /var/lib/docker o para Podman /var/lib/containers
-
5 GiB en /tmp
-
Para Podman, 30 GB en /var/tmp
-
-
Al implementar una instancia de cómputo en la nube para su instalación de Clasificación de datos, se recomienda utilizar un sistema que cumpla con los requisitos del sistema "Grande" mencionados anteriormente:
-
Tipo de instancia de Amazon Elastic Compute Cloud (Amazon EC2): "m6i.4xlarge". "Ver tipos de instancias de AWS adicionales" .
-
Tamaño de VM de Azure: "Standard_D16_v5". "Ver tipos de instancias de Azure adicionales".
-
Tipo de máquina GCP: "n2-standard-16". "Ver tipos de instancias de GCP adicionales" .
-
-
Permisos de carpeta UNIX: Se requieren los siguientes permisos mínimos de UNIX:
Carpeta Permisos mínimos /tmp
rwxrwxrwt/optar
rwxr-xr-x/var/lib/docker
rwx------/usr/lib/systemd/sistema
rwxr-xr-x -
Sistema operativo:
-
Los siguientes sistemas operativos requieren el uso del motor de contenedores Docker:
-
Red Hat Enterprise Linux versión 7.8 y 7.9
-
Ubuntu 22.04 (requiere la versión 1.23 o superior de Data Classification)
-
Ubuntu 24.04 (requiere la versión 1.23 o superior de Data Classification)
-
-
Los siguientes sistemas operativos requieren el uso del motor de contenedores Podman y requieren la versión 1.30 o superior de Data Classification:
-
Red Hat Enterprise Linux versión 8.8, 8.10, 9.0, 9.1, 9.2, 9.3, 9.4, 9.5, 9.6 y 9.7.
-
-
Las extensiones vectoriales avanzadas (AVX2) deben estar habilitadas en el sistema host.
-
-
Gestión de suscripciones de Red Hat: el host debe estar registrado en Gestión de suscripciones de Red Hat. Si no está registrado, el sistema no puede acceder a los repositorios para actualizar el software de terceros requerido durante la instalación.
-
Software adicional: Debe instalar el siguiente software en el host antes de instalar Data Classification:
-
Dependiendo del sistema operativo que estés usando, necesitas instalar uno de los motores de contenedores:
-
Docker Engine versión 19.3.1 o superior. "Ver instrucciones de instalación" .
-
Podman versión 4 o superior. Para instalar Podman, ingrese(
sudo yum install podman netavark -y).
-
-
-
Versión de Python 3.6 o superior. "Ver instrucciones de instalación" .
-
Consideraciones sobre NTP: NetApp recomienda configurar el sistema de clasificación de datos para utilizar un servicio de Protocolo de tiempo de red (NTP). La hora debe estar sincronizada entre el sistema de clasificación de datos y el sistema del agente de consola.
-
-
Consideraciones sobre Firewalld: Si planea utilizar
firewalldLe recomendamos que lo habilite antes de instalar Data Classification. Ejecute los siguientes comandos para configurarfirewalldpara que sea compatible con la Clasificación de Datos:firewall-cmd --permanent --add-service=http firewall-cmd --permanent --add-service=https firewall-cmd --permanent --add-port=80/tcp firewall-cmd --permanent --add-port=8080/tcp firewall-cmd --permanent --add-port=443/tcp firewall-cmd --reload
Tenga en cuenta que debe reiniciar Docker o Podman cada vez que habilite o actualice
firewalldajustes.
|
|
La dirección IP del sistema host de clasificación de datos no se puede cambiar después de la instalación. |

|
El instalador de Data Classification reserva el UID 4321 y el GID 4321. Antes de iniciar la instalación, asegúrate de que el UID 4321 y el GID 4321 no estén en uso en el host. Si están en uso, la instalación fallará con un mensaje de error de "usuario no válido". |
Verifica los requisitos previos de Console y Data Classification
Revisa los siguientes requisitos previos para asegurarte de que tienes una configuración compatible antes de implementar Data Classification.
-
Asegúrate de que el agente de la Console tiene permisos para desplegar recursos y crear grupos de seguridad para la instancia de Data Classification. Puedes encontrar los permisos más recientes de la Console en "las políticas proporcionadas por NetApp".
-
Asegúrate de que puedes mantener en funcionamiento Data Classification. La instancia de Data Classification debe permanecer encendida para analizar continuamente tus datos.
-
Asegúrate de que el navegador web tenga conectividad con Data Classification. Después de habilitar Data Classification, asegúrate de que los usuarios accedan a la interfaz de la Console desde un host que tenga conexión con la instancia de Data Classification.
La instancia de Data Classification utiliza una dirección IP privada para asegurarse de que los datos indexados no sean accesibles para otros. Como resultado, el navegador web que usas para acceder a la Console debe tener una conexión con esa dirección IP privada. Esa conexión puede venir de un host que esté dentro de la misma red que la instancia de Data Classification.
Verifique que todos los puertos requeridos estén habilitados
Debe asegurarse de que todos los puertos necesarios estén abiertos para la comunicación entre el agente de la consola, la clasificación de datos, Active Directory y sus fuentes de datos.
| Tipo de conexión | Puertos | Descripción |
|---|---|---|
Agente de consola <> Clasificación de datos |
8080 (TCP), 6000 (TCP), 443 (TCP), y 80. 9000 |
El grupo de seguridad para el agente de la Console debe permitir tráfico entrante y saliente por los puertos 6000 y 443 hacia y desde la instancia de Data Classification.
|
Agente de consola <> clúster ONTAP (NAS) |
443 (TCP) |
La consola descubre clústeres ONTAP mediante HTTPS. Si utiliza políticas de firewall personalizadas, deben cumplir los siguientes requisitos:
|
Clasificación de datos <> Clúster ONTAP |
|
Data Classification necesita una conexión de red a cada subred de Cloud Volumes ONTAP o sistema ONTAP local. Los grupos de seguridad de Cloud Volumes ONTAP deben permitir conexiones entrantes desde la instancia de Data Classification. Asegúrese de que estos puertos estén abiertos para la instancia de clasificación de datos:
Las políticas de exportación de volumen NFS deben permitir el acceso desde la instancia de clasificación de datos. |
Clasificación de datos <> Active Directory |
389 (TCP y UDP), 636 (TCP), 3268 (TCP) y 3269 (TCP) |
Debe tener un Directorio Activo ya configurado para los usuarios de su empresa. Además, la clasificación de datos necesita credenciales de Active Directory para escanear volúmenes CIFS. Debes tener la información del Directorio Activo:
|
Si se utiliza un firewall en un host Linux |
9000 |
Necesario para procesos internos dentro de un servidor Ubuntu. |
Instala Data Classification en el host Linux local
Para configuraciones típicas, instalarás el software en un solo sistema host.

Sigue estos pasos cuando instales el software Data Classification en un único host local en un entorno sin conexión.
Tenga en cuenta que todas las actividades de instalación se registran al instalar Data Classification. Si surge algún problema durante la instalación, puede ver el contenido del registro de auditoría de la instalación. Esta escrito para /opt/netapp/install_logs/ .
-
Verifique que su sistema Linux cumpla con losrequisitos del anfitrión .
-
Verifica que tienes instalados los dos paquetes de software necesarios (Docker Engine o Podman, y Python 3).
-
Asegúrese de tener privilegios de root en el sistema Linux.
-
Verifica que tu entorno offline cumple los requisitos permisos y conectividad.
-
En un sistema configurado para internet, descarga el software de Data Classification desde el "Sitio de soporte de NetApp". El archivo que debes seleccionar se llama DataSense-offline-bundle-<version>.tar.gz.
-
Copia el paquete de instalación al host Linux que planeas usar en modo privado.
-
Descomprime el paquete de instalación en el equipo anfitrión, por ejemplo:
tar -xzf DataSense-offline-bundle-v1.25.0.tar.gzEsto extrae el software necesario y el archivo de instalación real cc_onprem_installer.tar.gz.
-
Descomprime el archivo de instalación en la máquina anfitriona, por ejemplo:
tar -xzf cc_onprem_installer.tar.gz -
En Clasificación de datos, selecciona Deploy Classification On-Premises or Cloud.
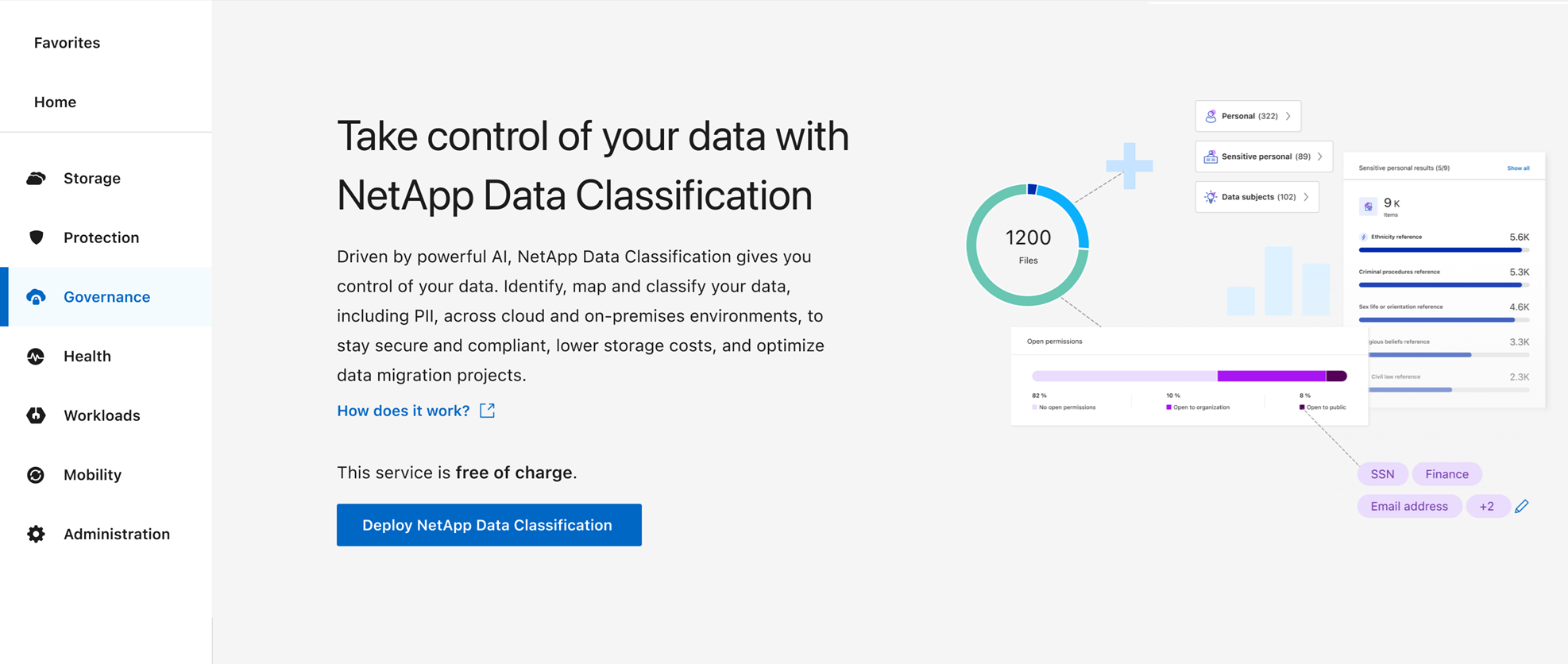
-
Selecciona Desplegar para iniciar la instalación local.
-
Se muestra el cuadro de diálogo Deploy Data Classification On Premises. Copia el comando proporcionado (por ejemplo:
sudo ./install.sh -a 12345 -c 27AG75 -t 2198qq --darksite) y pégalo en un archivo de texto para que puedas usarlo después. Luego selecciona Cerrar para cerrar el cuadro de diálogo. -
En la máquina host, ingrese el comando que copió y luego siga una serie de indicaciones, o puede proporcionar el comando completo incluidos todos los parámetros requeridos como argumentos de la línea de comando.
Ten en cuenta que el instalador realiza una comprobación previa para asegurarse de que los requisitos de tu sistema y red estén listos para una instalación exitosa.
Introduzca los parámetros según se le solicite: Introduzca el comando completo: -
Pega la información que copiaste del paso 8:
sudo ./install.sh -a <account_id> -c <client_id> -t <user_token> --darksite -
Introduzca la dirección IP o el nombre de host de la máquina host de clasificación de datos para que el sistema del agente de la consola pueda acceder a ella.
-
Ingrese la dirección IP o el nombre de host de la máquina host del agente de consola para que el sistema de clasificación de datos pueda acceder a ella.
Alternativamente, puedes crear el comando completo por adelantado, proporcionando los parámetros de host necesarios:
sudo ./install.sh -a <account_id> -c <client_id> -t <user_token> --host <ds_host> --manager-host <cm_host> --no-proxy --darksiteValores variables:
-
account_id = ID de cuenta de NetApp
-
client_id = ID de cliente del agente de consola (agregue el sufijo "clients" al ID de cliente si aún no está allí)
-
user_token = token de acceso de usuario JWT
-
ds_host = dirección IP o nombre de host del sistema de Data Classification.
-
cm_host = dirección IP o nombre de host del sistema del agente de consola.
-
El instalador de Data Classification instala paquetes, registra la instalación e instala Data Classification. La instalación puede tardar entre 10 y 20 minutos.
Si hay conectividad a través del puerto 8080 entre el equipo host y la instancia del agente de la Consola, verás el progreso de la instalación en la pestaña Clasificación de datos.
Desde la página de configuración puedes seleccionar la "clusters ONTAP on-premises" local y la "bases de datos" que quieres escanear.
Actualiza el software de clasificación de datos
Dado que el software de clasificación de datos se actualiza con nuevas funciones de forma periódica, deberías acostumbrarte a buscar nuevas versiones de vez en cuando para asegurarte de que estás usando el software y las funciones más recientes. Tendrás que actualizar el software de clasificación de datos manualmente porque no hay conectividad a internet para hacer la actualización automáticamente.
-
Te recomendamos que tu software del agente de la consola esté actualizado a la versión más reciente disponible. "Consulta los pasos para actualizar el agente de la consola".
-
A partir de la versión 1.24 de Data Classification puedes realizar actualizaciones a cualquier versión futura del software.
Si tu software de Data Classification está en una versión anterior a la 1.24, solo puedes actualizar una versión principal a la vez. Por ejemplo, si tienes instalada la versión 1.21.x, solo puedes actualizar a la 1.22.x. Si estás varias versiones principales atrás, tendrás que actualizar el software varias veces.
-
En un sistema configurado para internet, descarga el software de Data Classification desde el "Sitio de soporte de NetApp". El archivo que debes seleccionar se llama DataSense-offline-bundle-<version>.tar.gz.
-
Copia el paquete de software en el host Linux donde está instalado Data Classification en el sitio oscuro.
-
Descomprime el paquete de software en el equipo host, por ejemplo:
tar -xvf DataSense-offline-bundle-v1.25.0.tar.gzEsto extrae el archivo de instalación cc_onprem_installer.tar.gz.
-
Descomprime el archivo de instalación en la máquina anfitriona, por ejemplo:
tar -xzf cc_onprem_installer.tar.gzEsto extrae el script de actualización start_darksite_upgrade.sh y cualquier software de terceros necesario.
-
Ejecuta el script de actualización en la máquina host, por ejemplo:
start_darksite_upgrade.sh
El software de Data Classification se actualiza en tu host. La actualización puede tardar de 5 a 10 minutos.
Puedes verificar que el software se ha actualizado revisando la versión en la parte inferior de las páginas de la interfaz de usuario de Data Classification.