

Actualizar una configuración IP de MetroCluster de cuatro u ocho nodos (ONTAP 9,8 y versiones posteriores)
 Sugerir cambios
Sugerir cambios
Este procedimiento se puede usar para actualizar controladoras y almacenamiento en configuraciones de cuatro o ocho nodos.
A partir de ONTAP 9.13.1, puede actualizar las controladoras y el almacenamiento en una configuración IP de MetroCluster de ocho nodos si se amplía la configuración para convertirse en una configuración temporal de doce nodos y, a continuación, se eliminan los grupos anteriores de recuperación ante desastres.
A partir de ONTAP 9,8, puede actualizar las controladoras y el almacenamiento en una configuración IP de MetroCluster de cuatro nodos ampliando la configuración para convertirse en una configuración temporal de ocho nodos y, luego, eliminando el grupo anterior de recuperación ante desastres.
La siguiente guía es para un escenario poco común en el que necesita agregar un modelo de plataforma más antiguo (plataformas lanzadas antes de ONTAP 9.15.1) a una configuración de MetroCluster existente que contiene un modelo de plataforma más nuevo (plataformas lanzadas en ONTAP 9.15.1 o posterior).
Si su configuración de MetroCluster existente contiene una plataforma que utiliza puertos de clúster/HA compartidos (plataformas lanzadas en ONTAP 9.15.1 o posterior), no puede agregar una plataforma que utilice puertos de MetroCluster/HA compartidos (plataformas lanzadas antes de ONTAP 9.15.1) sin actualizar todos los nodos en la configuración a ONTAP 9.15.1P11 u ONTAP 9.16.1P4 o posterior.

|
Agregar un modelo de plataforma más antiguo que usa puertos HA/ MetroCluster compartidos a un MetroCluster que contiene un modelo de plataforma más nuevo que usa puertos HA/clúster compartidos es un escenario poco común y la mayoría de las combinaciones no se ven afectadas. |
Utilice la siguiente tabla para verificar si su combinación está afectada. Si su plataforma existente aparece en la primera columna y la plataforma que desea agregar a la configuración aparece en la segunda columna, todos los nodos de la configuración deben ejecutar ONTAP 9.15.1P11 u ONTAP 9.16.1P4 o posterior para agregar el nuevo grupo de DR.
| Si su MetroCluster existente contiene… | Y la plataforma que estás agregando es… | Realice lo siguiente… | ||
|---|---|---|---|---|
Un sistema AFF que utiliza puertos de alta disponibilidad/clúster compartidos:
|
Un sistema FAS que utiliza puertos de alta disponibilidad/clúster compartidos:
|
Un sistema AFF que utiliza puertos MetroCluster/HA compartidos:
|
Un sistema FAS que utiliza puertos MetroCluster/HA compartidos:
|
Antes de agregar la nueva plataforma a su configuración existente de MetroCluster, actualice todos los nodos en la configuración existente y nueva a ONTAP 9.15.1P11 u ONTAP 9.16.1P4 o posterior. |
-
Si tiene una configuración de ocho nodos, el sistema debe ejecutar ONTAP 9.13.1 o una versión posterior.
-
Si tiene una configuración de cuatro nodos, el sistema debe ejecutar ONTAP 9,8 o una versión posterior.
-
Si también va a actualizar los switches IP, debe actualizarlos antes de realizar este procedimiento de actualización.
-
Este procedimiento describe los pasos necesarios para actualizar un grupo de DR de cuatro nodos. Si tiene una configuración de ocho nodos (dos grupos de DR), puede actualizar uno o ambos grupos de DR.
Refresh DR groups one at a time. * References to "old nodes" mean the nodes that you intend to replace. * For eight-node configurations, the source and target eight-node MetroCluster platform combination must be supported.

Si se actualizan ambos grupos de recuperación de desastres, es posible que la combinación de la plataforma no sea compatible después de actualizar el primer grupo de recuperación de desastres. Debe actualizar ambos grupos de recuperación de desastres para lograr una configuración de ocho nodos compatible. -
Solo puede actualizar modelos de plataforma específicos mediante este procedimiento en una configuración IP de MetroCluster.
-
Para obtener información sobre qué combinaciones de actualización de plataformas son compatibles, revise la tabla de actualización de IP de MetroCluster en "Seleccione un método de actualización del sistema".
-
-
Se aplican los límites inferiores de las plataformas de origen y destino. Si realiza la transición a una plataforma superior, los límites de la nueva plataforma se aplican únicamente después de que se haya completado la actualización tecnológica de todos los grupos de recuperación ante desastres.
-
Si realiza una actualización tecnológica a una plataforma con límites inferiores a los de la plataforma de origen, debe ajustar y reducir los límites para que estén en los límites de la plataforma de destino o por debajo de ellos antes de realizar este procedimiento.
Active el registro de la consola
NetApp recomienda encarecidamente que habilite el inicio de sesión de la consola en los dispositivos que esté utilizando y realice las siguientes acciones al realizar este procedimiento:
-
Deje la función AutoSupport habilitada durante el mantenimiento.
-
Active un mensaje de AutoSupport de mantenimiento antes y después de las tareas de mantenimiento para deshabilitar la creación de casos durante la actividad de mantenimiento.
Consulte el artículo de la base de conocimientos "Cómo impedir la creación automática de casos durante las ventanas de mantenimiento programado".
-
Habilite el registro de sesiones para cualquier sesión de CLI. Para obtener instrucciones sobre cómo activar el registro de sesiones, consulte la sección Salida de sesión de registro en el artículo de la Base de conocimientos "Cómo configurar PuTTY para una conectividad óptima con sistemas ONTAP".
Realice el procedimiento de actualización
Utilice los siguientes pasos para actualizar la configuración de IP de MetroCluster.
-
Compruebe que tiene un dominio de retransmisión predeterminado creado en los nodos antiguos.
Cuando se añaden nodos nuevos a un clúster existente sin un dominio de retransmisión predeterminado, las LIF de gestión de nodos se crean para los nodos nuevos mediante identificadores únicos universales (UUID) en lugar de los nombres esperados. Para obtener más información, vea el artículo de la base de conocimientos "LIF de gestión de nodos en los nodos recién añadidos generados con nombres UUID".
-
Recopile información de los nodos antiguos.
En este momento, la configuración de cuatro nodos aparece como se muestra en la siguiente imagen:
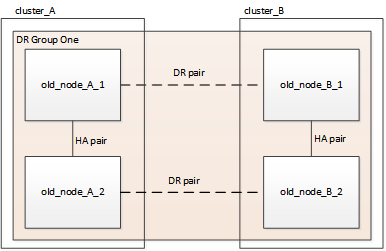
La configuración de ocho nodos aparece tal y como se muestra en la siguiente imagen:
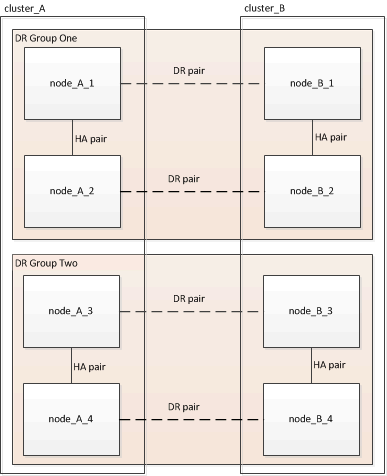
-
Para evitar la generación automática de casos de soporte, envíe un mensaje de AutoSupport para indicar que la actualización está en curso.
-
Emita el siguiente comando:
system node autosupport invoke -node * -type all -message "MAINT=10h Upgrading old-model to new-model"El siguiente ejemplo especifica una ventana de mantenimiento de 10 horas. Permita tiempo adicional dependiendo de su plan.
Si el mantenimiento se completa antes de que haya transcurrido el tiempo, puede invocar un mensaje de AutoSupport que indique el final del período de mantenimiento:
system node autosupport invoke -node * -type all -message MAINT=end-
Repita el comando en el clúster de partners.
-
-
Si el cifrado de extremo a extremo está activado, siga los pasos a. "Deshabilite el cifrado integral".
-
Elimine la configuración de MetroCluster existente de tiebreaker, Mediator u otro software que pueda iniciar la conmutación.
Si está usando…
Utilice este procedimiento…
Tiebreaker
-
Utilice la CLI de Tiebreaker
monitor removeComando para quitar la configuración de MetroCluster.En el siguiente ejemplo, «'cluster_A'» se elimina del software:
NetApp MetroCluster Tiebreaker :> monitor remove -monitor-name cluster_A Successfully removed monitor from NetApp MetroCluster Tiebreaker software.
-
Para confirmar que la configuración de MetroCluster se elimina correctamente mediante la CLI de tiebreaker
monitor show -statuscomando.NetApp MetroCluster Tiebreaker :> monitor show -status
Mediador
Ejecute el siguiente comando desde el símbolo del sistema de ONTAP:
metrocluster configuration-settings mediator removeAplicaciones de terceros
Consulte la documentación del producto.
-
-
Realice todos los pasos de "Ampliación de una configuración IP de MetroCluster" para añadir los nodos nuevos y el almacenamiento a la configuración.
Una vez finalizado el procedimiento de expansión, la configuración temporal aparece como se muestra en las siguientes imágenes:
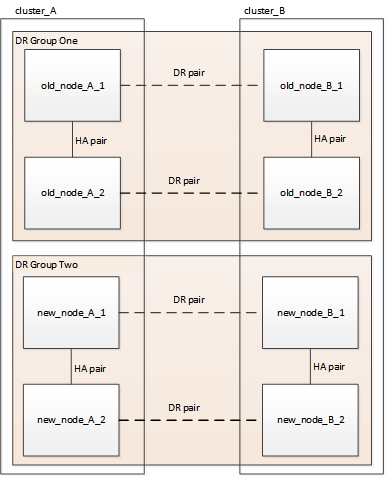 Figura 1. Configuración temporal de ocho nodos
Figura 1. Configuración temporal de ocho nodos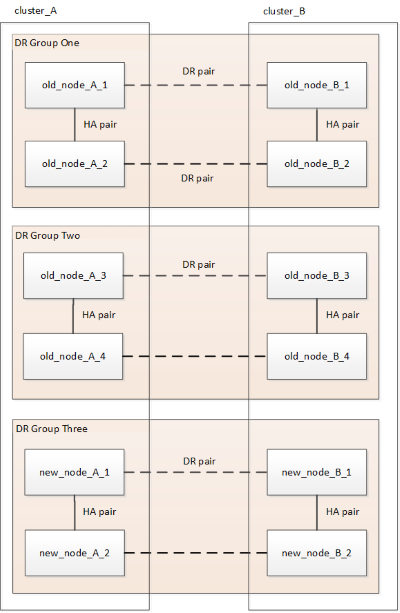 Figura 2. Configuración temporal con doce nodos
Figura 2. Configuración temporal con doce nodos -
Confirme que la toma de control es posible y que los nodos están conectados ejecutando el siguiente comando en ambos clústeres:
storage failover showcluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------------- --------- ------------------ Node_FC_1 Node_FC_2 true Connected to Node_FC_2 Node_FC_2 Node_FC_1 true Connected to Node_FC_1 Node_IP_1 Node_IP_2 true Connected to Node_IP_2 Node_IP_2 Node_IP_1 true Connected to Node_IP_1 -
Mueva los volúmenes CRS.
Siga los pasos de "Mover un volumen de metadatos en configuraciones de MetroCluster".
-
Mueva los datos de los nodos antiguos a los nodos nuevos siguiendo los siguientes procedimientos:
-
Realice todos los pasos de "Cree un agregado y mueva volúmenes a los nuevos nodos".
Puede optar por reflejar el agregado cuando o después de crearlo. -
Realice todos los pasos de "Mueva LIF de datos que no sean SAN y LIF de gestión de clúster a los nuevos nodos".
-
-
Modifique la dirección IP del par de clústeres de los nodos transitados para cada clúster:
-
Identifique el cluster_A peer mediante el
cluster peer showcomando:cluster_A::> cluster peer show Peer Cluster Name Cluster Serial Number Availability Authentication ------------------------- --------------------- -------------- -------------- cluster_B 1-80-000011 Unavailable absent
-
Modifique la dirección IP del mismo nivel cluster_A:
cluster peer modify -cluster cluster_A -peer-addrs node_A_3_IP -address-family ipv4
-
-
Identifique el par cluster_B mediante el
cluster peer showcomando:cluster_B::> cluster peer show Peer Cluster Name Cluster Serial Number Availability Authentication ------------------------- --------------------- -------------- -------------- cluster_A 1-80-000011 Unavailable absent
-
Modifique la dirección IP del mismo nivel cluster_B:
cluster peer modify -cluster cluster_B -peer-addrs node_B_3_IP -address-family ipv4
-
-
Compruebe que la dirección IP de paridad del clúster se haya actualizado para cada clúster:
-
Compruebe que la dirección IP se haya actualizado para cada clúster mediante el
cluster peer show -instancecomando.La
Remote Intercluster AddressesEn los siguientes ejemplos, se muestra la dirección IP actualizada.Ejemplo de cluster_A:
cluster_A::> cluster peer show -instance Peer Cluster Name: cluster_B Remote Intercluster Addresses: 172.21.178.204, 172.21.178.212 Availability of the Remote Cluster: Available Remote Cluster Name: cluster_B Active IP Addresses: 172.21.178.212, 172.21.178.204 Cluster Serial Number: 1-80-000011 Remote Cluster Nodes: node_B_3-IP, node_B_4-IP Remote Cluster Health: true Unreachable Local Nodes: - Address Family of Relationship: ipv4 Authentication Status Administrative: use-authentication Authentication Status Operational: ok Last Update Time: 4/20/2023 18:23:53 IPspace for the Relationship: Default Proposed Setting for Encryption of Inter-Cluster Communication: - Encryption Protocol For Inter-Cluster Communication: tls-psk Algorithm By Which the PSK Was Derived: jpake cluster_A::>+ Ejemplo de cluster_B
-
cluster_B::> cluster peer show -instance Peer Cluster Name: cluster_A Remote Intercluster Addresses: 172.21.178.188, 172.21.178.196 <<<<<<<< Should reflect the modified address Availability of the Remote Cluster: Available Remote Cluster Name: cluster_A Active IP Addresses: 172.21.178.196, 172.21.178.188 Cluster Serial Number: 1-80-000011 Remote Cluster Nodes: node_A_3-IP, node_A_4-IP Remote Cluster Health: true Unreachable Local Nodes: - Address Family of Relationship: ipv4 Authentication Status Administrative: use-authentication Authentication Status Operational: ok Last Update Time: 4/20/2023 18:23:53 IPspace for the Relationship: Default Proposed Setting for Encryption of Inter-Cluster Communication: - Encryption Protocol For Inter-Cluster Communication: tls-psk Algorithm By Which the PSK Was Derived: jpake cluster_B::> -
-
Siga los pasos de "Eliminación de un grupo de recuperación ante desastres" Para eliminar el grupo de recuperación ante desastres antiguo.
-
Si necesita actualizar ambos grupos de DR en una configuración de ocho nodos, repita todo el procedimiento para cada grupo de DR.
Después de eliminar el grupo de DR antiguo, la configuración aparece como se muestra en las siguientes imágenes:
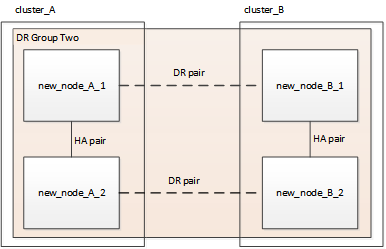 Figura 3. Configuración con cuatro nodos
Figura 3. Configuración con cuatro nodos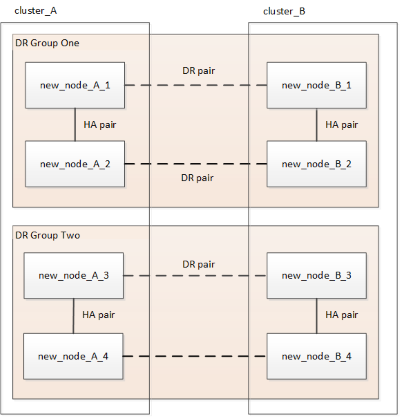 Figura 4. Configuración con ocho nodos
Figura 4. Configuración con ocho nodos -
Confirmar el modo operativo de la configuración de MetroCluster y realizar una comprobación de MetroCluster.
-
Confirme la configuración del MetroCluster y que el modo operativo es normal:
metrocluster show -
Confirme que se muestran todos los nodos esperados:
metrocluster node show -
Emita el siguiente comando:
metrocluster check run -
Mostrar los resultados de la comprobación de MetroCluster:
metrocluster check show
-
-
Si deshabilitó el cifrado de extremo a extremo antes de añadir los nodos nuevos, puede volver a habilitarlo siguiendo los pasos de "Habilite el cifrado integral".
-
Restaure la supervisión si es necesario, siguiendo el procedimiento para su configuración.
Si está usando…
Utilice este procedimiento
Tiebreaker
"Adición de configuraciones de MetroCluster" en Instalación y configuración de MetroCluster Tiebreaker.
Mediador
"Configurar ONTAP Mediator desde una configuración IP de MetroCluster" en Instalación y configuración de IP de MetroCluster.
Aplicaciones de terceros
Consulte la documentación del producto.
-
Para reanudar la generación automática de casos de soporte, envíe un mensaje de AutoSupport para indicar que se ha completado el mantenimiento.
-
Emita el siguiente comando:
system node autosupport invoke -node * -type all -message MAINT=end -
Repita el comando en el clúster de partners.
-