Créer des relations de synchronisation dans NetApp Copy and Sync
 Suggérer des modifications
Suggérer des modifications
Lorsque vous créez une relation de synchronisation, NetApp Copy and Sync copie les fichiers de la source vers la cible. Après la copie initiale, la fonction Copier et synchroniser synchronise toutes les données modifiées toutes les 24 heures.
Avant de pouvoir créer certains types de relations de synchronisation, vous devez d’abord créer un système dans la NetApp Console.
Créer des relations de synchronisation pour des types spécifiques de systèmes
Si vous souhaitez créer des relations de synchronisation pour l’un des éléments suivants, vous devez d’abord créer ou découvrir le système :
-
Amazon FSx pour ONTAP
-
Azure NetApp Files
-
Cloud Volumes ONTAP
-
Clusters ONTAP sur site
-
Créer ou découvrir le système.
-
Sélectionnez Page Systèmes.
-
Sélectionnez un système qui correspond à l’un des types répertoriés ci-dessus.
-
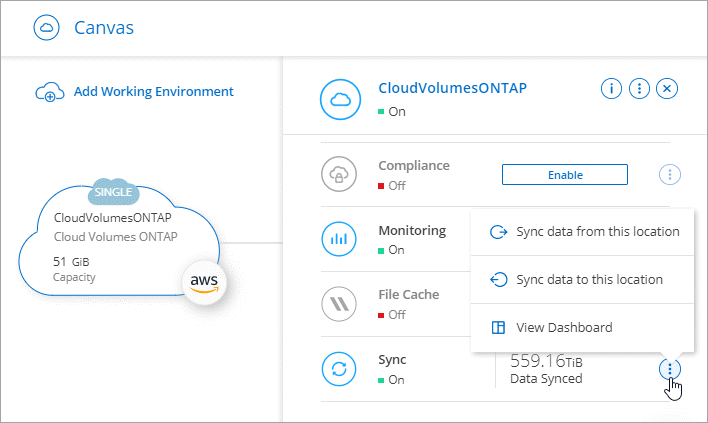
Sélectionnez le menu d’action à côté de Synchroniser.
-
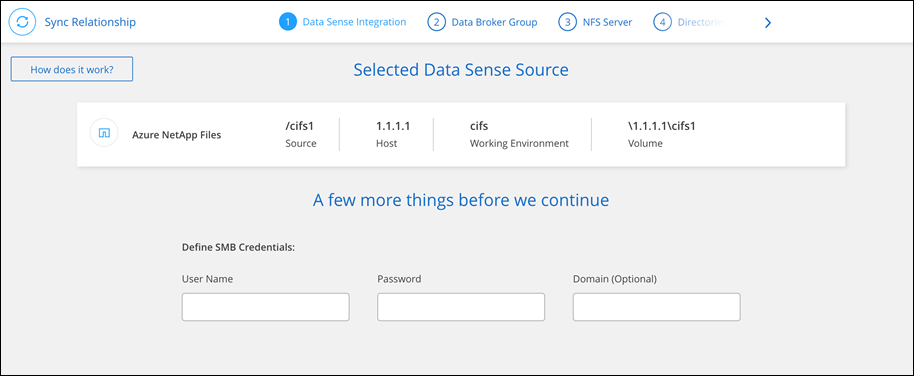
Sélectionnez Synchroniser les données à partir de cet emplacement ou Synchroniser les données vers cet emplacement et suivez les instructions pour configurer la relation de synchronisation.
Créer d'autres types de relations de synchronisation
Suivez ces étapes pour synchroniser les données vers ou depuis un type de stockage pris en charge autre qu’Amazon Amazon FSx pour ONTAP, Azure NetApp Files, Cloud Volumes ONTAP ou les clusters ONTAP sur site. Les étapes ci-dessous fournissent un exemple qui montre comment configurer une relation de synchronisation entre un serveur NFS et un bucket S3.
-
Dans la NetApp Console, sélectionnez Synchroniser.
-
Sur la page Définir la relation de synchronisation, choisissez une source et une cible.
Les étapes suivantes fournissent un exemple de création d’une relation de synchronisation entre un serveur NFS et un bucket S3.
-
Sur la page Serveur NFS, saisissez l'adresse IP ou le nom de domaine complet du serveur NFS que vous souhaitez synchroniser avec AWS.
-
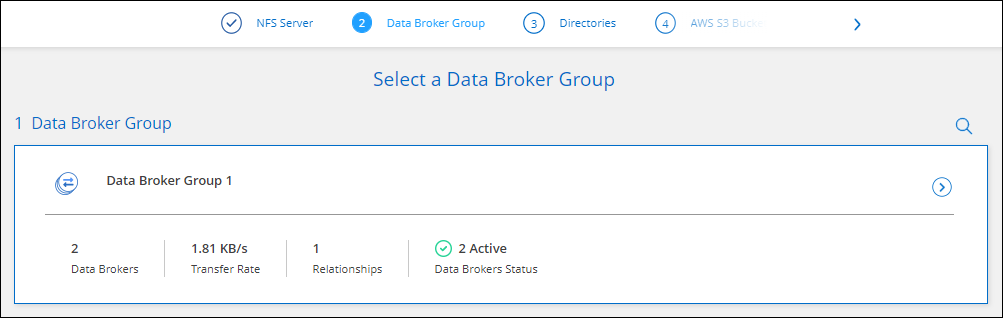
Sur la page Groupe de courtiers de données, suivez les invites pour créer une machine virtuelle de courtier de données dans AWS, Azure ou Google Cloud Platform, ou pour installer le logiciel de courtier de données sur un hôte Linux existant.
Pour plus de détails, reportez-vous aux pages suivantes :
-
Après avoir installé le courtier de données, sélectionnez Continuer.
-
Sur la page Répertoires, sélectionnez un répertoire ou un sous-répertoire de niveau supérieur.
Si la copie et la synchronisation ne parviennent pas à récupérer les exportations, sélectionnez Ajouter une exportation manuellement et saisissez le nom d'une exportation NFS.

Si vous souhaitez synchroniser plusieurs répertoires sur le serveur NFS, vous devez créer des relations de synchronisation supplémentaires une fois l'opération terminée. -
Sur la page AWS S3 Bucket, sélectionnez un bucket :
-
Accédez à un dossier existant dans le bucket ou sélectionnez un nouveau dossier que vous créez dans le bucket.
-
Sélectionnez Ajouter à la liste pour sélectionner un compartiment S3 qui n'est pas associé à votre compte AWS. "Des autorisations spécifiques doivent être appliquées au bucket S3" .
-
-
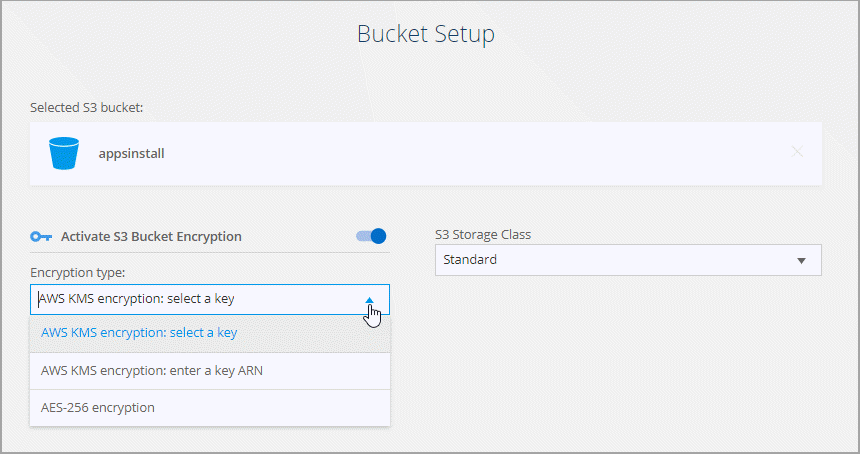
Sur la page Configuration du bucket, configurez le bucket :
-
Choisissez d'activer ou non le chiffrement du compartiment S3, puis sélectionnez une clé AWS KMS, saisissez l'ARN d'une clé KMS ou sélectionnez le chiffrement AES-256.
-
Sélectionnez une classe de stockage S3. "Afficher les classes de stockage prises en charge" .
-
-
Sur la page Paramètres, définissez comment les fichiers et dossiers sources sont synchronisés et conservés dans l'emplacement cible :
- Calendrier
-
Choisissez un calendrier récurrent pour les synchronisations futures ou désactivez le calendrier de synchronisation. Vous pouvez planifier une relation pour synchroniser les données aussi souvent que toutes les 1 minute.
- Délai de synchronisation expiré
-
Définissez si la copie et la synchronisation doivent annuler une synchronisation de données si la synchronisation n'est pas terminée dans le nombre de minutes, d'heures ou de jours spécifié.
- Notifications
-
Vous permet de choisir de recevoir ou non des notifications de copie et de synchronisation dans le centre de notifications de la console NetApp . Vous pouvez activer les notifications pour les synchronisations de données réussies, les synchronisations de données ayant échoué et les synchronisations de données annulées.
- Nouvelles tentatives
-
Définissez le nombre de fois que Copier et Synchroniser doivent réessayer de synchroniser un fichier avant de l'ignorer.
- Synchronisation continue
-
Après la synchronisation initiale des données, Copy and Sync écoute les modifications sur le bucket S3 source ou le bucket Google Cloud Storage et synchronise en continu toutes les modifications sur la cible au fur et à mesure qu'elles se produisent. Il n’est pas nécessaire de réanalyser la source à intervalles réguliers.
Ce paramètre est disponible uniquement lors de la création d'une relation de synchronisation et lorsque vous synchronisez des données d'un compartiment S3 ou de Google Cloud Storage vers Azure Blob Storage, CIFS, Google Cloud Storage, IBM Cloud Object Storage, NFS, S3 et StorageGRID ou d'Azure Blob Storage vers Azure Blob Storage, CIFS, Google Cloud Storage, IBM Cloud Object Storage, NFS et StorageGRID.
Si vous activez ce paramètre, cela affecte d’autres fonctionnalités comme suit :
-
La planification de synchronisation est désactivée.
-
Les paramètres suivants sont rétablis à leurs valeurs par défaut : Délai de synchronisation, Fichiers récemment modifiés et Date de modification.
-
Si S3 est la source, le filtre par taille sera actif uniquement sur les événements de copie (pas sur les événements de suppression).
-
Une fois la relation créée, vous pouvez uniquement l'accélérer ou la supprimer. Vous ne pouvez pas interrompre les synchronisations, modifier les paramètres ou afficher les rapports.
Il est possible de créer une relation de synchronisation continue avec un bucket externe. Pour ce faire, suivez ces étapes :
-
Accédez à la console Google Cloud pour le projet du bucket externe.
-
Accédez à Stockage Cloud > Paramètres > Compte de service de stockage Cloud.
-
Mettre à jour le fichier local.json :
{ "protocols": { "gcp": { "storage-account-email": <storage account email> } } } -
Redémarrez le courtier de données :
-
sudo pm2 arrêter tout
-
sudo pm2 démarrer tout
-
-
Créez une relation de synchronisation continue avec le bucket externe concerné.
Un courtier de données utilisé pour créer une relation de synchronisation continue avec un bucket externe ne pourra pas créer une autre relation de synchronisation continue avec un bucket de son projet.
-
-
- Comparer par
-
Choisissez si Copier et Synchroniser doivent comparer certains attributs pour déterminer si un fichier ou un répertoire a changé et doit être à nouveau synchronisé.
Même si vous décochez ces attributs, Copy and Sync compare toujours la source à la cible en vérifiant les chemins, les tailles de fichiers et les noms de fichiers. S'il y a des modifications, il synchronise ces fichiers et répertoires.
Vous pouvez choisir d'activer ou de désactiver la copie et la synchronisation en comparant les attributs suivants :
-
mtime : L'heure de la dernière modification d'un fichier. Cet attribut n'est pas valide pour les répertoires.
-
uid, gid et mode : indicateurs d'autorisation pour Linux.
-
- Copie pour les objets
-
Activez cette option pour copier les métadonnées et les balises de stockage d'objets. Si un utilisateur modifie les métadonnées de la source, Copier et Sync copie cet objet lors de la prochaine synchronisation, mais si un utilisateur modifie les balises de la source (et non les données elles-mêmes), Copier et Sync ne copie pas l'objet lors de la prochaine synchronisation.
Vous ne pouvez pas modifier cette option après avoir créé la relation.
La copie de balises est prise en charge avec les relations de synchronisation qui incluent Azure Blob ou un point de terminaison compatible S3 (S3, StorageGRID ou IBM Cloud Object Storage) comme cible.
La copie des métadonnées est prise en charge avec des relations « cloud à cloud » entre l’un des points de terminaison suivants :
-
AWS S3
-
Azure Blob
-
Stockage Google Cloud
-
Stockage d'objets IBM Cloud
-
StorageGRID
-
- Fichiers récemment modifiés
-
Choisissez d’exclure les fichiers qui ont été récemment modifiés avant la synchronisation planifiée.
- Supprimer les fichiers sur la source
-
Choisissez de supprimer les fichiers de l'emplacement source après que Copier et synchroniser ait copié les fichiers vers l'emplacement cible. Cette option comporte un risque de perte de données car les fichiers sources sont supprimés après avoir été copiés.
Si vous activez cette option, vous devez également modifier un paramètre dans le fichier local.json sur le courtier de données. Ouvrez le fichier et mettez-le à jour comme suit :
{ "workers":{ "transferrer":{ "delete-on-source": true } } }Après avoir mis à jour le fichier local.json, vous devez effectuer un redémarrage :
pm2 restart all. - Supprimer les fichiers sur la cible
-
Choisissez de supprimer les fichiers de l’emplacement cible, s’ils ont été supprimés de la source. La valeur par défaut est de ne jamais supprimer les fichiers de l'emplacement cible.
- Types de fichiers
-
Définissez les types de fichiers à inclure dans chaque synchronisation : fichiers, répertoires, liens symboliques et liens physiques.
Les liens physiques ne sont disponibles que pour les relations NFS à NFS non sécurisées. Les utilisateurs seront limités à un processus de scanner et à une concurrence de scanner, et les analyses doivent être exécutées à partir d'un répertoire racine. - Exclure les extensions de fichiers
-
Spécifiez l'expression régulière ou les extensions de fichier à exclure de la synchronisation en saisissant l'extension de fichier et en appuyant sur Entrée. Par exemple, tapez log ou .log pour exclure les fichiers *.log. Un séparateur n'est pas nécessaire pour plusieurs extensions. La vidéo suivante fournit une courte démonstration :
Exclure les extensions de fichier pour une relation de synchronisation
Les expressions régulières, ou Regex, diffèrent des caractères génériques ou des expressions glob. Cette fonctionnalité fonctionne uniquement avec les expressions régulières. - Exclure les répertoires
-
Spécifiez un maximum de 15 expressions régulières ou répertoires à exclure de la synchronisation en saisissant leur nom ou le chemin complet du répertoire et en appuyant sur Entrée. Les répertoires .copy-offload, .snapshot, ~snapshot sont exclus par défaut.
Les expressions régulières, ou Regex, diffèrent des caractères génériques ou des expressions glob. Cette fonctionnalité fonctionne uniquement avec les expressions régulières. - Taille du fichier
-
Choisissez de synchroniser tous les fichiers quelle que soit leur taille ou uniquement les fichiers qui se trouvent dans une plage de taille spécifique.
- Date de modification
-
Sélectionnez tous les fichiers quelle que soit leur date de dernière modification, les fichiers modifiés après une date spécifique, avant une date spécifique ou entre une période donnée.
- Date de création
-
Lorsqu'un serveur SMB est la source, ce paramètre vous permet de synchroniser les fichiers créés après une date spécifique, avant une date spécifique ou entre une plage horaire spécifique.
- ACL - Liste de contrôle d'accès
-
Copiez uniquement les ACL, uniquement les fichiers ou les ACL et les fichiers à partir d'un serveur SMB en activant un paramètre lorsque vous créez une relation ou après avoir créé une relation.
-
Sur la page Tags/Métadonnées, choisissez d'enregistrer une paire clé-valeur en tant que balise sur tous les fichiers transférés vers le bucket S3 ou d'attribuer une paire clé-valeur de métadonnées à tous les fichiers.
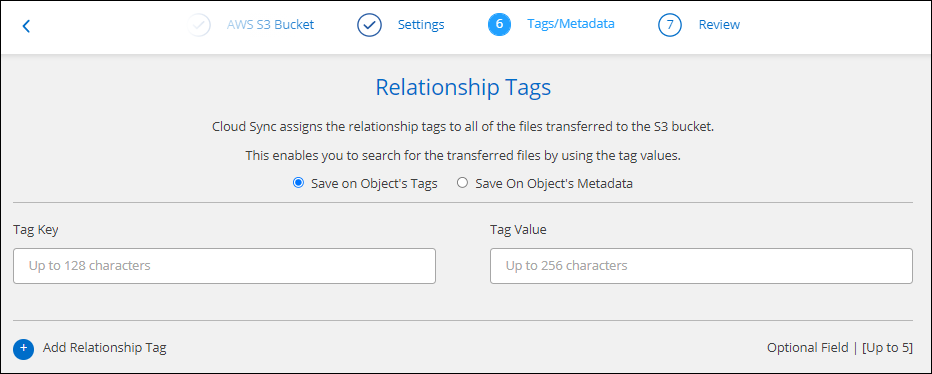

Cette même fonctionnalité est disponible lors de la synchronisation des données avec StorageGRID et IBM Cloud Object Storage. Pour Azure et Google Cloud Storage, seule l’option métadonnées est disponible. -
Vérifiez les détails de la relation de synchronisation, puis sélectionnez Créer une relation.
Résultat
Copier et synchroniser démarre la synchronisation des données entre la source et la cible. Des statistiques de synchronisation sur la durée de la synchronisation, si elle s'est arrêtée et le nombre de fichiers copiés, analysés ou supprimés sont disponibles. Vous pouvez ensuite gérer votre "synchroniser les relations" , "gérez vos courtiers en données" , ou "créer des rapports pour optimiser vos performances et votre configuration" .
Créer des relations de synchronisation à partir de la NetApp Data Classification
Copy and Sync est intégré à NetApp Data Classification. Depuis NetApp Data Classification, vous pouvez sélectionner les fichiers sources que vous souhaitez synchroniser avec un emplacement cible à l'aide de Copier et synchroniser.
Une fois que vous avez lancé une synchronisation de données à partir de NetApp Data Classification, toutes les informations sources sont contenues dans une seule étape et ne nécessitent que la saisie de quelques détails clés. Vous choisissez ensuite l’emplacement cible de la nouvelle relation de synchronisation.