

Suddivisione dei dati in livelli dai cluster ONTAP locali allo storage BLOB di Azure in NetApp Cloud Tiering
 Suggerisci modifiche
Suggerisci modifiche
Libera spazio sui tuoi cluster ONTAP locali suddividendo i dati inattivi in livelli di archiviazione BLOB di Azure.
Avvio rapido
Inizia subito seguendo questi passaggi oppure scorri verso il basso fino alle sezioni rimanenti per i dettagli completi.
 Prepararsi a suddividere i dati in livelli nell'archiviazione BLOB di Azure
Prepararsi a suddividere i dati in livelli nell'archiviazione BLOB di AzureTi occorre quanto segue:
-
Un cluster ONTAP locale di origine che esegue ONTAP 9.4 o versione successiva aggiunto alla NetApp Console e una connessione HTTPS all'archiviazione BLOB di Azure. "Scopri come scoprire un cluster" .
-
Un agente Console installato in una rete virtuale di Azure o in sede.
-
Rete per un agente che consente una connessione HTTPS in uscita al cluster ONTAP nel data center, all'archiviazione di Azure e al servizio Cloud Tiering.
 Imposta livelli
Imposta livelliNella NetApp Console, seleziona un sistema ONTAP locale, seleziona Abilita per il servizio di suddivisione in livelli e segui le istruzioni per suddividere i dati in livelli nell'archiviazione BLOB di Azure.
 Impostare la licenza
Impostare la licenzaAl termine del periodo di prova gratuito, puoi pagare Cloud Tiering tramite un abbonamento pay-as-you-go, una licenza BYOL ONTAP Cloud Tiering o una combinazione di entrambi:
-
Per abbonarsi da Azure Marketplace, "vai all'offerta Marketplace" , seleziona Iscriviti e segui le istruzioni.
-
Per pagare utilizzando una licenza Cloud Tiering BYOL, contattaci se devi acquistarne una, quindi"aggiungilo alla NetApp Console" .
Requisiti
Verifica il supporto per il tuo cluster ONTAP , configura la rete e prepara l'archiviazione degli oggetti.
L'immagine seguente mostra ciascun componente e le connessioni che è necessario predisporre tra di essi:
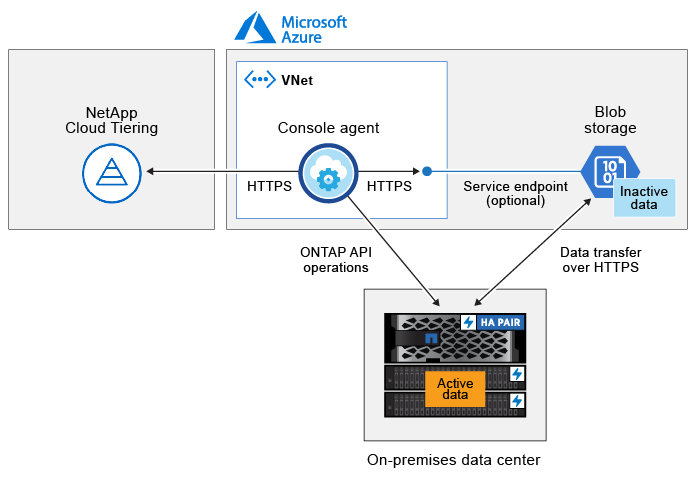

|
La comunicazione tra l'agente della console e l'archiviazione BLOB è riservata alla configurazione dell'archiviazione degli oggetti. L'agente può risiedere presso la tua sede anziché nel cloud. |
Prepara i tuoi cluster ONTAP
I cluster ONTAP devono soddisfare i seguenti requisiti quando si suddividono i dati in livelli nell'archiviazione BLOB di Azure.
- Piattaforme ONTAP supportate
-
-
Quando si utilizza ONTAP 9.8 e versioni successive: è possibile suddividere i dati dai sistemi AFF o dai sistemi FAS con aggregati tutti SSD o tutti HDD.
-
Quando si utilizza ONTAP 9.7 e versioni precedenti: è possibile suddividere in livelli i dati provenienti da sistemi AFF o sistemi FAS con aggregati completamente SSD.
-
- Versione ONTAP supportata
-
ONTAP 9.4 o successivo
- Requisiti di rete del cluster
-
-
Il cluster ONTAP avvia una connessione HTTPS tramite la porta 443 all'archiviazione BLOB di Azure.
ONTAP legge e scrive dati da e verso l'archiviazione di oggetti. L'archiviazione degli oggetti non si avvia mai, risponde e basta.
Sebbene ExpressRoute offra prestazioni migliori e costi di trasferimento dati inferiori, non è obbligatorio tra il cluster ONTAP e l'archiviazione BLOB di Azure. Ma questa è la prassi migliore consigliata.
-
È richiesta una connessione in ingresso dall'agente, che può risiedere in una rete virtuale di Azure o nei locali dell'utente.
Non è richiesta una connessione tra il cluster e il servizio Cloud Tiering.
-
È necessario un LIF intercluster su ciascun nodo ONTAP che ospita i volumi che si desidera suddividere in livelli. Il LIF deve essere associato allo IPspace che ONTAP deve utilizzare per connettersi all'archiviazione degli oggetti.
Quando si imposta il tiering dei dati, Cloud Tiering richiede lo spazio IP da utilizzare. Dovresti scegliere lo spazio IP a cui è associato ciascun LIF. Potrebbe trattarsi dello spazio IP "predefinito" o di uno spazio IP personalizzato creato da te. Scopri di più su "LIF" E "Spazi IP" .
-
- Volumi e aggregati supportati
-
Il numero totale di volumi che Cloud Tiering può suddividere in livelli potrebbe essere inferiore al numero di volumi presenti nel sistema ONTAP . Questo perché i volumi non possono essere suddivisi in livelli da alcuni aggregati. Fare riferimento alla documentazione ONTAP per "funzionalità o caratteristiche non supportate da FabricPool" .
|
|
Cloud Tiering supporta i volumi FlexGroup , a partire da ONTAP 9.5. L'installazione funziona come per qualsiasi altro volume. |
Scopri un cluster ONTAP
Prima di poter iniziare a suddividere in livelli i dati inattivi, è necessario aggiungere un sistema ONTAP locale alla NetApp Console .
Crea o cambia agenti
È necessario un agente per distribuire i dati sul cloud. Quando si suddividono i dati in livelli nell'archiviazione BLOB di Azure, è possibile utilizzare un agente presente in una rete virtuale di Azure o in sede. Sarà necessario creare un nuovo agente e assicurarsi che l'agente attualmente selezionato risieda in Azure o in locale.
Verifica di disporre delle autorizzazioni necessarie per l'agente
Se hai creato l'agente Console utilizzando la versione 3.9.25 o successiva, sei a posto. Il ruolo personalizzato che fornisce le autorizzazioni necessarie a un agente per gestire risorse e processi all'interno della rete Azure verrà configurato per impostazione predefinita. Vedi il "autorizzazioni di ruolo personalizzate richieste" e il "autorizzazioni specifiche richieste per Cloud Tiering" .
Se hai creato l'agente utilizzando una versione precedente, dovrai modificare l'elenco delle autorizzazioni per l'account Azure per aggiungere eventuali autorizzazioni mancanti.
Preparare la rete per l'agente della console
Assicurarsi che l'agente della console disponga delle connessioni di rete richieste. L'agente può essere installato in locale o in Azure.
-
Assicurarsi che la rete in cui è installato l'agente consenta le seguenti connessioni:
-
Una connessione HTTPS sulla porta 443 al servizio Cloud Tiering e all'archiviazione degli oggetti BLOB di Azure("vedere l'elenco degli endpoint" )
-
Una connessione HTTPS sulla porta 443 al LIF di gestione del cluster ONTAP
-
-
Se necessario, abilitare un endpoint del servizio VNet per l'archiviazione di Azure.
Si consiglia un endpoint del servizio VNet per l'archiviazione di Azure se si dispone di una connessione ExpressRoute o VPN dal cluster ONTAP alla VNet e si desidera che la comunicazione tra l'agente e l'archiviazione BLOB rimanga nella rete privata virtuale.
Preparare l'archiviazione BLOB di Azure
Quando si imposta la suddivisione in livelli, è necessario identificare il gruppo di risorse che si desidera utilizzare, nonché l'account di archiviazione e il contenitore di Azure che appartengono al gruppo di risorse. Un account di archiviazione consente a Cloud Tiering di autenticare e accedere al contenitore BLOB utilizzato per il tiering dei dati.
Cloud Tiering supporta il tiering su qualsiasi account di archiviazione in qualsiasi regione a cui è possibile accedere tramite l'agente.
Cloud Tiering supporta solo i tipi di account di archiviazione General Purpose v2 e Premium Block Blob.
|
|
Se si prevede di configurare Cloud Tiering per utilizzare un livello di accesso a costo inferiore a cui i dati suddivisi in livelli verranno trasferiti dopo un certo numero di giorni, non è necessario selezionare alcuna regola del ciclo di vita durante la configurazione del contenitore nel proprio account Azure. Cloud Tiering gestisce le transizioni del ciclo di vita. |
Suddividi i dati inattivi dal tuo primo cluster all'archiviazione BLOB di Azure
Dopo aver preparato l'ambiente Azure, inizia a suddividere in livelli i dati inattivi dal primo cluster.
-
Selezionare il sistema ONTAP locale.
-
Fare clic su Abilita per il servizio Tiering dal pannello di destra.
Se la destinazione del tiering di Azure Blob esiste come sistema nella pagina Sistemi, è possibile trascinare il cluster sul sistema Azure Blob per avviare la procedura guidata di configurazione.
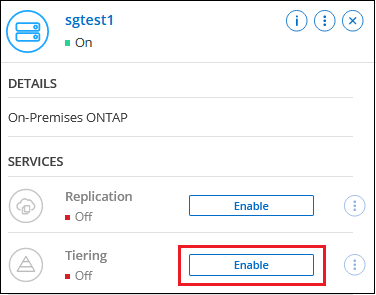
-
Definisci nome archivio oggetti: inserisci un nome per questo archivio oggetti. Deve essere univoco rispetto a qualsiasi altro archivio di oggetti che potresti utilizzare con gli aggregati su questo cluster.
-
Seleziona provider: seleziona Microsoft Azure e seleziona Continua.
-
Completare i passaggi nelle pagine Crea archiviazione oggetti:
-
Gruppo di risorse: seleziona un gruppo di risorse in cui è gestito un contenitore esistente o in cui desideri creare un nuovo contenitore per i dati a livelli e seleziona Continua.
Quando si utilizza un agente locale, è necessario immettere la sottoscrizione di Azure che fornisce l'accesso al gruppo di risorse.
-
Contenitore di Azure: selezionare il pulsante di opzione per aggiungere un nuovo contenitore BLOB a un account di archiviazione o per utilizzare un contenitore esistente. Quindi seleziona l'account di archiviazione e scegli il contenitore esistente oppure inserisci il nome del nuovo contenitore. Quindi seleziona Continua.
Gli account di archiviazione e i contenitori visualizzati in questo passaggio appartengono al gruppo di risorse selezionato nel passaggio precedente.
-
Ciclo di vita del livello di accesso: Cloud Tiering gestisce le transizioni del ciclo di vita dei dati suddivisi in livelli. I dati iniziano nella classe Hot, ma è possibile creare una regola per applicare la classe Cool ai dati dopo un certo numero di giorni.
Selezionare il livello di accesso a cui si desidera trasferire i dati suddivisi in livelli e il numero di giorni prima che i dati vengano assegnati a tale livello, quindi selezionare Continua. Ad esempio, lo screenshot qui sotto mostra che i dati a livelli vengono assegnati alla classe Cool dalla classe Hot dopo 45 giorni nell'archiviazione degli oggetti.
Se si sceglie Mantieni i dati in questo livello di accesso, i dati rimangono nel livello di accesso Hot e non vengono applicate regole. "Visualizza i livelli di accesso supportati".
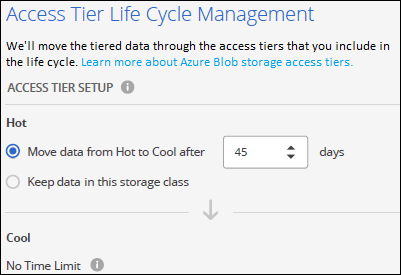
Si noti che la regola del ciclo di vita viene applicata a tutti i contenitori BLOB nell'account di archiviazione selezionato.
-
Rete cluster: selezionare lo spazio IP che ONTAP deve utilizzare per connettersi all'archiviazione degli oggetti e selezionare Continua.
Selezionando lo spazio IP corretto si garantisce che Cloud Tiering possa impostare una connessione da ONTAP allo storage degli oggetti del provider cloud.
È anche possibile impostare la larghezza di banda di rete disponibile per caricare dati inattivi nell'archiviazione degli oggetti definendo la "Velocità di trasferimento massima". Selezionare il pulsante di opzione Limitato e immettere la larghezza di banda massima utilizzabile, oppure selezionare Illimitato per indicare che non vi è alcun limite.
-
-
Nella pagina Volumi a livelli, seleziona i volumi per i quali desideri configurare la suddivisione in livelli e avvia la pagina Criteri di suddivisione in livelli:
-
Per selezionare tutti i volumi, seleziona la casella nella riga del titolo (
 ) e seleziona Configura volumi.
) e seleziona Configura volumi. -
Per selezionare più volumi, seleziona la casella per ogni volume (
 ) e seleziona Configura volumi.
) e seleziona Configura volumi. -
Per selezionare un singolo volume, selezionare la riga (o
 icona) per il volume.
icona) per il volume.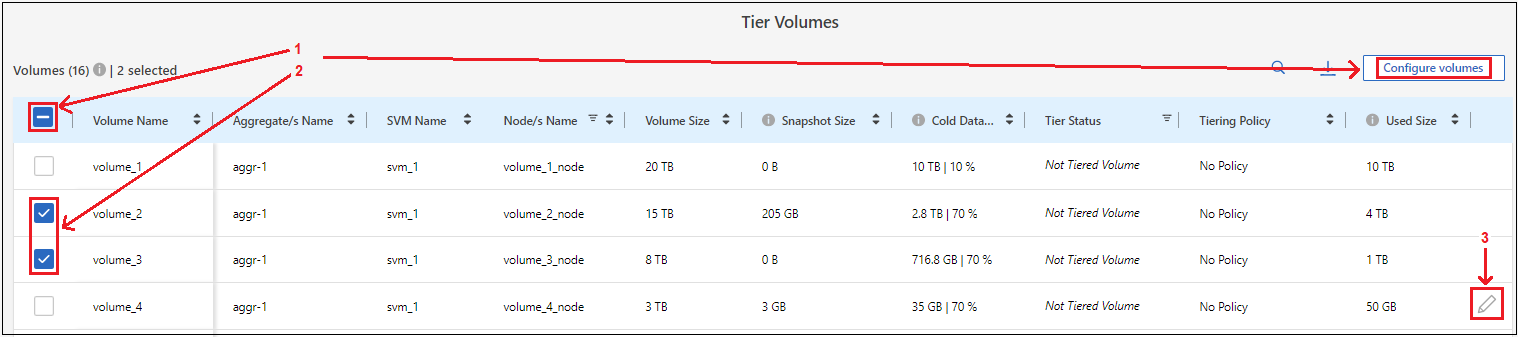
-
-
Nella finestra di dialogo Criterio di suddivisione in livelli, seleziona un criterio di suddivisione in livelli, modifica facoltativamente i giorni di raffreddamento per i volumi selezionati e seleziona Applica.
"Scopri di più sulle politiche di suddivisione in livelli di volume e sui giorni di raffreddamento".
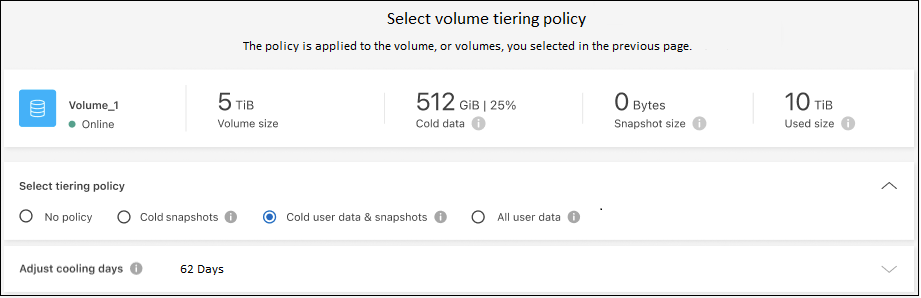
Hai configurato correttamente la suddivisione in livelli dei dati dai volumi sul cluster all'archiviazione di oggetti BLOB di Azure.
È possibile esaminare le informazioni sui dati attivi e inattivi del cluster. "Scopri di più sulla gestione delle impostazioni di suddivisione in livelli".
È anche possibile creare un archivio di oggetti aggiuntivo nei casi in cui si desideri suddividere i dati da determinati aggregati su un cluster in archivi di oggetti diversi. Oppure se si prevede di utilizzare FabricPool Mirroring, in cui i dati a livelli vengono replicati in un archivio oggetti aggiuntivo. "Scopri di più sulla gestione degli archivi di oggetti".