

Kubernetes モニタリング オペレーターのインストールと構成
 変更を提案
変更を提案
Data Infrastructure Insights は、 Kubernetes コレクション用の Kubernetes Monitoring Operator を提供します。新しいオペレーターをデプロイするには、Kubernetes > Collectors > +Kubernetes Collector に移動します。
Kubernetesモニタリングオペレーターをインストールする前に
参照"前提条件"Kubernetes Monitoring Operator をインストールまたはアップグレードする前に、ドキュメントを参照してください。
Kubernetes モニタリング オペレーターのインストール
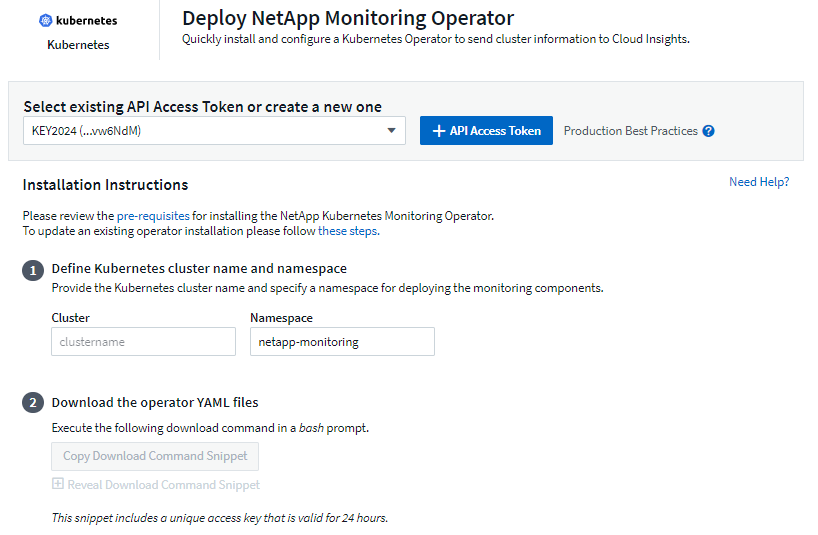
-
一意のクラスター名と名前空間を入力します。もしあなたがアップグレード以前の Kubernetes Operator からの場合は、同じクラスター名と名前空間を使用します。
-
これらを入力すると、ダウンロード コマンド スニペットをクリップボードにコピーできます。
-
スニペットを bash ウィンドウに貼り付けて実行します。 Operator インストール ファイルがダウンロードされます。スニペットには一意のキーがあり、24 時間有効であることに注意してください。
-
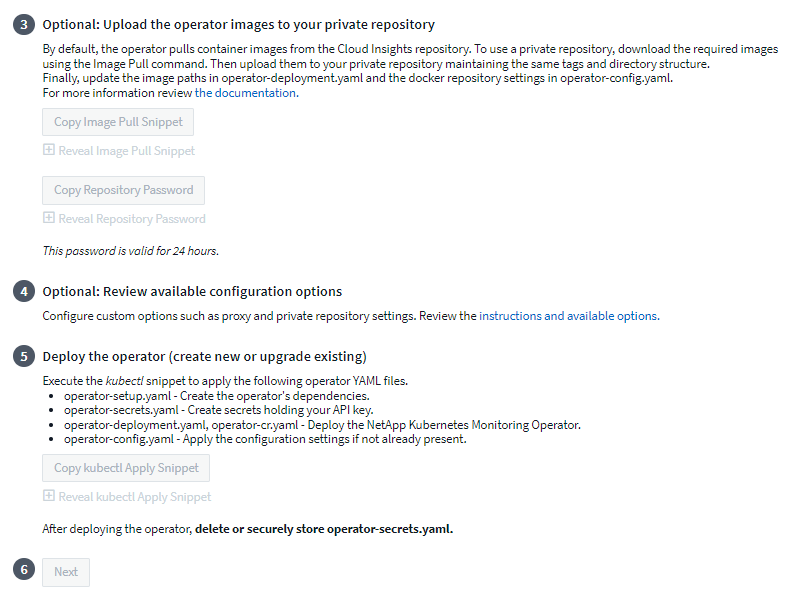
カスタム リポジトリまたはプライベート リポジトリがある場合は、オプションの Image Pull スニペットをコピーし、bash シェルに貼り付けて実行します。イメージをプルしたら、それをプライベート リポジトリにコピーします。必ず同じタグとフォルダー構造を維持してください。 operator-deployment.yaml 内のパスと、operator-config.yaml 内の docker リポジトリ設定を更新します。
-
必要に応じて、プロキシやプライベート リポジトリ設定などの利用可能な構成オプションを確認します。詳細については、"設定オプション" 。
-
準備ができたら、kubectl Apply スニペットをコピーし、ダウンロードして実行して、Operator をデプロイします。
-
インストールは自動的に進行します。完了したら、[次へ] ボタンをクリックします。
-
インストールが完了したら、[次へ] ボタンをクリックします。 operator-secrets.yaml ファイルも必ず削除するか、安全に保存してください。
カスタムリポジトリをお持ちの場合は、以下をお読みください。カスタム/プライベートDockerリポジトリを使用する 。
Kubernetes 監視コンポーネント
Data Infrastructure Insights Kubernetes モニタリングは、次の 4 つのモニタリング コンポーネントで構成されています。
-
クラスターメトリック
-
ネットワークパフォーマンスとマップ(オプション)
-
イベントログ(オプション)
-
変更分析(オプション)
上記のオプション コンポーネントは、各 Kubernetes コレクターに対してデフォルトで有効になっています。特定のコレクターに対してコンポーネントが必要ないと判断した場合は、Kubernetes > Collectors に移動し、画面の右側にあるコレクターの「3 つのドット」メニューから Modify Deployment を選択して無効にすることができます。
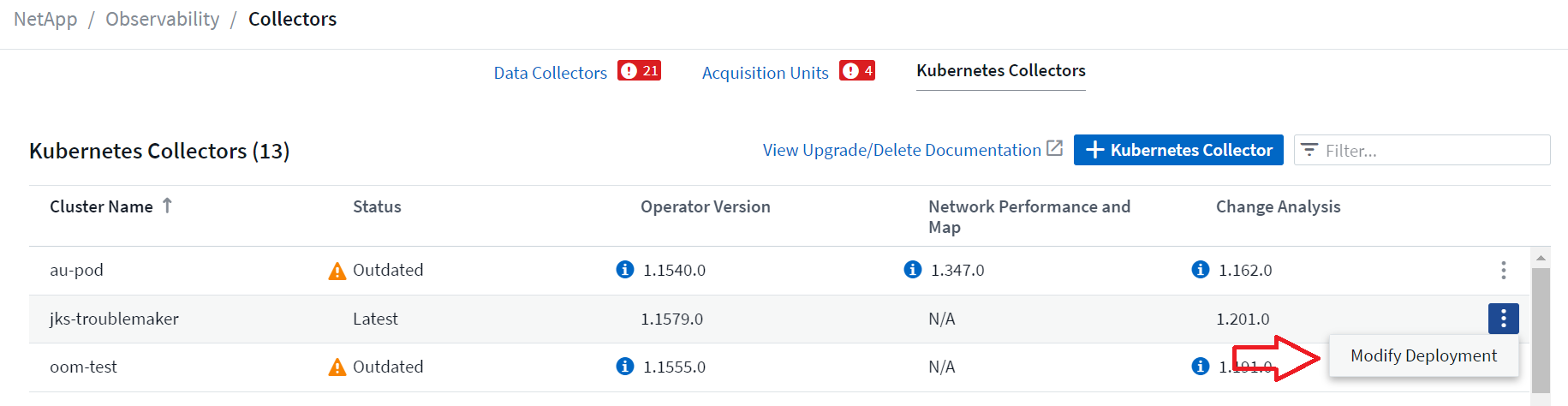
画面には各コンポーネントの現在の状態が表示され、必要に応じてそのコレクターのコンポーネントを無効または有効にすることができます。
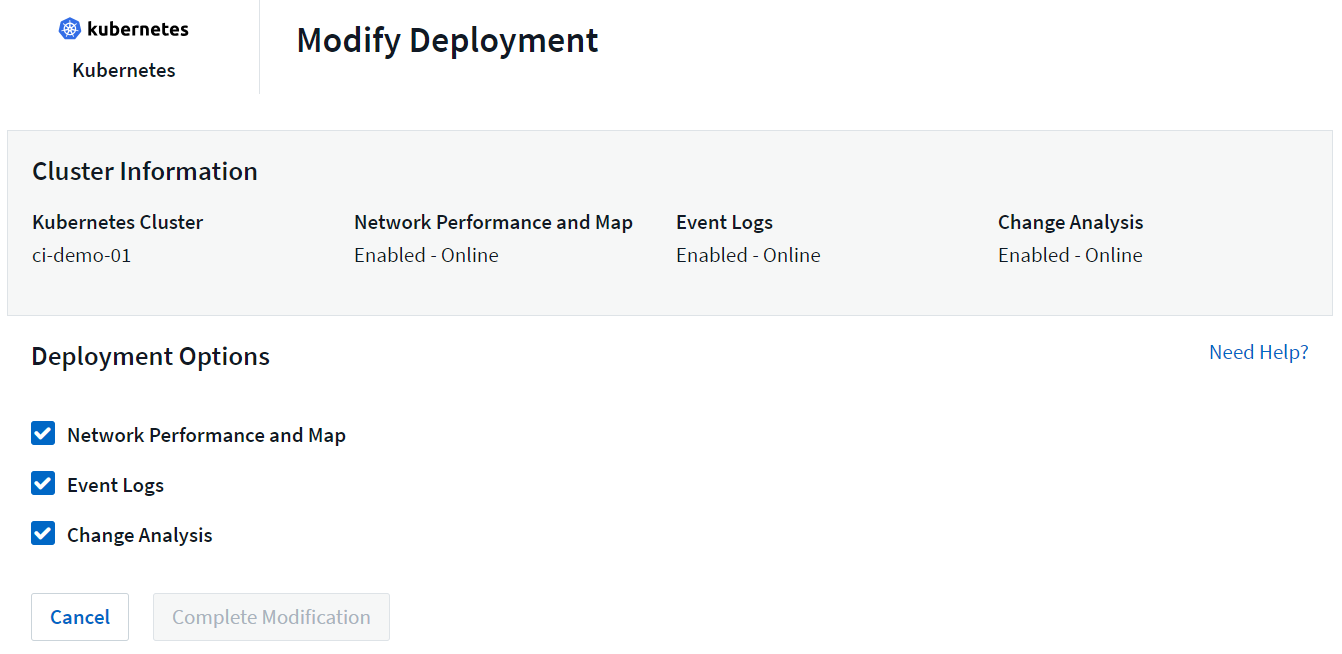
最新のKubernetesモニタリングオペレーターへのアップグレード
DII プッシュボタンアップグレード
DII Kubernetes Collectors ページから Kubernetes Monitoring Operator をアップグレードできます。アップグレードするクラスターの横にあるメニューをクリックし、「アップグレード」を選択します。オペレーターはイメージ署名を検証し、現在のインストールのスナップショットを実行して、アップグレードを実行します。数分以内に、オペレーターのステータスが「アップグレード進行中」から「最新」へと進行していくのが確認できます。エラーが発生した場合は、詳細を表示するにはエラー ステータスを選択し、以下のプッシュ ボタン アップグレードのトラブルシューティング表を参照してください。

|
オペレーターバージョン1.2057.0より前のバージョンでは、プッシュボタンによるアップグレードは利用できません。最新バージョンにアップグレードするには、以下の手動アップグレード手順に従ってください。アップグレード後は、プッシュボタンアップグレード機能を使用して今後のアップグレードを実行できます。 |
プライベートリポジトリによるプッシュボタンアップグレード
オペレーターがプライベート リポジトリを使用するように構成されている場合は、オペレーターの実行に必要なすべてのイメージとその署名がリポジトリで使用可能であることを確認してください。アップグレード プロセス中にイメージが不足しているためにエラーが発生した場合は、イメージをリポジトリに追加して、アップグレードを再試行してください。リポジトリにイメージ署名をアップロードするには、次のようにcosignツールを使用してください。3 オプション: オペレータイメージをプライベートリポジトリにアップロード > イメージプルスニペットで指定されたすべてのイメージの署名をアップロードしてください。
cosign copy example.com/src:v1 example.com/dest:v1 #Example cosign copy <DII container registry>/netapp-monitoring:<image version> <private repository>/netapp-monitoring:<image version>
以前実行していたバージョンにロールバックする
プッシュボタン アップグレード機能を使用してアップグレードし、アップグレード後 7 日以内に現在のバージョンのオペレーターに問題が発生した場合は、アップグレード プロセス中に作成されたスナップショットを使用して、以前実行していたバージョンにダウングレードできます。ロールバックするクラスターの横にあるメニューをクリックし、[ロールバック] を選択します。
手動アップグレード
既存の Operator に AgentConfiguration が存在するかどうかを判断します(名前空間がデフォルトの netapp-monitoring でない場合は、適切な名前空間に置き換えます):
kubectl -n netapp-monitoring get agentconfiguration netapp-ci-monitoring-configuration _AgentConfiguration_ が存在する場合:
-
インストール既存のオペレータよりも最新のオペレータを優先します。
-
必ず最新のコンテナイメージを取得するカスタム リポジトリを使用している場合。
-
AgentConfiguration が存在しない場合:
-
Data Infrastructure Insightsによって認識されるクラスター名をメモします (名前空間がデフォルトの netapp-monitoring でない場合は、適切な名前空間に置き換えてください)。
kubectl -n netapp-monitoring get agent -o jsonpath='{.items[0].spec.cluster-name}' * 既存の Operator のバックアップを作成します (名前空間がデフォルトの netapp-monitoring でない場合は、適切な名前空間に置き換えます)。kubectl -n netapp-monitoring get agent -o yaml > agent_backup.yaml * <<to-remove-the-kubernetes-monitoring-operator,アンインストール>>既存のオペレータ。 * <<installing-the-kubernetes-monitoring-operator,インストール>>最新のオペレーター。
-
同じクラスター名を使用します。
-
最新の Operator YAML ファイルをダウンロードした後、デプロイする前に、agent_backup.yaml にあるカスタマイズをダウンロードした operator-config.yaml に移植します。
-
必ず最新のコンテナイメージを取得するカスタム リポジトリを使用している場合。
-
Kubernetes モニタリング オペレーターの停止と起動
Kubernetes モニタリング オペレーターを停止するには:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=0 Kubernetes モニタリング オペレーターを起動するには:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=1
アンインストール
Kubernetesモニタリングオペレーターを削除するには
Kubernetes モニタリング オペレーターのデフォルトの名前空間は「netapp-monitoring」であることに注意してください。独自の名前空間を設定している場合は、これらのコマンドと後続のすべてのコマンドおよびファイルでその名前空間を置き換えます。
監視オペレーターの新しいバージョンは、次のコマンドでアンインストールできます。
kubectl -n <NAMESPACE> delete agent -l installed-by=nkmo-<NAMESPACE> kubectl -n <NAMESPACE> delete clusterrole,clusterrolebinding,crd,svc,deploy,role,rolebinding,secret,sa -l installed-by=nkmo-<NAMESPACE>
監視オペレーターが専用のネームスペースにデプロイされている場合は、ネームスペースを削除します。
kubectl delete ns <NAMESPACE> 注: 最初のコマンドで「リソースが見つかりません」と返された場合は、次の手順に従って、監視オペレーターの古いバージョンをアンインストールしてください。
以下の各コマンドを順番に実行します。現在のインストールによっては、これらのコマンドの一部が「オブジェクトが見つかりません」というメッセージを返す場合があります。これらのメッセージは無視しても問題ありません。
kubectl -n <NAMESPACE> delete agent agent-monitoring-netapp kubectl delete crd agents.monitoring.netapp.com kubectl -n <NAMESPACE> delete role agent-leader-election-role kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader <NAMESPACE>-agent-manager-role <NAMESPACE>-agent-proxy-role <NAMESPACE>-cluster-role-privileged kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding <NAMESPACE>-agent-manager-rolebinding <NAMESPACE>-agent-proxy-rolebinding <NAMESPACE>-cluster-role-binding-privileged kubectl delete <NAMESPACE>-psp-nkmo kubectl delete ns <NAMESPACE>
セキュリティ コンテキスト制約が以前に作成されている場合:
kubectl delete scc telegraf-hostaccess
Kube-state-metricsについて
NetApp Kubernetes Monitoring Operator は、他のインスタンスとの競合を避けるために独自の kube-state-metrics をインストールします。
Kube-State-Metricsの詳細については、以下を参照してください。"このページ" 。
オペレーターの設定/カスタマイズ
これらのセクションには、オペレーター構成のカスタマイズ、プロキシの操作、カスタムまたはプライベート Docker リポジトリの使用、OpenShift の操作に関する情報が含まれています。
設定オプション
最も頻繁に変更される設定は、AgentConfiguration カスタム リソースで構成できます。オペレーターをデプロイする前に、operator-config.yaml ファイルを編集してこのリソースを編集できます。このファイルには、コメントアウトされた設定の例が含まれています。リストを見る"利用可能な設定"オペレーターの最新バージョン。
オペレーターをデプロイした後、次のコマンドを使用してこのリソースを編集することもできます。
kubectl -n netapp-monitoring edit AgentConfiguration デプロイされたオペレーターのバージョンが _AgentConfiguration_ をサポートしているかどうかを確認するには、次のコマンドを実行します:
kubectl get crd agentconfigurations.monitoring.netapp.com 「サーバーからのエラー (NotFound)」というメッセージが表示された場合は、AgentConfiguration を使用する前にオペレーターをアップグレードする必要があります。
プロキシサポートの設定
Kubernetes モニタリング オペレーターをインストールするために、テナント上でプロキシを使用できる場所は 2 つあります。これらは同じプロキシ システムである場合もあれば、別のプロキシ システムである場合もあります。
-
インストール コード スニペットの実行中(「curl」を使用)に、スニペットが実行されるシステムをData Infrastructure Insights環境に接続するために必要なプロキシ
-
ターゲット Kubernetes クラスターがData Infrastructure Insights環境と通信するために必要なプロキシ
これらのいずれかまたは両方にプロキシを使用する場合、Kubernetes Operating Monitor をインストールするには、まずプロキシがData Infrastructure Insights環境との良好な通信を許可するように構成されていることを確認する必要があります。プロキシがあり、Operator をインストールするサーバー/VM からData Infrastructure Insightsにアクセスできる場合は、プロキシは適切に構成されている可能性があります。
Kubernetes オペレーティング モニターのインストールに使用するプロキシについては、Operator をインストールする前に、http_proxy/https_proxy 環境変数を設定します。一部のプロキシ環境では、no_proxy environment 変数も設定する必要がある場合があります。
変数を設定するには、Kubernetes モニタリング オペレーターをインストールする前に、システムで次の手順を実行します。
-
現在のユーザーの https_proxy および/または http_proxy 環境変数を設定します。
-
セットアップするプロキシに認証 (ユーザー名/パスワード) がない場合は、次のコマンドを実行します。
export https_proxy=<proxy_server>:<proxy_port> .. セットアップするプロキシに認証 (ユーザー名/パスワード) がある場合は、次のコマンドを実行します。
export http_proxy=<proxy_username>:<proxy_password>@<proxy_server>:<proxy_port>
-
Kubernetes クラスターがData Infrastructure Insights環境と通信するために使用するプロキシについては、これらの手順をすべて読んだ後、Kubernetes Monitoring Operator をインストールしてください。
Kubernetes Monitoring Operator をデプロイする前に、operator-config.yaml の AgentConfiguration のプロキシセクションを設定します。
agent:
...
proxy:
server: <server for proxy>
port: <port for proxy>
username: <username for proxy>
password: <password for proxy>
# In the noproxy section, enter a comma-separated list of
# IP addresses and/or resolvable hostnames that should bypass
# the proxy
noproxy: <comma separated list>
isTelegrafProxyEnabled: true
isFluentbitProxyEnabled: <true or false> # true if Events Log enabled
isCollectorsProxyEnabled: <true or false> # true if Network Performance and Map enabled
isAuProxyEnabled: <true or false> # true if AU enabled
...
...
カスタムまたはプライベートDockerリポジトリの使用
デフォルトでは、Kubernetes Monitoring Operator はData Infrastructure Insightsリポジトリからコンテナ イメージをプルします。監視のターゲットとして Kubernetes クラスターが使用されており、そのクラスターがカスタムまたはプライベート Docker リポジトリまたはコンテナー レジストリからのみコンテナー イメージをプルするように構成されている場合は、Kubernetes 監視オペレーターに必要なコンテナーへのアクセスを構成する必要があります。
NetApp Monitoring Operator インストール タイルから「イメージ プル スニペット」を実行します。このコマンドは、 Data Infrastructure Insightsリポジトリにログインし、オペレーターのすべてのイメージ依存関係をプルし、 Data Infrastructure Insightsリポジトリからログアウトします。プロンプトが表示されたら、提供されたリポジトリの一時パスワードを入力します。このコマンドは、オプション機能を含む、オペレータが使用するすべてのイメージをダウンロードします。これらの画像がどの機能に使用されているかについては、以下を参照してください。
コアオペレーター機能とKubernetesモニタリング
-
netapp 監視
-
ci-kube-rbac-プロキシ
-
ci-ksm
-
ci-telegraf
-
ディストロレスルートユーザー
イベントログ
-
ci-fluent-bit
-
ci-kubernetes-イベントエクスポーター
ネットワークパフォーマンスとマップ
-
ci-net-オブザーバー
変更分析
-
ci-k8s-change-observer
企業ポリシーに従って、オペレーターの Docker イメージをプライベート/ローカル/エンタープライズ Docker リポジトリにプッシュします。リポジトリ内のこれらのイメージへのイメージ タグとディレクトリ パスが、 Data Infrastructure Insightsリポジトリのものと一致していることを確認します。
operator-deployment.yaml の monitoring-operator デプロイメントを編集し、すべてのイメージ参照を変更してプライベート Docker リポジトリを使用します。
image: <docker repo of the enterprise/corp docker repo>/ci-kube-rbac-proxy:<ci-kube-rbac-proxy version> image: <docker repo of the enterprise/corp docker repo>/netapp-monitoring:<version>
新しい docker リポジトリの場所を反映するように、operator-config.yaml の AgentConfiguration を編集します。プライベートリポジトリ用の新しい imagePullSecret を作成します。詳細については、https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/ を参照してください。
agent: ... # An optional docker registry where you want docker images to be pulled from as compared to CI's docker registry # Please see documentation link here: link:task_config_telegraf_agent_k8s.html#using-a-custom-or-private-docker-repository[Using a custom or private docker repository] dockerRepo: your.docker.repo/long/path/to/test # Optional: A docker image pull secret that maybe needed for your private docker registry dockerImagePullSecret: docker-secret-name
長期パスワード用の API アクセストークン
一部の環境(プロキシリポジトリなど)では、Data Infrastructure Insights docker リポジトリの長期パスワードが必要です。インストール時に UI で提供されるパスワードは 24 時間のみ有効です。それを使用する代わりに、API アクセストークンを docker リポジトリパスワードとして使用できます。このパスワードは、API アクセストークンが有効である限り有効です。この特定の目的のために新しい API アクセストークンを生成することも、既存のものを使用することもできます。
"こちらをお読みください"新しいAPIアクセストークンを作成する手順については、こちらをご覧ください。
ダウンロードした operator-secrets.yaml ファイルから既存の API アクセス トークンを抽出するには、ユーザーは以下を実行できます:
grep '\.dockerconfigjson' operator-secrets.yaml |sed 's/.*\.dockerconfigjson: //g' |base64 -d |jq
実行中のオペレーターインストールから既存のAPIアクセストークンを抽出するには、ユーザーは以下を実行できます:
kubectl -n netapp-monitoring get secret netapp-ci-docker -o jsonpath='{.data.\.dockerconfigjson}' |base64 -d |jq
OpenShift の手順
OpenShift 4.6 以降で実行している場合は、operator-config.yaml の AgentConfiguration を編集して runPrivileged 設定を有効にする必要があります:
# Set runPrivileged to true SELinux is enabled on your kubernetes nodes runPrivileged: true
Openshift は、一部の Kubernetes コンポーネントへのアクセスをブロックする可能性のある追加のセキュリティ レベルを実装する場合があります。
寛容と汚点
netapp-ci-telegraf-ds、netapp-ci-fluent-bit-ds、および netapp-ci-net-observer-l4-ds DaemonSets は、すべてのノードでデータを正しく収集するために、クラスター内のすべてのノードでポッドをスケジュールする必要があります。オペレーターは、いくつかのよく知られた 汚染 を許容するように設定されています。ノードにカスタムテイントを設定して、ポッドがすべてのノードで実行されないようにしている場合は、それらのテイントに対して*許容*を作成できます。"_AgentConfiguration_内" 。クラスター内のすべてのノードにカスタム テイントを適用した場合は、オペレーター ポッドをスケジュールして実行できるように、オペレーター デプロイメントに必要な許容値も追加する必要があります。
Kubernetesについて詳しく知る"汚名と寛容"。
Kubernetes モニタリング オペレーター イメージ署名の検証
オペレータのイメージとそれが展開するすべての関連イメージは、 NetAppによって署名されています。インストール前に cosign ツールを使用してイメージを手動で検証したり、Kubernetes アドミッション コントローラーを構成したりすることができます。詳細については、"Kubernetesドキュメント" 。
イメージ署名の検証に使用される公開鍵は、モニタリング オペレーターのインストール タイルの「オプション: オペレーター イメージをプライベート リポジトリにアップロード > イメージ署名公開鍵」で入手できます。
イメージ署名を手動で検証するには、次の手順を実行します。
-
画像プルスニペットをコピーして実行する
-
リポジトリパスワードをコピーしてプロンプトが表示されたら入力します
-
イメージ署名公開鍵(例では dii-image-signing.pub)を保存します。
-
cosign を使用してイメージを検証します。共同署名の使用例を参照してください
$ cosign verify --key dii-image-signing.pub --insecure-ignore-sct --insecure-ignore-tlog <repository>/<image>:<tag>
Verification for <repository>/<image>:<tag> --
The following checks were performed on each of these signatures:
- The cosign claims were validated
- The signatures were verified against the specified public key
[{"critical":{"identity":{"docker-reference":"<repository>/<image>"},"image":{"docker-manifest-digest":"sha256:<hash>"},"type":"cosign container image signature"},"optional":null}]
トラブルシューティング
Kubernetes モニタリング オペレーターの設定中に問題が発生した場合に試すことは次のとおりです。
| 問題: | これを試してください: |
|---|---|
Kubernetes 永続ボリュームと対応するバックエンド ストレージ デバイス間のハイパーリンク/接続が表示されません。私の Kubernetes 永続ボリュームは、ストレージ サーバーのホスト名を使用して構成されています。 |
手順に従って既存の Telegraf エージェントをアンインストールし、最新の Telegraf エージェントを再インストールします。 Telegraf バージョン 2.0 以降を使用している必要があり、Kubernetes クラスター ストレージがData Infrastructure Insightsによってアクティブに監視されている必要があります。 |
ログには次のようなメッセージが表示されます: E0901 15:21:39.962145 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: *v1.MutatingWebhookConfiguration の一覧を取得できませんでした: サーバーは要求されたリソースを見つけることができませんでした E0901 15:21:43.168161 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: *v1.Lease の一覧を取得できませんでした: サーバーは要求されたリソースを見つけることができませんでした (get leases.coordination.k8s.io) など。 |
これらのメッセージは、Kubernetes バージョン 1.20 未満で kube-state-metrics バージョン 2.0.0 以上を実行している場合に表示されることがあります。 Kubernetes のバージョンを取得するには: kubectl version kube-state-metrics のバージョンを取得するには: kubectl get deploy/kube-state-metrics -o jsonpath='{..image}' これらのメッセージが表示されないようにするには、ユーザーは kube-state-metrics デプロイメントを変更して、次のリースを無効にすることができます: mutatingwebhookconfigurations validatingwebhookconfigurations volumeattachments resources 具体的には、次の CLI 引数を使用できます: resources=certificatesigningrequests,configmaps,cronjobs,daemonsets, deployments,endpoints,horizontalpodautoscalers,ingresses,jobs,limitranges, namespaces,networkpolicies,nodes,persistentvolumeclaims,persistentvolumes, poddisruptionbudgets,pods,replicasets,replicationcontrollers,resourcequotas, secrets、services、statefulsets、storageclasses デフォルトのリソースリストは次のとおりです: "certificatesigningrequests、configmaps、cronjobs、daemonsets、deployments、endpoints、horizontalpodautoscalers、ingresses、jobs、leases、limitranges、mutatingwebhookconfigurations、namespaces、networkpolicies、nodes、persistentvolumeclaims、persistentvolumes、poddisruptionbudgets、pods、replicasets、replicationcontrollers、resourcequotas、secrets、services、statefulsets、storageclasses、validatingwebhookconfigurations、volumeattachments" |
Telegraf から次のようなエラー メッセージが表示されますが、Telegraf は起動して実行されます: Oct 11 14:23:41 ip-172-31-39-47 systemd[1]: Started The plugin-driven server agent for reporting metrics into InfluxDB. 10月11日 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="キャッシュディレクトリの作成に失敗しました。 /etc/telegraf/.cache/snowflake、err: mkdir /etc/telegraf/.ca che: 権限が拒否されました。無視されました\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" Oct 11 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="開けませんでした。無視されました。open /etc/telegraf/.cache/snowflake/ocsp_response_cache.json: そのようなファイルまたはディレクトリはありません\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" Oct 11 14:23:41 ip-172-31-39-47 telegraf[1827]: 2021-10-11T14:23:41Z I! Telegraf 1.19.3 の起動 |
これは既知の問題です。参照"このGitHubの記事"詳細についてはこちらをご覧ください。 Telegraf が稼働している限り、ユーザーはこれらのエラー メッセージを無視できます。 |
Kubernetes では、Telegraf ポッドが次のエラーを報告しています: 「mountstats 情報の処理中にエラーが発生しました: mountstats ファイルを開けませんでした: /hostfs/proc/1/mountstats、エラー: open /hostfs/proc/1/mountstats: 権限が拒否されました」 |
SELinux が有効になっていて強制されている場合、Telegraf ポッドが Kubernetes ノード上の /proc/1/mountstats ファイルにアクセスできない可能性があります。この制限を克服するには、エージェント構成を編集し、runPrivileged 設定を有効にします。詳細については、OpenShift の手順を参照してください。 |
Kubernetes では、Telegraf ReplicaSet ポッドが次のエラーを報告しています: [inputs.prometheus] プラグインのエラー: キーペア /etc/kubernetes/pki/etcd/server.crt をロードできませんでした:/etc/kubernetes/pki/etcd/server.key: open /etc/kubernetes/pki/etcd/server.crt: そのようなファイルまたはディレクトリはありません |
Telegraf ReplicaSet ポッドは、マスターまたは etcd として指定されたノード上で実行されることを目的としています。 ReplicaSet ポッドがこれらのノードのいずれかで実行されていない場合は、これらのエラーが発生します。マスター/etcd ノードに taint があるかどうかを確認します。そうなる場合は、Telegraf ReplicaSet (telegraf-rs) に必要な許容範囲を追加します。たとえば、ReplicaSet を編集します… kubectl edit rs telegraf-rs …そして、適切な許容値を仕様に追加します。次に、ReplicaSet ポッドを再起動します。 |
PSP/PSA環境があります。これは監視オペレーターに影響しますか? |
Kubernetes クラスターが Pod Security Policy (PSP) または Pod Security Admission (PSA) を適用した状態で実行されている場合は、最新の Kubernetes Monitoring Operator にアップグレードする必要があります。 PSP/PSA をサポートする現在の Operator にアップグレードするには、次の手順に従います。1.アンインストール以前の監視オペレーター: kubectl delete agent agent-monitoring-netapp -n netapp-monitoring kubectl delete ns netapp-monitoring kubectl delete crd agents.monitoring.netapp.com kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding 2.インストール監視オペレータの最新バージョン。 |
PSP/PSA を使用しているのですが、Operator を展開しようとして問題が発生しました。 |
1.次のコマンドを使用してエージェントを編集します: kubectl -n <name-space> edit agent 2. 「security-policy-enabled」を「false」としてマークします。これにより、ポッド セキュリティ ポリシーとポッド セキュリティ アドミッションが無効になり、オペレーターがデプロイできるようになります。次のコマンドを使用して確認します: kubectl get psp (Pod Security Policy が削除されたことが表示されます) kubectl get all -n <namespace> |
grep -i psp (何も見つからないことが表示されます) |
「ImagePullBackoff」エラーが発生 |
カスタムまたはプライベートなDockerリポジトリを使用しており、Kubernetes Monitoring Operatorがそれを正しく認識するようにまだ設定されていない場合、これらのエラーが発生する可能性があります。詳細はこちらカスタム/プライベートリポジトリの設定について。 |
モニタリング オペレーターのデプロイメントで問題が発生していますが、現在のドキュメントでは解決できません。 |
次のコマンドの出力をキャプチャまたはメモして、テクニカル サポート チームに連絡してください。 kubectl -n netapp-monitoring get all kubectl -n netapp-monitoring describe all kubectl -n netapp-monitoring logs <monitoring-operator-pod> --all-containers=true kubectl -n netapp-monitoring logs <telegraf-pod> --all-containers=true |
Operator 名前空間の net-observer (ワークロード マップ) ポッドは CrashLoopBackOff にあります |
これらのポッドは、ネットワーク可観測性のワークロード マップ データ コレクターに対応します。以下を試してください: • いずれかのポッドのログをチェックして、最小カーネル バージョンを確認します。例: ---- {"ci-tenant-id":"your-tenant-id","collector-cluster":"your-k8s-cluster-name","environment":"prod","level":"error","msg":"検証に失敗しました。理由: カーネル バージョン 3.10.0 は、最小カーネル バージョン 4.18.0 より小さいです","time":"2022-11-09T08:23:08Z"} ---- • Net-observer ポッドでは、Linux カーネル バージョンが少なくとも 4.18.0 である必要があります。 「uname -r」コマンドを使用してカーネルバージョンを確認し、4.18.0以上であることを確認します。 |
ポッドはオペレーター名前空間(デフォルト:netapp-monitoring)で実行されていますが、ワークロードマップのUIやクエリのKubernetesメトリックにデータが表示されません。 |
K8S クラスターのノード上の時刻設定を確認します。正確な監査とデータ レポートを実現するために、ネットワーク タイム プロトコル (NTP) または簡易ネットワーク タイム プロトコル (SNTP) を使用してエージェント マシンの時刻を同期することを強くお勧めします。 |
オペレーター名前空間内の一部のネットオブザーバーポッドが保留状態になっています |
Net-observer は DaemonSet であり、k8s クラスターの各ノードでポッドを実行します。 • 保留中の状態のポッドに注意し、CPU またはメモリのリソースの問題が発生しているかどうかを確認します。ノードで必要なメモリと CPU が使用可能であることを確認します。 |
Kubernetes モニタリング オペレーターをインストールした直後、ログに次の内容が表示されます: [inputs.prometheus] プラグインでエラーが発生しました: http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics への HTTP リクエストの作成エラー: http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics を取得: tcp をダイヤル: kube-state-metrics.<namespace>.svc.cluster.local を検索: そのようなホストはありません |
このメッセージは通常、新しいオペレータがインストールされ、ksm ポッドが起動する前に telegraf-rs ポッドが起動している場合にのみ表示されます。すべてのポッドが実行されると同時に、これらのメッセージは停止します。 |
クラスター内に存在する Kubernetes CronJobs に対して収集されているメトリックが表示されません。 |
Kubernetesのバージョンを確認してください(つまり |
オペレーターをインストールすると、telegraf-ds ポッドは CrashLoopBackOff 状態になり、ポッド ログに「su: 認証失敗」と表示されます。 |
AgentConfiguration の telegraf セクションを編集し、dockerMetricCollectionEnabled を false に設定します。詳細については、オペレーターの"設定オプション"を参照してください。… spec:… telegraf:…- name:docker run-mode:- DaemonSet substitutions:- key:DOCKER_UNIX_SOCK_PLACEHOLDER value:unix:///run/docker.sock …… |
Telegraf ログに次のようなエラー メッセージが繰り返し表示されます: E! [エージェント] 出力への書き込みエラー: http: Post "https://<tenant_url>/rest/v1/lake/ingest/influxdb": コンテキストの期限が切れました (ヘッダーの待機中に Client.Timeout を超えました) |
AgentConfiguration の telegraf セクションを編集し、outputTimeout を 10 秒に増やします。詳細については、オペレーターの"設定オプション"。 |
一部のイベント ログの involvedobject データが見つかりません。 |
必ず、"権限"上記のセクション。 |
netapp-ci-monitoring-operator-<pod> と monitoring-operator-<pod> という名前の 2 つの監視オペレータ ポッドが実行されているのはなぜですか? |
2023年10月12日現在、 Data Infrastructure Insightsは、ユーザーへのサービス向上のため、オペレーターをリファクタリングしました。これらの変更を完全に適用するには、古い演算子を削除するそして新しいものをインストールする。 |
Kubernetes イベントが予期せずData Infrastructure Insightsへのレポートを停止しました。 |
イベント エクスポーター ポッドの名前を取得します。 `kubectl -n netapp-monitoring get pods |
grep event-exporter |
awk '{print $1}' |
sed 's/event-exporter./event-exporter/'` |
Kubernetes モニタリング オペレーターによってデプロイされたポッドが、リソース不足のためにクラッシュしているのがわかります。 |
Kubernetesモニタリングオペレーターを参照してください"設定オプション"必要に応じて CPU および/またはメモリの制限を増やします。 |
イメージが欠落しているか、構成が無効であるため、netapp-ci-kube-state-metrics ポッドの起動または準備ができませんでした。現在、StatefulSet はスタックしており、構成の変更が netapp-ci-kube-state-metrics ポッドに適用されていません。 |
StatefulSetは"壊れた"州。構成の問題を修正したら、netapp-ci-kube-state-metrics ポッドをバウンスします。 |
netapp-ci-kube-state-metrics ポッドは、Kubernetes Operator のアップグレードを実行した後に起動に失敗し、ErrImagePull (イメージのプルに失敗します) をスローします。 |
ポッドを手動でリセットしてみてください。 |
ログ分析の Kubernetes クラスターで、「イベントは maxEventAgeSeconds より古いため破棄されました」というメッセージが表示されています。 |
Operator の agentconfiguration を変更し、event-exporter-maxEventAgeSeconds (つまり 60 秒)、event-exporter-kubeQPS (つまり 100)、および event-exporter-kubeBurst (つまり 500) を増やします。これらの設定オプションの詳細については、"設定オプション"ページ。 |
Telegraf は、ロック可能なメモリが不足しているために警告を発したりクラッシュしたりします。 |
基盤となるオペレーティング システム/ノードで Telegraf のロック可能なメモリの制限を増やしてみてください。制限を増やすことができない場合は、NKMO エージェント構成を変更し、unprotected を true に設定します。これにより、Telegraf はロックされたメモリ ページを予約しないように指示されます。復号化された秘密がディスクにスワップアウトされる可能性があるため、セキュリティ上のリスクが生じる可能性がありますが、ロックされたメモリを予約できない環境での実行が可能になります。 unprotected 設定オプションの詳細については、"設定オプション"ページ。 |
Telegraf から次のような警告メッセージが表示されます: W! [inputs.diskio] "vdc" のディスク名を収集できません: /dev/vdc の読み取りエラー: そのようなファイルまたはディレクトリはありません |
Kubernetes Monitoring Operator の場合、これらの警告メッセージは無害であり、無視しても問題ありません。または、AgentConfiguration の telegraf セクションを編集し、runDsPrivileged を true に設定します。詳細については、"オペレータの設定オプション"を参照してください。 |
Fluent-bit ポッドが次のエラーで失敗しています: [2024/10/16 14:16:23] [error] [/src/fluent-bit/plugins/in_tail/tail_fs_inotify.c:360 errno=24] 開いているファイルが多すぎます [2024/10/16 14:16:23] [error] 入力 tail.0 の初期化に失敗しました [2024/10/16 14:16:23] [error] [engine] 入力の初期化に失敗しました |
クラスター内の fsnotify 設定を変更してみます。 sudo sysctl fs.inotify.max_user_instances (take note of setting) sudo sysctl fs.inotify.max_user_instances=<something larger than current setting> sudo sysctl fs.inotify.max_user_watches (take note of setting) sudo sysctl fs.inotify.max_user_watches=<something larger than current setting> Fluent-bit を再起動します。 注意: これらの設定をノードの再起動後も維持するには、/etc/sysctl.conf に次の行を追加する必要があります。 fs.inotify.max_user_instances=<something larger than current setting> fs.inotify.max_user_watches=<something larger than current setting> |
Telegraf DS ポッドは、TLS 証明書を検証できないために kubernetes 入力プラグインが HTTP リクエストを実行できないことに関連するエラーを報告しています。例: E! [inputs.kubernetes] プラグインのエラー: HTTPリクエストの送信中にエラーが発生しました"https://<kubelet_IP>:10250/stats/summary":得る"https://<kubelet_IP>:10250/stats/summary":tls: 証明書の検証に失敗しました: x509: IP SANが含まれていないため、<kubelet_IP>の証明書を検証できません |
これは、kubelet が自己署名証明書を使用している場合、および/または指定された証明書の証明書の Subject Alternative Name リストに <kubelet_IP> が含まれていない場合に発生します。これを解決するには、ユーザーは"エージェント構成"、telegraf:insecureK8sSkipVerify を true に設定します。これにより、Telegraf 入力プラグインが検証をスキップするように設定されます。あるいは、ユーザーはkubeletを次のように設定することができます。"サーバーTLSブートストラップ"これにより、「certificates.k8s.io」API からの証明書要求がトリガーされます。 |
Fluent-bit ポッドで次のエラーが発生し、ポッドを起動できません:026/01/12 20:20:32] [error] [sqldb] error=unable to open database file [2026/01/12 20:20:32] [error] [input:tail:tail.0] db: could not create 'in_tail_files' table [2026/01/12 20:20:32] [error] [input:tail:tail.0] could not open/create database [2026/01/12 20:20:32] [error] failed initialize input tail.0 [2026/01/12 20:20:32] [error] [engine] input initialization failed |
DBファイルが存在するホストディレクトリに適切な読み取り / 書き込み権限があることを確認してください。具体的には、ホストディレクトリは非ルートユーザーに読み取り / 書き込み権限を付与する必要があります。デフォルトのDBファイルの場所は、fluent-bit-dbFile agentconfiguration オプションで上書きされない限り、/var/log/ です。SELinuxが有効になっている場合は、fluent-bit-seLinuxOptionsType agentconfigurationオプションを 'spc_t' に設定してみてください。 |
Telegraf から以下のようなエラーメッセージが表示されますが、Telegraf は起動して実行されます:E! [inputs.kubernetes] プラグインでエラーが発生しました: https://<IP>>:<port>>/pods HTTP ステータス 403 Forbidden が返されました |
これらのメッセージは、Kubernetesのバージョンが1.33未満の場合に表示される可能性があります。telegrafで使用される「nodes/pods」RBACリソースは、これらのバージョンには存在しません。古いバージョンで必要なRBACリソースについては、operator-additional-permissions.yamlの「Kubernetesバージョン < 1.33の場合」セクションを参照してください。 |
追加情報は以下からご覧いただけます。"サポート"ページまたは"データコレクターサポートマトリックス"。