

NetApp Cloud TieringでオンプレミスのONTAPクラスターから Amazon S3 にデータを階層化
 変更を提案
変更を提案
NetApp Cloud Tieringで非アクティブなデータを Amazon S3 に階層化することで、オンプレミスのONTAPクラスターのスペースを解放します。
クイック スタート
次の手順に従ってすぐに始めましょう。各ステップの詳細については、このトピックの次のセクションで説明します。
 使用する設定方法を特定する
使用する設定方法を特定するオンプレミスのONTAPクラスターをパブリックインターネット経由で AWS S3 に直接接続するか、VPN または AWS Direct Connect を使用してプライベート VPC エンドポイントインターフェイス経由でトラフィックを AWS S3 にルーティングするかを選択します。
 コンソールエージェントを準備する
コンソールエージェントを準備するコンソールエージェントがすでに AWS VPC またはオンプレミスにデプロイされている場合は、準備は完了です。そうでない場合は、 ONTAPデータを AWS S3 ストレージに階層化するためのエージェントを作成する必要があります。また、エージェントが AWS S3 に接続できるように、エージェントのネットワーク設定をカスタマイズする必要があります。
 オンプレミスのONTAPクラスタを準備する
オンプレミスのONTAPクラスタを準備するNetApp ConsoleでONTAPクラスターを検出し、クラスターが最小要件を満たしていることを確認し、クラスターが AWS S3 に接続できるようにネットワーク設定をカスタマイズします。
 Amazon S3を階層化ターゲットとして準備する
Amazon S3を階層化ターゲットとして準備するエージェントが S3 バケットを作成および管理するための権限を設定します。また、オンプレミスのONTAPクラスターが S3 バケットにデータを読み書きできるように、アクセス許可を設定する必要があります。
 システムでクラウド階層化を有効にする
システムでクラウド階層化を有効にするオンプレミスのシステムを選択し、クラウド階層化サービスに対して 有効 を選択し、プロンプトに従ってデータを Amazon S3 に階層化します。
 ライセンスの設定
ライセンスの設定無料トライアルが終了したら、従量課金制サブスクリプション、 ONTAP Cloud Tiering BYOL ライセンス、またはその両方の組み合わせを通じて Cloud Tiering の料金を支払います。
-
AWS Marketplaceからサブスクライブするには、 "マーケットプレイスオファーにアクセス"をクリックし、「購読」を選択して、指示に従います。
-
Cloud Tiering BYOLライセンスを使用して支払うには、購入が必要な場合はお問い合わせくださいに連絡し、"NetApp Consoleに追加する" 。
接続オプションのネットワーク図
オンプレミスのONTAPシステムから AWS S3 への階層化を構成するときに使用できる接続方法は 2 つあります。
-
パブリック接続 - パブリック S3 エンドポイントを使用して、 ONTAPシステムを AWS S3 に直接接続します。
-
プライベート接続 - VPN または AWS Direct Connect を使用し、プライベート IP アドレスを使用する VPC エンドポイント インターフェイスを介してトラフィックをルーティングします。
次の図は、*パブリック接続*方式と、コンポーネント間で準備する必要がある接続を示しています。オンプレミスにインストールしたコンソールエージェント、または AWS VPC にデプロイしたエージェントを使用できます。
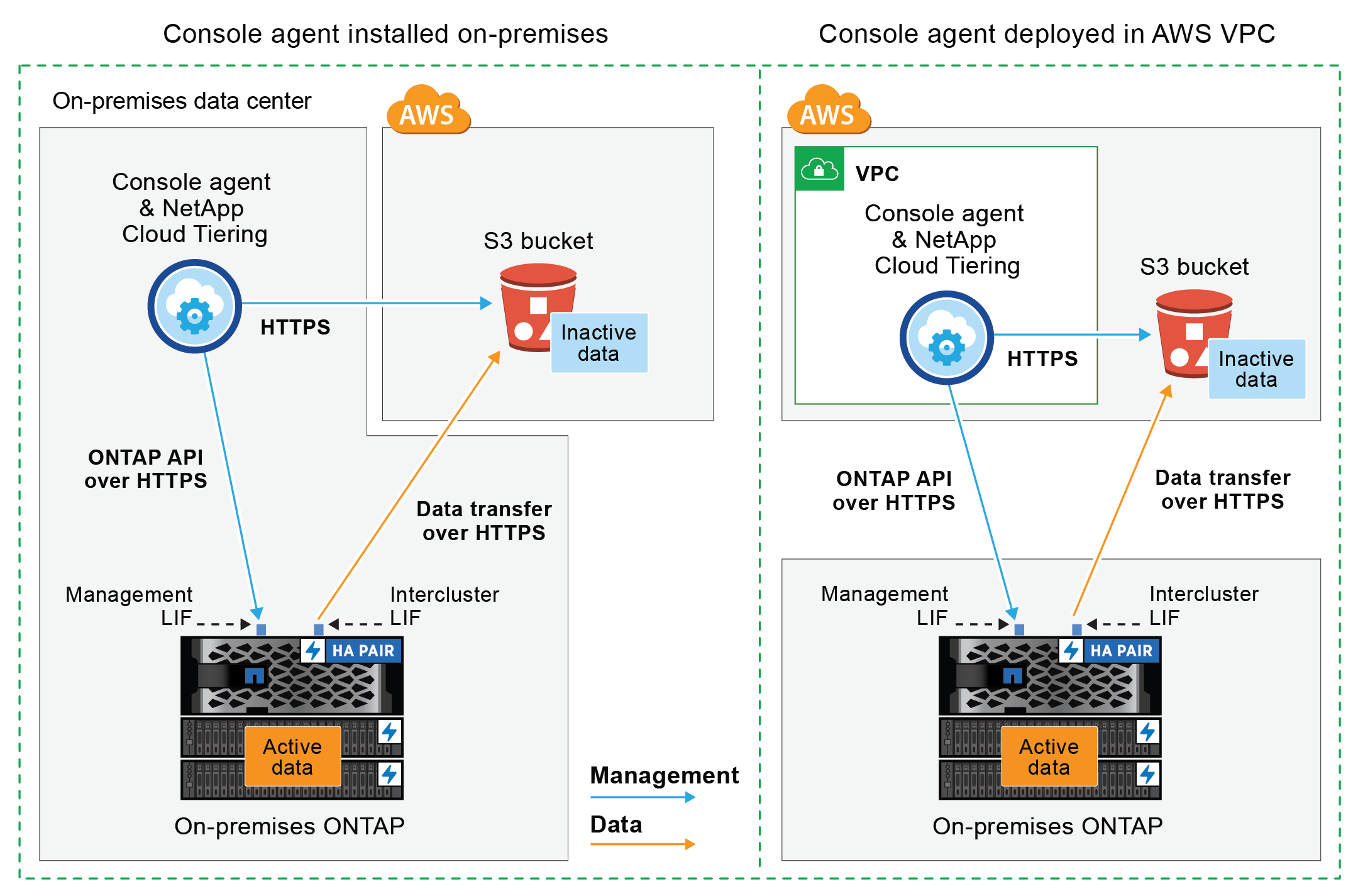
次の図は、*プライベート接続*方式と、コンポーネント間で準備する必要がある接続を示しています。オンプレミスにインストールしたコンソールエージェント、または AWS VPC にデプロイしたエージェントを使用できます。
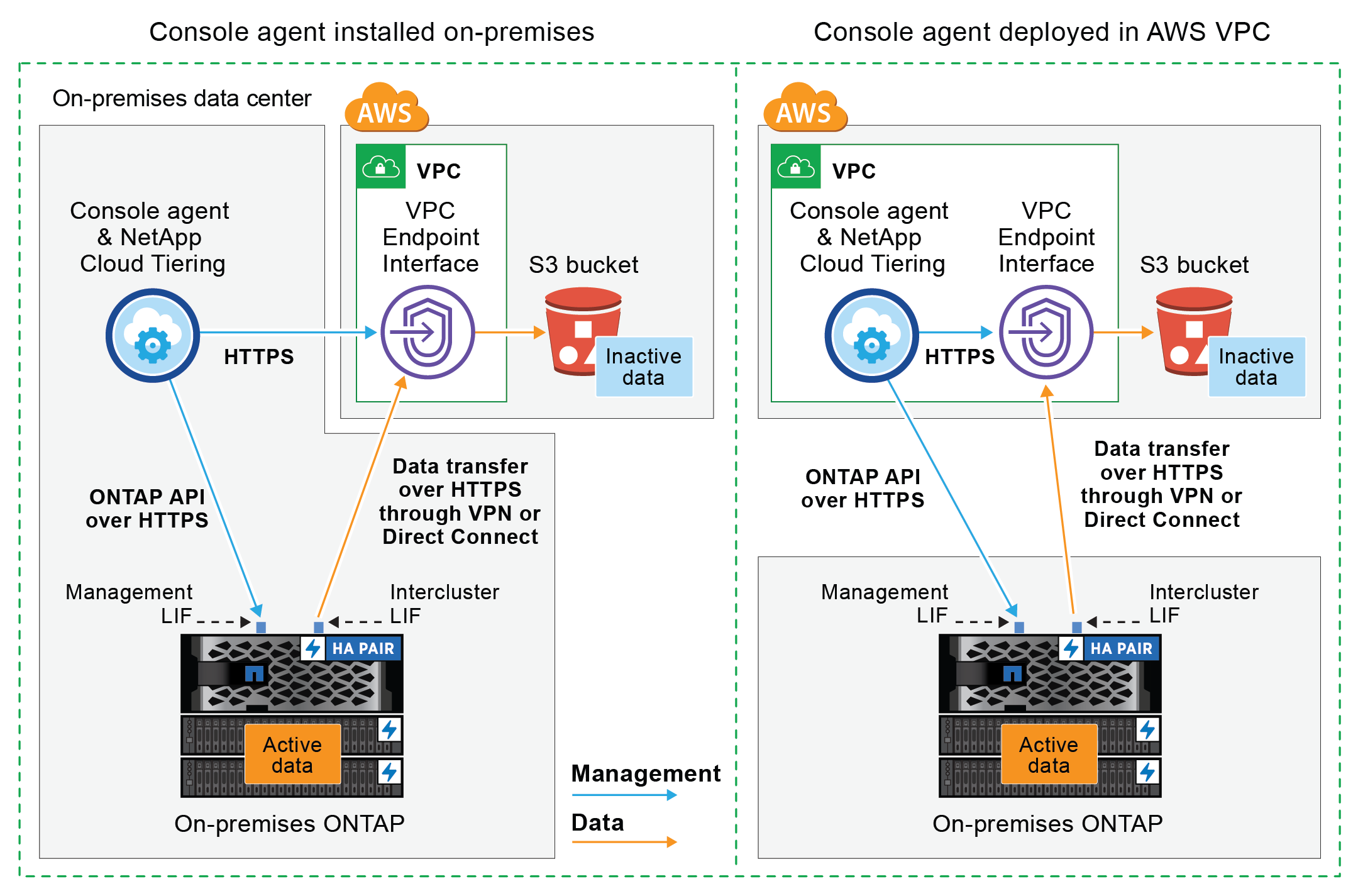

|
エージェントと S3 間の通信は、オブジェクト ストレージのセットアップのみに使用されます。 |
コンソールエージェントを準備する
エージェントは、NetApp Consoleから階層化機能を有効にします。非アクティブなONTAPデータを階層化するにはエージェントが必要です。
エージェントを作成または切り替える
AWS VPC またはオンプレミスにすでにエージェントがデプロイされている場合は、準備は完了です。そうでない場合は、いずれかの場所にエージェントを作成して、 ONTAPデータを AWS S3 ストレージに階層化する必要があります。別のクラウド プロバイダーにデプロイされたエージェントは使用できません。
エージェントのネットワーク要件
-
エージェントがインストールされているネットワークで次の接続が有効になっていることを確認します。
-
ポート443経由のCloud TieringサービスとS3オブジェクトストレージへのHTTPS接続("エンドポイントのリストを見る")
-
ポート443経由のONTAPクラスタ管理LIFへのHTTPS接続
-
-
ONTAPクラスターから VPC への Direct Connect または VPN 接続があり、エージェントと S3 間の通信を AWS 内部ネットワーク (プライベート接続) 内に維持したい場合は、S3 への VPC エンドポイント インターフェイスを有効にする必要があります。VPC エンドポイント インターフェイスを設定する方法をご覧ください。
ONTAPクラスタを準備する
Amazon S3 にデータを階層化する場合、 ONTAPクラスターは次の要件を満たしている必要があります。
ONTAPの要件
- サポートされているONTAPプラットフォーム
-
-
ONTAP 9.8 以降を使用する場合: AFFシステム、またはすべて SSD のアグリゲートまたはすべて HDD のアグリゲートを持つFASシステムからデータを階層化できます。
-
ONTAP 9.7 以前を使用する場合: AFFシステム、またはすべて SSD アグリゲートを持つFASシステムからデータを階層化できます。
-
- サポートされるONTAPバージョン
-
-
ONTAP 9.2 以降
-
AWS PrivateLink接続を使用してオブジェクトストレージに接続する場合は、 ONTAP 9.7以降が必要です。
-
- サポートされているボリュームとアグリゲート
-
Cloud Tiering で階層化できるボリュームの合計数は、 ONTAPシステム上のボリューム数よりも少なくなる可能性があります。これは、一部のアグリゲートからボリュームを階層化できないためです。 ONTAPのドキュメントを参照してください。 "FabricPoolでサポートされていない機能" 。
|
|
Cloud Tiering は、 ONTAP 9.5 以降でFlexGroupボリュームをサポートします。セットアップは他のボリュームと同じように機能します。 |
クラスターネットワークの要件
-
クラスタでは、コンソール エージェントからクラスタ管理 LIF への受信 HTTPS 接続が必要です。
クラスターと Cloud Tiering 間の接続は必要ありません。
-
階層化するボリュームをホストする各ONTAPノードには、クラスタ間 LIF が必要です。これらのクラスタ間 LIF はオブジェクト ストアにアクセスできる必要があります。
クラスターは、階層化操作のために、クラスター間 LIF から Amazon S3 ストレージへのポート 443 経由のアウトバウンド HTTPS 接続を開始します。 ONTAP はオブジェクト ストレージとの間でデータの読み取りと書き込みを行います。オブジェクト ストレージは開始することはなく、応答するだけです。
-
クラスタ間 LIF は、 ONTAP がオブジェクト ストレージに接続するために使用する IPspace に関連付ける必要があります。 "IPspacesについて詳しくはこちら" 。
Cloud Tiering を設定するときに、使用する IPspace の入力を求められます。これらの LIF が関連付けられている IPspace を選択する必要があります。これは、「デフォルト」の IPspace の場合もあれば、作成したカスタム IPspace の場合もあります。
「デフォルト」とは異なる IPspace を使用している場合は、オブジェクト ストレージにアクセスするために静的ルートを作成する必要がある場合があります。
IPspace 内のすべてのクラスタ間 LIF はオブジェクト ストアにアクセスできる必要があります。現在の IPspace に対してこれを構成できない場合は、すべてのクラスタ間 LIF がオブジェクト ストアにアクセスできる専用の IPspace を作成する必要があります。
-
S3 接続に AWS のプライベート VPC インターフェイス エンドポイントを使用している場合は、HTTPS/443 を使用するために、S3 エンドポイント証明書をONTAPクラスターにロードする必要があります。VPC エンドポイント インターフェイスを設定し、S3 証明書をロードする方法を確認します。
NetApp ConsoleでONTAPクラスタを検出する
コールド データをオブジェクト ストレージに階層化する前に、 NetApp ConsoleでオンプレミスのONTAPクラスターを検出する必要があります。クラスターを追加するには、クラスター管理 IP アドレスと管理者ユーザー アカウントのパスワードを知っておく必要があります。
AWS環境を準備する
新しいクラスターのデータ階層化を設定すると、サービスで S3 バケットを作成するか、エージェントが設定されている AWS アカウント内の既存の S3 バケットを選択するかを尋ねるメッセージが表示されます。 AWS アカウントには、Cloud Tiering に入力できる権限とアクセスキーが必要です。 ONTAPクラスターはアクセス キーを使用して、S3 との間でデータを階層化します。
デフォルトでは、クラウド階層化によってバケットが自動的に作成されます。独自のバケットを使用する場合は、階層化アクティベーション ウィザードを開始する前にバケットを作成し、ウィザードでそのバケットを選択できます。 "NetApp ConsoleからS3バケットを作成する方法をご覧ください" 。バケットはボリュームの非アクティブなデータを保存するためだけに使用してください。他の目的には使用できません。 S3バケットは"クラウド階層化をサポートするリージョン"。
|
|
一定の日数後に階層化されたデータが移行される低コストのストレージ クラスを使用するように Cloud Tiering を構成する予定の場合は、AWS アカウントでバケットを設定するときにライフサイクル ルールを選択しないでください。 Cloud Tiering はライフサイクルの遷移を管理します。 |
S3の権限を設定する
次の 2 セットの権限を構成する必要があります。
-
エージェントが S3 バケットを作成および管理できるようにするための権限。
-
オンプレミスのONTAPクラスターが S3 バケットのデータの読み取りと書き込みを行えるようにするための権限。
-
コンソールエージェントの権限:
-
確認する "これらのS3権限"エージェントに権限を付与する IAM ロールの一部です。これらは、エージェントを最初に展開したときにデフォルトで含まれているはずです。そうでない場合は、不足している権限を追加する必要があります。参照 "AWSドキュメント: IAMポリシーの編集"手順についてはこちらをご覧ください。
-
Cloud Tiering によって作成されるデフォルトのバケットには、「fabric-pool」というプレフィックスが付きます。バケットに別のプレフィックスを使用する場合は、使用する名前で権限をカスタマイズする必要があります。 S3の権限に次の行が表示されます
"Resource": ["arn:aws:s3:::fabric-pool*"]。 「fabric-pool」を、使用したいプレフィックスに変更する必要があります。たとえば、バケットのプレフィックスとして「tiering-1」を使用する場合は、この行を次のように変更します。"Resource": ["arn:aws:s3:::tiering-1*"]。同じNetApp Console組織内の追加のクラスターに使用するバケットに別のプレフィックスを使用する場合は、他のバケットのプレフィックスを含む別の行を追加できます。例えば:
"Resource": ["arn:aws:s3:::tiering-1*"]
"Resource": ["arn:aws:s3:::tiering-2*"]
独自のバケットを作成し、標準のプレフィックスを使用しない場合は、この行を次のように変更する必要があります。 `"Resource": ["arn:aws:s3:::*"]`どのバケットも認識されるようになります。ただし、これにより、ボリュームの非アクティブなデータを保持するために設計したバケットではなく、すべてのバケットが公開される可能性があります。
-
-
クラスター権限:
-
サービスをアクティブ化すると、階層化ウィザードによってアクセス キーとシークレット キーの入力が求められます。これらの認証情報はONTAPクラスターに渡され、 ONTAP はデータを S3 バケットに階層化できるようになります。そのためには、次の権限を持つ IAM ユーザーを作成する必要があります。
"s3:ListAllMyBuckets", "s3:ListBucket", "s3:GetBucketLocation", "s3:GetObject", "s3:PutObject", "s3:DeleteObject"参照 "AWS ドキュメント: IAM ユーザーに権限を委任するロールの作成"詳細については。
-
-
アクセス キーを作成または検索します。
Cloud Tiering はアクセス キーをONTAPクラスターに渡します。資格情報はクラウド階層化サービスに保存されません。
VPC エンドポイント インターフェースを使用してシステムをプライベート接続用に設定する
標準的なパブリックインターネット接続を使用する場合は、すべての権限はエージェントによって設定されるため、他に何もする必要はありません。このタイプの接続は、上記の最初の図 。
オンプレミスのデータセンターから VPC へのインターネット経由のより安全な接続を確立したい場合は、階層化アクティベーションウィザードで AWS PrivateLink 接続を選択するオプションがあります。プライベート IP アドレスを使用する VPC エンドポイント インターフェイスを介してオンプレミス システムに接続するために VPN または AWS Direct Connect を使用する予定の場合は、これが必要です。このタイプの接続は、上の2番目の図 。
-
Amazon VPC コンソールまたはコマンドラインを使用して、インターフェイスエンドポイント設定を作成します。 "Amazon S3 の AWS PrivateLink の使用に関する詳細をご覧ください" 。
-
エージェントに関連付けられているセキュリティ グループ構成を変更します。ポリシーを「カスタム」(「フルアクセス」から)に変更し、必要なS3エージェント権限を追加する先に示したとおりです。
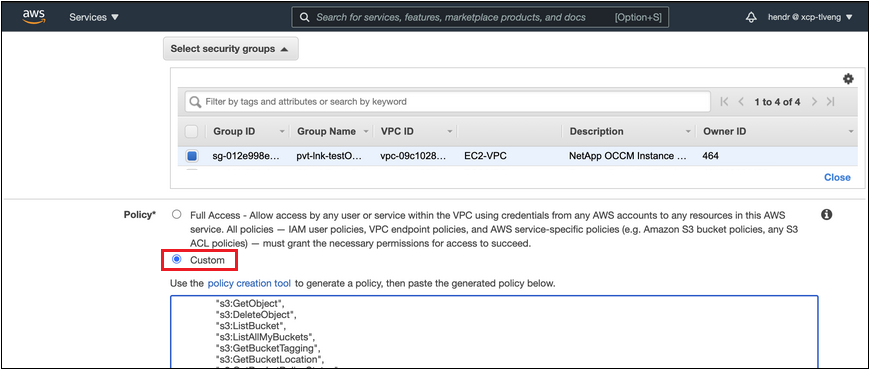
プライベート エンドポイントへの通信にポート 80 (HTTP) を使用している場合は、設定は完了です。これで、クラスターでクラウド階層化を有効にできるようになりました。
プライベート エンドポイントへの通信にポート 443 (HTTPS) を使用している場合は、次の 4 つの手順に示すように、VPC S3 エンドポイントから証明書をコピーし、 ONTAPクラスターに追加する必要があります。
-
AWS コンソールからエンドポイントの DNS 名を取得します。
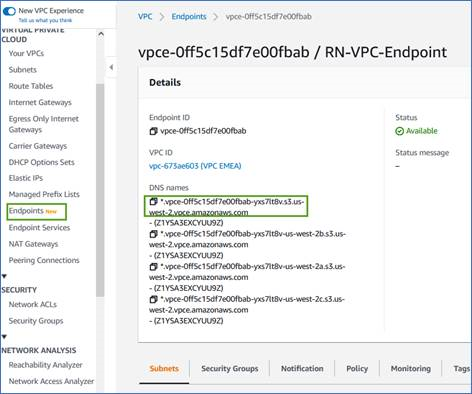
-
VPC S3 エンドポイントから証明書を取得します。これを実行するには "エージェントをホストするVMにログインする"次のコマンドを実行します。エンドポイントの DNS 名を入力するときは、先頭に「*」を置き換えて「bucket」を追加します。
[ec2-user@ip-10-160-4-68 ~]$ openssl s_client -connect bucket.vpce-0ff5c15df7e00fbab-yxs7lt8v.s3.us-west-2.vpce.amazonaws.com:443 -showcerts -
このコマンドの出力から、S3 証明書のデータ (BEGIN / END CERTIFICATE タグを含む、その間のすべてのデータ) をコピーします。
Certificate chain 0 s:/CN=s3.us-west-2.amazonaws.com` i:/C=US/O=Amazon/OU=Server CA 1B/CN=Amazon -----BEGIN CERTIFICATE----- MIIM6zCCC9OgAwIBAgIQA7MGJ4FaDBR8uL0KR3oltTANBgkqhkiG9w0BAQsFADBG … … GqvbOz/oO2NWLLFCqI+xmkLcMiPrZy+/6Af+HH2mLCM4EsI2b+IpBmPkriWnnxo= -----END CERTIFICATE----- -
ONTAPクラスタ CLI にログインし、次のコマンドを使用してコピーした証明書を適用します (独自のストレージ VM 名に置き換えます)。
cluster1::> security certificate install -vserver <svm_name> -type server-ca Please enter Certificate: Press <Enter> when done
最初のクラスターから非アクティブなデータを Amazon S3 に階層化する
AWS 環境を準備したら、最初のクラスターから非アクティブなデータの階層化を開始します。
-
必要な S3 権限を持つ IAM ユーザーの AWS アクセスキー。
-
オンプレミスのONTAPシステムを選択します。
-
右側のパネルから、クラウド階層化の 有効化 をクリックします。
Amazon S3 階層化先がシステムとして [システム] ページに存在している場合は、クラスターをシステムにドラッグしてセットアップ ウィザードを開始できます。
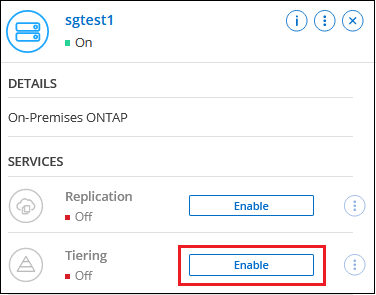 オプションを示すスクリーンショット。"]
オプションを示すスクリーンショット。"] -
オブジェクト ストレージ名の定義: このオブジェクト ストレージの名前を入力します。このクラスター上のアグリゲートで使用している他のオブジェクト ストレージとは一意である必要があります。
-
プロバイダーを選択: Amazon Web Services を選択し、続行 を選択します。
-
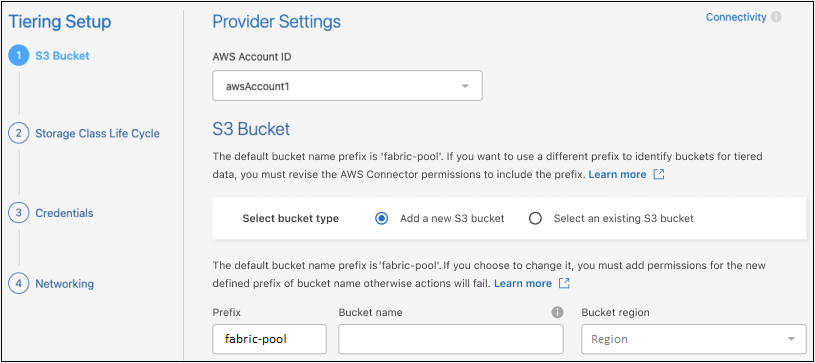
*階層化設定*ページのセクションを完了します。
-
S3 バケット: 新しい S3 バケットを追加するか、既存の S3 バケットを選択し、バケットのリージョンを選択して、続行 を選択します。
オンプレミスエージェントを使用する場合は、既存の S3 バケットまたは作成される新しい S3 バケットへのアクセスを提供する AWS アカウント ID を入力する必要があります。
エージェントの IAM ポリシーにより、インスタンスがそのプレフィックスで名前が付けられたバケットに対して S3 アクションを実行できるようになるため、デフォルトでは fabric-pool プレフィックスが使用されます。たとえば、S3 バケットに fabric-pool-AFF1 という名前を付けることができます。ここで、AFF1 はクラスターの名前です。階層化に使用するバケットのプレフィックスも定義できます。見るS3権限の設定使用する予定のカスタムプレフィックスを認識する AWS 権限があることを確認します。
-
ストレージ クラス: クラウド階層化は、階層化されたデータのライフサイクルの遷移を管理します。データは Standard クラスで始まりますが、一定の日数が経過した後にデータに別のストレージ クラスを適用するルールを作成できます。
階層化されたデータを移行する S3 ストレージ クラスと、そのクラスにデータが割り当てられるまでの日数を選択し、[続行] を選択します。たとえば、以下のスクリーンショットは、オブジェクト ストレージで 45 日経過した後、階層化データが Standard クラスから Standard-IA クラスに割り当てられていることを示しています。
このストレージ クラスにデータを保持する を選択した場合、データは Standard ストレージ クラスに残り、ルールは適用されません。"サポートされているストレージクラスを参照" 。
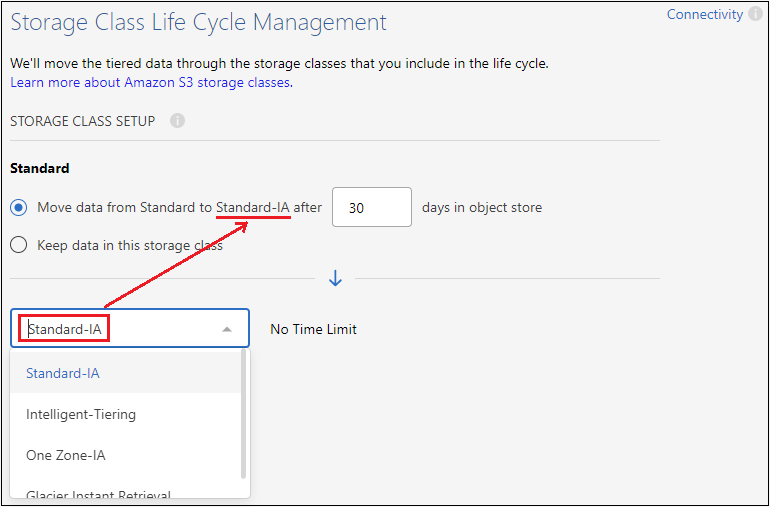
ライフサイクル ルールは、選択したバケット内のすべてのオブジェクトに適用されることに注意してください。
-
認証情報: 必要な S3 権限を持つ IAM ユーザーのアクセスキー ID とシークレットキーを入力し、[続行] を選択します。
IAM ユーザーは、S3 バケット ページで選択または作成したバケットと同じ AWS アカウントに属している必要があります。
-
ネットワーク: ネットワークの詳細を入力し、[続行] を選択します。
階層化するボリュームが存在するONTAPクラスタ内の IPspace を選択します。この IPspace のクラスタ間 LIF には、クラウド プロバイダーのオブジェクト ストレージに接続できるように、アウトバウンド インターネット アクセスが必要です。
必要に応じて、以前に設定した AWS PrivateLink を使用するかどうかを選択します。上記のセットアップ情報を参照してください。エンドポイントの構成をガイドするダイアログ ボックスが表示されます。
「最大転送速度」を定義することで、非アクティブなデータをオブジェクト ストレージにアップロードするために使用できるネットワーク帯域幅を設定することもできます。 *制限*ラジオ ボタンを選択し、使用できる最大帯域幅を入力するか、*無制限*を選択して制限がないことを示します。
-
-
[Tier Volumes] ページで、階層化を構成するボリュームを選択し、[Tiering Policy] ページを起動します。
-
すべてのボリュームを選択するには、タイトル行のボックスをチェックします(
 )をクリックし、「ボリュームの構成」を選択します。
)をクリックし、「ボリュームの構成」を選択します。 -
複数のボリュームを選択するには、各ボリュームのボックスをチェックします(
 )をクリックし、「ボリュームの構成」を選択します。
)をクリックし、「ボリュームの構成」を選択します。 -
単一のボリュームを選択するには、行(または
 ボリュームの(アイコン)をクリックします。
ボリュームの(アイコン)をクリックします。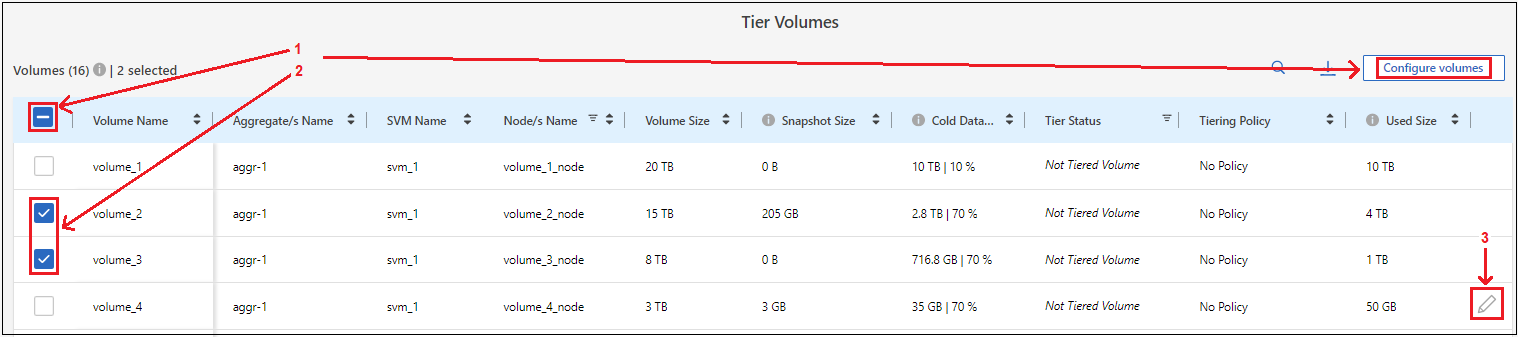
-
-
[階層化ポリシー] ダイアログで、階層化ポリシーを選択し、必要に応じて選択したボリュームの冷却日数を調整して、[適用] を選択します。
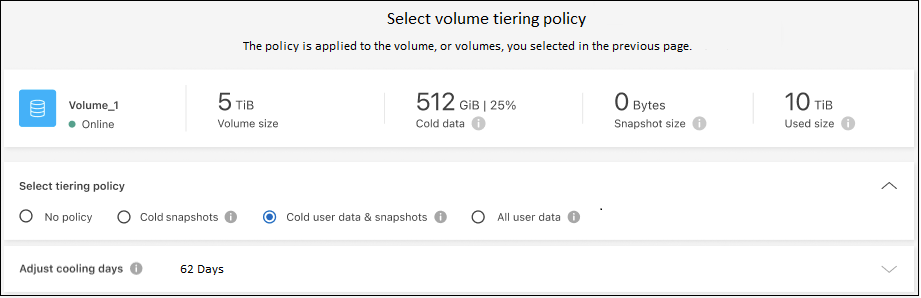
クラスター上のボリュームから S3 オブジェクト ストレージへのデータ階層化が正常に設定されました。
クラスター上のアクティブなデータと非アクティブなデータに関する情報を確認できます。"階層設定の管理について詳しくは" 。
クラスター上の特定のアグリゲートから異なるオブジェクト ストアにデータを階層化する必要がある場合は、追加のオブジェクト ストレージを作成することもできます。または、階層化されたデータが追加のオブジェクト ストアに複製されるFabricPoolミラーリングを使用する予定の場合。"オブジェクトストアの管理について詳しくは" 。