

NetApp Data Classificationについて学ぶ
 変更を提案
変更を提案
NetApp Data Classification は、 NetApp Consoleのデータ ガバナンス サービスであり、企業のオンプレミスおよびクラウド データ ソースをスキャンしてデータをマッピングおよび分類し、個人情報を識別します。これにより、セキュリティとコンプライアンスのリスクが軽減され、ストレージ コストが削減され、データ移行プロジェクトが支援されます。

|
バージョン 1.31 以降、データ分類はNetApp Console内のコア機能として利用できます。追加料金はかかりません。分類ライセンスやサブスクリプションは必要ありません。 + 旧バージョン 1.30 以前を使用している場合は、サブスクリプションの有効期限が切れるまでそのバージョンを利用できます。 |
NetApp Console
データ分類には、NetApp Consoleからアクセスできます。
NetApp Consoleは、オンプレミスとクラウド環境全体にわたるエンタープライズ グレードのNetAppストレージとデータ サービスの集中管理を提供します。NetAppデータ サービスにアクセスして使用するには、コンソールが必要です。管理インターフェースとして、1 つのインターフェースから多数のストレージ リソースを管理できます。コンソール管理者は、企業内のすべてのシステムのストレージとサービスへのアクセスを制御できます。
NetApp Consoleの使用を開始するためにライセンスやサブスクリプションは必要ありません。ストレージ システムまたはNetAppデータ サービスへの接続を確保するためにクラウドにコンソール エージェントを展開する必要がある場合にのみ料金が発生します。ただし、コンソールからアクセスできる一部のNetAppデータ サービスは、ライセンスまたはサブスクリプションベースです。
詳細はこちら"NetApp Console"。
機能
データ分類では、人工知能 (AI)、自然言語処理 (NLP)、機械学習 (ML) を使用してスキャンしたコンテンツを理解し、エンティティを抽出してそれに応じてコンテンツを分類します。これにより、データ分類では次の機能領域が提供できるようになります。
データ分類では、コンプライアンスの取り組みに役立ついくつかのツールが提供されます。データ分類を使用すると次のことができます。
-
個人を特定できる情報 (PII) を特定します。
-
GDPR、CCPA、PCI、HIPAA のプライバシー規制で要求される、広範囲にわたる機密個人情報を特定します。
-
名前または電子メール アドレスに基づいて、データ主体アクセス要求 (DSAR) に応答します。
データ分類により、犯罪目的でアクセスされる危険性があるデータを識別できます。データ分類を使用すると次のことができます。
-
組織全体または一般に公開されている、オープン権限を持つすべてのファイルとディレクトリ (共有とフォルダー) を識別します。
-
最初の専用場所の外部に存在する機密データを識別します。
-
データ保持ポリシーに準拠します。
-
Policies を使用すると、新しいセキュリティ問題が自動的に検出され、セキュリティ スタッフがすぐに対処できるようになります。
データ分類は、ストレージの総所有コスト (TCO) の削減に役立つツールを提供します。データ分類を使用すると次のことができます。
-
重複データやビジネスに関係のないデータを識別して、ストレージ効率を向上させます。
-
非アクティブなデータを特定し、より安価なオブジェクト ストレージに階層化することで、ストレージ コストを節約します。 "Cloud Volumes ONTAPシステムの階層化について詳しくは" 。 "オンプレミスのONTAPシステムからの階層化の詳細" 。
サポートされているシステムとデータソース
データ分類では、次の種類のシステムおよびデータ ソースからの構造化データと非構造化データをスキャンして分析できます。
システム
-
Amazon FSx for NetApp ONTAP管理
-
Azure NetApp Files
-
Cloud Volumes ONTAP (AWS、Azure、または GCP にデプロイ)
-
Google Cloud NetApp Volumes
-
オンプレミスのONTAPクラスタ
-
StorageGRID
データソース
-
NetAppファイル共有
-
データベース:
-
Amazon リレーショナルデータベースサービス (Amazon RDS)
-
MongoDB
-
MySQL
-
Oracle
-
PostgreSQL
-
SAP HANA
-
SQL サーバー (MSSQL)
-
データ分類では、NFS バージョン 3.x、4.0、4.1、および CIFS バージョン 1.x、2.0、2.1、3.0 がサポートされています。
料金
データ分類は無料でご利用いただけます。分類ライセンスや有料サブスクリプションは必要ありません。
インフラコスト
-
クラウドにデータ分類をインストールするには、クラウド インスタンスを展開する必要があり、展開先のクラウド プロバイダーから料金が発生します。見る各クラウドプロバイダーに展開されるインスタンスの種類 。オンプレミス システムに Data Classification をインストールする場合、料金はかかりません。
-
データ分類では、コンソール エージェントを展開する必要があります。多くの場合、コンソールで使用している他のストレージやサービスがあるため、既にコンソール エージェントが存在します。コンソール エージェント インスタンスには、デプロイされているクラウド プロバイダーからの料金が発生します。参照 "各クラウドプロバイダーに展開されるインスタンスの種類"。オンプレミス システムにコンソール エージェントをインストールする場合、料金はかかりません。
データ転送コスト
データ転送コストは設定によって異なります。データ分類インスタンスとデータ ソースが同じアベイラビリティー ゾーンとリージョンにある場合、データ転送コストは発生しません。ただし、 Cloud Volumes ONTAPシステムなどのデータ ソースが別のアベイラビリティ ゾーンまたはリージョンにある場合は、クラウド プロバイダーからデータ転送コストが請求されます。詳細については、次のリンクを参照してください。
データ分類インスタンス
クラウドにデータ分類をデプロイすると、コンソールはコンソール エージェントと同じサブネットにインスタンスをデプロイします。 "コンソール エージェントの詳細について説明します。"
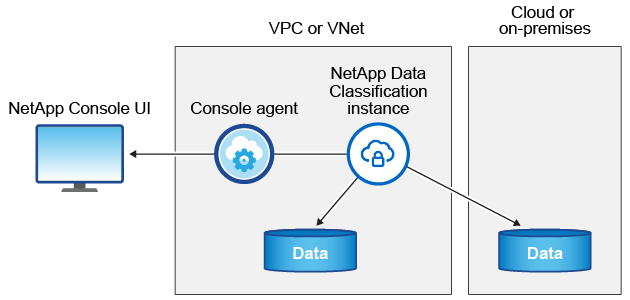
デフォルトインスタンスについては次の点に注意してください。
-
AWS では、データ分類は "m6i.4xlargeインスタンス"500 GiB の GP2 ディスクで実行されます。オペレーティングシステムイメージは Amazon Linux 2 です。
-
Azureでは、データ分類は"Standard_D16s_v3 VM"500 GiB のディスクを搭載。オペレーティング システム イメージは Ubuntu 22.04 です。
-
GCPでは、データ分類は"n2-標準-16 VM"500 GiB の標準永続ディスクを備えています。オペレーティング システム イメージは Ubuntu 22.04 です。
-
デフォルトのインスタンスが利用できないリージョンでは、データ分類は代替インスタンスで実行されます。"代替インスタンスタイプを参照" 。
-
インスタンスの名前は CloudCompliance となり、生成されたハッシュ (UUID) が連結されます。例: CloudCompliance-16bb6564-38ad-4080-9a92-36f5fd2f71c7
-
コンソール エージェントごとに 1 つのデータ分類インスタンスのみが展開されます。
また、オンプレミスの Linux ホストまたは優先クラウド プロバイダーのホストにデータ分類を展開することもできます。どのインストール方法を選択しても、ソフトウェアはまったく同じように機能します。インスタンスがインターネットにアクセスできる限り、データ分類ソフトウェアのアップグレードは自動化されます。

|
データ分類は継続的にデータをスキャンするため、インスタンスは常に実行されたままにしておく必要があります。 |
異なるインスタンスタイプにデプロイ
インスタンス タイプの次の仕様を確認してください。
| システムサイズ | 仕様 | 制限事項 |
|---|---|---|
特大 |
32 個の CPU、128 GB の RAM、1 TiB の SSD |
最大5億個のファイルをスキャンできます。 |
大(デフォルト) |
16 CPU、64 GB RAM、500 GiB SSD |
最大2億5000万個のファイルをスキャンできます。 |
データ分類スキャンの仕組み
大まかに言えば、データ分類スキャンは次のように機能します。
-
コンソールでデータ分類のインスタンスをデプロイします。
-
1つまたは複数のデータソースに対してスキャンを有効にします。
-
データ分類は、AI 学習プロセスを使用してデータをスキャンします。
-
提供されているダッシュボードとレポート ツールを使用して、コンプライアンスとガバナンスの取り組みを支援します。
データ分類を有効にし、スキャンするリポジトリ (ボリューム、データベース スキーマ、またはその他のユーザー データ) を選択すると、すぐにデータのスキャンが開始され、個人データと機密データが識別されます。ほとんどの場合、バックアップ、ミラー、または DR サイトではなく、ライブの本番データのスキャンに重点を置く必要があります。次に、データ分類によって組織のデータがマッピングされ、各ファイルが分類され、データ内のエンティティと定義済みパターンが識別および抽出されます。スキャンの結果は、個人情報、機密個人情報、データ カテゴリ、およびファイル タイプのインデックスです。
Data Classification は、NFS および CIFS ボリュームをマウントすることで、他のクライアントと同様にデータに接続します。 NFS ボリュームは自動的に読み取り専用としてアクセスされますが、CIFS ボリュームをスキャンするには Active Directory の資格情報を提供する必要があります。
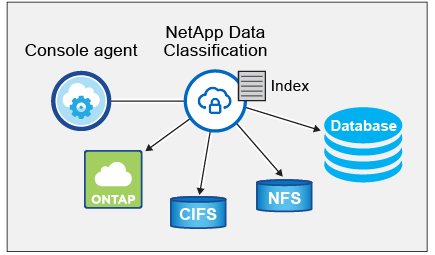
最初のスキャンの後、データ分類はラウンドロビン方式でデータを継続的にスキャンし、増分変更を検出します。そのため、インスタンスを実行し続けることが重要です。
ボリューム レベルまたはデータベース スキーマ レベルでスキャンを有効または無効にすることができます。

|
データ分類では、スキャンできるデータの量に制限はありません。各コンソール エージェントは、500 TiB のデータのスキャンと表示をサポートします。500TiB以上のデータをスキャンするには、"別のコンソールエージェントをインストールする"それから"別のデータ分類インスタンスをデプロイする"。 + コンソール UI には、単一のコネクタからのデータが表示されます。複数のコンソールエージェントからデータを表示するヒントについては、"複数のコンソールエージェントを操作する" 。 |
マッピングとフルスキャン
データ分類では、次の 2 種類のスキャンを実行できます。
-
マップのみのスキャンでは、データの概要のみが提供され、選択されたデータソースに対して実行されます。マップのみのスキャンは、ファイルにアクセスして内部のデータを確認しないため、フルスキャンよりも時間がかかりません。最初にこれを実行して調査領域を特定し、その後それらの領域に対してフルスキャンを実行することができます。
-
フルスキャンは、データの詳細なスキャンを提供します。フルスキャンには、マップのみのスキャンと、ファイル内のデータの分類が含まれます。
マップのみのスキャンとフルスキャンの違いの詳細については、"マッピングスキャンと分類スキャンの違いは何ですか?"を参照してください。
データ分類が分類する情報
データ分類では、次のデータを収集し、インデックスを付け、カテゴリを割り当てます。
-
ファイルに関する*標準メタデータ*: ファイルの種類、サイズ、作成日と変更日など。
-
個人データ: 電子メール アドレス、識別番号、クレジットカード番号などの個人を特定できる情報 (PII)。データ分類では、ファイル内の特定の単語、文字列、パターンを使用してこれを識別します。"個人データについて詳しくはこちら" 。
-
機密個人データ: 一般データ保護規則 (GDPR) やその他のプライバシー規制で定義されている、健康データ、民族的出身、政治的意見などの特別な種類の機密個人情報 (SPII)。"機密性の高い個人データについて詳しく見る" 。
-
カテゴリ: データ分類は、スキャンしたデータを取得し、それをさまざまな種類のカテゴリに分割します。カテゴリは、各ファイルのコンテンツとメタデータの AI 分析に基づくトピックです。"カテゴリーについて詳しく見る"。
-
名前エンティティ認識: データ分類では、AI を使用して文書から人の自然な名前を抽出します。"データ主体のアクセス要求への対応について学ぶ" 。
ネットワークの概要
データ分類では、クラウドまたはオンプレミスなど、任意の場所に単一のサーバーまたはクラスターを展開します。サーバーは標準プロトコルを介してデータ ソースに接続し、同じサーバーにデプロイされている Elasticsearch クラスターで検出結果をインデックス化します。これにより、マルチクラウド、クロスクラウド、プライベートクラウド、オンプレミス環境のサポートが可能になります。
コンソールは、コンソール エージェントからの受信 HTTP 接続を有効にするセキュリティ グループを使用して、データ分類インスタンスをデプロイします。
コンソールを SaaS モードで使用する場合、コンソールへの接続は HTTPS 経由で提供され、ブラウザとデータ分類インスタンス間で送信されるプライベート データは TLS 1.2 を使用したエンドツーエンドの暗号化で保護されるため、 NetAppやサードパーティが読み取ることはできません。
アウトバウンドルールは完全にオープンです。データ分類ソフトウェアをインストールおよびアップグレードし、使用状況メトリックを送信するには、インターネット アクセスが必要です。
厳しいネットワーク要件がある場合、"データ分類が接続するエンドポイントについて学習する" 。