

インターネットアクセスがあるホストにNetApp Data Classificationをインストールする
 変更を提案
変更を提案
ネットワーク内の Linux ホスト、またはインターネットにアクセスできるクラウド上の Linux ホストに NetApp Data Classification を導入するには、ネットワーク内またはクラウドに Linux ホストを手動で導入する必要があります。
オンプレミス インストールは、オンプレミスにあるデータ分類インスタンスを使用してオンプレミスのONTAPシステムをスキャンする場合に適したオプションです。これは必須ではありません。どのインストール方法を選択しても、ソフトウェアは同じように機能します。
データ分類のインストール スクリプトは、システムと環境が必要な前提条件を満たしているかどうかを確認することから始まります。前提条件がすべて満たされている場合は、インストールが開始されます。データ分類のインストールの実行とは別に前提条件を検証したい場合は、前提条件のみをテストする別のソフトウェア パッケージをダウンロードできます。"Linuxホストがデータ分類をインストールする準備ができているかどうかを確認する方法をご覧ください" 。

|
オンプレミスの VMware vSphere 環境では、Data Classification は簡素化された"OVAを使用した導入"をサポートします。 |
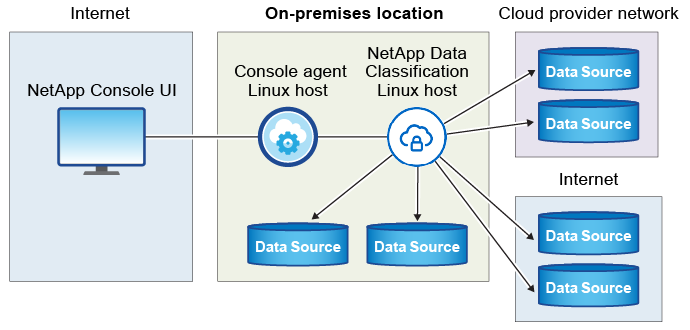
社内の Linux ホストへの一般的なインストールには、次のコンポーネントと接続が含まれます。
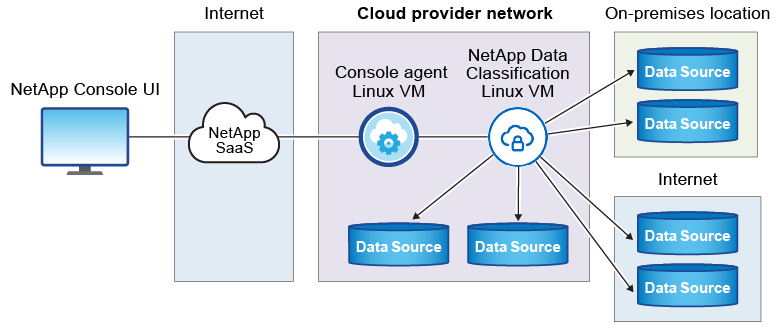
クラウド内の Linux ホストへの一般的なインストールには、次のコンポーネントと接続が含まれます。
クイック スタート
以下の手順に従ってすぐに開始するか、残りのセクションまでスクロールして詳細を確認してください。
 コンソールエージェントを作成する
コンソールエージェントを作成するコンソールエージェントがまだない場合は、 "コンソールエージェントをオンプレミスに展開する"ネットワーク内の Linux ホスト上、またはクラウド内の Linux ホスト上。
クラウド プロバイダーを使用してコンソール エージェントを作成することもできます。見る "AWSでコンソールエージェントを作成する"、 "Azureでコンソールエージェントを作成する" 、 または "GCP でコンソール エージェントを作成する"。
 前提条件を確認する
前提条件を確認するご使用の環境が前提条件を満たしていることを確認してください。これには、インスタンスのアウトバウンド インターネット アクセス、ポート 443 経由のコンソール エージェントとデータ分類間の接続などが含まれます。完全なリストを見る 。
また、以下の要件を満たすLinuxシステムも必要です。以下の要件 。
 データ分類をダウンロードして展開する
データ分類をダウンロードして展開するNetAppサポート サイトから Cloud Data Classification ソフトウェアをダウンロードし、使用する予定の Linux ホストにインストーラ ファイルをコピーします。次に、インストール ウィザードを起動し、プロンプトに従ってデータ分類インスタンスをデプロイします。
コンソールエージェントを作成する
Data Classification をインストールして使用するには、Console エージェントが必要です。ほとんどの場合、Data Classification をアクティブ化する前に、Console エージェントをセットアップしておく必要があるでしょう。
クラウドプロバイダー環境で作成するには、 "AWSでコンソールエージェントを作成する" 、 "Azureでコンソールエージェントを作成する" 、 または "GCP でコンソール エージェントを作成する"。
特定のクラウド プロバイダーにデプロイされたコンソール エージェントを使用する必要があるシナリオがいくつかあります。
-
AWS のCloud Volumes ONTAPまたはAmazon FSx for ONTAPでデータをスキャンする場合は、AWS のコンソールエージェントを使用します。
-
Azure のCloud Volumes ONTAPまたはAzure NetApp Filesでデータをスキャンする場合は、Azure のコンソール エージェントを使用します。
Azure NetApp Filesの場合、スキャンするボリュームと同じリージョンにデプロイする必要があります。
-
GCP のCloud Volumes ONTAPでデータをスキャンする場合は、GCP のコンソール エージェントを使用します。
オンプレミスのONTAPシステム、 NetAppファイル共有、データベース アカウントは、これらのクラウド コンソール エージェントのいずれかを使用してスキャンできます。
また、 "コンソールエージェントをオンプレミスに展開する"ネットワーク内の Linux ホストまたはクラウド内の Linux ホスト上。オンプレミスで Data Classification をインストールする予定のユーザーの中には、オンプレミスでコンソール エージェントをインストールすることを選択する場合もあります。
Data Classification をインストールするときは、コンソール エージェント システムの IP アドレスまたはホスト名が必要になります。オンプレミスでコンソール エージェントをインストールした場合は、この情報が得られます。コンソール エージェントがクラウドに展開されている場合は、コンソールからこの情報を確認できます。ヘルプ アイコンを選択し、次に サポート、コンソール エージェント を選択します。
Linuxホストシステムを準備する
データ分類ソフトウェアは、特定のオペレーティング システム要件、RAM 要件、ソフトウェア要件などを満たすホスト上で実行する必要があります。 Linux ホストはネットワーク内またはクラウド内に配置できます。
データ分類を実行し続けることができることを確認します。データ分類マシンは、データを継続的にスキャンするためにオンのままにしておく必要があります。
-
データ分類は専用ホスト上で実行する必要があります。ホストは、他のアプリケーションやウイルス対策などのサードパーティ製ソフトウェアと共有することはできません。
-
データ分類でスキャンする予定のデータ セットに合わせてサイズを選択します。
システムサイズ CPU RAM(スワップメモリを無効にする必要があります) ディスク 特大
CPU×32
128GBのRAM
-
/ に 1 TiB SSD、または /opt に 100 GiB 利用可能
-
/var/lib/docker で 895 GiB が利用可能
-
/tmp に 5 GiB
-
Podman の場合、/var/tmp に 30 GB
大きい
CPU×16
64GBのRAM
-
/ に 500 GiB SSD、または /opt に 100 GiB 利用可能
-
/var/lib/docker または Podman /var/lib/containers で 400 GiB が利用可能
-
/tmp に 5 GiB
-
Podman の場合、/var/tmp に 30 GB
-
-
データ分類インストール用にクラウドにコンピューティング インスタンスをデプロイする場合は、上記の「大規模」システム要件を満たすシステムを使用することをお勧めします。
-
Amazon Elastic Compute Cloud (Amazon EC2) インスタンスタイプ:「m6i.4xlarge」。"その他のAWSインスタンスタイプを見る" 。
-
Azure VM サイズ:"Standard_D16_v5"。"その他のAzureインスタンスタイプを見る"。
-
GCP マシンタイプ:「n2-standard-16」。"その他の GCP インスタンスタイプを見る" 。
-
-
UNIX フォルダ権限: 次の最低限の UNIX 権限が必要です。
フォルダ 最小限の権限 /tmp
rwxrwxrwt/opt
rwxr-xr-x/var/lib/docker
rwx------/usr/lib/systemd/システム
rwxr-xr-x -
オペレーティング·システム:
-
次のオペレーティング システムでは、Docker コンテナ エンジンを使用する必要があります。
-
Red Hat Enterprise Linux バージョン 7.8 および 7.9
-
Ubuntu 22.04 (データ分類バージョン 1.23 以上が必要)
-
Ubuntu 24.04 (データ分類バージョン 1.23 以上が必要)
-
-
次のオペレーティング システムでは、Podman コンテナー エンジンを使用する必要があり、データ分類バージョン 1.30 以上が必要です。
-
Red Hat Enterprise Linux バージョン 8.8、8.10、9.0、9.1、9.2、9.3、9.4、9.5、9.6、および 9.7。
-
-
ホスト システムで Advanced Vector Extensions (AVX2) を有効にする必要があります。
-
-
Red Hat サブスクリプション管理: ホストは Red Hat サブスクリプション管理に登録されている必要があります。登録されていない場合、システムはリポジトリにアクセスできず、インストール中に必要なサードパーティ製ソフトウェアを更新できません。
-
追加ソフトウェア: Data Classification をインストールする前に、ホストに次のソフトウェアをインストールする必要があります。
-
使用している OS に応じて、次のいずれかのコンテナ エンジンをインストールする必要があります。
-
Docker Engine バージョン 19.3.1 以上。 "インストール手順を見る" 。
-
Podman バージョン 4 以上。 Podmanをインストールするには、次のように入力します。(
sudo yum install podman netavark -y)。
-
-
-
Python バージョン 3.6 以上。 "インストール手順を見る" 。
-
NTP に関する考慮事項: NetApp、データ分類システムをネットワーク タイム プロトコル (NTP) サービスを使用するように構成することを推奨しています。データ分類システムとコンソール エージェント システムの間で時刻を同期する必要があります。
-
-
Firewalldの考慮事項: 使用を計画している場合
firewalld、データ分類をインストールする前に有効にすることをお勧めします。設定するには次のコマンドを実行します `firewalld`データ分類と互換性があるように:firewall-cmd --permanent --add-service=http firewall-cmd --permanent --add-service=https firewall-cmd --permanent --add-port=80/tcp firewall-cmd --permanent --add-port=8080/tcp firewall-cmd --permanent --add-port=443/tcp firewall-cmd --reload
追加のデータ分類ホストをスキャナー ノードとして使用することを計画している場合は、この時点で次のルールをプライマリ システムに追加します。
firewall-cmd --permanent --add-port=2377/tcp firewall-cmd --permanent --add-port=7946/udp firewall-cmd --permanent --add-port=7946/tcp firewall-cmd --permanent --add-port=4789/udp
有効化または更新するたびにDockerまたはPodmanを再起動する必要があることに注意してください。 `firewalld`設定。

|
データ分類ホスト システムの IP アドレスは、インストール後に変更することはできません。 |
データ分類からのアウトバウンドインターネットアクセスを有効にする
データ分類には、アウトバウンドのインターネット アクセスが必要です。仮想ネットワークまたは物理ネットワークでインターネット アクセスにプロキシ サーバーを使用している場合は、データ分類インスタンスに次のエンドポイントに接続するための送信インターネット アクセスがあることを確認してください。
| エンドポイント | 目的 |
|---|---|
https://api.console.netapp.com |
NetAppアカウントを含むコンソールとの通信。 |
https://netapp-cloud-account.auth0.com https://auth0.com |
集中ユーザー認証のためのコンソール Web サイトとの通信。 |
https://support.compliance.api.bluexp.netapp.com/ https://hub.docker.com https://auth.docker.io https://registry-1.docker.io https://index.docker.io/ https://dseasb33srnrn.cloudfront.net/ https://production.cloudflare.docker.com/ |
ソフトウェア イメージ、マニフェスト、テンプレートへのアクセスを提供し、ログとメトリックを送信します。 |
https://support.compliance.api.bluexp.netapp.com/ |
NetApp が監査レコードからデータをストリーミングできるようにします。 |
https://github.com/docker https://download.docker.com |
docker インストールの前提条件パッケージを提供します。 |
http://packages.ubuntu.com/ http://archive.ubuntu.com |
Ubuntu インストールの前提条件となるパッケージを提供します。 |
必要なポートがすべて有効になっていることを確認します
コンソール エージェント、データ分類、Active Directory、およびデータ ソース間の通信に必要なすべてのポートが開いていることを確認する必要があります。
| 接続タイプ | ポート | 説明 |
|---|---|---|
コンソールエージェント <> データ分類 |
8080 (TCP)、443 (TCP)、および 80。9000 |
コンソール エージェントのファイアウォールまたはルーティング ルールでは、ポート 443 経由のデータ分類インスタンスとの間の受信トラフィックと送信トラフィックを許可する必要があります。コンソールでインストールの進行状況を確認できるように、ポート 8080 が開いていることを確認してください。 Linux ホストでファイアウォールが使用されている場合、Ubuntu サーバー内の内部プロセスにはポート 9000 が必要です。 |
コンソールエージェント <> ONTAPクラスタ (NAS) |
443(TCP) |
コンソールは、HTTPS を使用してONTAPクラスターを検出します。カスタム ファイアウォール ポリシーを使用する場合は、次の要件を満たす必要があります。
|
データ分類 <> ONTAPクラスタ |
|
データ分類には、各Cloud Volumes ONTAPサブネットまたはオンプレミスのONTAPシステムへのネットワーク接続が必要です。 Cloud Volumes ONTAPのファイアウォールまたはルーティング ルールは、データ分類インスタンスからの受信接続を許可する必要があります。 次のポートがデータ分類インスタンスに対して開いていることを確認します。
NFS ボリュームのエクスポート ポリシーでは、データ分類インスタンスからのアクセスを許可する必要があります。 |
データ分類 <> Active Directory |
389 (TCP & UDP)、636 (TCP)、3268 (TCP)、および 3269 (TCP) |
社内のユーザー用に Active Directory がすでに設定されている必要があります。さらに、データ分類では、CIFS ボリュームをスキャンするために Active Directory 資格情報が必要です。 Active Directory の情報が必要です:
|
Linuxホストにデータ分類をインストールする
通常の構成では、ソフトウェアを単一のホスト システムにインストールします。ここでその手順をご覧ください 。
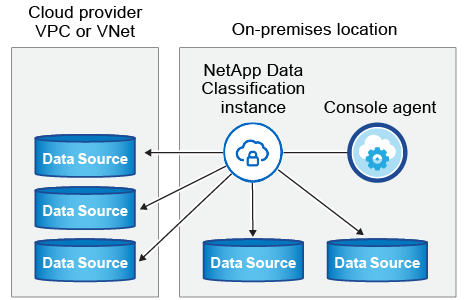
見るLinuxホストシステムの準備そして前提条件の確認データ分類を展開する前に、要件の完全なリストを確認してください。
インスタンスがインターネットに接続されている限り、データ分類ソフトウェアへのアップグレードは自動化されます。
|
|
現在、データ分類では、ソフトウェアがオンプレミスにインストールされている場合、S3 バケット、 Azure NetApp Files、または FSx for ONTAPをスキャンできません。このような場合には、クラウドに別のコンソールエージェントとデータ分類のインスタンスを展開し、 "コネクタ間の切り替え"さまざまなデータ ソース用。 |
一般的な構成の単一ホストインストール
単一のオンプレミス ホストにデータ分類ソフトウェアをインストールする場合は、要件を確認し、次の手順に従ってください。
"このビデオを見る"Data Classification のインストール方法を確認します。
Data Classification をインストールすると、すべてのインストール アクティビティがログに記録されることに注意してください。インストール中に問題が発生した場合は、インストール監査ログの内容を表示できます。それは、 /opt/netapp/install_logs/ 。
-
Linuxシステムがホスト要件。
-
システムに 2 つの前提条件ソフトウェア パッケージ (Docker Engine または Podman、および Python 3) がインストールされていることを確認します。
-
Linux システムでルート権限を持っていることを確認してください。
-
インターネットへのアクセスにプロキシを使用している場合:
-
プロキシ サーバー情報 (IP アドレスまたはホスト名、接続ポート、接続スキーム: https または http、ユーザー名とパスワード) が必要になります。
-
プロキシが TLS インターセプションを実行している場合は、TLS CA 証明書が保存されている Data Classification Linux システム上のパスを知っておく必要があります。
-
プロキシは非透過である必要があります。データ分類は現在、透過プロキシをサポートしていません。
-
ユーザーはローカル ユーザーである必要があります。ドメイン ユーザーはサポートされていません。
-
-
オフライン環境が要件を満たしていることを確認する権限と接続性。
-
"NetAppサポート サイト"からData Classificationソフトウェアをダウンロードします。*DATASENSE-INSTALLER-<version>.tar.gz*という名前のファイルを選択します。
-
使用する予定のLinuxホストにインストーラファイルをコピーします( `scp`または他の方法)。
-
ホスト マシン上でインストーラ ファイルを解凍します。例:
tar -xzf DATASENSE-INSTALLER-V1.25.0.tar.gz -
コンソールで、*ガバナンス > 分類*を選択します。
-
*オンプレミスまたはクラウドでの分類の展開*を選択します。
-
クラウドで準備したインスタンスにデータ分類をインストールするか、オンプレミスで準備したインスタンスにデータ分類をインストールするかに応じて、適切な デプロイ オプションを選択してデータ分類のインストールを開始します。
-
オンプレミスでのデータ分類の展開 ダイアログが表示されます。提供されたコマンドをコピーします(例:
sudo ./install.sh -a 12345 -c 27AG75 -t 2198qq) を作成し、テキスト ファイルに貼り付けて、後で使用することもできます。次に、[閉じる] を選択してダイアログを閉じます。 -
ホスト マシンで、コピーしたコマンドを入力して一連のプロンプトに従うか、必要なすべてのパラメーターを含む完全なコマンドをコマンド ライン引数として指定することもできます。
インストーラーは、インストールを正常に実行するためにシステムとネットワークの要件が満たされているかどうかを確認するための事前チェックを実行することに注意してください。 "このビデオを見る"事前チェックのメッセージとその意味を理解する。
プロンプトに従ってパラメータを入力します。 完全なコマンドを入力します。 -
手順 7 からコピーしたコマンドを貼り付けます。
sudo ./install.sh -a <account_id> -c <client_id> -t <user_token>クラウドインスタンス(オンプレミスではない)にインストールする場合は、
--manual-cloud-install <cloud_provider>。 -
コンソール エージェント システムからアクセスできるように、データ分類ホスト マシンの IP アドレスまたはホスト名を入力します。
-
データ分類システムからアクセスできるように、コンソール エージェント ホスト マシンの IP アドレスまたはホスト名を入力します。
-
プロンプトに従ってプロキシの詳細を入力します。コンソール エージェントがすでにプロキシを使用している場合は、データ分類はコンソール エージェントが使用するプロキシを自動的に使用するため、ここでこの情報を再度入力する必要はありません。
あるいは、必要なホストとプロキシのパラメータを指定して、コマンド全体を事前に作成することもできます。
sudo ./install.sh -a <account_id> -c <client_id> -t <user_token> --host <ds_host> --manager-host <cm_host> --manual-cloud-install <cloud_provider> --proxy-host <proxy_host> --proxy-port <proxy_port> --proxy-scheme <proxy_scheme> --proxy-user <proxy_user> --proxy-password <proxy_password> --cacert-folder-path <ca_cert_dir>変数値:
-
account_id = NetAppアカウント ID
-
client_id = コンソールエージェントのクライアントID(クライアントIDに「clients」というサフィックスがない場合は追加します)
-
user_token = JWTユーザーアクセストークン
-
ds_host = データ分類 Linux システムの IP アドレスまたはホスト名。
-
cm_host = コンソール エージェント システムの IP アドレスまたはホスト名。
-
cloud_provider = クラウドインスタンスにインストールする場合は、クラウドプロバイダーに応じて「AWS」、「Azure」、または「Gcp」を入力します。
-
proxy_host = ホストがプロキシ サーバーの背後にある場合のプロキシ サーバーの IP またはホスト名。
-
proxy_port = プロキシ サーバーに接続するためのポート (デフォルトは 80)。
-
proxy_scheme = 接続スキーム: https または http (デフォルトは http)。
-
proxy_user = 基本認証が必要な場合に、プロキシ サーバーに接続するための認証済みユーザー。ユーザーはローカル ユーザーである必要があります。ドメイン ユーザーはサポートされていません。
-
proxy_password = 指定したユーザー名のパスワード。
-
ca_cert_dir = 追加の TLS CA 証明書バンドルを含むデータ分類 Linux システム上のパス。プロキシが TLS インターセプションを実行している場合にのみ必要です。
-
Data Classification インストーラーは、パッケージをインストールし、インストールを登録し、Data Classification をインストールします。インストールには10〜20分かかります。
ホスト マシンとコンソール エージェント インスタンスの間にポート 8080 経由の接続がある場合は、コンソールの [データ分類] タブにインストールの進行状況が表示されます。