

NetApp Cloud Tiering 에서 온프레미스 ONTAP 클러스터의 데이터를 Amazon S3로 계층화
 변경 제안
변경 제안
NetApp Cloud Tiering 에서 비활성 데이터를 Amazon S3에 계층화하여 온프레미스 ONTAP 클러스터의 공간을 확보하세요.
빠른 시작
다음 단계에 따라 빠르게 시작하세요. 각 단계에 대한 자세한 내용은 이 항목의 다음 섹션에서 설명합니다.
 사용할 구성 방법을 식별하세요
사용할 구성 방법을 식별하세요온프레미스 ONTAP 클러스터를 공용 인터넷을 통해 AWS S3에 직접 연결할지, 아니면 VPN이나 AWS Direct Connect를 사용하여 프라이빗 VPC 엔드포인트 인터페이스를 통해 트래픽을 AWS S3로 라우팅할지 선택합니다.
 콘솔 에이전트 준비
콘솔 에이전트 준비AWS VPC나 사내에 콘솔 에이전트를 이미 배포한 경우 모든 준비가 완료된 것입니다. 그렇지 않은 경우 ONTAP 데이터를 AWS S3 스토리지로 계층화하기 위한 에이전트를 만들어야 합니다. 또한 에이전트가 AWS S3에 연결할 수 있도록 네트워크 설정을 사용자 지정해야 합니다.
 온프레미스 ONTAP 클러스터 준비
온프레미스 ONTAP 클러스터 준비NetApp Console 에서 ONTAP 클러스터를 검색하고, 클러스터가 최소 요구 사항을 충족하는지 확인하고, 클러스터가 AWS S3에 연결할 수 있도록 네트워크 설정을 사용자 지정합니다.
 Amazon S3를 계층화 대상으로 준비하세요
Amazon S3를 계층화 대상으로 준비하세요에이전트가 S3 버킷을 만들고 관리할 수 있는 권한을 설정합니다. 또한 온프레미스 ONTAP 클러스터에 대한 권한을 설정하여 S3 버킷에서 데이터를 읽고 쓸 수 있도록 해야 합니다.
 시스템에서 클라우드 티어링 활성화
시스템에서 클라우드 티어링 활성화온프레미스 시스템을 선택하고, 클라우드 티어링 서비스에 대해 *활성화*를 선택한 다음, 화면의 지시에 따라 데이터를 Amazon S3로 계층화합니다.
 라이센스 설정
라이센스 설정무료 평가판이 종료된 후에는 사용량에 따른 요금 구독, ONTAP Cloud Tiering BYOL 라이선스 또는 두 가지를 조합하여 Cloud Tiering 비용을 지불하세요.
-
AWS Marketplace에서 구독하려면 "마켓플레이스 상품으로 이동" , *구독*을 선택한 다음, 안내를 따르세요.
-
Cloud Tiering BYOL 라이선스를 사용하여 지불하려면 구매해야 하는 경우 문의으로 이메일을 보내십시오."NetApp Console 에 추가하세요" .
연결 옵션에 대한 네트워크 다이어그램
온프레미스 ONTAP 시스템에서 AWS S3로 계층화를 구성할 때 사용할 수 있는 연결 방법은 두 가지가 있습니다.
-
공개 연결 - 공개 S3 엔드포인트를 사용하여 ONTAP 시스템을 AWS S3에 직접 연결합니다.
-
개인 연결 - VPN 또는 AWS Direct Connect를 사용하고 개인 IP 주소를 사용하는 VPC 엔드포인트 인터페이스를 통해 트래픽을 라우팅합니다.
다음 다이어그램은 공개 연결 방법과 구성 요소 간에 준비해야 하는 연결을 보여줍니다. 사내에 설치한 콘솔 에이전트나 AWS VPC에 배포한 에이전트를 사용할 수 있습니다.
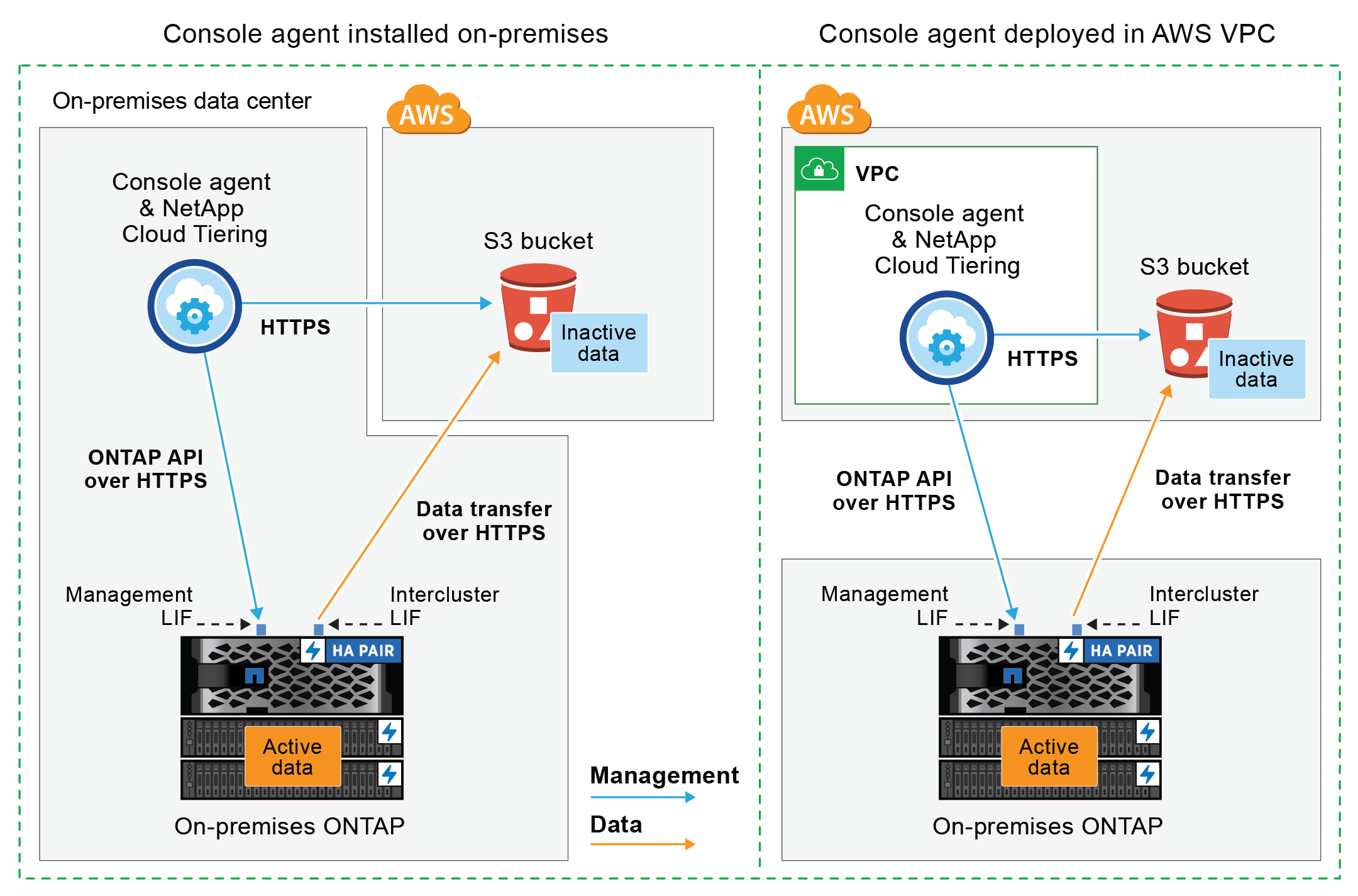
다음 다이어그램은 개인 연결 방법과 구성 요소 간에 준비해야 하는 연결을 보여줍니다. 사내에 설치한 콘솔 에이전트나 AWS VPC에 배포한 에이전트를 사용할 수 있습니다.
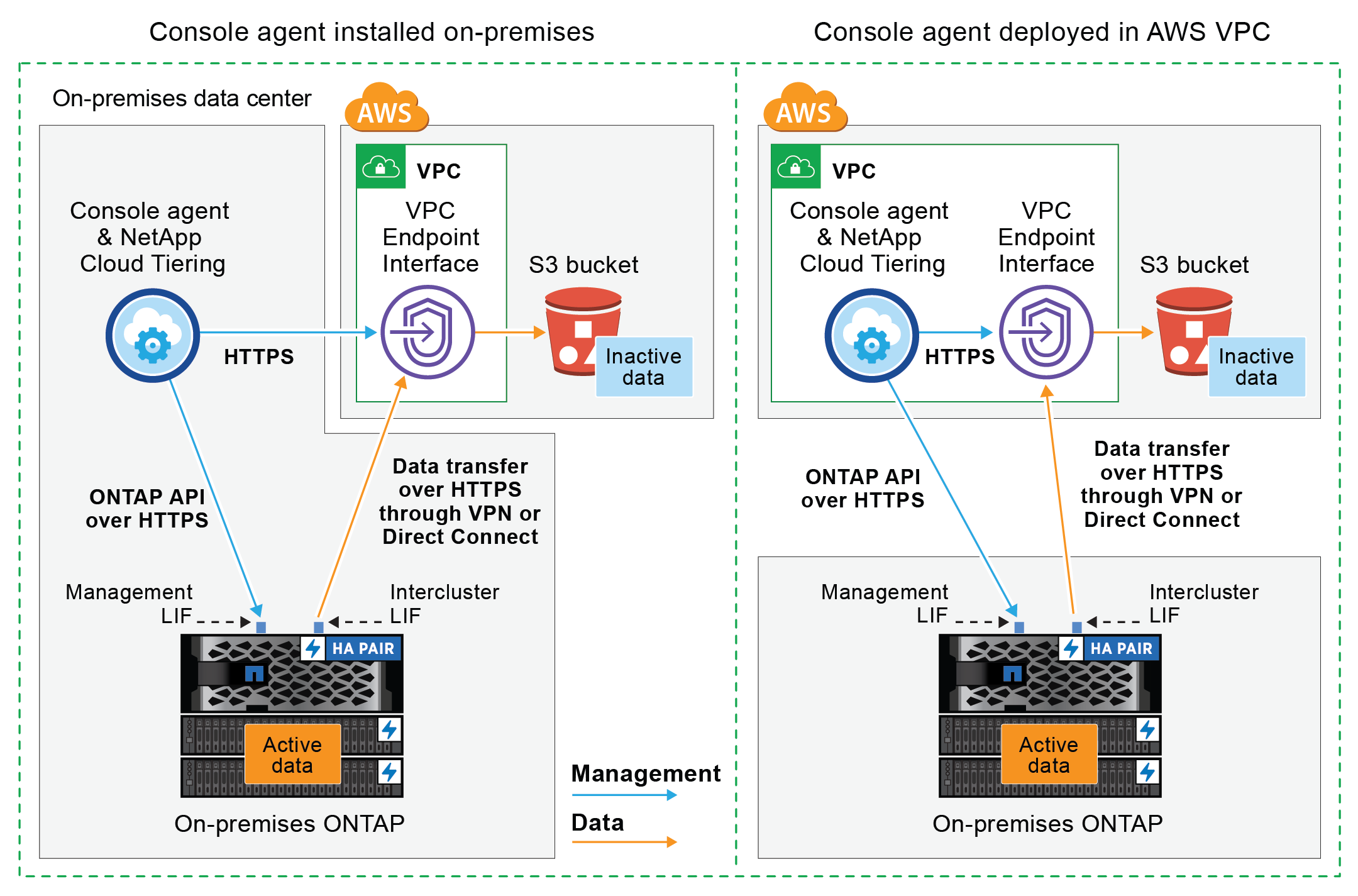

|
에이전트와 S3 간의 통신은 개체 스토리지 설정을 위한 것입니다. |
콘솔 에이전트를 준비하세요
에이전트는 NetApp Console 에서 계층화 기능을 활성화합니다. 비활성 ONTAP 데이터를 계층화하려면 에이전트가 필요합니다.
에이전트 생성 또는 전환
AWS VPC나 사내에 에이전트를 이미 배포한 경우 준비가 완료된 것입니다. 그렇지 않은 경우 해당 위치 중 하나에 에이전트를 만들어 ONTAP 데이터를 AWS S3 스토리지로 계층화해야 합니다. 다른 클라우드 공급자에 배포된 에이전트를 사용할 수 없습니다.
에이전트 네트워킹 요구 사항
-
에이전트가 설치된 네트워크에서 다음 연결이 허용되는지 확인하세요.
-
포트 443을 통해 Cloud Tiering 서비스 및 S3 개체 스토리지에 HTTPS 연결("엔드포인트 목록을 확인하세요" )
-
ONTAP 클러스터 관리 LIF에 대한 포트 443을 통한 HTTPS 연결
-
-
ONTAP 클러스터에서 VPC로 Direct Connect 또는 VPN 연결이 있고 에이전트와 S3 간 통신을 AWS 내부 네트워크(비공개 연결)에 유지하려는 경우 S3에 대한 VPC 엔드포인트 인터페이스를 활성화해야 합니다.VPC 엔드포인트 인터페이스를 설정하는 방법을 알아보세요.
ONTAP 클러스터 준비
Amazon S3에 데이터를 계층화할 때 ONTAP 클러스터는 다음 요구 사항을 충족해야 합니다.
ONTAP 요구 사항
- 지원되는 ONTAP 플랫폼
-
-
ONTAP 9.8 이상을 사용하는 경우: AFF 시스템이나 FAS 시스템의 데이터를 모든 SSD 집계 또는 모든 HDD 집계를 사용하여 계층화할 수 있습니다.
-
ONTAP 9.7 및 이전 버전을 사용하는 경우: 모든 SSD 집계를 사용하여 AFF 시스템 또는 FAS 시스템의 데이터를 계층화할 수 있습니다.
-
- 지원되는 ONTAP 버전
-
-
ONTAP 9.2 이상
-
AWS PrivateLink 연결을 사용하여 객체 스토리지에 연결하려면 ONTAP 9.7 이상이 필요합니다.
-
- 지원되는 볼륨 및 집계
-
Cloud Tiering에서 계층화할 수 있는 볼륨의 총 수는 ONTAP 시스템의 볼륨 수보다 적을 수 있습니다. 이는 일부 집계에서 볼륨을 계층화할 수 없기 때문입니다. ONTAP 설명서를 참조하세요. "FabricPool 에서 지원하지 않는 기능 또는 특징" .
|
|
Cloud Tiering은 ONTAP 9.5부터 FlexGroup 볼륨을 지원합니다. 설치는 다른 볼륨과 동일하게 진행됩니다. |
클러스터 네트워킹 요구 사항
-
클러스터에는 콘솔 에이전트에서 클러스터 관리 LIF로의 인바운드 HTTPS 연결이 필요합니다.
클러스터와 클라우드 티어링 간의 연결은 필요하지 않습니다.
-
계층화하려는 볼륨을 호스팅하는 각 ONTAP 노드에는 클러스터 간 LIF가 필요합니다. 이러한 클러스터 간 LIF는 개체 저장소에 액세스할 수 있어야 합니다.
클러스터는 계층화 작업을 위해 클러스터 간 LIF에서 Amazon S3 스토리지로 포트 443을 통해 아웃바운드 HTTPS 연결을 시작합니다. ONTAP 개체 스토리지에서 데이터를 읽고 씁니다. 개체 스토리지는 결코 시작하지 않고 단지 응답만 합니다.
-
클러스터 간 LIF는 ONTAP 개체 스토리지에 연결하는 데 사용해야 하는 _IPspace_와 연결되어야 합니다. "IPspaces에 대해 자세히 알아보세요" .
클라우드 티어링을 설정하면 사용할 IP 공간을 입력하라는 메시지가 표시됩니다. 이러한 LIF가 연결된 IP 공간을 선택해야 합니다. 이는 "기본" IP 공간일 수도 있고 사용자가 만든 사용자 지정 IP 공간일 수도 있습니다.
"기본"이 아닌 다른 IP 공간을 사용하는 경우 개체 스토리지에 액세스하려면 정적 경로를 만들어야 할 수도 있습니다.
IPspace 내의 모든 클러스터 간 LIF는 개체 저장소에 액세스할 수 있어야 합니다. 현재 IP 공간에 대해 이를 구성할 수 없는 경우 모든 클러스터 간 LIF가 개체 저장소에 액세스할 수 있는 전용 IP 공간을 만들어야 합니다.
-
AWS에서 S3 연결을 위해 Private VPC Interface Endpoint를 사용하는 경우 HTTPS/443을 사용하려면 S3 엔드포인트 인증서를 ONTAP 클러스터에 로드해야 합니다.VPC 엔드포인트 인터페이스를 설정하고 S3 인증서를 로드하는 방법을 알아보세요.
NetApp Console 에서 ONTAP 클러스터를 찾아보세요
콜드 데이터를 개체 스토리지로 계층화하려면 먼저 NetApp Console 에서 온프레미스 ONTAP 클러스터를 검색해야 합니다. 클러스터를 추가하려면 클러스터 관리 IP 주소와 관리자 사용자 계정의 비밀번호를 알아야 합니다.
AWS 환경 준비
새 클러스터에 대한 데이터 계층화를 설정하면 서비스에서 S3 버킷을 생성할지 아니면 에이전트가 설정된 AWS 계정에서 기존 S3 버킷을 선택할지 묻는 메시지가 표시됩니다. AWS 계정에는 Cloud Tiering에 입력할 수 있는 권한과 액세스 키가 있어야 합니다. ONTAP 클러스터는 액세스 키를 사용하여 S3에 데이터를 계층화하고 저장합니다.
기본적으로 클라우드 티어링은 버킷을 자동으로 생성합니다. 자신의 버킷을 사용하려면 계층화 활성화 마법사를 시작하기 전에 버킷을 하나 만든 다음 마법사에서 해당 버킷을 선택하면 됩니다. "NetApp Console 에서 S3 버킷을 만드는 방법을 알아보세요." . 버킷은 볼륨의 비활성 데이터를 저장하는 데만 사용해야 하며 다른 용도로는 사용할 수 없습니다. S3 버킷은 다음 위치에 있어야 합니다."클라우드 티어링을 지원하는 지역" .
|
|
특정 기간 후에 계층화된 데이터가 전환되는 비용이 낮은 스토리지 클래스를 사용하도록 Cloud Tiering을 구성하려는 경우 AWS 계정에서 버킷을 설정할 때 어떠한 수명 주기 규칙도 선택해서는 안 됩니다. 클라우드 티어링은 수명 주기 전환을 관리합니다. |
S3 권한 설정
두 가지 권한 세트를 구성해야 합니다.
-
에이전트가 S3 버킷을 생성하고 관리할 수 있는 권한입니다.
-
온프레미스 ONTAP 클러스터가 S3 버킷에서 데이터를 읽고 쓸 수 있는 권한입니다.
-
콘솔 에이전트 권한:
-
확인해주세요 "이 S3 권한" 에이전트에게 권한을 제공하는 IAM 역할의 일부입니다. 에이전트를 처음 배포했을 때 기본적으로 포함되어 있어야 합니다. 그렇지 않은 경우 누락된 권한을 추가해야 합니다. 를 참조하십시오 "AWS 설명서: IAM 정책 편집" 지침을 보려면.
-
Cloud Tiering이 생성하는 기본 버킷에는 "fabric-pool"이라는 접두사가 붙습니다. 버킷에 다른 접두사를 사용하려면 사용하려는 이름으로 권한을 사용자 지정해야 합니다. S3 권한에서 다음 줄이 표시됩니다.
"Resource": ["arn:aws:s3:::fabric-pool*"]. "fabric-pool"을 사용하려는 접두사로 변경해야 합니다. 예를 들어, 버킷의 접두사로 "tiering-1"을 사용하려면 이 줄을 다음과 같이 변경합니다."Resource": ["arn:aws:s3:::tiering-1*"].동일한 NetApp Console 조직에서 추가 클러스터에 사용할 버킷에 다른 접두사를 사용하려는 경우 다른 버킷에 대한 접두사가 포함된 다른 줄을 추가할 수 있습니다. 예를 들어:
"Resource": ["arn:aws:s3:::tiering-1*"]
"Resource": ["arn:aws:s3:::tiering-2*"]
자신의 버킷을 생성하고 표준 접두사를 사용하지 않는 경우 이 줄을 다음으로 변경해야 합니다.
"Resource": ["arn:aws:s3:::*"]따라서 모든 버킷이 인식됩니다. 하지만 이렇게 하면 볼륨에서 비활성 데이터를 보관하도록 설계한 버킷 대신 모든 버킷이 노출될 수 있습니다. -
-
클러스터 권한:
-
서비스를 활성화하면 계층화 마법사가 액세스 키와 비밀 키를 입력하라는 메시지를 표시합니다. 이러한 자격 증명은 ONTAP 클러스터로 전달되어 ONTAP 이 데이터를 S3 버킷에 계층화할 수 있도록 합니다. 이를 위해서는 다음 권한이 있는 IAM 사용자를 만들어야 합니다.
"s3:ListAllMyBuckets", "s3:ListBucket", "s3:GetBucketLocation", "s3:GetObject", "s3:PutObject", "s3:DeleteObject"를 참조하십시오 "AWS 설명서: IAM 사용자에게 권한을 위임하는 역할 생성" 자세한 내용은.
-
-
액세스 키를 생성하거나 찾습니다.
클라우드 티어링은 액세스 키를 ONTAP 클러스터에 전달합니다. 자격 증명은 Cloud Tiering 서비스에 저장되지 않습니다.
VPC 엔드포인트 인터페이스를 사용하여 개인 연결을 위한 시스템 구성
표준 공용 인터넷 연결을 사용하려는 경우 모든 권한은 에이전트가 설정하므로 별도로 설정하실 필요가 없습니다. 이러한 유형의 연결은 다음에서 확인할 수 있습니다.위의 첫 번째 다이어그램 .
온프레미스 데이터 센터에서 VPC로 인터넷을 통해 보다 안전한 연결을 원하는 경우, 계층화 활성화 마법사에서 AWS PrivateLink 연결을 선택하는 옵션이 있습니다. 개인 IP 주소를 사용하는 VPC 엔드포인트 인터페이스를 통해 온프레미스 시스템에 연결하기 위해 VPN이나 AWS Direct Connect를 사용하려는 경우 필요합니다. 이 유형의 연결은 다음에 표시됩니다.위의 두 번째 다이어그램 .
-
Amazon VPC 콘솔이나 명령줄을 사용하여 인터페이스 엔드포인트 구성을 만듭니다. "Amazon S3에 AWS PrivateLink를 사용하는 방법에 대한 자세한 내용을 확인하세요." .
-
에이전트와 연결된 보안 그룹 구성을 수정합니다. 정책을 "전체 액세스"에서 "사용자 지정"으로 변경해야 합니다.필요한 S3 에이전트 권한을 추가합니다. 앞서 보여준 것처럼.
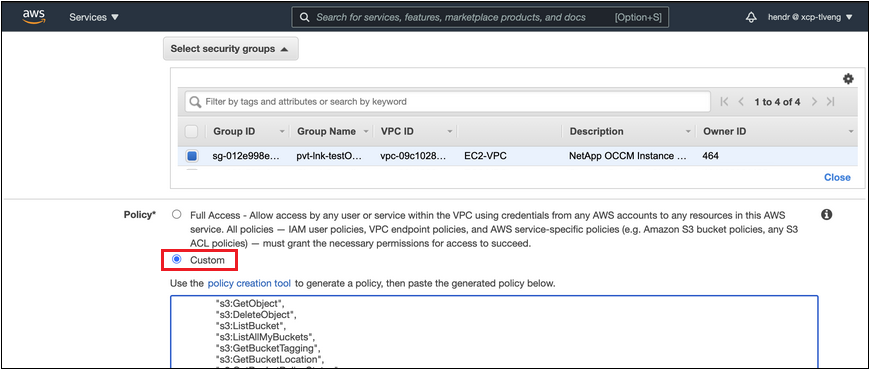
개인 엔드포인트와 통신하기 위해 포트 80(HTTP)을 사용한다면 준비가 완료된 것입니다. 이제 클러스터에서 클라우드 티어링을 활성화할 수 있습니다.
개인 엔드포인트와 통신하기 위해 포트 443(HTTPS)을 사용하는 경우 다음 4단계에 표시된 대로 VPC S3 엔드포인트에서 인증서를 복사하여 ONTAP 클러스터에 추가해야 합니다.
-
AWS 콘솔에서 엔드포인트의 DNS 이름을 얻습니다.
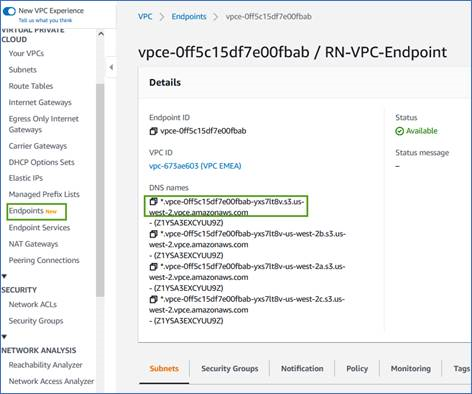
-
VPC S3 엔드포인트에서 인증서를 가져옵니다. 당신은 이것을 이렇게 합니다 "에이전트를 호스팅하는 VM에 로그인" 다음 명령을 실행합니다. 엔드포인트의 DNS 이름을 입력할 때 "*"를 "bucket"으로 바꿔서 처음에 추가합니다.
[ec2-user@ip-10-160-4-68 ~]$ openssl s_client -connect bucket.vpce-0ff5c15df7e00fbab-yxs7lt8v.s3.us-west-2.vpce.amazonaws.com:443 -showcerts -
이 명령의 출력에서 S3 인증서에 대한 데이터를 복사합니다(BEGIN / END CERTIFICATE 태그를 포함하여 그 사이의 모든 데이터).
Certificate chain 0 s:/CN=s3.us-west-2.amazonaws.com` i:/C=US/O=Amazon/OU=Server CA 1B/CN=Amazon -----BEGIN CERTIFICATE----- MIIM6zCCC9OgAwIBAgIQA7MGJ4FaDBR8uL0KR3oltTANBgkqhkiG9w0BAQsFADBG … … GqvbOz/oO2NWLLFCqI+xmkLcMiPrZy+/6Af+HH2mLCM4EsI2b+IpBmPkriWnnxo= -----END CERTIFICATE----- -
ONTAP 클러스터 CLI에 로그인하고 다음 명령을 사용하여 복사한 인증서를 적용합니다(사용자의 스토리지 VM 이름으로 대체).
cluster1::> security certificate install -vserver <svm_name> -type server-ca Please enter Certificate: Press <Enter> when done
첫 번째 클러스터에서 비활성 데이터를 Amazon S3로 계층화합니다.
AWS 환경을 준비한 후 첫 번째 클러스터에서 비활성 데이터의 계층화를 시작합니다.
-
필수 S3 권한이 있는 IAM 사용자를 위한 AWS 액세스 키입니다.
-
온프레미스 ONTAP 시스템을 선택하세요.
-
오른쪽 패널에서 클라우드 티어링에 대해 *활성화*를 클릭합니다.
Amazon S3 계층화 대상이 시스템 페이지에 시스템으로 존재하는 경우 클러스터를 시스템으로 끌어서 놓으면 설정 마법사가 시작됩니다.
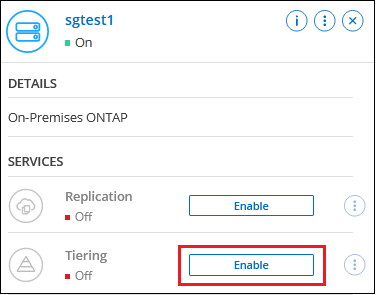
-
개체 저장소 이름 정의: 이 개체 저장소의 이름을 입력합니다. 이 클러스터에서 집계와 함께 사용할 수 있는 다른 개체 저장소와 고유해야 합니다.
-
공급자 선택: *Amazon Web Services*를 선택하고 *계속*을 선택합니다.
-
계층화 설정 페이지에서 섹션을 완료하세요.
-
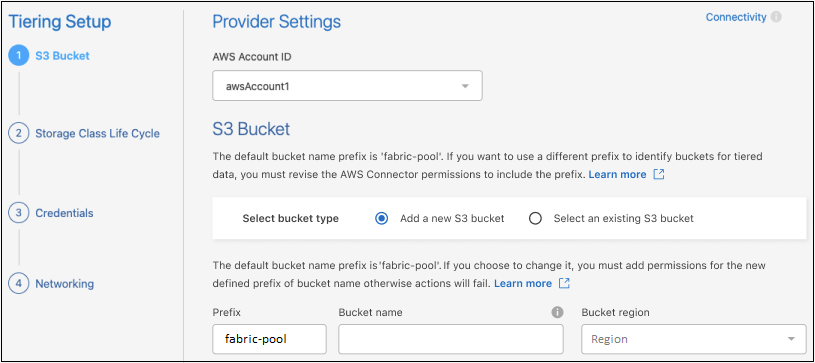
S3 버킷: 새로운 S3 버킷을 추가하거나 기존 S3 버킷을 선택하고, 버킷 지역을 선택한 후 *계속*을 선택합니다.
온프레미스 에이전트를 사용하는 경우 기존 S3 버킷이나 새로 생성될 S3 버킷에 대한 액세스를 제공하는 AWS 계정 ID를 입력해야 합니다.
fabric-pool 접두사가 기본적으로 사용되는 이유는 에이전트의 IAM 정책에 따라 인스턴스가 해당 접두사로 명명된 버킷에서 S3 작업을 수행할 수 있기 때문입니다. 예를 들어, S3 버킷의 이름을 _fabric-pool-AFF1_로 지정할 수 있습니다. 여기서 AFF1은 클러스터의 이름입니다. 계층화에 사용되는 버킷의 접두사도 정의할 수 있습니다. 보다S3 권한 설정 사용하려는 사용자 정의 접두사를 인식하는 AWS 권한이 있는지 확인하세요.
-
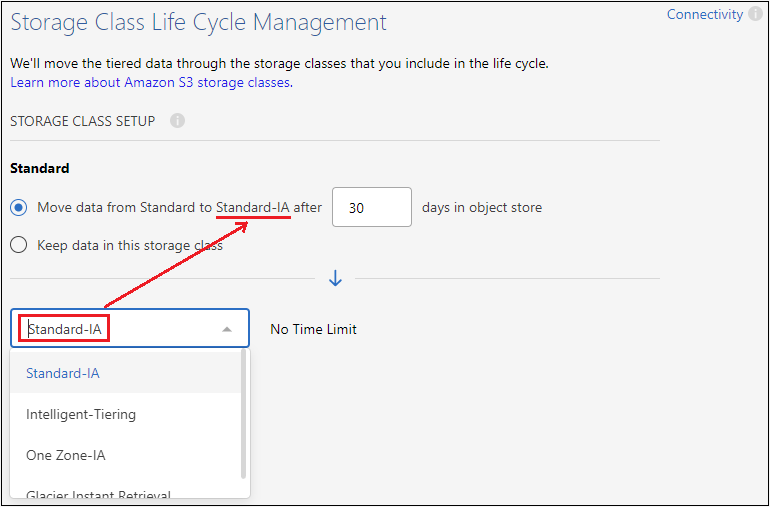
스토리지 클래스: 클라우드 계층화는 계층화된 데이터의 수명 주기 전환을 관리합니다. 데이터는 Standard 클래스에서 시작하지만, 특정 일수가 지나면 데이터에 다른 저장 클래스를 적용하는 규칙을 만들 수 있습니다.
계층화된 데이터를 전환할 S3 스토리지 클래스를 선택하고, 데이터가 해당 클래스에 할당되기 전까지의 일수를 선택한 후 *계속*을 선택합니다. 예를 들어, 아래 스크린샷은 계층화된 데이터가 개체 저장소에서 45일이 지난 후 Standard 클래스에서 Standard-IA 클래스로 할당되는 것을 보여줍니다.
*이 저장소 클래스에 데이터 유지*를 선택하면 데이터는 표준 저장소 클래스에 유지되며 규칙은 적용되지 않습니다. "지원되는 스토리지 클래스 보기" .
선택한 버킷의 모든 객체에 수명 주기 규칙이 적용됩니다.
-
자격 증명: 필요한 S3 권한이 있는 IAM 사용자의 액세스 키 ID와 비밀 키를 입력하고 *계속*을 선택합니다.
IAM 사용자는 S3 버킷 페이지에서 선택하거나 생성한 버킷과 동일한 AWS 계정에 있어야 합니다.
-
네트워킹: 네트워킹 세부 정보를 입력하고 *계속*을 선택하세요.
계층화하려는 볼륨이 있는 ONTAP 클러스터의 IP 공간을 선택합니다. 이 IP공간의 클러스터 간 LIF는 클라우드 공급자의 개체 스토리지에 연결할 수 있도록 아웃바운드 인터넷 액세스가 가능해야 합니다.
선택적으로, 이전에 구성한 AWS PrivateLink를 사용할지 여부를 선택합니다. 위의 설정 정보를 참조하세요. 엔드포인트 구성을 안내하는 대화 상자가 표시됩니다.
"최대 전송 속도"를 정의하여 비활성 데이터를 개체 스토리지에 업로드하는 데 사용할 수 있는 네트워크 대역폭을 설정할 수도 있습니다. 제한됨 라디오 버튼을 선택하고 사용 가능한 최대 대역폭을 입력하거나, *무제한*을 선택하여 제한이 없음을 나타냅니다.
-
-
계층 볼륨 페이지에서 계층화를 구성하려는 볼륨을 선택하고 계층화 정책 페이지를 시작합니다.
-
모든 볼륨을 선택하려면 제목 행의 상자를 선택하십시오.
 )을 클릭하고 *볼륨 구성*을 선택합니다.
)을 클릭하고 *볼륨 구성*을 선택합니다. -
여러 볼륨을 선택하려면 각 볼륨의 상자를 선택하십시오.
 )을 클릭하고 *볼륨 구성*을 선택합니다.
)을 클릭하고 *볼륨 구성*을 선택합니다. -
단일 볼륨을 선택하려면 행을 선택하세요(또는
 볼륨에 대한 아이콘)입니다.
볼륨에 대한 아이콘)입니다.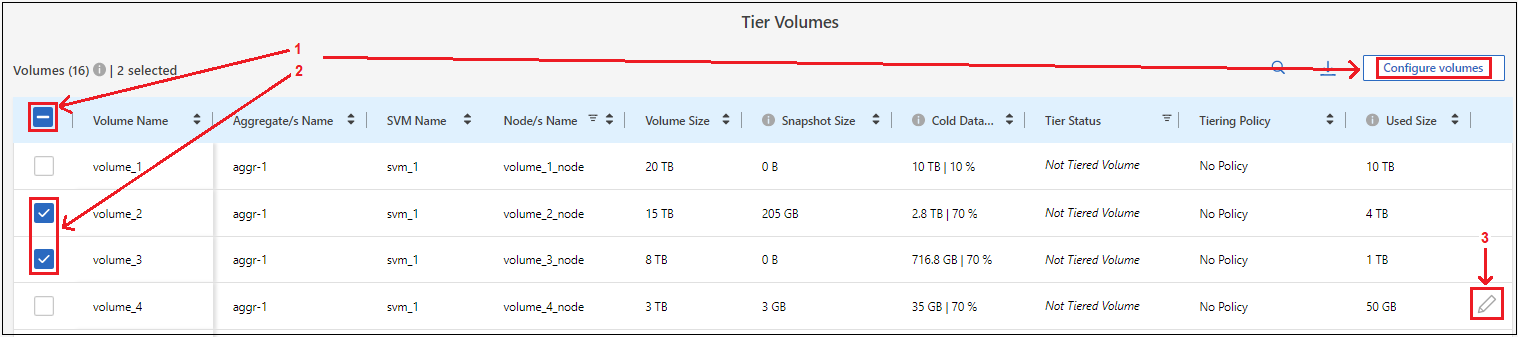
-
-
계층화 정책 대화 상자에서 계층화 정책을 선택하고, 선택적으로 선택한 볼륨에 대한 냉각 일수를 조정하고, *적용*을 선택합니다.
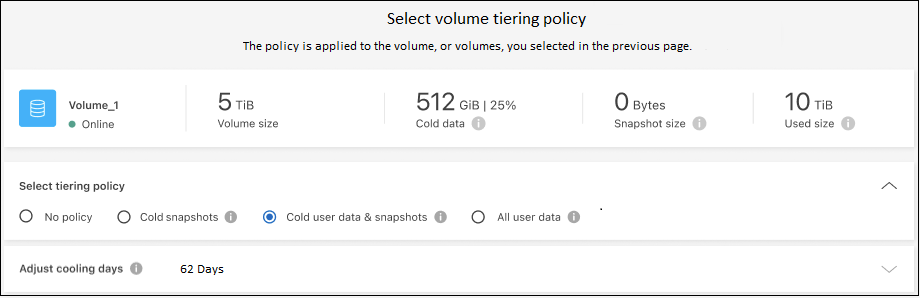
클러스터의 볼륨에서 S3 개체 스토리지로 데이터 계층화를 성공적으로 설정했습니다.
클러스터의 활성 및 비활성 데이터에 대한 정보를 검토할 수 있습니다. "계층화 설정 관리에 대해 자세히 알아보세요" .
클러스터의 특정 집계에서 다른 개체 저장소로 데이터를 계층화하려는 경우 추가 개체 저장소를 만들 수도 있습니다. 또는 계층화된 데이터가 추가 개체 저장소에 복제되는 FabricPool Mirroring을 사용할 계획인 경우입니다. "객체 저장소 관리에 대해 자세히 알아보세요" .