

Dados em camadas de clusters ONTAP locais para o Amazon S3 no NetApp Cloud Tiering
 Sugerir alterações
Sugerir alterações
Libere espaço em seus clusters ONTAP locais hierarquizando dados inativos no Amazon S3 no NetApp Cloud Tiering.
Início rápido
Comece rapidamente seguindo estes passos. Detalhes de cada etapa são fornecidos nas seções a seguir deste tópico.
 Identifique o método de configuração que você usará
Identifique o método de configuração que você usaráEscolha se você conectará seu cluster ONTAP local diretamente ao AWS S3 pela Internet pública ou se usará uma VPN ou o AWS Direct Connect e roteará o tráfego por meio de uma interface de endpoint VPC privada para o AWS S3.
 Prepare seu agente de console
Prepare seu agente de consoleSe você já tiver o agente do Console implantado na sua VPC da AWS ou em suas instalações, está tudo pronto. Caso contrário, você precisará criar o agente para hierarquizar os dados do ONTAP no armazenamento AWS S3. Você também precisará personalizar as configurações de rede do agente para que ele possa se conectar ao AWS S3.
 Prepare seu cluster ONTAP local
Prepare seu cluster ONTAP localDescubra seu cluster ONTAP no NetApp Console, verifique se o cluster atende aos requisitos mínimos e personalize as configurações de rede para que o cluster possa se conectar ao AWS S3.
 Prepare o Amazon S3 como seu destino de hierarquização
Prepare o Amazon S3 como seu destino de hierarquizaçãoConfigure permissões para o agente criar e gerenciar o bucket S3. Você também precisará configurar permissões para o cluster ONTAP local para que ele possa ler e gravar dados no bucket S3.
 Habilitar o Cloud Tiering no sistema
Habilitar o Cloud Tiering no sistemaSelecione um sistema local, selecione Ativar para o serviço Cloud Tiering e siga as instruções para hierarquizar dados no Amazon S3.
 Configurar licenciamento
Configurar licenciamentoApós o término do seu teste gratuito, pague pelo Cloud Tiering por meio de uma assinatura pré-paga, uma licença BYOL do ONTAP Cloud Tiering ou uma combinação de ambos:
-
Para assinar no AWS Marketplace, "vá para a oferta do Marketplace" , selecione Inscrever-se e siga as instruções.
-
Para pagar usando uma licença BYOL do Cloud Tiering, envie um e-mail para:ng-cloud-tiering@netapp.com?subject=Licensing[entre em contato conosco se precisar comprar uma] e, em seguida,"adicione-o ao NetApp Console" .
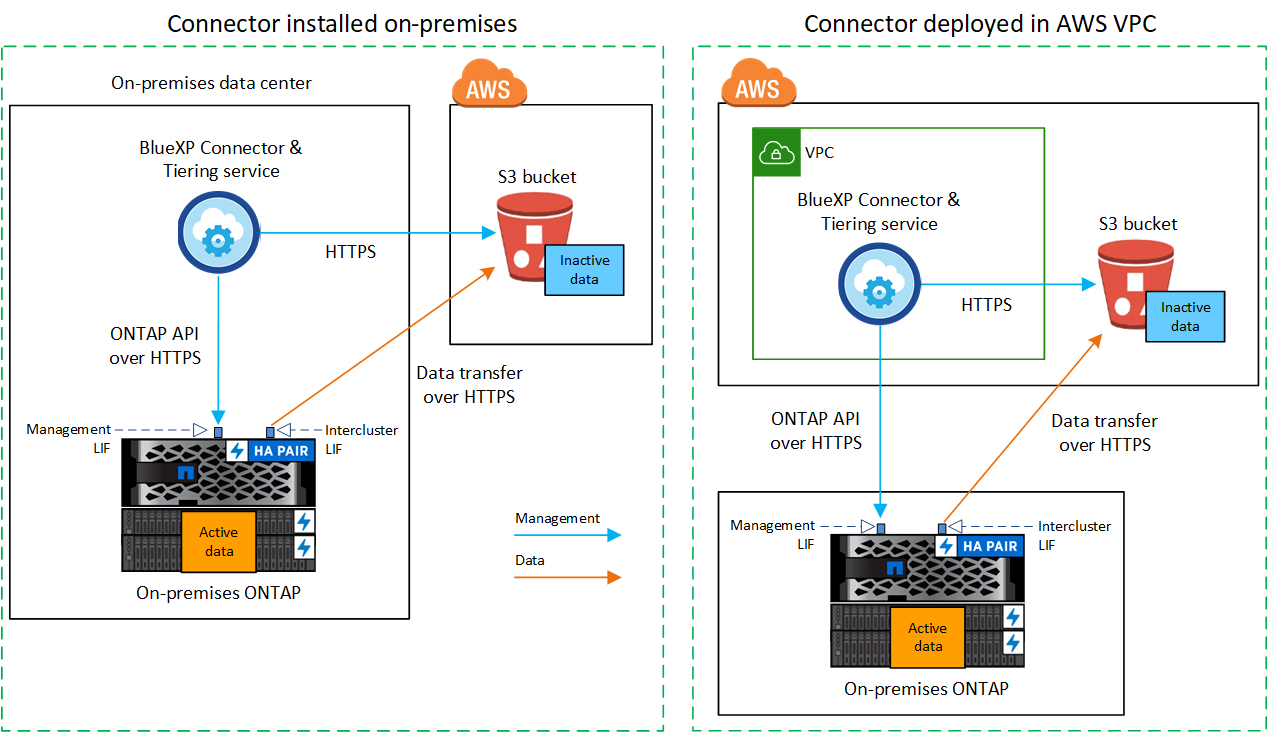
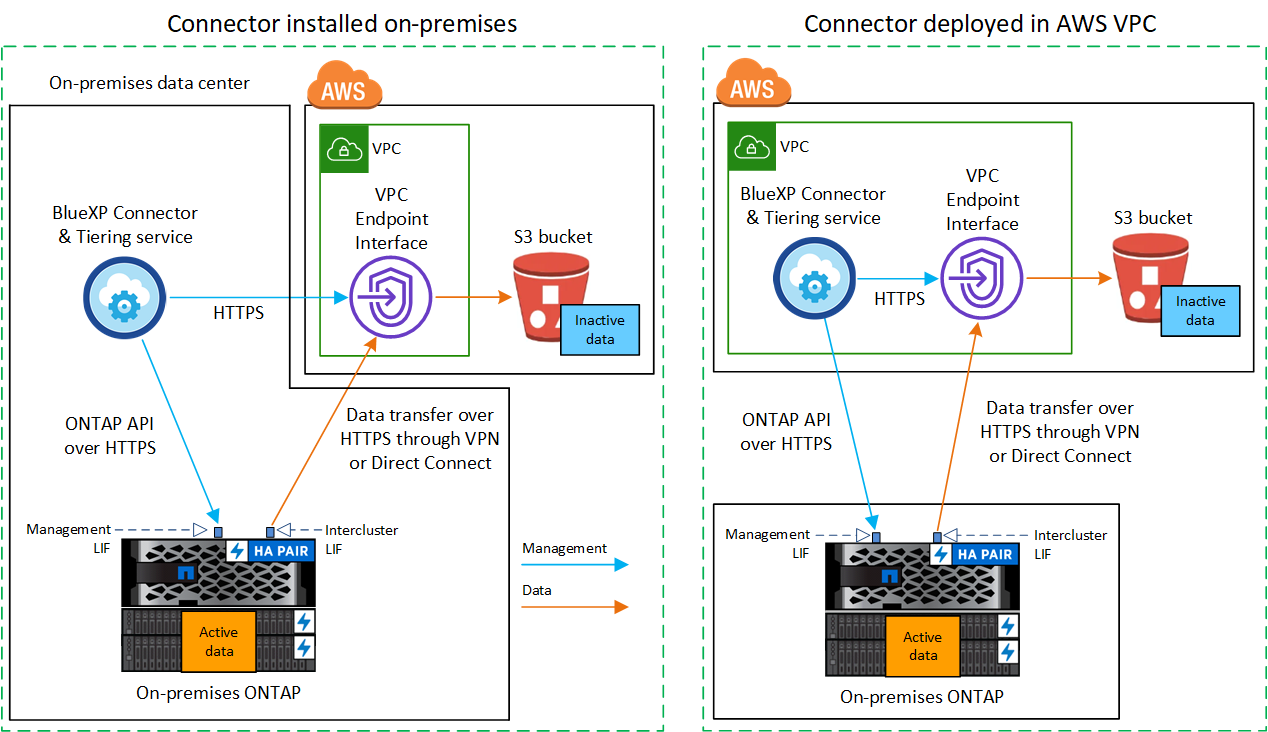
Diagramas de rede para opções de conexão
Há dois métodos de conexão que você pode usar ao configurar a hierarquização de sistemas ONTAP locais para o AWS S3.
-
Conexão pública - Conecte diretamente o sistema ONTAP ao AWS S3 usando um endpoint S3 público.
-
Conexão privada - Use uma VPN ou AWS Direct Connect e roteie o tráfego por meio de uma interface de endpoint VPC que usa um endereço IP privado.
O diagrama a seguir mostra o método conexão pública e as conexões que você precisa preparar entre os componentes. Você pode usar o agente do Console que você instalou em suas instalações ou um agente que você implantou na VPC da AWS.
O diagrama a seguir mostra o método de conexão privada e as conexões que você precisa preparar entre os componentes. Você pode usar o agente do Console que você instalou em suas instalações ou um agente que você implantou na VPC da AWS.

|
A comunicação entre um agente e o S3 é somente para configuração de armazenamento de objetos. |
Prepare seu agente de console
O agente habilita recursos de hierarquização do NetApp Console. É necessário um agente para hierarquizar seus dados ONTAP inativos.
Criar ou trocar agentes
Se você já tiver um agente implantado em sua VPC da AWS ou em suas instalações, está tudo pronto. Caso contrário, você precisará criar um agente em qualquer um desses locais para hierarquizar os dados do ONTAP no armazenamento AWS S3. Você não pode usar um agente implantado em outro provedor de nuvem.
Requisitos de rede do agente
-
Certifique-se de que a rede onde o agente está instalado habilite as seguintes conexões:
-
Uma conexão HTTPS pela porta 443 para o serviço Cloud Tiering e para o seu armazenamento de objetos S3("veja a lista de pontos de extremidade" )
-
Uma conexão HTTPS pela porta 443 para seu LIF de gerenciamento de cluster ONTAP
-
-
"Certifique-se de que o agente tenha permissões para gerenciar o bucket S3"
-
Se você tiver uma conexão Direct Connect ou VPN do seu cluster ONTAP para o VPC e quiser que a comunicação entre o agente e o S3 permaneça na sua rede interna da AWS (uma conexão privada), será necessário habilitar uma interface VPC Endpoint para o S3.Veja como configurar uma interface de endpoint VPC.
Prepare seu cluster ONTAP
Seus clusters ONTAP devem atender aos seguintes requisitos ao hierarquizar dados no Amazon S3.
Requisitos do ONTAP
- Plataformas ONTAP suportadas
-
-
Ao usar o ONTAP 9.8 e posterior: você pode hierarquizar dados de sistemas AFF ou sistemas FAS com agregados totalmente SSD ou totalmente HDD.
-
Ao usar o ONTAP 9.7 e versões anteriores: você pode hierarquizar dados de sistemas AFF ou sistemas FAS com agregados totalmente SSD.
-
- Versões ONTAP suportadas
-
-
ONTAP 9.2 ou posterior
-
ONTAP 9.7 ou posterior é necessário se você planeja usar uma conexão AWS PrivateLink para armazenamento de objetos
-
- Volumes e agregados suportados
-
O número total de volumes que o Cloud Tiering pode hierarquizar pode ser menor que o número de volumes no seu sistema ONTAP . Isso ocorre porque os volumes não podem ser hierarquizados a partir de alguns agregados. Consulte a documentação do ONTAP para "funcionalidade ou recursos não suportados pelo FabricPool" .
|
|
O Cloud Tiering oferece suporte a volumes FlexGroup a partir do ONTAP 9.5. A configuração funciona da mesma forma que qualquer outro volume. |
Requisitos de rede do cluster
-
O cluster requer uma conexão HTTPS de entrada do agente do Console para o LIF de gerenciamento do cluster.
Não é necessária uma conexão entre o cluster e o Cloud Tiering.
-
Um LIF intercluster é necessário em cada nó ONTAP que hospeda os volumes que você deseja hierarquizar. Esses LIFs intercluster devem ser capazes de acessar o armazenamento de objetos.
O cluster inicia uma conexão HTTPS de saída pela porta 443 dos LIFs entre clusters para o armazenamento do Amazon S3 para operações de divisão em camadas. O ONTAP lê e grava dados de e para o armazenamento de objetos — o armazenamento de objetos nunca inicia, ele apenas responde.
-
Os LIFs intercluster devem ser associados ao IPspace que o ONTAP deve usar para se conectar ao armazenamento de objetos. "Saiba mais sobre IPspaces" .
Ao configurar o Cloud Tiering, você será solicitado a informar o IPspace a ser usado. Você deve escolher o IPspace ao qual esses LIFs estão associados. Pode ser o IPspace "padrão" ou um IPspace personalizado que você criou.
Se você estiver usando um IPspace diferente do "Padrão", talvez seja necessário criar uma rota estática para obter acesso ao armazenamento de objetos.
Todos os LIFs intercluster dentro do IPspace devem ter acesso ao armazenamento de objetos. Se você não puder configurar isso para o IPspace atual, será necessário criar um IPspace dedicado onde todos os LIFs intercluster tenham acesso ao armazenamento de objetos.
-
Se você estiver usando um endpoint de interface VPC privada na AWS para a conexão S3, para que o HTTPS/443 seja usado, você precisará carregar o certificado de endpoint S3 no cluster ONTAP .Veja como configurar uma interface de endpoint VPC e carregar o certificado S3.
-
Certifique-se de que seu cluster ONTAP tenha permissões para acessar o bucket S3.
Descubra seu cluster ONTAP no NetApp Console
Você precisa descobrir seu cluster ONTAP local no NetApp Console antes de começar a hierarquizar dados frios no armazenamento de objetos. Você precisará saber o endereço IP de gerenciamento do cluster e a senha da conta de usuário administrador para adicionar o cluster.
Prepare seu ambiente AWS
Ao configurar a hierarquização de dados para um novo cluster, você será perguntado se deseja que o serviço crie um bucket S3 ou se deseja selecionar um bucket S3 existente na conta da AWS onde o agente está configurado. A conta da AWS deve ter permissões e uma chave de acesso que você pode inserir no Cloud Tiering. O cluster ONTAP usa a chave de acesso para hierarquizar dados dentro e fora do S3.
Por padrão, o Cloud tiering cria o bucket para você. Se quiser usar seu próprio bucket, você pode criar um antes de iniciar o assistente de ativação de camadas e então selecionar esse bucket no assistente. "Veja como criar buckets S3 no NetApp Console" . O bucket deve ser usado exclusivamente para armazenar dados inativos dos seus volumes. Ele não pode ser usado para nenhuma outra finalidade. O bucket S3 deve estar em um"região que oferece suporte ao Cloud Tiering" .
|
|
Se você estiver planejando configurar o Cloud Tiering para usar uma classe de armazenamento de custo mais baixo para onde seus dados em camadas farão a transição após um determinado número de dias, não selecione nenhuma regra de ciclo de vida ao configurar o bucket na sua conta da AWS. O Cloud Tiering gerencia as transições do ciclo de vida. |
Configurar permissões S3
Você precisará configurar dois conjuntos de permissões:
-
Permissões para o agente para que ele possa criar e gerenciar o bucket S3.
-
Permissões para o cluster ONTAP local para que ele possa ler e gravar dados no bucket S3.
-
Permissões do agente do console:
-
Confirme que "essas permissões S3" fazem parte da função do IAM que fornece permissões ao agente. Eles deveriam ter sido incluídos por padrão quando você implantou o agente pela primeira vez. Caso contrário, você precisará adicionar quaisquer permissões ausentes. Veja o "Documentação da AWS: Editando políticas do IAM" para obter instruções.
-
O bucket padrão criado pelo Cloud Tiering tem o prefixo "fabric-pool". Se quiser usar um prefixo diferente para seu bucket, você precisará personalizar as permissões com o nome que deseja usar. Nas permissões do S3 você verá uma linha
"Resource": ["arn:aws:s3:::fabric-pool*"]. Você precisará alterar "fabric-pool" para o prefixo que deseja usar. Por exemplo, se você quiser usar "tiering-1" como prefixo para seus buckets, você alterará esta linha para"Resource": ["arn:aws:s3:::tiering-1*"].Se quiser usar um prefixo diferente para os buckets que serão usados para clusters adicionais nesta mesma organização do NetApp Console , você poderá adicionar outra linha com o prefixo para outros buckets. Por exemplo:
"Resource": ["arn:aws:s3:::tiering-1*"]
"Resource": ["arn:aws:s3:::tiering-2*"]
Se você estiver criando seu próprio bucket e não usar um prefixo padrão, você deve alterar esta linha para
"Resource": ["arn:aws:s3:::*"]para que qualquer balde seja reconhecido. No entanto, isso pode expor todos os seus buckets em vez daqueles que você projetou para armazenar dados inativos dos seus volumes. -
-
Permissões de cluster:
-
Ao ativar o serviço, o assistente de Hierarquia solicitará que você insira uma chave de acesso e uma chave secreta. Essas credenciais são passadas ao cluster ONTAP para que o ONTAP possa hierarquizar dados no bucket S3. Para isso, você precisará criar um usuário do IAM com as seguintes permissões:
"s3:ListAllMyBuckets", "s3:ListBucket", "s3:GetBucketLocation", "s3:GetObject", "s3:PutObject", "s3:DeleteObject"Veja o "Documentação da AWS: Criando uma função para delegar permissões a um usuário do IAM" para mais detalhes.
-
-
Crie ou localize a chave de acesso.
O Cloud Tiering passa a chave de acesso para o cluster ONTAP . As credenciais não são armazenadas no serviço Cloud Tiering.
Configure seu sistema para uma conexão privada usando uma interface de endpoint VPC
Se você planeja usar uma conexão de internet pública padrão, todas as permissões são definidas pelo agente e não há mais nada que você precise fazer. Este tipo de conexão é mostrado naprimeiro diagrama acima .
Se você quiser ter uma conexão mais segura pela internet do seu data center local para a VPC, há uma opção para selecionar uma conexão AWS PrivateLink no assistente de ativação de camadas. É necessário se você planeja usar uma VPN ou AWS Direct Connect para conectar seu sistema local por meio de uma interface de endpoint VPC que usa um endereço IP privado. Este tipo de conexão é mostrado nasegundo diagrama acima .
-
Crie uma configuração de endpoint de interface usando o Amazon VPC Console ou a linha de comando. "Veja detalhes sobre o uso do AWS PrivateLink para Amazon S3" .
-
Modifique a configuração do grupo de segurança associado ao agente. Você deve alterar a política para "Personalizada" (de "Acesso Total") e deveadicione as permissões necessárias do agente S3 como mostrado anteriormente.
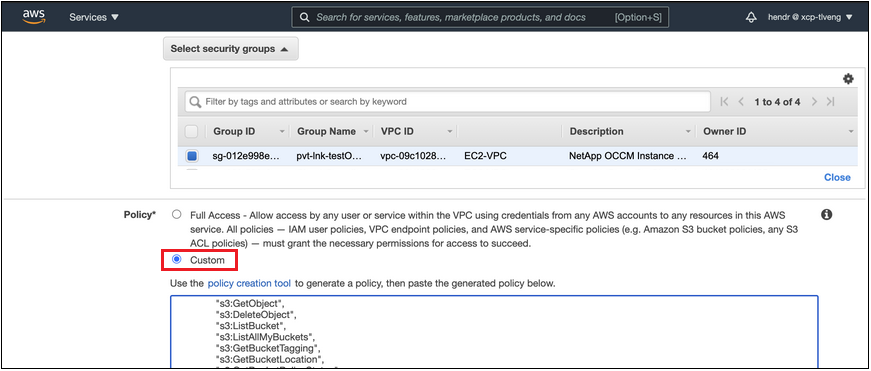
Se você estiver usando a porta 80 (HTTP) para comunicação com o ponto de extremidade privado, está tudo pronto. Agora você pode habilitar o Cloud Tiering no cluster.
Se estiver usando a porta 443 (HTTPS) para comunicação com o endpoint privado, você deverá copiar o certificado do endpoint VPC S3 e adicioná-lo ao seu cluster ONTAP , conforme mostrado nas próximas 4 etapas.
-
Obtenha o nome DNS do endpoint no Console da AWS.
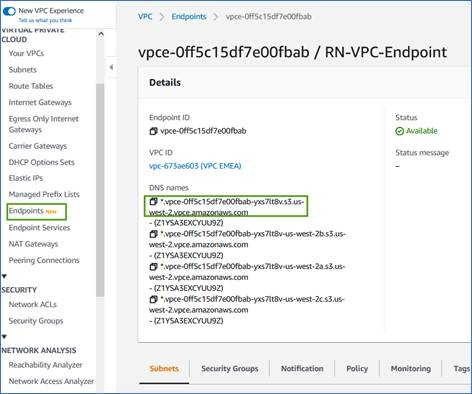
-
Obtenha o certificado do endpoint S3 da VPC. Você faz isso por "efetuar login na VM que hospeda o agente" e executando o seguinte comando. Ao inserir o nome DNS do endpoint, adicione “bucket” no início, substituindo o “*”:
[ec2-user@ip-10-160-4-68 ~]$ openssl s_client -connect bucket.vpce-0ff5c15df7e00fbab-yxs7lt8v.s3.us-west-2.vpce.amazonaws.com:443 -showcerts -
Da saída deste comando, copie os dados do certificado S3 (todos os dados entre, e incluindo, as tags BEGIN / END CERTIFICATE):
Certificate chain 0 s:/CN=s3.us-west-2.amazonaws.com` i:/C=US/O=Amazon/OU=Server CA 1B/CN=Amazon -----BEGIN CERTIFICATE----- MIIM6zCCC9OgAwIBAgIQA7MGJ4FaDBR8uL0KR3oltTANBgkqhkiG9w0BAQsFADBG … … GqvbOz/oO2NWLLFCqI+xmkLcMiPrZy+/6Af+HH2mLCM4EsI2b+IpBmPkriWnnxo= -----END CERTIFICATE----- -
Efetue login na CLI do cluster ONTAP e aplique o certificado que você copiou usando o seguinte comando (substitua pelo nome da sua própria VM de armazenamento):
cluster1::> security certificate install -vserver <svm_name> -type server-ca Please enter Certificate: Press <Enter> when done
Dados inativos em camadas do seu primeiro cluster para o Amazon S3
Depois de preparar seu ambiente AWS, comece a hierarquizar dados inativos do seu primeiro cluster.
-
Uma chave de acesso da AWS para um usuário do IAM que tenha as permissões S3 necessárias.
-
Selecione o sistema ONTAP local.
-
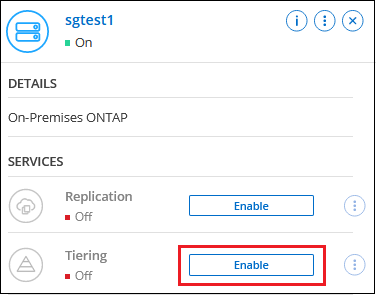
Clique em Ativar para Camadas de Nuvem no painel direito.
Se o destino de camadas do Amazon S3 existir como um sistema na página Sistemas, você poderá arrastar o cluster para o sistema para iniciar o assistente de configuração.
-
Definir nome do armazenamento de objetos: insira um nome para este armazenamento de objetos. Ele deve ser exclusivo de qualquer outro armazenamento de objetos que você possa estar usando com agregados neste cluster.
-
Selecionar provedor: Selecione Amazon Web Services e selecione Continuar.
-
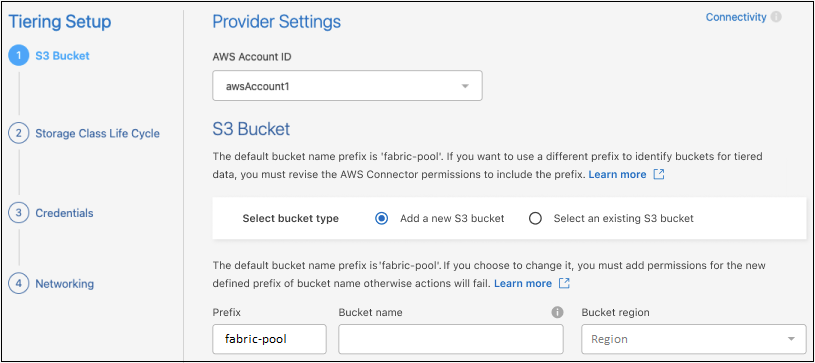
Complete as seções na página Configuração de níveis:
-
S3 Bucket: adicione um novo bucket S3 ou selecione um bucket S3 existente, selecione a região do bucket e selecione Continuar.
Ao usar um agente local, você deve inserir o ID da conta da AWS que fornece acesso ao bucket S3 existente ou ao novo bucket S3 que será criado.
O prefixo fabric-pool é usado por padrão porque a política do IAM para o agente permite que a instância execute ações do S3 em buckets nomeados com esse prefixo exato. Por exemplo, você pode nomear o bucket S3 fabric-pool-AFF1, onde AFF1 é o nome do cluster. Você também pode definir o prefixo para os buckets usados para hierarquização. Verconfigurando permissões S3 para garantir que você tenha permissões da AWS que reconheçam qualquer prefixo personalizado que você planeja usar.
-
Classe de armazenamento: o Cloud Tiering gerencia as transições do ciclo de vida dos seus dados em camadas. Os dados começam na classe Padrão, mas você pode criar uma regra para aplicar uma classe de armazenamento diferente aos dados após um determinado número de dias.
Selecione a classe de armazenamento S3 para a qual você deseja fazer a transição dos dados em camadas e o número de dias antes que os dados sejam atribuídos a essa classe e selecione Continuar. Por exemplo, a captura de tela abaixo mostra que dados em camadas são atribuídos à classe Standard-IA a partir da classe Standard após 45 dias no armazenamento de objetos.
Se você escolher Manter dados nesta classe de armazenamento, os dados permanecerão na classe de armazenamento Padrão e nenhuma regra será aplicada. "Veja as classes de armazenamento suportadas" .
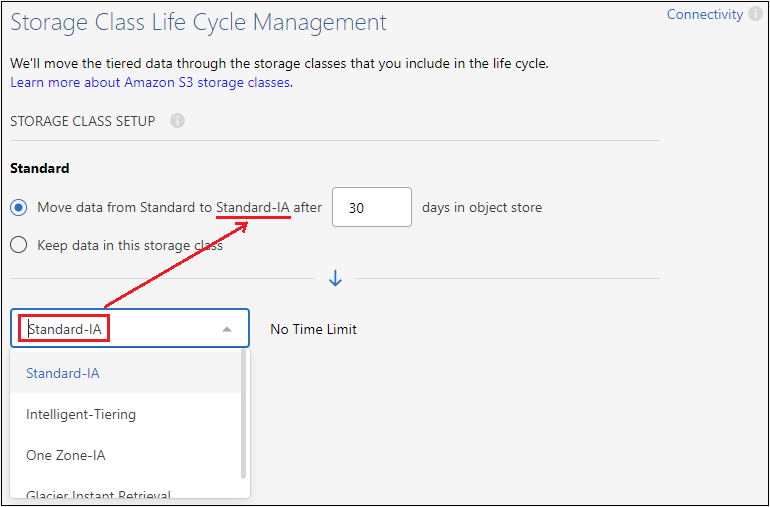
Observe que a regra do ciclo de vida é aplicada a todos os objetos no bucket selecionado.
-
Credenciais: insira o ID da chave de acesso e a chave secreta de um usuário do IAM que tenha as permissões S3 necessárias e selecione Continuar.
O usuário do IAM deve estar na mesma conta da AWS que o bucket que você selecionou ou criou na página S3 Bucket.
-
Rede: Insira os detalhes da rede e selecione Continuar.
Selecione o IPspace no cluster ONTAP onde residem os volumes que você deseja hierarquizar. Os LIFs intercluster para este IPspace devem ter acesso de saída à Internet para que possam se conectar ao armazenamento de objetos do seu provedor de nuvem.
Opcionalmente, escolha se você usará um AWS PrivateLink que você configurou anteriormente. Veja as informações de configuração acima. Uma caixa de diálogo é exibida para ajudar a guiá-lo pela configuração do endpoint.
Você também pode definir a largura de banda de rede disponível para carregar dados inativos no armazenamento de objetos definindo a "Taxa máxima de transferência". Selecione o botão de opção Limitado e insira a largura de banda máxima que pode ser usada ou selecione Ilimitado para indicar que não há limite.
-
-
Na página Volumes em camadas, selecione os volumes para os quais você deseja configurar o escalonamento e inicie a página Política de escalonamento:
-
Para selecionar todos os volumes, marque a caixa na linha de título (
 ) e selecione Configurar volumes.
) e selecione Configurar volumes. -
Para selecionar vários volumes, marque a caixa para cada volume (
 ) e selecione Configurar volumes.
) e selecione Configurar volumes. -
Para selecionar um único volume, selecione a linha (ou
 ícone) para o volume.
ícone) para o volume.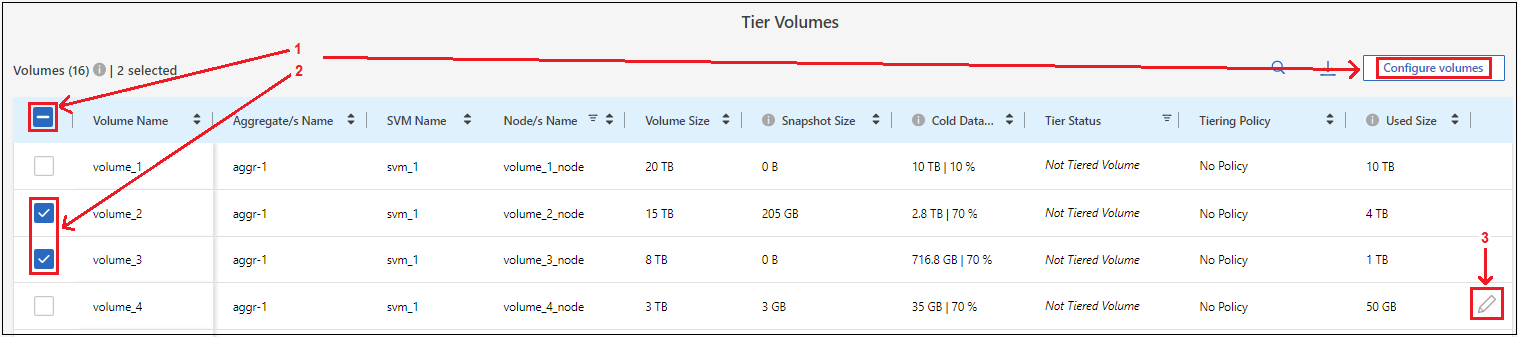
-
-
Na caixa de diálogo Política de níveis, selecione uma política de níveis, ajuste opcionalmente os dias de resfriamento para os volumes selecionados e selecione Aplicar.
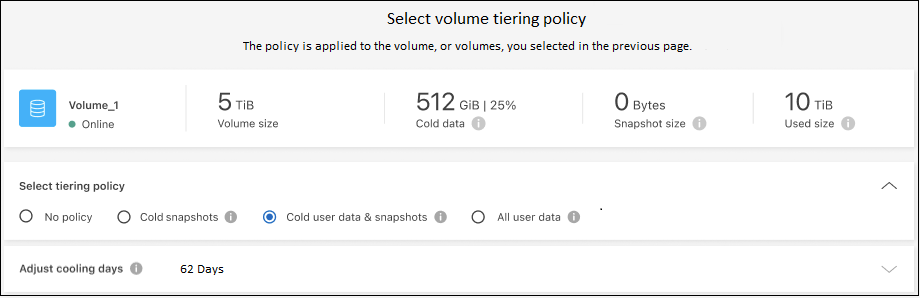
Você configurou com sucesso a hierarquização de dados de volumes no cluster para o armazenamento de objetos S3.
Você pode revisar informações sobre os dados ativos e inativos no cluster. "Saiba mais sobre como gerenciar suas configurações de níveis" .
Você também pode criar armazenamento de objetos adicional nos casos em que deseja hierarquizar dados de determinados agregados em um cluster para diferentes armazenamentos de objetos. Ou se você planeja usar o FabricPool Mirroring, onde seus dados em camadas são replicados para um armazenamento de objetos adicional. "Saiba mais sobre como gerenciar armazenamentos de objetos" .