

Instalação e configuração do operador de monitoramento do Kubernetes
 Sugerir alterações
Sugerir alterações
O Data Infrastructure Insights oferece o Kubernetes Monitoring Operator para a coleção Kubernetes. Navegue até Kubernetes > Coletores > +Kubernetes Collector para implantar um novo operador.
Antes de instalar o Kubernetes Monitoring Operator
Veja o"Pré-requisitos" documentação antes de instalar ou atualizar o Kubernetes Monitoring Operator.
Instalando o Operador de Monitoramento do Kubernetes
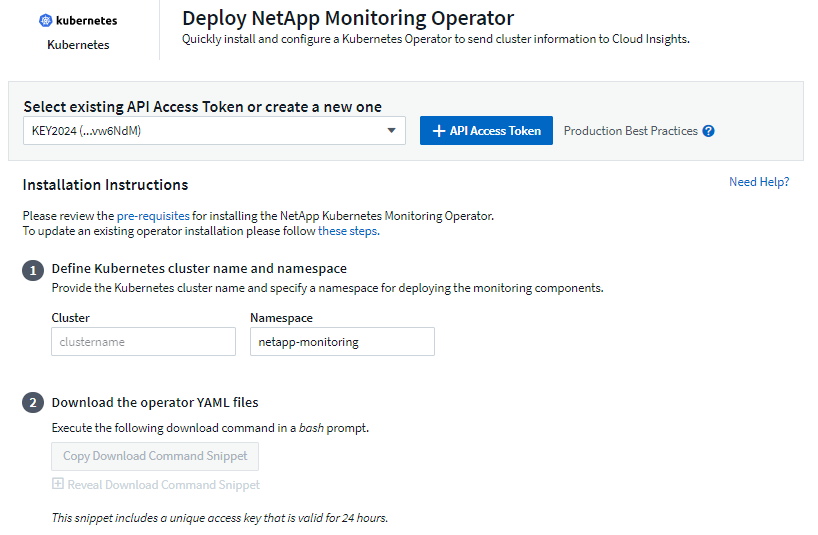
-
Insira um nome de cluster e um namespace exclusivos. Se você éatualizando de um operador Kubernetes anterior, use o mesmo nome de cluster e namespace.
-
Depois de inseri-los, você pode copiar o trecho do Comando de Download para a área de transferência.
-
Cole o snippet em uma janela bash e execute-o. Os arquivos de instalação do Operador serão baixados. Observe que o snippet tem uma chave única e é válido por 24 horas.
-
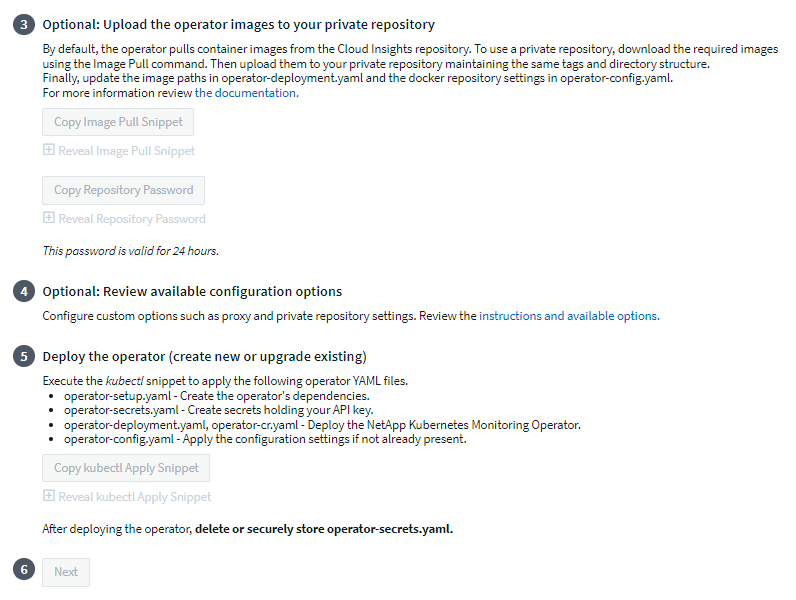
Se você tiver um repositório personalizado ou privado, copie o snippet opcional Image Pull, cole-o em um shell bash e execute-o. Depois que as imagens forem extraídas, copie-as para seu repositório privado. Certifique-se de manter as mesmas tags e estrutura de pastas. Atualize os caminhos em operator-deployment.yaml, bem como as configurações do repositório do Docker em operator-config.yaml.
-
Se desejar, revise as opções de configuração disponíveis, como configurações de proxy ou repositório privado. Você pode ler mais sobre"opções de configuração" .
-
Quando estiver pronto, implante o Operador copiando o snippet kubectl Apply, baixando-o e executando-o.
-
A instalação prossegue automaticamente. Quando estiver concluído, clique no botão Avançar.
-
Quando a instalação estiver concluída, clique no botão Avançar. Certifique-se também de excluir ou armazenar com segurança o arquivo operator-secrets.yaml.
Se você tiver um repositório personalizado, leia sobreusando um repositório docker personalizado/privado .
Componentes de monitoramento do Kubernetes
O Data Infrastructure Insights Kubernetes Monitoring é composto por quatro componentes de monitoramento:
-
Métricas de Cluster
-
Desempenho e mapa de rede (opcional)
-
Registros de eventos (opcional)
-
Análise de Mudanças (opcional)
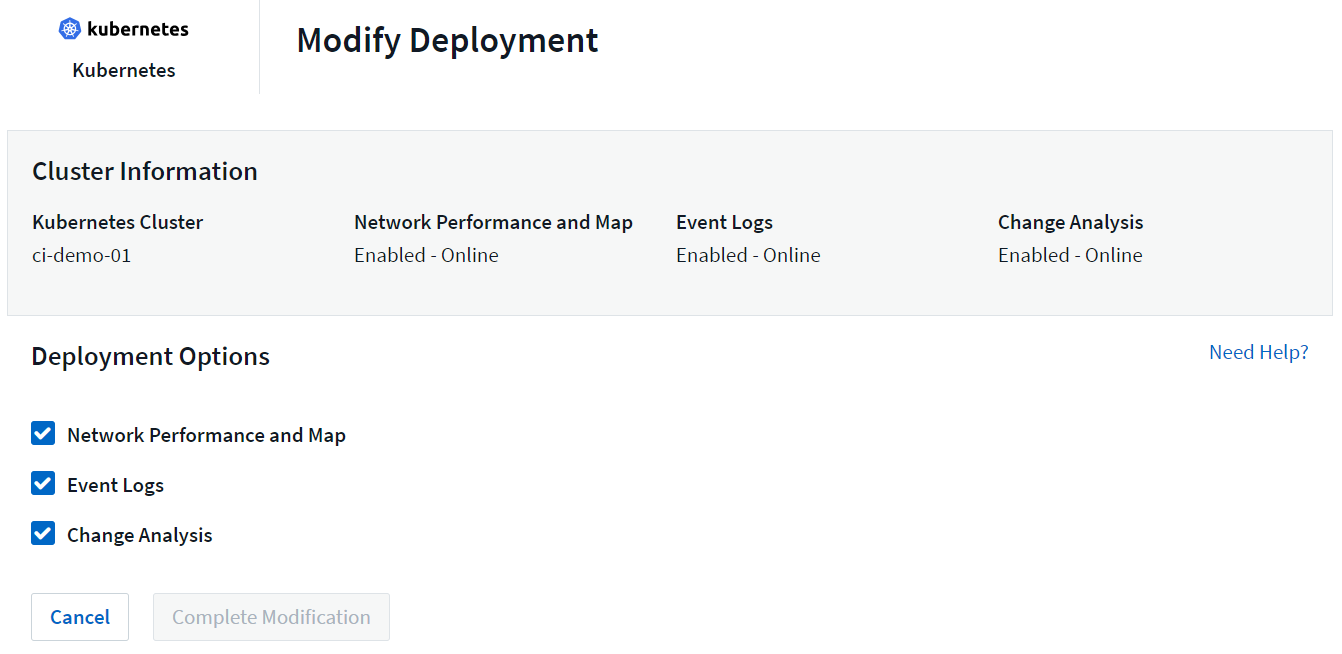
Os componentes opcionais acima são habilitados por padrão para cada coletor do Kubernetes; se você decidir que não precisa de um componente para um coletor específico, poderá desabilitá-lo navegando até Kubernetes > Coletores e selecionando Modificar implantação no menu de "três pontos" do coletor, à direita da tela.
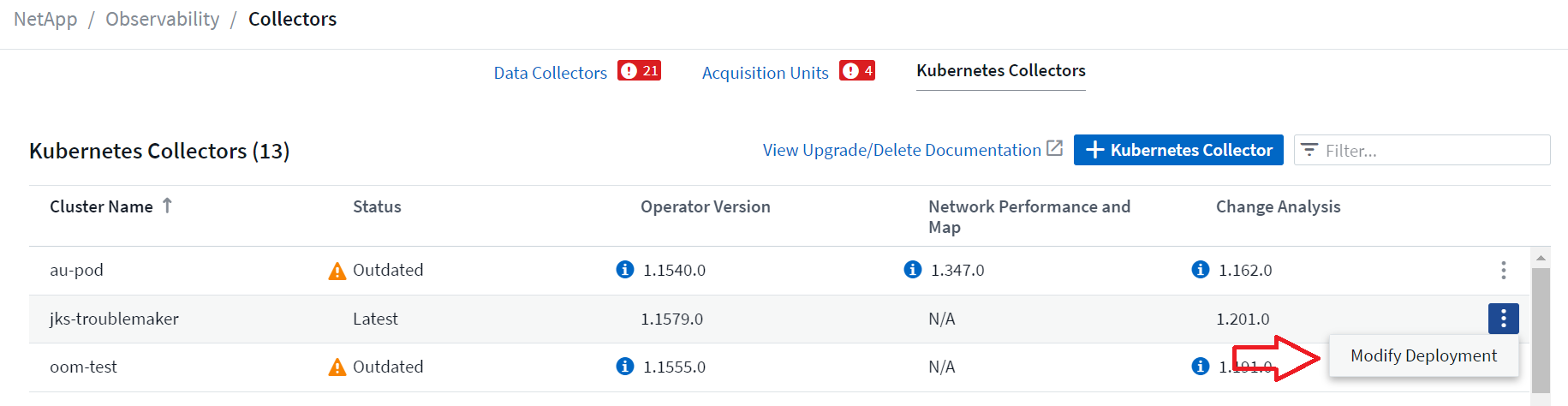
A tela mostra o estado atual de cada componente e permite que você desabilite ou habilite componentes para aquele coletor, conforme necessário.
Atualizando para o mais recente Kubernetes Monitoring Operator
Atualizações de botão DII
Você pode atualizar o Kubernetes Monitoring Operator por meio da página DII Kubernetes Collectors. Clique no menu ao lado do cluster que você gostaria de atualizar e selecione Atualizar. O operador verificará as assinaturas de imagem, fará um snapshot da sua instalação atual e realizará a atualização. Em poucos minutos, você verá o progresso do status do operador, passando de Atualização em andamento para a mais recente. Se você encontrar um erro, pode selecionar o status Erro para obter mais detalhes e consultar a tabela de solução de problemas de atualizações por botão abaixo.

|
As atualizações por botão não estão disponíveis para versões do operador anteriores à 1.2057.0. Siga as instruções de atualização manual abaixo para atualizar para a versão mais recente. Após essa atualização, as atualizações futuras poderão ser realizadas usando o recurso de atualização por botão. |
Atualizações por botão com repositórios privados
Se o seu operador estiver configurado para usar um repositório privado, certifique-se de que todas as imagens necessárias para executar o operador e suas assinaturas estejam disponíveis no seu repositório. Se você encontrar um erro durante o processo de atualização de imagens ausentes, basta adicioná-las ao seu repositório e tentar atualizar novamente. Para carregar as assinaturas de imagem no seu repositório, use a ferramenta cosign da seguinte forma, certificando-se de carregar as assinaturas de todas as imagens especificadas em 3 Opcional: Carregue as imagens do operador no seu repositório privado > Image Pull Snippet
cosign copy example.com/src:v1 example.com/dest:v1 #Example cosign copy <DII container registry>/netapp-monitoring:<image version> <private repository>/netapp-monitoring:<image version>
Revertendo para uma versão anterior
Se você atualizou usando o recurso de atualizações por botão e encontrar alguma dificuldade com a versão atual do operador dentro de sete dias após a atualização, você pode fazer o downgrade para a versão anterior usando o snapshot criado durante o processo de atualização. Clique no menu ao lado do cluster que você gostaria de reverter e selecione Reverter.
Atualizações manuais
Determine se existe uma AgentConfiguration com o operador existente (se o seu namespace não for o padrão netapp-monitoring, substitua pelo namespace apropriado):
kubectl -n netapp-monitoring get agentconfiguration netapp-ci-monitoring-configuration Se uma _AgentConfiguration_ existir:
-
Instalaro operador mais recente sobre o operador existente.
-
Certifique-se de que você estápuxando as últimas imagens de contêiner se você estiver usando um repositório personalizado.
-
Se a AgentConfiguration não existir:
-
Anote o nome do seu cluster conforme reconhecido pelo Data Infrastructure Insights (se o seu namespace não for o netapp-monitoring padrão, substitua pelo namespace apropriado):
kubectl -n netapp-monitoring get agent -o jsonpath='{.items[0].spec.cluster-name}' * Crie um backup do Operador existente (se o seu namespace não for o netapp-monitoring padrão, substitua pelo namespace apropriado):kubectl -n netapp-monitoring get agent -o yaml > agent_backup.yaml * <<to-remove-the-kubernetes-monitoring-operator,Desinstalar>>o Operador existente. * <<installing-the-kubernetes-monitoring-operator,Instalar>>o mais recente Operador.
-
Use o mesmo nome de cluster.
-
Após baixar os arquivos YAML mais recentes do Operator, transfira quaisquer personalizações encontradas em agent_backup.yaml para o operator-config.yaml baixado antes de implantar.
-
Certifique-se de que você estápuxando as últimas imagens de contêiner se você estiver usando um repositório personalizado.
-
Parando e iniciando o operador de monitoramento do Kubernetes
Para interromper o Operador de Monitoramento do Kubernetes:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=0 Para iniciar o Operador de Monitoramento do Kubernetes:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=1
Desinstalando
Para remover o Operador de Monitoramento do Kubernetes
Observe que o namespace padrão para o Kubernetes Monitoring Operator é "netapp-monitoring". Se você tiver definido seu próprio namespace, substitua-o nestes e em todos os comandos e arquivos subsequentes.
Versões mais recentes do operador de monitoramento podem ser desinstaladas com os seguintes comandos:
kubectl -n <NAMESPACE> delete agent -l installed-by=nkmo-<NAMESPACE> kubectl -n <NAMESPACE> delete clusterrole,clusterrolebinding,crd,svc,deploy,role,rolebinding,secret,sa -l installed-by=nkmo-<NAMESPACE>
Se o operador de monitoramento foi implantado em seu próprio namespace dedicado, exclua o namespace:
kubectl delete ns <NAMESPACE> Observação: se o primeiro comando retornar “Nenhum recurso encontrado”, use as instruções a seguir para desinstalar versões mais antigas do operador de monitoramento.
Execute cada um dos seguintes comandos em ordem. Dependendo da sua instalação atual, alguns desses comandos podem retornar mensagens de "objeto não encontrado". Essas mensagens podem ser ignoradas com segurança.
kubectl -n <NAMESPACE> delete agent agent-monitoring-netapp kubectl delete crd agents.monitoring.netapp.com kubectl -n <NAMESPACE> delete role agent-leader-election-role kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader <NAMESPACE>-agent-manager-role <NAMESPACE>-agent-proxy-role <NAMESPACE>-cluster-role-privileged kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding <NAMESPACE>-agent-manager-rolebinding <NAMESPACE>-agent-proxy-rolebinding <NAMESPACE>-cluster-role-binding-privileged kubectl delete <NAMESPACE>-psp-nkmo kubectl delete ns <NAMESPACE>
Se uma Restrição de Contexto de Segurança foi criada anteriormente:
kubectl delete scc telegraf-hostaccess
Sobre Kube-state-metrics
O NetApp Kubernetes Monitoring Operator instala suas próprias métricas de estado do kube para evitar conflitos com outras instâncias.
Para obter informações sobre Kube-State-Metrics, consulte"esta página" .
Configurando/Personalizando o Operador
Estas seções contêm informações sobre como personalizar a configuração do seu operador, trabalhar com proxy, usar um repositório Docker personalizado ou privado ou trabalhar com o OpenShift.
Opções de configuração
As configurações mais comumente modificadas podem ser configuradas no recurso personalizado AgentConfiguration. Você pode editar este recurso antes de implantar o operador editando o arquivo operator-config.yaml. Este arquivo inclui exemplos comentados de configurações. Veja a lista de"configurações disponíveis" para a versão mais recente do operador.
Você também pode editar esse recurso depois que o operador for implantado usando o seguinte comando:
kubectl -n netapp-monitoring edit AgentConfiguration Para determinar se a versão implantada do operador suporta _AgentConfiguration_, execute o seguinte comando:
kubectl get crd agentconfigurations.monitoring.netapp.com Se você vir uma mensagem “Erro do servidor (Não encontrado)”, seu operador deverá ser atualizado antes que você possa usar o AgentConfiguration.
Configurando o suporte a proxy
Há dois lugares onde você pode usar um proxy no seu locatário para instalar o Kubernetes Monitoring Operator. Esses podem ser os mesmos sistemas proxy ou sistemas separados:
-
Proxy necessário durante a execução do snippet de código de instalação (usando "curl") para conectar o sistema onde o snippet é executado ao seu ambiente do Data Infrastructure Insights
-
Proxy necessário para o cluster Kubernetes de destino se comunicar com seu ambiente do Data Infrastructure Insights
Se você usar um proxy para um ou ambos, para instalar o Kubernetes Operating Monitor, primeiro você deve garantir que seu proxy esteja configurado para permitir uma boa comunicação com seu ambiente do Data Infrastructure Insights . Se você tiver um proxy e puder acessar o Data Infrastructure Insights do servidor/VM do qual deseja instalar o Operator, é provável que seu proxy esteja configurado corretamente.
Para o proxy usado para instalar o Kubernetes Operating Monitor, antes de instalar o Operator, defina as variáveis de ambiente http_proxy/https_proxy. Para alguns ambientes de proxy, talvez você também precise definir a variável de ambiente no_proxy.
Para definir a(s) variável(is), execute as seguintes etapas no seu sistema antes de instalar o Kubernetes Monitoring Operator:
-
Defina as variáveis de ambiente https_proxy e/ou http_proxy para o usuário atual:
-
Se o proxy que está sendo configurado não tiver autenticação (nome de usuário/senha), execute o seguinte comando:
export https_proxy=<proxy_server>:<proxy_port> .. Se o proxy que está sendo configurado tiver autenticação (nome de usuário/senha), execute este comando:
export http_proxy=<proxy_username>:<proxy_password>@<proxy_server>:<proxy_port>
-
Para que o proxy usado no seu cluster Kubernetes se comunique com seu ambiente do Data Infrastructure Insights , instale o Kubernetes Monitoring Operator depois de ler todas estas instruções.
Configure a seção proxy de AgentConfiguration em operator-config.yaml antes de implantar o Kubernetes Monitoring Operator.
agent:
...
proxy:
server: <server for proxy>
port: <port for proxy>
username: <username for proxy>
password: <password for proxy>
# In the noproxy section, enter a comma-separated list of
# IP addresses and/or resolvable hostnames that should bypass
# the proxy
noproxy: <comma separated list>
isTelegrafProxyEnabled: true
isFluentbitProxyEnabled: <true or false> # true if Events Log enabled
isCollectorsProxyEnabled: <true or false> # true if Network Performance and Map enabled
isAuProxyEnabled: <true or false> # true if AU enabled
...
...
Usando um repositório docker personalizado ou privado
Por padrão, o Kubernetes Monitoring Operator extrairá imagens de contêiner do repositório do Data Infrastructure Insights . Se você tiver um cluster Kubernetes usado como destino para monitoramento e esse cluster estiver configurado para extrair apenas imagens de contêiner de um repositório Docker personalizado ou privado ou de um registro de contêiner, você deverá configurar o acesso aos contêineres necessários para o Kubernetes Monitoring Operator.
Execute o “Image Pull Snippet” do bloco de instalação do NetApp Monitoring Operator. Este comando fará login no repositório do Data Infrastructure Insights , extrairá todas as dependências de imagem do operador e sairá do repositório do Data Infrastructure Insights . Quando solicitado, digite a senha temporária do repositório fornecida. Este comando baixa todas as imagens usadas pelo operador, inclusive para recursos opcionais. Veja abaixo para quais recursos essas imagens são usadas.
Funcionalidade do Operador Principal e Monitoramento do Kubernetes
-
monitoramento netapp
-
ci-kube-rbac-proxy
-
ci-ksm
-
ci-telegraf
-
distroless-usuário-root
Registro de eventos
-
ci-fluent-bit
-
ci-kubernetes-event-exporter
Desempenho e Mapa da Rede
-
observador ci-net
Análise de mudanças
-
ci-k8s-change-observer
Envie a imagem do Docker do operador para seu repositório Docker privado/local/empresarial de acordo com suas políticas corporativas. Certifique-se de que as tags de imagem e os caminhos de diretório para essas imagens no seu repositório sejam consistentes com aqueles no repositório do Data Infrastructure Insights .
Edite a implantação do operador de monitoramento em operator-deployment.yaml e modifique todas as referências de imagem para usar seu repositório privado do Docker.
image: <docker repo of the enterprise/corp docker repo>/ci-kube-rbac-proxy:<ci-kube-rbac-proxy version> image: <docker repo of the enterprise/corp docker repo>/netapp-monitoring:<version>
Edite o AgentConfiguration em operator-config.yaml para refletir a nova localização do repositório docker. Crie um novo imagePullSecret para seu repositório privado, para mais detalhes veja https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/
agent: ... # An optional docker registry where you want docker images to be pulled from as compared to CI's docker registry # Please see documentation link here: link:task_config_telegraf_agent_k8s.html#using-a-custom-or-private-docker-repository[Using a custom or private docker repository] dockerRepo: your.docker.repo/long/path/to/test # Optional: A docker image pull secret that maybe needed for your private docker registry dockerImagePullSecret: docker-secret-name
Token de acesso à API para senhas de longo prazo
Alguns ambientes (ou seja, repositórios proxy) exigem senhas de longa duração para o repositório Data Infrastructure Insights docker. A senha fornecida na interface do usuário no momento da instalação é válida por apenas 24 horas. Em vez de usar essa senha, pode-se usar um API Access Token como senha do repositório docker. Essa senha será válida enquanto o API Access Token for válido. Pode-se gerar um novo API Access Token para esse propósito específico ou usar um já existente.
"Leia aqui" para obter instruções sobre como criar um novo token de acesso à API.
Para extrair um token de acesso à API existente de um arquivo operator-secrets.yaml baixado, os usuários podem executar o seguinte:
grep '\.dockerconfigjson' operator-secrets.yaml |sed 's/.*\.dockerconfigjson: //g' |base64 -d |jq
Para extrair um token de acesso à API existente de uma instalação de operador em execução, os usuários podem executar o seguinte:
kubectl -n netapp-monitoring get secret netapp-ci-docker -o jsonpath='{.data.\.dockerconfigjson}' |base64 -d |jq
Instruções do OpenShift
Se você estiver executando o OpenShift 4.6 ou superior, você deve editar o AgentConfiguration em operator-config.yaml para habilitar a configuração runPrivileged:
# Set runPrivileged to true SELinux is enabled on your kubernetes nodes runPrivileged: true
O Openshift pode implementar um nível adicional de segurança que pode bloquear o acesso a alguns componentes do Kubernetes.
Tolerâncias e Manchas
Os DaemonSets netapp-ci-telegraf-ds, netapp-ci-fluent-bit-ds e netapp-ci-net-observer-l4-ds devem agendar um pod em cada nó do cluster para coletar dados corretamente em todos os nós. O operador foi configurado para tolerar algumas manchas bem conhecidas. Se você configurou alguma contaminação personalizada em seus nós, impedindo assim que os pods sejam executados em todos os nós, você pode criar uma tolerância para essas contaminações"na Configuração do Agente" . Se você tiver aplicado taints personalizados a todos os nós do cluster, também deverá adicionar as tolerâncias necessárias à implantação do operador para permitir que o pod do operador seja agendado e executado.
Saiba mais sobre o Kubernetes"Manchas e Tolerâncias" .
Verificando assinaturas de imagem do operador de monitoramento do Kubernetes
A imagem do operador e todas as imagens relacionadas que ele implementa são assinadas pela NetApp. Você pode verificar manualmente as imagens antes da instalação usando a ferramenta cosign ou configurar um controlador de admissão do Kubernetes. Para mais detalhes, consulte o"Documentação do Kubernetes" .
A chave pública usada para verificar as assinaturas de imagem está disponível no bloco de instalação do Operador de Monitoramento em Opcional: Carregar as imagens do operador para seu repositório privado > Chave Pública de Assinatura de Imagem
Para verificar manualmente uma assinatura de imagem, execute as seguintes etapas:
-
Copie e execute o Image Pull Snippet
-
Copie e insira a senha do repositório quando solicitado
-
Armazene a chave pública da assinatura da imagem (dii-image-signing.pub no exemplo)
-
Verifique as imagens usando cosign. Consulte o seguinte exemplo de uso de cosigno
$ cosign verify --key dii-image-signing.pub --insecure-ignore-sct --insecure-ignore-tlog <repository>/<image>:<tag>
Verification for <repository>/<image>:<tag> --
The following checks were performed on each of these signatures:
- The cosign claims were validated
- The signatures were verified against the specified public key
[{"critical":{"identity":{"docker-reference":"<repository>/<image>"},"image":{"docker-manifest-digest":"sha256:<hash>"},"type":"cosign container image signature"},"optional":null}]
Solução de problemas
Algumas coisas que você pode tentar se tiver problemas ao configurar o Kubernetes Monitoring Operator:
| Problema: | Experimente isto: |
|---|---|
Não vejo um hiperlink/conexão entre meu Volume Persistente do Kubernetes e o dispositivo de armazenamento de back-end correspondente. Meu volume persistente do Kubernetes é configurado usando o nome do host do servidor de armazenamento. |
Siga as etapas para desinstalar o agente Telegraf existente e reinstale o agente Telegraf mais recente. Você deve estar usando o Telegraf versão 2.0 ou posterior, e seu armazenamento de cluster Kubernetes deve ser monitorado ativamente pelo Data Infrastructure Insights. |
Estou vendo mensagens nos logs semelhantes às seguintes: E0901 15:21:39.962145 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: Falha ao listar *v1.MutatingWebhookConfiguration: o servidor não conseguiu encontrar o recurso solicitado E0901 15:21:43.168161 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: Falha ao listar *v1.Lease: o servidor não conseguiu encontrar o recurso solicitado (obter leases.coordination.k8s.io) etc. |
Essas mensagens podem ocorrer se você estiver executando o kube-state-metrics versão 2.0.0 ou superior com versões do Kubernetes inferiores à 1.20. Para obter a versão do Kubernetes: kubectl version Para obter a versão do kube-state-metrics: kubectl get deploy/kube-state-metrics -o jsonpath='{..image}' Para evitar que essas mensagens aconteçam, os usuários podem modificar sua implantação do kube-state-metrics para desabilitar os seguintes Leases: mutatingwebhookconfigurations validatingwebhookconfigurations volumeattachments resources Mais especificamente, eles podem usar o seguinte argumento da CLI: resources=certificatesigningrequests,configmaps,cronjobs,daemonsets, deployments,endpoints,horizontalpodautoscalers,ingresses,jobs,limitranges, namespaces,networkpolicies,nodes,persistentvolumeclaims,persistentvolumes, poddisruptionbudgets,pods,replicasets,replicationcontrollers,resourcequotas, segredos, serviços, conjuntos de estado, classes de armazenamento A lista de recursos padrão é: "certificatesigningrequests, configmaps, cronjobs, daemonsets, implantações, endpoints, horizontalpodautoscalers, ingresses, jobs, leases, limitranges, mutatingwebhookconfigurations, namespaces, networkpolicies, nodes, persistentvolumeclaims, persistentvolumes, poddisruptionbudgets, pods, replicasets, replicationcontrollers, resourcequotas, secrets, services, statefulsets, storageclasses, validatingwebhookconfigurations, volumeattachments" |
Vejo mensagens de erro do Telegraf semelhantes às seguintes, mas o Telegraf inicia e executa: 11 de outubro 14:23:41 ip-172-31-39-47 systemd[1]: Iniciado O agente do servidor controlado por plugin para relatar métricas no InfluxDB. 11 de out. 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="falha ao criar diretório de cache. /etc/telegraf/.cache/snowflake, err: mkdir /etc/telegraf/.ca che: permissão negada. ignorada\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" 11 de out. 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="falha ao abrir. Ignorado. abra /etc/telegraf/.cache/snowflake/ocsp_response_cache.json: arquivo ou diretório inexistente\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" 11 de out. 14:23:41 ip-172-31-39-47 telegraf[1827]: 2021-10-11T14:23:41Z Eu! Iniciando o Telegraf 1.19.3 |
Este é um problema conhecido. Consulte"Este artigo do GitHub" para mais detalhes. Enquanto o Telegraf estiver funcionando, os usuários podem ignorar essas mensagens de erro. |
No Kubernetes, meus pods Telegraf estão relatando o seguinte erro: "Erro no processamento de informações de mountstats: falha ao abrir o arquivo mountstats: /hostfs/proc/1/mountstats, erro: abrir /hostfs/proc/1/mountstats: permissão negada" |
Se o SELinux estiver habilitado e em execução, é provável que ele esteja impedindo que o(s) pod(s) Telegraf acessem o arquivo /proc/1/mountstats no nó do Kubernetes. Para superar essa restrição, edite a configuração do agente e ative a configuração runPrivileged. Para mais detalhes, consulte as instruções do OpenShift. |
No Kubernetes, meu pod Telegraf ReplicaSet está relatando o seguinte erro: [inputs.prometheus] Erro no plugin: não foi possível carregar o par de chaves /etc/kubernetes/pki/etcd/server.crt:/etc/kubernetes/pki/etcd/server.key: aberto /etc/kubernetes/pki/etcd/server.crt: nenhum arquivo ou diretório desse tipo |
O pod Telegraf ReplicaSet foi projetado para ser executado em um nó designado como mestre ou para etcd. Se o pod ReplicaSet não estiver em execução em um desses nós, você receberá esses erros. Verifique se seus nós mestre/etcd têm contaminações. Se isso acontecer, adicione as tolerâncias necessárias ao Telegraf ReplicaSet, telegraf-rs. Por exemplo, edite o ReplicaSet… kubectl edit rs telegraf-rs …e adicione as tolerâncias apropriadas à especificação. Em seguida, reinicie o pod ReplicaSet. |
Tenho um ambiente PSP/PSA. Isso afeta meu operador de monitoramento? |
Se o seu cluster Kubernetes estiver em execução com a Política de Segurança de Pod (PSP) ou a Admissão de Segurança de Pod (PSA) em vigor, você deverá atualizar para a versão mais recente do Operador de Monitoramento do Kubernetes. Siga estas etapas para atualizar para a Operadora atual com suporte para PSP/PSA: 1. Desinstalar o operador de monitoramento anterior: kubectl delete agent agent-monitoring-netapp -n netapp-monitoring kubectl delete ns netapp-monitoring kubectl delete crd agents.monitoring.netapp.com kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding 2. Instalar a versão mais recente do operador de monitoramento. |
Tive problemas ao tentar implantar o Operador e tenho o PSP/PSA em uso. |
1. Edite o agente usando o seguinte comando: kubectl -n <name-space> edit agent 2. Marque 'security-policy-enabled' como 'false'. Isso desabilitará as Políticas de Segurança do Pod e a Admissão de Segurança do Pod e permitirá que o Operador faça a implantação. Confirme usando os seguintes comandos: kubectl get psp (deve mostrar que a Política de Segurança do Pod foi removida) kubectl get all -n <namespace> |
grep -i psp (deve mostrar que nada foi encontrado) |
Erros "ImagePullBackoff" vistos |
Esses erros podem ocorrer se você tiver um repositório docker personalizado ou privado e ainda não tiver configurado o Kubernetes Monitoring Operator para reconhecê-lo corretamente. Ler mais sobre configurar para repositório personalizado/privado. |
Estou tendo um problema com a implantação do meu operador de monitoramento e a documentação atual não me ajuda a resolvê-lo. |
Capture ou anote a saída dos seguintes comandos e entre em contato com a equipe de Suporte Técnico. kubectl -n netapp-monitoring get all kubectl -n netapp-monitoring describe all kubectl -n netapp-monitoring logs <monitoring-operator-pod> --all-containers=true kubectl -n netapp-monitoring logs <telegraf-pod> --all-containers=true |
Os pods net-observer (Mapa de Carga de Trabalho) no namespace Operator estão em CrashLoopBackOff |
Esses pods correspondem ao coletor de dados do Workload Map para Network Observability. Tente isto: • Verifique os logs de um dos pods para confirmar a versão mínima do kernel. Por exemplo: ---- {"ci-tenant-id":"your-tenant-id","collector-cluster":"your-k8s-cluster-name","environment":"prod","level":"error","msg":"falha na validação. Motivo: a versão do kernel 3.10.0 é inferior à versão mínima do kernel 4.18.0","time":"2022-11-09T08:23:08Z"} ---- • Os pods do Net-observer exigem que a versão do kernel Linux seja pelo menos 4.18.0. Verifique a versão do kernel usando o comando “uname -r” e certifique-se de que seja >= 4.18.0 |
Os pods estão sendo executados no namespace do Operador (padrão: netapp-monitoring), mas nenhum dado é mostrado na IU para o mapa de carga de trabalho ou métricas do Kubernetes em Consultas |
Verifique a configuração de tempo nos nós do cluster K8S. Para auditoria e relatórios de dados precisos, é altamente recomendável sincronizar a hora na máquina do agente usando o Network Time Protocol (NTP) ou o Simple Network Time Protocol (SNTP). |
Alguns dos pods do net-observer no namespace do operador estão no estado Pendente |
Net-observer é um DaemonSet e executa um pod em cada nó do cluster k8s. • Observe o pod que está no estado Pendente e verifique se ele está enfrentando um problema de recurso de CPU ou memória. Certifique-se de que a memória e a CPU necessárias estejam disponíveis no nó. |
Estou vendo o seguinte em meus logs imediatamente após instalar o Kubernetes Monitoring Operator: [inputs.prometheus] Erro no plugin: erro ao fazer solicitação HTTP para http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics: Obter http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics: discar tcp: procurar kube-state-metrics.<namespace>.svc.cluster.local: nenhum host |
Essa mensagem normalmente só é vista quando um novo operador é instalado e o pod telegraf-rs é ativado antes do pod ksm. Essas mensagens devem parar quando todos os pods estiverem em execução. |
Não vejo nenhuma métrica sendo coletada para os CronJobs do Kubernetes que existem no meu cluster. |
Verifique sua versão do Kubernetes (ou seja, |
Após instalar o operador, os pods telegraf-ds entram em CrashLoopBackOff e os logs dos pods indicam "su: Falha de autenticação". |
Edite a seção telegraf em AgentConfiguration e defina dockerMetricCollectionEnabled como false. Para mais detalhes, consulte o "opções de configuração" do operador. … spec: … telegraf: … - name: docker run-mode: - DaemonSet substitutions: - key: DOCKER_UNIX_SOCK_PLACEHOLDER value: unix:///run/docker.sock … … |
Vejo mensagens de erro repetidas semelhantes às seguintes nos meus logs do Telegraf: E! [agent] Erro ao gravar em outputs.http: Post "https://<tenant_url>/rest/v1/lake/ingest/influxdb": prazo de contexto excedido (Client.Timeout excedido ao aguardar cabeçalhos) |
Edite a seção telegraf em AgentConfiguration e aumente outputTimeout para 10s. Para mais detalhes, consulte o manual do operador"opções de configuração" . |
Estou sem dados involvedobject para alguns Logs de Eventos. |
Certifique-se de ter seguido os passos no"Permissões" seção acima. |
Por que estou vendo dois pods de operador de monitoramento em execução, um chamado netapp-ci-monitoring-operator-<pod> e o outro chamado monitoring-operator-<pod>? |
A partir de 12 de outubro de 2023, o Data Infrastructure Insights refatorou o operador para melhor atender nossos usuários; para que essas mudanças sejam totalmente adotadas, você deveremover o operador antigo einstalar o novo . |
Meus eventos do Kubernetes pararam inesperadamente de reportar ao Data Infrastructure Insights. |
Recupere o nome do pod do exportador de eventos: `kubectl -n netapp-monitoring get pods |
grep event-exporter |
awk '{print $1}' |
sed 's/event-exporter./event-exporter/'` |
Estou vendo pod(s) implantado(s) pelo Kubernetes Monitoring Operator travando devido a recursos insuficientes. |
Consulte o Operador de Monitoramento do Kubernetes"opções de configuração" para aumentar os limites da CPU e/ou memória conforme necessário. |
Uma imagem ausente ou configuração inválida fez com que os pods netapp-ci-kube-state-metrics falhassem na inicialização ou ficassem prontos. Agora o StatefulSet está travado e as alterações de configuração não estão sendo aplicadas aos pods netapp-ci-kube-state-metrics. |
O StatefulSet está em um"quebrado" estado. Depois de corrigir quaisquer problemas de configuração, faça o retorno dos pods netapp-ci-kube-state-metrics. |
Os pods netapp-ci-kube-state-metrics falham ao iniciar após executar uma atualização do Kubernetes Operator, gerando ErrImagePull (falha ao extrair a imagem). |
Tente redefinir os pods manualmente. |
Mensagens "Evento descartado por ser mais antigo que maxEventAgeSeconds" estão sendo observadas no meu cluster Kubernetes na Análise de Log. |
Modifique o operador agentconfiguration e aumente event-exporter-maxEventAgeSeconds (ou seja, para 60s), event-exporter-kubeQPS (ou seja, para 100) e event-exporter-kubeBurst (ou seja, para 500). Para obter mais detalhes sobre essas opções de configuração, consulte o"opções de configuração" página. |
O Telegraf avisa ou trava por causa de memória bloqueável insuficiente. |
Tente aumentar o limite de memória bloqueável para o Telegraf no sistema operacional/nó subjacente. Se aumentar o limite não for uma opção, modifique a configuração do agente NKMO e defina unprotected como true. Isso instruirá o Telegraf a não tentar reservar páginas de memória bloqueadas. Embora isso possa representar um risco à segurança, pois segredos descriptografados podem ser transferidos para o disco, isso permite a execução em ambientes onde não é possível reservar memória bloqueada. Para mais detalhes sobre as opções de configuração desprotegidas, consulte o"opções de configuração" página. |
Vejo mensagens de aviso do Telegraf parecidas com as seguintes: W! [inputs.diskio] Não foi possível coletar o nome do disco para "vdc": erro ao ler /dev/vdc: arquivo ou diretório inexistente |
Para o operador de monitoramento do Kubernetes, essas mensagens de aviso são benignas e podem ser ignoradas com segurança. Como alternativa, edite a seção telegraf em AgentConfiguration e defina runDsPrivileged como true. Para mais detalhes, consulte a "opções de configuração do operador". |
Meu pod fluent-bit está falhando com os seguintes erros: [2024/10/16 14:16:23] [erro] [/src/fluent-bit/plugins/in_tail/tail_fs_inotify.c:360 errno=24] Muitos arquivos abertos [2024/10/16 14:16:23] [erro] falha ao inicializar a entrada tail.0 [2024/10/16 14:16:23] [erro] falha na inicialização da entrada [engine] |
Tente alterar as configurações do fsnotify no seu cluster: sudo sysctl fs.inotify.max_user_instances (take note of setting) sudo sysctl fs.inotify.max_user_instances=<something larger than current setting> sudo sysctl fs.inotify.max_user_watches (take note of setting) sudo sysctl fs.inotify.max_user_watches=<something larger than current setting> Reinicie o Fluent-bit. Observação: para tornar essas configurações persistentes nas reinicializações dos nós, você precisa colocar as seguintes linhas em /etc/sysctl.conf fs.inotify.max_user_instances=<something larger than current setting> fs.inotify.max_user_watches=<something larger than current setting> |
Os pods do Telegraf DS estão relatando erros referentes ao plug-in de entrada do Kubernetes que não consegue fazer solicitações HTTP devido à incapacidade de validar o certificado TLS. Por exemplo: E! [inputs.kubernetes] Erro no plugin: erro ao fazer solicitação HTTP para"https://<kubelet_IP>:10250/stats/summary": Pegar"https://<kubelet_IP>:10250/stats/summary": tls: falha ao verificar o certificado: x509: não é possível validar o certificado para <kubelet_IP> porque ele não contém nenhum SAN IP |
Isso ocorrerá se o kubelet estiver usando certificados autoassinados e/ou o certificado especificado não incluir o <kubelet_IP> na lista Nome alternativo do assunto dos certificados. Para resolver isso, o usuário pode modificar o"configuração do agente" , e defina telegraf:insecureK8sSkipVerify como true. Isso configurará o plugin de entrada do Telegraf para pular a verificação. Alternativamente, o usuário pode configurar o kubelet para"servidorTLSBootstrap" , que acionará uma solicitação de certificado da API 'certificates.k8s.io'. |
Estou recebendo o seguinte erro nos pods do Fluent-bit e o pod não inicia: 026/01/12 20:20:32] [erro] [sqldb] erro=não foi possível abrir o arquivo de banco de dados [2026/01/12 20:20:32] [erro] [input:tail:tail.0] db: não foi possível criar a tabela 'in_tail_files' [2026/01/12 20:20:32] [erro] [input:tail:tail.0] não foi possível abrir/criar o banco de dados [2026/01/12 20:20:32] [erro] falha ao inicializar a entrada tail.0 [2026/01/12 20:20:32] [erro] [engine] falha na inicialização da entrada |
Certifique-se de que o diretório do host em que o arquivo DB reside tenha as permissões de leitura/gravação adequadas. Mais especificamente, o diretório do host deve conceder permissões de leitura/gravação a usuários que não sejam root. O local padrão do arquivo DB é /var/log/, a menos que seja substituído pela opção fluent-bit-dbFile agentconfiguration. Se o SELinux estiver habilitado, tente definir a opção fluent-bit-seLinuxOptionsType agentconfiguration como 'spc_t'. |
Vejo mensagens de erro do Telegraf semelhantes à seguinte, mas o Telegraf inicia e executa normalmente: E! [inputs.kubernetes] Erro no plugin: https://<IP>>:<port>>/pods status HTTP retornado 403 Forbidden |
Essas mensagens podem ocorrer se você estiver executando versões do Kubernetes anteriores à 1.33. O recurso RBAC "nodes/pods" usado pelo telegraf não existe nessas versões. Consulte a seção "For Kubernetes versions < 1.33" do operator-additional-permissions.yaml para os recursos RBAC necessários em versões mais antigas. |
Informações adicionais podem ser encontradas em"Apoiar" página ou no"Matriz de Suporte ao Coletor de Dados" .