

Monitor system health in StorageGRID
 Suggest changes
Suggest changes
Monitor the overall health of your StorageGRID system on a daily basis.
The StorageGRID system can continue to operate when parts of the grid are unavailable. Potential issues indicated by alerts aren't necessarily issues with system operations. Investigate issues summarized on the Health status card of the Grid Manager Dashboard.
To be notified of alerts as soon as they are triggered, you can set up email notifications for alerts or configure SNMP traps.
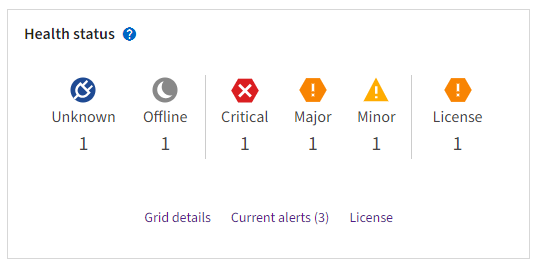
When issues exist, links appear that allow you to view additional details:
| Link | Appears when… |
|---|---|
Grid details |
Any nodes are disconnected (connection state Unknown or Administratively Down). |
Current alerts (Critical, Major, Minor) |
Alerts are currently active. |
Recently resolved alerts |
Alerts triggered in the past week are now resolved. |
License |
There is an issue with the software license for this StorageGRID system. You can update license information as needed. |
Monitor node connection states
If one or more nodes are disconnected from the grid, critical StorageGRID operations might be affected. Monitor node connection states and address any issues promptly.
| Icon | Description | Action required |
|---|---|---|
|
Not connected - Unknown For an unknown reason, a node is disconnected or services on the node are unexpectedly down. For example, a service on the node might be stopped, or the node might have lost its network connection because of a power failure or unexpected outage. The Unable to communicate with node alert might also be triggered. Other alerts might also be active. |
Requires immediate attention. Select each alert and follow the recommended actions. For example, you might need to restart a service that has stopped or restart the host for the node. Note: A node might appear as Unknown during managed shutdown operations. You can ignore the Unknown state in these cases. |
|
Not connected - Administratively down For an expected reason, node is not connected to grid. For example, the node, or services on the node, has been gracefully shut down, the node is rebooting, or the software is being upgraded. One or more alerts might also be active. Based on the underlying issue, these nodes often go back online with no intervention. |
Determine if any alerts are affecting this node. If one or more alerts are active, select each alert and follow the recommended actions. |
|
Connected The node is connected to the grid. |
No action required. |
View current and resolved alerts
Current alerts: When an alert is triggered, an alert icon is displayed on the dashboard. An alert icon is also displayed for the node on the Nodes page. If alert email notifications are configured, an email notification will also be sent, unless the alert has been silenced.
Resolved alerts: You can search and view a history of alerts that have been resolved.
Optionally, you have watched the video:
The following table describes the information shown in the Grid Manager for current and resolved alerts.
| Column header | Description |
|---|---|
Name or title |
The name of the alert and its description. |
Severity |
The severity of the alert. For current alerts, if multiple alerts are grouped the title row shows how many instances of that alert are occurring at each severity.
|
Time triggered |
Current alerts: The date and time the alert was triggered in your local time and in UTC. If multiple alerts are grouped, the title row shows times for the most recent instance of the alert (newest) and the oldest instance of the alert (oldest). Resolved alerts: How long ago the alert was triggered. |
Site/Node |
The name of the site and node where the alert is occurring or has occurred. |
Status |
Whether the alert is active, silenced, or resolved. If multiple alerts are grouped and All alerts is selected in the drop-down, the title row shows how many instances of that alert are active and how many instances have been silenced. |
Time resolved (resolved alerts only) |
How long ago the alert was resolved. |
Current values or data values |
The value of the metric that caused the alert to be triggered. For some alerts, additional values are shown to help you understand and investigate the alert. For example, the values shown for a Low object data storage alert include the percentage of disk space used, the total amount of disk space, and the amount of disk space used. Note: If multiple current alerts are grouped, current values aren't shown in the title row. |
Triggered values (resolved alerts only) |
The value of the metric that caused the alert to be triggered. For some alerts, additional values are shown to help you understand and investigate the alert. For example, the values shown for a Low object data storage alert include the percentage of disk space used, the total amount of disk space, and the amount of disk space used. |
-
Select the Current alerts or Resolved alerts link to view a list of alerts in those categories. You can also view the details for an alert by selecting Nodes > node > Overview and then selecting the alert from the Alerts table.
By default, current alerts are shown as follows:
-
The most recently triggered alerts are shown first.
-
Multiple alerts of the same type are shown as a group.
-
Alerts that have been silenced aren't shown.
-
For a specific alert on a specific node, if the thresholds are reached for more than one severity, only the most severe alert is shown. That is, if alert thresholds are reached for the minor, major, and critical severities, only the critical alert is shown.
The Current alerts page is refreshed every two minutes.
-
-
To expand groups of alerts, select the down caret
 . To collapse individual alerts in a group, select the up caret
. To collapse individual alerts in a group, select the up caret  , or select the group's name.
, or select the group's name. -
To display individual alerts instead of groups of alerts, clear the Group alerts checkbox.
-
To sort current alerts or alert groups, select the up/down arrows
 in each column header.
in each column header.-
When Group alerts is selected, both the alert groups and the individual alerts within each group are sorted. For example, you might want to sort the alerts in a group by Time triggered to find the most recent instance of a specific alert.
-
When Group alerts is cleared, the entire list of alerts is sorted. For example, you might want to sort all alerts by Node/Site to see all alerts affecting a specific node.
-
-
To filter current alerts by status (All alerts, Active, or Silenced, use the drop-down menu at the top of the table.
-
To sort resolved alerts:
-
Select a time period from the When triggered drop-down menu.
-
Select one or more severities from the Severity drop-down menu.
-
Select one or more default or custom alert rules from the Alert rule drop-down menu to filter on resolved alerts related to a specific alert rule.
-
Select one or more nodes from the Node drop-down menu to filter on resolved alerts related to a specific node.
-
-
To view details for a specific alert, select the alert. A dialog box provides details and recommended actions for the alert you selected.
-
(Optional) For a specific alert, select silence this alert to silence the alert rule that caused this alert to be triggered.
You must have the Manage alerts or Root access permission to silence an alert rule.

Be careful when deciding to silence an alert rule. If an alert rule is silenced, you might not detect an underlying problem until it prevents a critical operation from completing. -
To view the current conditions for the alert rule:
-
From the alert details, select View conditions.
A pop-up appears, listing the Prometheus expression for each defined severity.
-
To close the pop-up, select any location outside of the pop-up.
-
-
Optionally, select Edit rule to edit the alert rule that caused this alert to be triggered.
You must have the Manage alerts or Root access permission to edit an alert rule.
Be careful when deciding to edit an alert rule. If you change trigger values, you might not detect an underlying problem until it prevents a critical operation from completing. -
To close the alert details, select Close.