

Kubernetes 监控 Operator 安装和配置
 建议更改
建议更改
Data Infrastructure Insights为 Kubernetes 集合提供了 Kubernetes Monitoring Operator。导航到 Kubernetes > Collectors > +Kubernetes Collector 来部署新的操作员。
安装 Kubernetes Monitoring Operator 之前
查看"先决条件"在安装或升级 Kubernetes Monitoring Operator 之前,请先阅读文档。
安装 Kubernetes 监控操作员
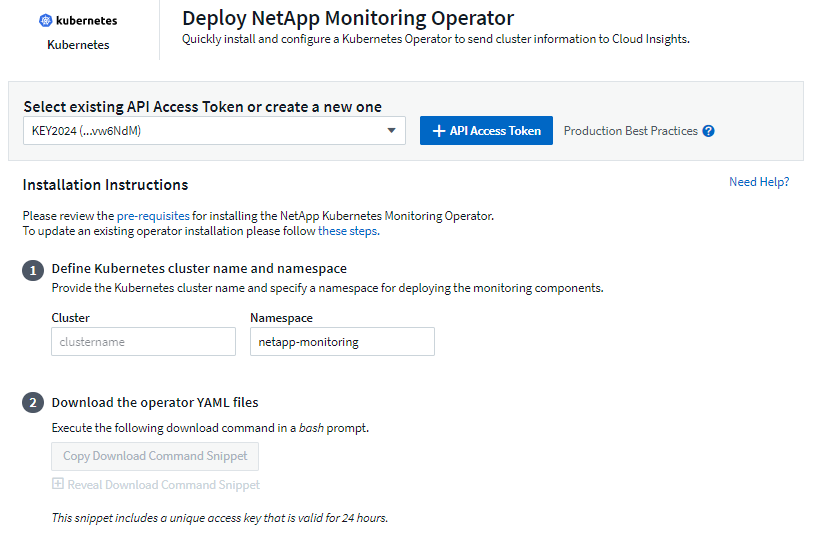
-
输入唯一的集群名称和命名空间。如果你升级与之前的 Kubernetes Operator 一样,使用相同的集群名称和命名空间。
-
输入这些内容后,您可以将下载命令片段复制到剪贴板。
-
将代码片段粘贴到 bash 窗口并执行。将下载 Operator 安装文件。请注意,该代码片段具有唯一密钥,并且有效期为 24 小时。
-
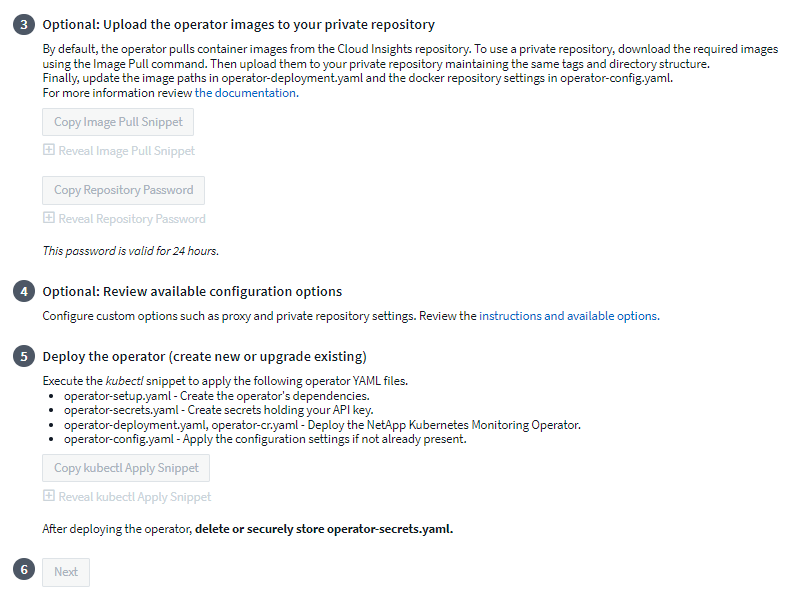
如果您有自定义或私有存储库,请复制可选的 Image Pull 代码片段,将其粘贴到 bash shell 中并执行。提取图像后,将其复制到您的私人存储库。确保保持相同的标签和文件夹结构。更新_operator-deployment.yaml_ 中的路径以及_operator-config.yaml_ 中的 docker 存储库设置。
-
如果需要,请查看可用的配置选项,例如代理或私有存储库设置。您可以阅读更多关于"配置选项"。
-
准备就绪后,通过复制 kubectl Apply 代码片段、下载并执行它来部署 Operator。
-
安装将自动进行。完成后,单击“下一步”按钮。
-
安装完成后,单击“下一步”按钮。请确保删除或安全存储 operator-secrets.yaml 文件。
如果您有自定义存储库,请阅读使用自定义/私有 docker 仓库。
Kubernetes 监控组件
Data Infrastructure InsightsKubernetes 监控由四个监控组件组成:
-
集群指标
-
网络性能和地图(可选)
-
事件日志(可选)
-
变化分析(可选)
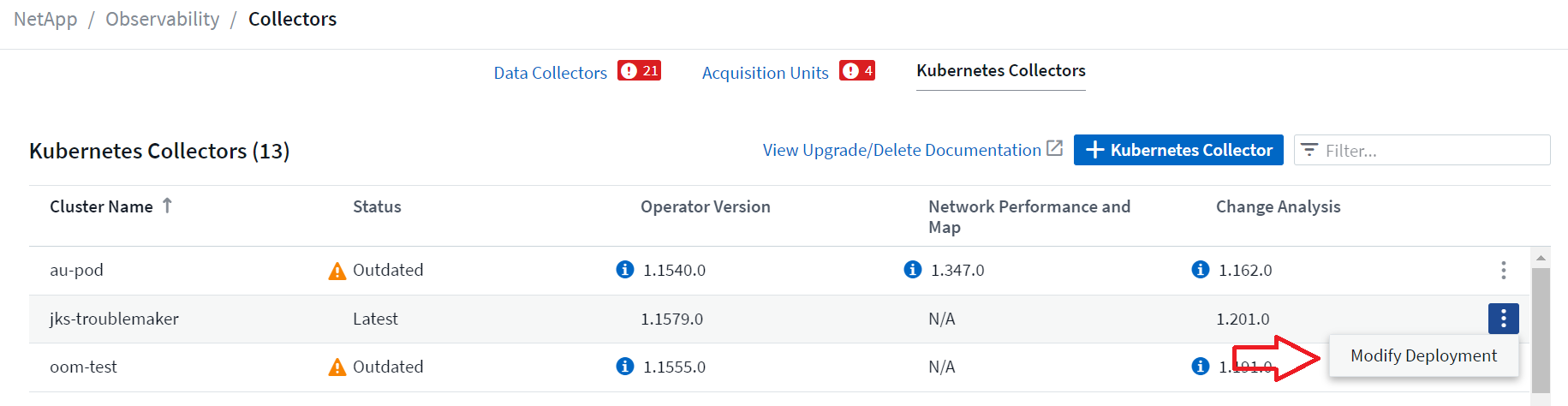
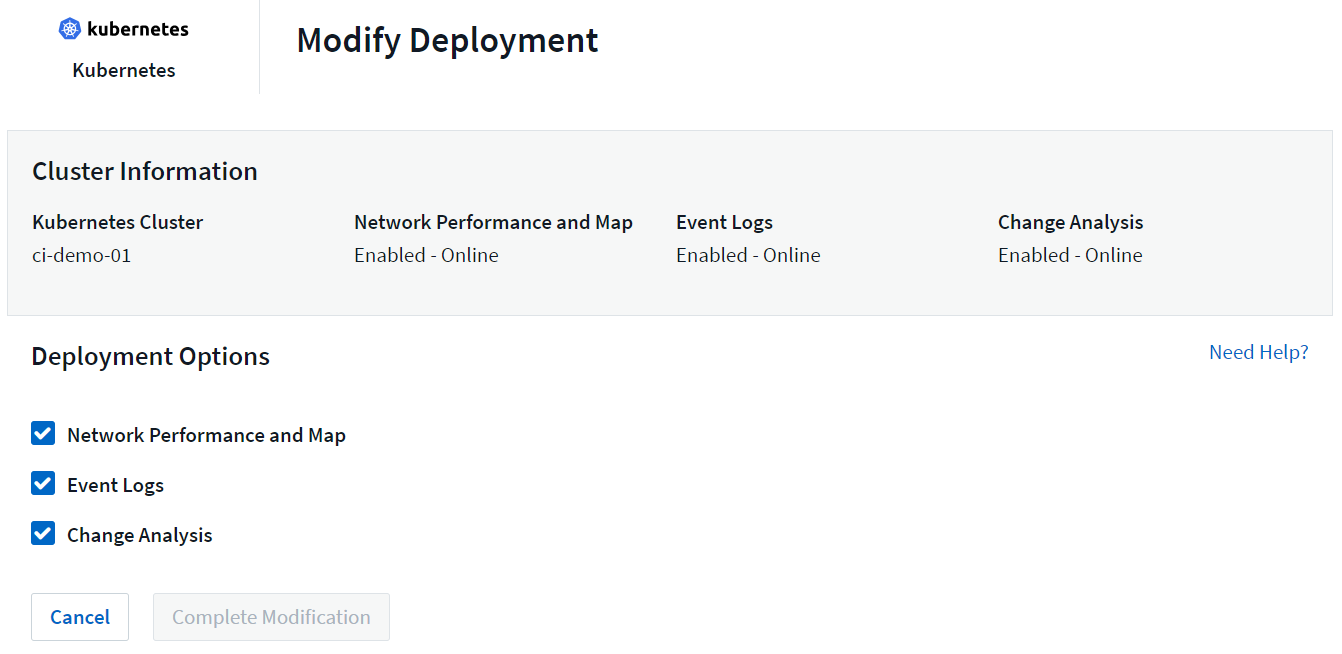
默认情况下,每个 Kubernetes 收集器都会启用上述可选组件;如果您决定不需要特定收集器的组件,则可以通过导航到 Kubernetes > Collectors 并从屏幕右侧收集器的“三个点”菜单中选择_修改部署_来禁用它。
屏幕显示每个组件的当前状态,并允许您根据需要禁用或启用该收集器的组件。
升级到最新的 Kubernetes Monitoring Operator
DII 按钮升级
您可以通过 DII Kubernetes Collectors 页面升级 Kubernetes Monitoring Operator。单击要升级的集群旁边的菜单,然后选择“升级”。操作员将验证图像签名,对当前安装进行快照并执行升级。几分钟内,您将看到操作员状态从“升级进行中”进展到“最新”。如果遇到错误,您可以选择错误状态以了解更多详细信息,并参考下面的按钮升级故障排除表。

|
1.2057.0 之前的操作员版本不提供按钮升级。请按照以下手动升级说明升级到最新版本。完成此操作后,可以使用按钮升级功能执行未来的升级。 |
使用私有存储库进行按钮升级
如果您的操作员配置为使用私有存储库,请确保运行操作员所需的所有图像及其签名均可在您的存储库中获取。如果在升级过程中遇到缺少图像的错误,只需将它们添加到存储库并重试升级。要将图像签名上传到您的存储库,请使用如下 cosign 工具,确保上传 3 下指定的所有图像的签名可选:将操作员图像上传到您的私人存储库 > 图像拉取片段
cosign copy example.com/src:v1 example.com/dest:v1 #Example cosign copy <DII container registry>/netapp-monitoring:<image version> <private repository>/netapp-monitoring:<image version>
回滚到之前运行的版本
如果您使用按钮升级功能进行升级,并且在升级后七天内遇到当前版本的操作员的任何困难,则可以使用升级过程中创建的快照降级到以前运行的版本。单击要回滚的集群旁边的菜单,然后选择“回滚”。
手动升级
确定是否存在与现有 Operator 一起的 AgentConfiguration(如果您的命名空间不是默认的 netapp-monitoring,请替换相应的命名空间):
kubectl -n netapp-monitoring get agentconfiguration netapp-ci-monitoring-configuration 如果存在 _AgentConfiguration_:
如果 AgentConfiguration 不存在:
-
记下Data Infrastructure Insights识别的集群名称(如果您的命名空间不是默认的 netapp-monitoring,请替换为适当的命名空间):
kubectl -n netapp-monitoring get agent -o jsonpath='{.items[0].spec.cluster-name}' * 创建现有 Operator 的备份(如果您的命名空间不是默认的 netapp-monitoring,请替换为适当的命名空间):kubectl -n netapp-monitoring get agent -o yaml > agent_backup.yaml * <<to-remove-the-kubernetes-monitoring-operator,卸载>>现有的运营商。 * <<installing-the-kubernetes-monitoring-operator,安装>>最新的操作员。
-
使用相同的集群名称。
-
下载最新的 Operator YAML 文件后,将 agent_backup.yaml 中的任何自定义项移植到已下载的 operator-config.yaml,然后再进行部署。
-
确保您拉取最新的容器镜像如果您使用自定义存储库。
-
停止和启动 Kubernetes 监控操作员
要停止 Kubernetes Monitoring Operator:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=0 要启动 Kubernetes Monitoring Operator:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=1
卸载
删除 Kubernetes Monitoring Operator
请注意,Kubernetes Monitoring Operator 的默认命名空间是“netapp-monitoring”。如果您设置了自己的命名空间,请在这些命令和所有后续命令和文件中替换该命名空间。
可以使用以下命令卸载较新版本的监控操作员:
kubectl -n <NAMESPACE> delete agent -l installed-by=nkmo-<NAMESPACE> kubectl -n <NAMESPACE> delete clusterrole,clusterrolebinding,crd,svc,deploy,role,rolebinding,secret,sa -l installed-by=nkmo-<NAMESPACE>
如果监控操作员部署在其自己的专用命名空间中,请删除该命名空间:
kubectl delete ns <NAMESPACE> 注意:如果第一个命令返回“未找到资源”,请使用以下说明卸载旧版本的监控操作员。
按顺序执行以下每个命令。根据您当前的安装,其中一些命令可能会返回“未找到对象”消息。您可以安全地忽略这些消息。
kubectl -n <NAMESPACE> delete agent agent-monitoring-netapp kubectl delete crd agents.monitoring.netapp.com kubectl -n <NAMESPACE> delete role agent-leader-election-role kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader <NAMESPACE>-agent-manager-role <NAMESPACE>-agent-proxy-role <NAMESPACE>-cluster-role-privileged kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding <NAMESPACE>-agent-manager-rolebinding <NAMESPACE>-agent-proxy-rolebinding <NAMESPACE>-cluster-role-binding-privileged kubectl delete <NAMESPACE>-psp-nkmo kubectl delete ns <NAMESPACE>
如果先前创建了安全上下文约束:
kubectl delete scc telegraf-hostaccess
关于 Kube-state-metrics
NetApp Kubernetes Monitoring Operator 安装自己的 kube-state-metrics 以避免与任何其他实例发生冲突。
有关 Kube-State-Metrics 的信息,请参阅"本页"。
配置/自定义操作员
这些部分包含有关自定义操作员配置、使用代理、使用自定义或私有 docker 存储库或使用 OpenShift 的信息。
配置选项
最常修改的设置可以在_AgentConfiguration_自定义资源中配置。您可以在部署操作员之前通过编辑 operator-config.yaml 文件来编辑此资源。该文件包含已注释掉的设置示例。查看列表"可用设置"以获取最新版本的操作员。
您还可以在部署操作员后使用以下命令编辑此资源:
kubectl -n netapp-monitoring edit AgentConfiguration 要确定已部署版本的操作符是否支持 _AgentConfiguration_,请运行以下命令:
kubectl get crd agentconfigurations.monitoring.netapp.com 如果您看到“服务器错误(未找到)”消息,则必须先升级您的操作员才能使用 AgentConfiguration。
配置代理支持
您可以在租户的两个地方使用代理来安装 Kubernetes Monitoring Operator。这些可能是相同或独立的代理系统:
-
执行安装代码片段(使用“curl”)期间需要代理,以将执行代码片段的系统连接到您的Data Infrastructure Insights环境
-
目标 Kubernetes 集群与您的Data Infrastructure Insights环境进行通信所需的代理
如果您对其中一个或两个都使用代理,为了安装 Kubernetes 操作监视器,您必须首先确保您的代理配置为允许与您的Data Infrastructure Insights环境进行良好的通信。如果您有代理并且可以从您希望安装 Operator 的服务器/VM 访问Data Infrastructure Insights,那么您的代理可能配置正确。
对于用于安装 Kubernetes Operating Monitor 的代理,在安装 Operator 之前,请设置 http_proxy/https_proxy 环境变量。对于某些代理环境,您可能还需要设置 no_proxy environment 变量。
要设置变量,请在安装 Kubernetes Monitoring Operator*之前*在系统上执行以下步骤:
-
为当前用户设置 https_proxy 和/或 http_proxy 环境变量:
-
如果正在设置的代理没有身份验证(用户名/密码),请运行以下命令:
export https_proxy=<proxy_server>:<proxy_port> .. 如果正在设置的代理确实具有身份验证(用户名/密码),请运行以下命令:
export http_proxy=<proxy_username>:<proxy_password>@<proxy_server>:<proxy_port>
-
对于用于 Kubernetes 集群与Data Infrastructure Insights环境通信的代理,请在阅读所有这些说明后安装 Kubernetes 监控操作员。
在部署 Kubernetes Monitoring Operator 之前,配置 operator-config.yaml 中 AgentConfiguration 的代理部分。
agent:
...
proxy:
server: <server for proxy>
port: <port for proxy>
username: <username for proxy>
password: <password for proxy>
# In the noproxy section, enter a comma-separated list of
# IP addresses and/or resolvable hostnames that should bypass
# the proxy
noproxy: <comma separated list>
isTelegrafProxyEnabled: true
isFluentbitProxyEnabled: <true or false> # true if Events Log enabled
isCollectorsProxyEnabled: <true or false> # true if Network Performance and Map enabled
isAuProxyEnabled: <true or false> # true if AU enabled
...
...
使用自定义或私有的 Docker 仓库
默认情况下,Kubernetes Monitoring Operator 将从Data Infrastructure Insights存储库中提取容器镜像。如果您有一个 Kubernetes 集群作为监控目标,并且该集群配置为仅从自定义或私有 Docker 存储库或容器注册表中提取容器镜像,则必须配置对 Kubernetes 监控操作员所需容器的访问权限。
从NetApp Monitoring Operator 安装图块运行“Image Pull Snippet”。此命令将登录Data Infrastructure Insights存储库,为操作员提取所有图像依赖项,并退出Data Infrastructure Insights存储库。出现提示时,输入提供的存储库临时密码。此命令下载操作员使用的所有图像,包括可选功能。请参阅下文了解这些图像的用途。
核心 Operator 功能和 Kubernetes 监控
-
netapp-监控
-
ci-kube-rbac-代理
-
ci-ksm
-
西电讯报
-
distroless-root 用户
事件日志
-
ci-fluent-bit
-
ci-kubernetes-事件导出器
网络性能和地图
-
ci-net-观察者
变更分析
-
ci-k8s-change-observer
根据您的公司政策将操作员 docker 镜像推送到您的私有/本地/企业 docker 存储库。确保存储库中这些图像的图像标签和目录路径与Data Infrastructure Insights存储库中的一致。
编辑 operator-deployment.yaml 中的 monitoring-operator 部署,并修改所有镜像引用以使用您的私有 Docker 存储库。
image: <docker repo of the enterprise/corp docker repo>/ci-kube-rbac-proxy:<ci-kube-rbac-proxy version> image: <docker repo of the enterprise/corp docker repo>/netapp-monitoring:<version>
编辑 operator-config.yaml 中的 AgentConfiguration 以反映新的 docker repo 位置。为您的专用存储库创建新的 imagePullSecret,有关详细信息,请参见 https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/
agent: ... # An optional docker registry where you want docker images to be pulled from as compared to CI's docker registry # Please see documentation link here: link:task_config_telegraf_agent_k8s.html#using-a-custom-or-private-docker-repository[Using a custom or private docker repository] dockerRepo: your.docker.repo/long/path/to/test # Optional: A docker image pull secret that maybe needed for your private docker registry dockerImagePullSecret: docker-secret-name
长期密码的 API 访问令牌
某些环境(即代理存储库)需要 Data Infrastructure Insights docker 存储库的长期密码。安装时在 UI 中提供的密码仅在 24 小时内有效。可以使用 API 访问令牌作为 docker 存储库密码,而不是使用它。只要 API 访问令牌有效,此密码就会有效。可以为此特定目的生成新的 API 访问令牌,也可以使用现有的 API 访问令牌。
"阅读此处" 以获取创建新 API 访问令牌的说明。
要从下载的 operator-secrets.yaml 文件中提取现有的 API Access Token,用户可以运行以下命令:
grep '\.dockerconfigjson' operator-secrets.yaml |sed 's/.*\.dockerconfigjson: //g' |base64 -d |jq
要从正在运行的操作符安装中提取现有 API 访问令牌,用户可以运行以下命令:
kubectl -n netapp-monitoring get secret netapp-ci-docker -o jsonpath='{.data.\.dockerconfigjson}' |base64 -d |jq
OpenShift 说明
如果您在 OpenShift 4.6 或更高版本上运行,则必须编辑 operator-config.yaml 中的 AgentConfiguration 以启用 runPrivileged 设置:
# Set runPrivileged to true SELinux is enabled on your kubernetes nodes runPrivileged: true
Openshift 可能会实施额外的安全级别,从而阻止对某些 Kubernetes 组件的访问。
容忍度和污点
netapp-ci-telegraf-ds、netapp-ci-fluent-bit-ds 和 netapp-ci-net-observer-l4-ds DaemonSet 必须在集群中的每个节点上安排一个 pod,以便正确收集所有节点上的数据。操作员已配置为容忍一些众所周知的*污点*。如果您在节点上配置了任何自定义污点,从而阻止 Pod 在每个节点上运行,则可以为这些污点创建 *容忍度*"在_AgentConfiguration_中" 。如果您已将自定义污点应用于集群中的所有节点,则还必须向操作员部署添加必要的容忍度,以允许调度和执行操作员 pod。
了解有关 Kubernetes 的更多信息"污点和容忍度"。
验证 Kubernetes 监控 Operator 镜像签名
操作员的映像及其部署的所有相关映像均由NetApp签名。您可以在安装前使用 cosign 工具手动验证图像,或者配置 Kubernetes 准入控制器。欲了解更多详情,请参阅"Kubernetes 文档"。
用于验证镜像签名的公钥可在“监控操作员”安装磁贴中找到,位于“可选:将操作员镜像上传到您的私有存储库 > 镜像签名公钥”下
要手动验证图像签名,请执行以下步骤:
-
复制并运行图像拉取片段
-
出现提示时复制并输入存储库密码
-
存储图像签名公钥(示例中为 dii-image-signing.pub)
-
使用 cosign 验证图像。请参阅以下 cosign 用法示例
$ cosign verify --key dii-image-signing.pub --insecure-ignore-sct --insecure-ignore-tlog <repository>/<image>:<tag>
Verification for <repository>/<image>:<tag> --
The following checks were performed on each of these signatures:
- The cosign claims were validated
- The signatures were verified against the specified public key
[{"critical":{"identity":{"docker-reference":"<repository>/<image>"},"image":{"docker-manifest-digest":"sha256:<hash>"},"type":"cosign container image signature"},"optional":null}]
故障排除
如果在设置 Kubernetes Monitoring Operator 时遇到问题,请尝试以下操作:
| 问题: | 尝试一下: |
|---|---|
我没有看到我的 Kubernetes 持久卷和相应的后端存储设备之间的超链接/连接。我的 Kubernetes 持久卷是使用存储服务器的主机名配置的。 |
按照步骤卸载现有的 Telegraf 代理,然后重新安装最新的 Telegraf 代理。您必须使用 Telegraf 2.0 或更高版本,并且您的 Kubernetes 集群存储必须由Data Infrastructure Insights主动监控。 |
我在日志中看到类似以下内容的消息:E0901 15:21:39.962145 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352:无法列出*v1.MutatingWebhookConfiguration:服务器找不到请求的资源E0901 15:21:43.168161 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352:无法列出*v1.Lease:服务器找不到请求的资源(获取leases.coordination.k8s.io)等。 |
如果您运行 kube-state-metrics 版本 2.0.0 或更高版本且 Kubernetes 版本低于 1.20,则可能会出现这些消息。获取 Kubernetes 版本:kubectl version 获取 kube-state-metrics 版本:kubectl get deploy/kube-state-metrics -o jsonpath='{..image}' 为了防止出现这些消息,用户可以修改其 kube-state-metrics 部署以禁用以下租约:mutatingwebhookconfigurations validatingwebhookconfigurations volumeattachments resources 更具体地说,他们可以使用以下 CLI 参数:resources=certificatesigningrequests、configmaps、cronjobs、daemonsets、deployments、endpoints、horizontalpodautoscalers、ingresses、jobs、limitranges、namespaces、networkpolicies、nodes、persistentvolumeclaims、persistentvolumes、poddisruptionbudgets、pods、replicasets、replicationcontrollers、resourcequotas, secrets,services,statefulsets,storageclasses 默认资源列表为:“certificatesigningrequests、configmaps、cronjobs、daemonsets、deployments、endpoints、horizontalpodautoscalers、ingresses、jobs、leases、limitranges、mutatingwebhookconfigurations、namespaces、networkpolicies、nodes、persistentvolumeclaims、persistentvolumes、poddisruptionbudgets、pods、replicasets、replicationcontrollers、resourcequotas、secrets、services、statefulsets、storageclasses、validatingwebhookconfigurations、volumeattachments” |
我看到 Telegraf 发出类似以下内容的错误消息,但 Telegraf 确实启动并运行:10 月 11 日 14:23:41 ip-172-31-39-47 systemd[1]: 已启动用于将指标报告到 InfluxDB 的插件驱动的服务器代理。 10月11日 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="无法创建缓存目录。 /etc/telegraf/.cache/snowflake,错误:mkdir /etc/telegraf/.ca che:权限被拒绝。ignored\n” func="gosnowflake.(*defaultLogger).Errorf” file="log.go:120” 10月11日 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="无法打开。忽略。打开 /etc/telegraf/.cache/snowflake/ocsp_response_cache.json:没有这样的文件或目录\n“func =”gosnowflake。(*defaultLogger).Errorf“file =”log.go:120“10月11日14:23:41 ip-172-31-39-47 telegraf [1827]:2021-10-11T14:23:41Z I!启动 Telegraf 1.19.3 |
这是一个已知问题。参考"这篇 GitHub 文章"了解更多详情。只要 Telegraf 正常运行,用户就可以忽略这些错误消息。 |
在 Kubernetes 上,我的 Telegraf pod 报告以下错误:“处理 mountstats 信息时出错:无法打开 mountstats 文件:/hostfs/proc/1/mountstats,错误:打开 /hostfs/proc/1/mountstats:权限被拒绝” |
如果启用并强制执行 SELinux,则可能会阻止 Telegraf pod 访问 Kubernetes 节点上的 /proc/1/mountstats 文件。要克服此限制,请编辑代理配置并启用 runPrivileged 设置。有关更多详细信息,请参阅 OpenShift 说明。 |
在 Kubernetes 上,我的 Telegraf ReplicaSet pod 报告以下错误:[inputs.prometheus] 插件错误:无法加载密钥对 /etc/kubernetes/pki/etcd/server.crt:/etc/kubernetes/pki/etcd/server.key:打开 /etc/kubernetes/pki/etcd/server.crt:没有此文件或目录 |
Telegraf ReplicaSet pod 旨在在指定为主节点或 etcd 的节点上运行。如果 ReplicaSet pod 没有在其中一个节点上运行,您将收到这些错误。检查您的 master/etcd 节点是否有污点。如果确实如此,请向 Telegraf ReplicaSet、telegraf-rs 添加必要的容忍度。例如,编辑 ReplicaSet…kubectl edit rs telegraf-rs…并将适当的容忍度添加到规范中。然后,重新启动 ReplicaSet pod。 |
我有一个 PSP/PSA 环境。这会影响我的监控操作员吗? |
如果您的 Kubernetes 集群正在运行 Pod 安全策略 (PSP) 或 Pod 安全准入 (PSA),则必须升级到最新的 Kubernetes 监控操作员。按照以下步骤升级到支持 PSP/PSA 的当前运营商:1.卸载上一个监控操作员: kubectl delete agent agent-monitoring-netapp -n netapp-monitoring kubectl delete ns netapp-monitoring kubectl delete crd agents.monitoring.netapp.com kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding 2.安装监控操作员的最新版本。 |
我在尝试部署 Operator 时遇到了问题,并且我正在使用 PSP/PSA。 |
1.使用以下命令编辑代理:kubectl -n <name-space> edit agent 2。将“security-policy-enabled”标记为“false”。这将禁用 Pod 安全策略和 Pod 安全准入并允许操作员部署。使用以下命令确认:kubectl get psp(应该显示 Pod 安全策略已删除)kubectl get all -n <namespace> |
grep -i psp(应该显示未找到任何内容) |
出现“ImagePullBackoff”错误 |
如果您有自定义或私有 docker 存储库,并且尚未配置 Kubernetes Monitoring Operator 以正确识别它,则可能会看到这些错误。阅读更多有关自定义/私有存储库的配置。 |
我的监控操作员部署出现了问题,当前文档无法帮助我解决该问题。 |
捕获或以其他方式记录以下命令的输出,并联系技术支持团队。 kubectl -n netapp-monitoring get all kubectl -n netapp-monitoring describe all kubectl -n netapp-monitoring logs <monitoring-operator-pod> --all-containers=true kubectl -n netapp-monitoring logs <telegraf-pod> --all-containers=true |
Operator 命名空间中的 net-observer(工作负载图)pod 处于 CrashLoopBackOff 状态 |
这些 pod 对应于网络可观测性的工作负载图数据收集器。尝试以下操作:• 检查其中一个 pod 的日志以确认最低内核版本。例如: ---- {“ci-tenant-id”:“your-tenant-id”,“collector-cluster”:“your-k8s-cluster-name”,“environment”:“prod”,“level”:“error”,“msg”:“验证失败。原因:内核版本 3.10.0 低于最低内核版本 4.18.0","time":"2022-11-09T08:23:08Z"} ---- • Net-observer pods 要求 Linux 内核版本至少为 4.18.0。使用命令“uname -r”检查内核版本,并确保它们> = 4.18.0 |
Pod 在 Operator 命名空间(默认值:netapp-monitoring)中运行,但 UI 中未显示工作负载图或查询中的 Kubernetes 指标的数据 |
检查K8S集群节点上的时间设置。为了准确的审计和数据报告,强烈建议使用网络时间协议 (NTP) 或简单网络时间协议 (SNTP) 同步代理机器上的时间。 |
Operator 命名空间中的部分 net-observer pod 处于 Pending 状态 |
Net-observer是一个DaemonSet,在k8s集群的每个Node中运行一个pod。 • 注意处于待处理状态的 pod,并检查它是否遇到 CPU 或内存资源问题。确保节点中具有所需的内存和 CPU。 |
安装 Kubernetes Monitoring Operator 后,我立即在日志中看到以下内容:[inputs.prometheus] 插件错误:向 http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics 发出 HTTP 请求时出错:获取 http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics:拨号 tcp:查找 kube-state-metrics.<namespace>.svc.cluster.local:没有这样的主机 |
通常仅在安装新操作员并且 telegraf-rs pod 在 ksm pod 启动之前启动时才会看到此消息。一旦所有 pod 都运行起来,这些消息就会停止。 |
我确实没有看到针对我的集群中存在的 Kubernetes CronJobs 收集任何指标。 |
验证你的 Kubernetes 版本(即 |
安装操作员后,telegraf-ds pod 进入 CrashLoopBackOff,pod 日志显示“su: Authentication failed”。 |
编辑 AgentConfiguration 中的 telegraf 部分,并将 dockerMetricCollectionEnabled 设置为 false。更多详情请参考 operator 的"配置选项"。… spec: … telegraf: …- name: docker run-mode: - DaemonSet substitutions: - key: DOCKER_UNIX_SOCK_PLACEHOLDER value: unix:///run/docker.sock …… |
我在 Telegraf 日志中看到类似以下内容的重复错误消息:E! [agent] 写入输出时出错。http:发布“\https://<tenant_url>/rest/v1/lake/ingest/influxdb”:超出上下文截止时间(等待标头时超出 Client.Timeout) |
编辑_AgentConfiguration_中的telegraf部分,并将_outputTimeout_增加到10秒。欲了解更多详情,请参阅运营商的"配置选项"。 |
我缺少某些事件日志的_involvedobject_数据。 |
确保您已按照"权限"上面的部分。 |
为什么我看到两个监控操作员 pod 正在运行,一个名为 netapp-ci-monitoring-operator-<pod>,另一个名为 monitoring-operator-<pod>? |
自 2023 年 10 月 12 日起, Data Infrastructure Insights已重构了 Operator,以便更好地服务我们的用户;为了完全采用这些更改,您必须删除旧的操作员和安装新的。 |
我的 kubernetes 事件意外停止向Data Infrastructure Insights报告。 |
检索事件导出器 pod 的名称: `kubectl -n netapp-monitoring get pods |
grep event-exporter |
awk '{print $1}' |
sed 's/event-exporter./event-exporter/'` |
我看到 Kubernetes Monitoring Operator 部署的 pod 由于资源不足而崩溃。 |
参考 Kubernetes Monitoring Operator"配置选项"根据需要增加 CPU 和/或内存限制。 |
缺少图像或配置无效导致 netapp-ci-kube-state-metrics pod 无法启动或准备就绪。现在 StatefulSet 卡住了,配置更改没有应用到 netapp-ci-kube-state-metrics pod。 |
StatefulSet 位于"破碎的"状态。修复所有配置问题后,反弹 netapp-ci-kube-state-metrics pod。 |
运行 Kubernetes Operator 升级后,netapp-ci-kube-state-metrics pod 无法启动,抛出 ErrImagePull(无法拉取图像)。 |
尝试手动重置 pod。 |
在日志分析下,我的 Kubernetes 集群中观察到“事件因超过 maxEventAgeSeconds 而被丢弃”消息。 |
修改 Operator agentconfiguration,将 event-exporter-maxEventAgeSeconds(即增加到 60s)、event-exporter-kubeQPS(即增加到 100)和 event-exporter-kubeBurst(即增加到 500)增加。有关这些配置选项的更多详细信息,请参阅"配置选项"页。 |
Telegraf 因可锁定内存不足而发出警告或崩溃。 |
尝试增加底层操作系统/节点中 Telegraf 的可锁定内存限制。如果无法增加限制,请修改 NKMO 代理配置并将 unprotected 设置为 true。这将指示 Telegraf 不要尝试保留锁定的内存页面。虽然这可能会带来安全风险,因为解密的秘密可能会被交换到磁盘,但它允许在无法保留锁定内存的环境中执行。有关 unprotected 配置选项的更多详细信息,请参阅"配置选项"页。 |
我看到来自 Telegraf 的类似以下内容的警告消息:W! [inputs.diskio] 无法收集“vdc”的磁盘名称:读取 /dev/vdc 时出错:没有此文件或目录 |
对于 Kubernetes Monitoring Operator,这些警告消息是良性的,可以安全地忽略。或者,编辑 AgentConfiguration 中的 telegraf 部分,并将 runDsPrivileged 设置为 true。有关更多详细信息,请参阅"操作员的配置选项"。 |
我的 fluent-bit pod 出现以下错误:[2024/10/16 14:16:23] [错误] [/src/fluent-bit/plugins/in_tail/tail_fs_inotify.c:360 errno=24] 打开的文件太多 [2024/10/16 14:16:23] [错误] 初始化输入 tail.0 失败 [2024/10/16 14:16:23] [错误] [引擎] 输入初始化失败 |
尝试更改集群中的 fsnotify 设置: sudo sysctl fs.inotify.max_user_instances (take note of setting) sudo sysctl fs.inotify.max_user_instances=<something larger than current setting> sudo sysctl fs.inotify.max_user_watches (take note of setting) sudo sysctl fs.inotify.max_user_watches=<something larger than current setting> 重新启动 Fluent-bit。 注意:为了使这些设置在节点重启后仍然有效,您需要在 /etc/sysctl.conf 中添加以下几行 fs.inotify.max_user_instances=<something larger than current setting> fs.inotify.max_user_watches=<something larger than current setting> |
telegraf DS pods 报告与 kubernetes 输入插件有关的错误,由于无法验证 TLS 证书而无法发出 HTTP 请求。例如:E! [inputs.kubernetes] 插件错误:向以下对象发出 HTTP 请求时出错"https://<kubelet_IP>:10250/stats/summary":得到"https://<kubelet_IP>:10250/stats/summary":tls:无法验证证书:x509:无法验证 <kubelet_IP> 的证书,因为它不包含任何 IP SAN |
如果 kubelet 使用自签名证书,和/或指定的证书未在证书_Subject Alternative Name_ 列表中包含 <kubelet_IP>,就会发生这种情况。为了解决这个问题,用户可以修改"代理配置",并将 telegraf:insecureK8sSkipVerify 设置为 true。这将配置 telegraf 输入插件以跳过验证。或者,用户可以配置 kubelet"服务器TLSBootstrap" ,这将触发来自“certificates.k8s.io”API 的证书请求。 |
我在 Fluent-bit pods 中收到以下错误,pod 无法启动:026/01/12 20:20:32] [error] [sqldb] error=unable to open database file [2026/01/12 20:20:32] [error] [input:tail:tail.0] db: could not create 'in_tail_files' table [2026/01/12 20:20:32] [error] [input:tail:tail.0] could not open/create database [2026/01/12 20:20:32] [error] failed initialize input tail.0 [2026/01/12 20:20:32] [error] [engine] input initialization failed |
确保数据库文件所在的主机目录具有正确的读/写权限。更具体地说,主机目录应向非 root 用户授予读/写权限。默认数据库文件位置为 /var/log/,除非被 fluent-bit-dbFile agentconfiguration 选项覆盖。如果启用了 SELinux,请尝试将 fluent-bit-seLinuxOptionsType agentconfiguration 选项设置为 'spc_t' |
我看到来自 Telegraf 的类似于以下的错误消息,但 Telegraf 确实启动并运行:E! [inputs.kubernetes] 插件出错: https://<IP>>:<port>>/pods 返回 HTTP 状态 403 Forbidden |
如果您在低于 1.33 的 Kubernetes 版本上运行,则可能会出现这些消息。telegraf 使用的"nodes/pods" RBAC 资源在这些版本上不存在。有关旧版本所需的 RBAC 资源,请参阅 operator-additional-permissions.yaml 的"对于 Kubernetes 版本 < 1.33"部分。 |
更多信息可从"支持"页面或在"数据收集器支持矩阵"。