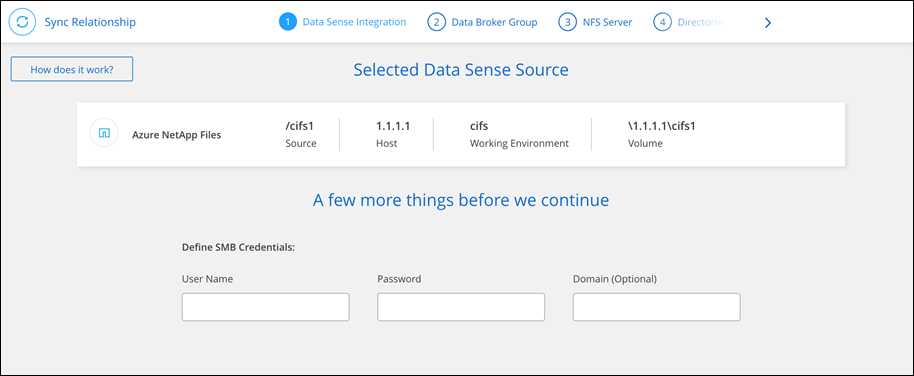
Erstellen Sie Synchronisierungsbeziehungen in NetApp Copy and Sync
 Änderungen vorschlagen
Änderungen vorschlagen
Wenn Sie eine Synchronisierungsbeziehung erstellen, NetApp Copy and Sync Dateien von der Quelle zum Ziel. Nach der ersten Kopie synchronisiert Copy and Sync alle geänderten Daten alle 24 Stunden.
Bevor Sie bestimmte Arten von Synchronisierungsbeziehungen erstellen können, müssen Sie zunächst ein System in der NetApp Console erstellen.
Erstellen Sie Synchronisierungsbeziehungen für bestimmte Systemtypen
Wenn Sie Synchronisierungsbeziehungen für eines der folgenden Elemente erstellen möchten, müssen Sie zuerst das System erstellen oder ermitteln:
-
Amazon FSx für ONTAP
-
Azure NetApp Files
-
Cloud Volumes ONTAP
-
On-Premise- ONTAP Cluster
-
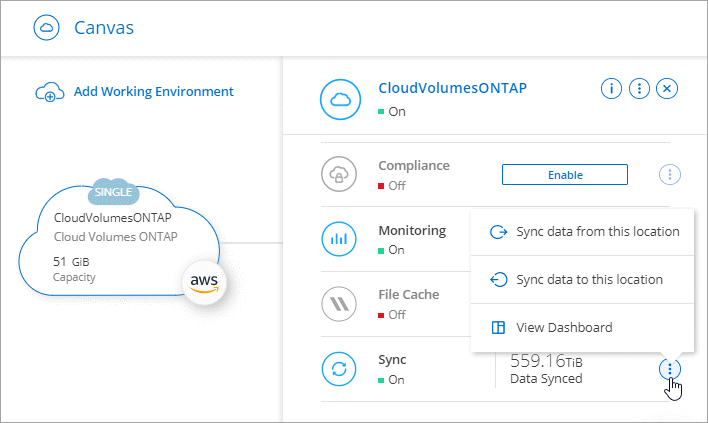
Erstellen oder entdecken Sie das System.
-
Wählen Sie Systemseite.
-
Wählen Sie ein System aus, das einem der oben aufgeführten Typen entspricht.
-
Wählen Sie das Aktionsmenü neben „Synchronisieren“ aus.
-
Wählen Sie Daten von diesem Ort synchronisieren oder Daten mit diesem Ort synchronisieren und folgen Sie den Anweisungen zum Einrichten der Synchronisierungsbeziehung.
Erstellen anderer Arten von Synchronisierungsbeziehungen
Verwenden Sie diese Schritte, um Daten mit einem anderen unterstützten Speichertyp als Amazon FSx for ONTAP, Azure NetApp Files, Cloud Volumes ONTAP oder lokalen ONTAP Clustern zu synchronisieren oder von diesem zu übertragen. Die folgenden Schritte stellen ein Beispiel dar, das zeigt, wie eine Synchronisierungsbeziehung von einem NFS-Server zu einem S3-Bucket eingerichtet wird.
-
Wählen Sie in der NetApp Console*Synchronisieren* aus.
-
Wählen Sie auf der Seite Synchronisierungsbeziehung definieren eine Quelle und ein Ziel aus.
Die folgenden Schritte bieten ein Beispiel für die Erstellung einer Synchronisierungsbeziehung von einem NFS-Server zu einem S3-Bucket.
-
Geben Sie auf der Seite NFS-Server die IP-Adresse oder den vollqualifizierten Domänennamen des NFS-Servers ein, den Sie mit AWS synchronisieren möchten.
-
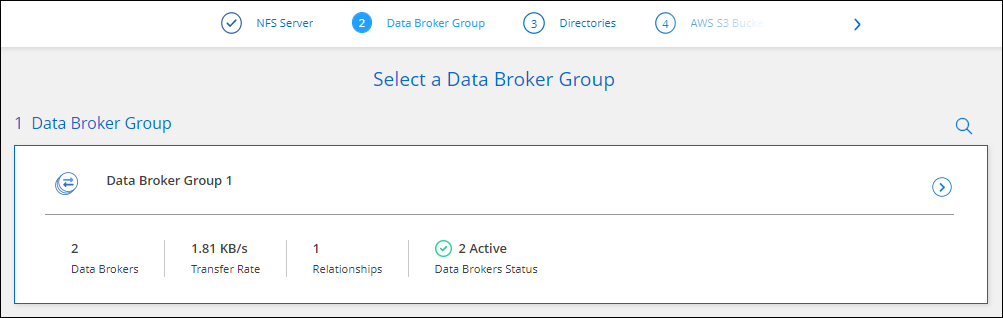
Folgen Sie auf der Seite Data Broker Group den Anweisungen zum Erstellen einer virtuellen Data Broker-Maschine in AWS, Azure oder Google Cloud Platform oder zum Installieren der Data Broker-Software auf einem vorhandenen Linux-Host.
Weitere Einzelheiten finden Sie auf den folgenden Seiten:
-
Wählen Sie nach der Installation des Datenbrokers Weiter.
-
Wählen Sie auf der Seite Verzeichnisse ein Verzeichnis der obersten Ebene oder ein Unterverzeichnis aus.
Wenn Copy and Sync die Exporte nicht abrufen kann, wählen Sie Export manuell hinzufügen und geben Sie den Namen eines NFS-Exports ein.

Wenn Sie mehr als ein Verzeichnis auf dem NFS-Server synchronisieren möchten, müssen Sie anschließend zusätzliche Synchronisierungsbeziehungen erstellen. -
Wählen Sie auf der Seite AWS S3 Bucket einen Bucket aus:
-
Führen Sie einen Drilldown durch, um einen vorhandenen Ordner im Bucket auszuwählen oder einen neuen Ordner auszuwählen, den Sie im Bucket erstellen.
-
Wählen Sie Zur Liste hinzufügen, um einen S3-Bucket auszuwählen, der nicht mit Ihrem AWS-Konto verknüpft ist. "Für den S3-Bucket müssen bestimmte Berechtigungen angewendet werden" .
-
-
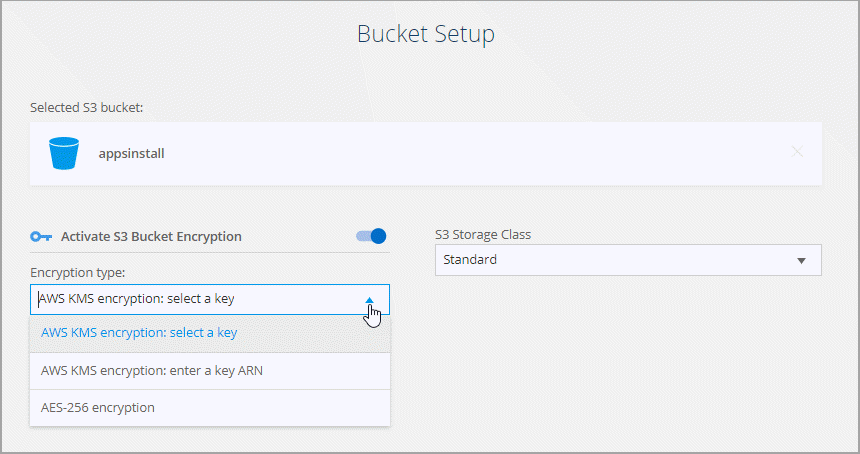
Richten Sie auf der Seite Bucket-Setup den Bucket ein:
-
Wählen Sie, ob die S3-Bucket-Verschlüsselung aktiviert werden soll, und wählen Sie dann einen AWS KMS-Schlüssel aus, geben Sie die ARN eines KMS-Schlüssels ein oder wählen Sie die AES-256-Verschlüsselung aus.
-
Wählen Sie eine S3-Speicherklasse aus. "Anzeigen der unterstützten Speicherklassen" .
-
-
Definieren Sie auf der Seite Einstellungen, wie Quelldateien und -ordner am Zielspeicherort synchronisiert und verwaltet werden:
- Zeitplan
-
Wählen Sie einen wiederkehrenden Zeitplan für zukünftige Synchronisierungen oder deaktivieren Sie den Synchronisierungszeitplan. Sie können eine Beziehung so planen, dass die Daten alle 1 Minute synchronisiert werden.
- Synchronisierungs-Timeout
-
Legen Sie fest, ob Copy and Sync eine Datensynchronisierung abbrechen soll, wenn die Synchronisierung nicht innerhalb der angegebenen Anzahl von Minuten, Stunden oder Tagen abgeschlossen ist.
- Benachrichtigungen
-
Ermöglicht Ihnen die Auswahl, ob Sie Kopier- und Synchronisierungsbenachrichtigungen im Benachrichtigungscenter der NetApp Konsole erhalten möchten. Sie können Benachrichtigungen für erfolgreiche, fehlgeschlagene und abgebrochene Datensynchronisierungen aktivieren.
- Wiederholungsversuche
-
Definieren Sie, wie oft Copy and Sync erneut versuchen soll, eine Datei zu synchronisieren, bevor sie übersprungen wird.
- Kontinuierliche Synchronisierung
-
Nach der ersten Datensynchronisierung überwacht Copy and Sync Änderungen am Quell-S3-Bucket oder Google Cloud Storage-Bucket und synchronisiert alle Änderungen kontinuierlich mit dem Ziel, sobald sie auftreten. Es ist nicht erforderlich, die Quelle in geplanten Intervallen erneut zu scannen.
Diese Einstellung ist nur verfügbar, wenn Sie eine Synchronisierungsbeziehung erstellen und wenn Sie Daten aus einem S3-Bucket oder Google Cloud Storage mit Azure Blob Storage, CIFS, Google Cloud Storage, IBM Cloud Object Storage, NFS, S3 und StorageGRID oder von Azure Blob Storage mit Azure Blob Storage, CIFS, Google Cloud Storage, IBM Cloud Object Storage, NFS und StorageGRID synchronisieren.
Wenn Sie diese Einstellung aktivieren, wirkt sich dies wie folgt auf andere Funktionen aus:
-
Der Synchronisierungszeitplan ist deaktiviert.
-
Die folgenden Einstellungen werden auf ihre Standardwerte zurückgesetzt: Synchronisierungszeitüberschreitung, Zuletzt geänderte Dateien und Änderungsdatum.
-
Wenn S3 die Quelle ist, ist die Filterung nach Größe nur bei Kopierereignissen aktiv (nicht bei Löschereignissen).
-
Nachdem die Beziehung erstellt wurde, können Sie sie nur beschleunigen oder löschen. Sie können Synchronisierungen nicht abbrechen, Einstellungen nicht ändern oder Berichte anzeigen.
Es ist möglich, eine Continuous Sync-Beziehung mit einem externen Bucket zu erstellen. Führen Sie dazu die folgenden Schritte aus:
-
Gehen Sie zur Google Cloud-Konsole für das Projekt des externen Buckets.
-
Gehen Sie zu Cloud-Speicher > Einstellungen > Cloud-Speicher-Dienstkonto.
-
Aktualisieren Sie die Datei local.json:
{ "protocols": { "gcp": { "storage-account-email": <storage account email> } } } -
Starten Sie den Datenbroker neu:
-
sudo pm2 alles stoppen
-
sudo pm2 starte alles
-
-
Erstellen Sie eine Continuous Sync-Beziehung mit dem entsprechenden externen Bucket.
Ein Datenbroker, der zum Erstellen einer kontinuierlichen Synchronisierungsbeziehung mit einem externen Bucket verwendet wird, kann keine weitere kontinuierliche Synchronisierungsbeziehung mit einem Bucket in seinem Projekt erstellen.
-
-
- Vergleichen nach
-
Wählen Sie, ob Copy and Sync bestimmte Attribute vergleichen soll, wenn festgestellt wird, ob sich eine Datei oder ein Verzeichnis geändert hat und erneut synchronisiert werden soll.
Auch wenn Sie diese Attribute deaktivieren, vergleicht Copy and Sync die Quelle dennoch mit dem Ziel, indem es die Pfade, Dateigrößen und Dateinamen überprüft. Wenn es Änderungen gibt, werden diese Dateien und Verzeichnisse synchronisiert.
Sie können den Vergleich der folgenden Attribute durch Kopieren und Synchronisieren aktivieren oder deaktivieren:
-
mtime: Die letzte Änderungszeit einer Datei. Dieses Attribut ist für Verzeichnisse nicht gültig.
-
uid, gid und mode: Berechtigungsflags für Linux.
-
- Kopieren für Objekte
-
Aktivieren Sie diese Option, um Metadaten und Tags des Objektspeichers zu kopieren. Wenn ein Benutzer die Metadaten der Quelle ändert, kopiert Copy and Sync dieses Objekt bei der nächsten Synchronisierung. Wenn ein Benutzer jedoch die Tags der Quelle ändert (und nicht die Daten selbst), kopiert Copy and Sync das Objekt bei der nächsten Synchronisierung nicht.
Sie können diese Option nicht mehr bearbeiten, nachdem Sie die Beziehung erstellt haben.
Das Kopieren von Tags wird mit Synchronisierungsbeziehungen unterstützt, die Azure Blob oder einen S3-kompatiblen Endpunkt (S3, StorageGRID oder IBM Cloud Object Storage) als Ziel enthalten.
Das Kopieren von Metadaten wird mit „Cloud-zu-Cloud“-Beziehungen zwischen den folgenden Endpunkten unterstützt:
-
AWS S3
-
Azure-Blob
-
Google Cloud-Speicher
-
IBM Cloud Object Storage
-
StorageGRID
-
- Kürzlich geänderte Dateien
-
Wählen Sie aus, ob Dateien ausgeschlossen werden sollen, die vor der geplanten Synchronisierung geändert wurden.
- Dateien auf der Quelle löschen
-
Wählen Sie, ob Dateien vom Quellspeicherort gelöscht werden sollen, nachdem Copy and Sync die Dateien an den Zielspeicherort kopiert hat. Bei dieser Option besteht das Risiko eines Datenverlusts, da die Quelldateien nach dem Kopieren gelöscht werden.
Wenn Sie diese Option aktivieren, müssen Sie auch einen Parameter in der Datei local.json auf dem Datenbroker ändern. Öffnen Sie die Datei und aktualisieren Sie sie wie folgt:
{ "workers":{ "transferrer":{ "delete-on-source": true } } }Nach der Aktualisierung der Datei local.json sollten Sie einen Neustart durchführen:
pm2 restart all. - Dateien auf dem Ziel löschen
-
Wählen Sie das Löschen von Dateien vom Zielspeicherort aus, wenn diese vom Quellspeicherort gelöscht wurden. Standardmäßig werden niemals Dateien vom Zielspeicherort gelöscht.
- Dateitypen
-
Definieren Sie die Dateitypen, die bei jeder Synchronisierung berücksichtigt werden sollen: Dateien, Verzeichnisse, symbolische Links und Hardlinks.
Hardlinks sind nur für ungesicherte NFS-zu-NFS-Beziehungen verfügbar. Benutzer sind auf einen Scanvorgang und eine Scanner-Parallelität beschränkt und Scans müssen von einem Stammverzeichnis aus ausgeführt werden. - Dateierweiterungen ausschließen
-
Geben Sie den regulären Ausdruck oder die Dateierweiterungen an, die von der Synchronisierung ausgeschlossen werden sollen, indem Sie die Dateierweiterung eingeben und die Eingabetaste drücken. Geben Sie beispielsweise log oder .log ein, um *.log-Dateien auszuschließen. Bei mehreren Erweiterungen ist kein Trennzeichen erforderlich. Das folgende Video bietet eine kurze Demo:
Dateierweiterungen für eine Synchronisierungsbeziehung ausschließen
Regex oder reguläre Ausdrücke unterscheiden sich von Platzhaltern oder Glob-Ausdrücken. Diese Funktion funktioniert nur mit regulären Ausdrücken. - Verzeichnisse ausschließen
-
Geben Sie maximal 15 reguläre Ausdrücke oder Verzeichnisse an, die von der Synchronisierung ausgeschlossen werden sollen, indem Sie deren Namen oder den vollständigen Verzeichnispfad eingeben und die Eingabetaste drücken. Die Verzeichnisse .copy-offload, .snapshot und ~snapshot sind standardmäßig ausgeschlossen.
Regex oder reguläre Ausdrücke unterscheiden sich von Platzhaltern oder Glob-Ausdrücken. Diese Funktion funktioniert nur mit regulären Ausdrücken. - Dateigröße
-
Wählen Sie, ob alle Dateien unabhängig von ihrer Größe oder nur Dateien in einem bestimmten Größenbereich synchronisiert werden sollen.
- Änderungsdatum
-
Wählen Sie alle Dateien unabhängig vom Datum der letzten Änderung, Dateien, die nach einem bestimmten Datum, vor einem bestimmten Datum oder innerhalb eines bestimmten Zeitraums geändert wurden.
- Erstellungsdatum
-
Wenn ein SMB-Server die Quelle ist, können Sie mit dieser Einstellung Dateien synchronisieren, die nach einem bestimmten Datum, vor einem bestimmten Datum oder innerhalb eines bestimmten Zeitraums erstellt wurden.
- ACL – Zugriffskontrollliste
-
Kopieren Sie nur ACLs, nur Dateien oder ACLs und Dateien von einem SMB-Server, indem Sie beim Erstellen einer Beziehung oder nach dem Erstellen einer Beziehung eine Einstellung aktivieren.
-
Wählen Sie auf der Seite Tags/Metadaten aus, ob ein Schlüssel-Wert-Paar als Tag für alle in den S3-Bucket übertragenen Dateien gespeichert oder allen Dateien ein Schlüssel-Wert-Paar für Metadaten zugewiesen werden soll.
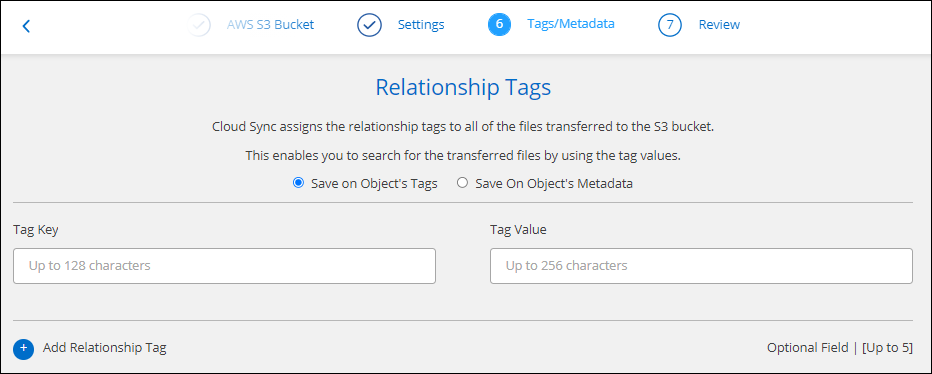

Dieselbe Funktion ist beim Synchronisieren von Daten mit StorageGRID und IBM Cloud Object Storage verfügbar. Für Azure und Google Cloud Storage ist nur die Metadatenoption verfügbar. -
Überprüfen Sie die Details der Synchronisierungsbeziehung und wählen Sie dann Beziehung erstellen.
Ergebnis
„Kopieren und Synchronisieren“ startet die Synchronisierung der Daten zwischen Quelle und Ziel. Es stehen Synchronisierungsstatistiken zur Verfügung, die Aufschluss darüber geben, wie lange die Synchronisierung gedauert hat, ob sie angehalten wurde und wie viele Dateien kopiert, gescannt oder gelöscht wurden. Sie können dann Ihre "Synchronisierungsbeziehungen" , "Verwalten Sie Ihre Datenbroker" , oder "Erstellen Sie Berichte zur Optimierung Ihrer Leistung und Konfiguration" .
Erstellen Sie Synchronisierungsbeziehungen aus der NetApp Data Classification
Copy and Sync ist in die NetApp Data Classification integriert. Innerhalb von NetApp Data Classification können Sie die Quelldateien auswählen, die Sie mithilfe von „Kopieren und Synchronisieren“ mit einem Zielspeicherort synchronisieren möchten.
Nachdem Sie eine Datensynchronisierung von NetApp Data Classification initiiert haben, sind alle Quellinformationen in einem einzigen Schritt enthalten und Sie müssen nur einige wichtige Details eingeben. Anschließend wählen Sie den Zielort für die neue Synchronisierungsbeziehung.