

Suddivisione dei dati in livelli dai cluster ONTAP locali ad Amazon S3 in NetApp Cloud Tiering
 Suggerisci modifiche
Suggerisci modifiche
Libera spazio sui tuoi cluster ONTAP locali suddividendo i dati inattivi in Amazon S3 in NetApp Cloud Tiering.
Avvio rapido
Inizia subito seguendo questi passaggi. I dettagli per ogni passaggio sono forniti nelle sezioni seguenti di questo argomento.
 Identifica il metodo di configurazione che utilizzerai
Identifica il metodo di configurazione che utilizzeraiScegli se connettere il tuo cluster ONTAP locale direttamente ad AWS S3 tramite Internet pubblico oppure se utilizzare una VPN o AWS Direct Connect e instradare il traffico tramite un'interfaccia VPC Endpoint privata ad AWS S3.
 Prepara il tuo agente console
Prepara il tuo agente consoleSe hai già distribuito l'agente della console nella tua AWS VPC o in sede, sei a posto. In caso contrario, sarà necessario creare l'agente per suddividere i dati ONTAP nello storage AWS S3. Sarà inoltre necessario personalizzare le impostazioni di rete dell'agente in modo che possa connettersi ad AWS S3.
 Prepara il tuo cluster ONTAP on-premise
Prepara il tuo cluster ONTAP on-premiseScopri il tuo cluster ONTAP nella NetApp Console, verifica che il cluster soddisfi i requisiti minimi e personalizza le impostazioni di rete in modo che il cluster possa connettersi ad AWS S3.
 Prepara Amazon S3 come destinazione del tuo tiering
Prepara Amazon S3 come destinazione del tuo tieringImposta le autorizzazioni per l'agente per creare e gestire il bucket S3. Sarà inoltre necessario impostare le autorizzazioni per il cluster ONTAP locale in modo che possa leggere e scrivere dati nel bucket S3.
 Abilita Cloud Tiering sul sistema
Abilita Cloud Tiering sul sistemaSelezionare un sistema locale, selezionare Abilita per il servizio Cloud Tiering e seguire le istruzioni per suddividere i dati in livelli su Amazon S3.
 Impostare la licenza
Impostare la licenzaAl termine del periodo di prova gratuito, puoi pagare Cloud Tiering tramite un abbonamento pay-as-you-go, una licenza BYOL ONTAP Cloud Tiering o una combinazione di entrambi:
-
Per abbonarsi ad AWS Marketplace, "vai all'offerta Marketplace" , seleziona Iscriviti e segui le istruzioni.
-
Per pagare utilizzando una licenza Cloud Tiering BYOL, contattaci se devi acquistarne una, quindi"aggiungilo alla NetApp Console" .
Diagrammi di rete per le opzioni di connessione
Sono disponibili due metodi di connessione che è possibile utilizzare quando si configura la suddivisione in livelli dai sistemi ONTAP locali ad AWS S3.
-
Connessione pubblica: collega direttamente il sistema ONTAP ad AWS S3 utilizzando un endpoint S3 pubblico.
-
Connessione privata: utilizza una VPN o AWS Direct Connect e instrada il traffico tramite un'interfaccia VPC Endpoint che utilizza un indirizzo IP privato.
Il diagramma seguente mostra il metodo di connessione pubblica e le connessioni che è necessario preparare tra i componenti. Puoi utilizzare l'agente della console installato in sede oppure un agente distribuito nella VPC AWS.
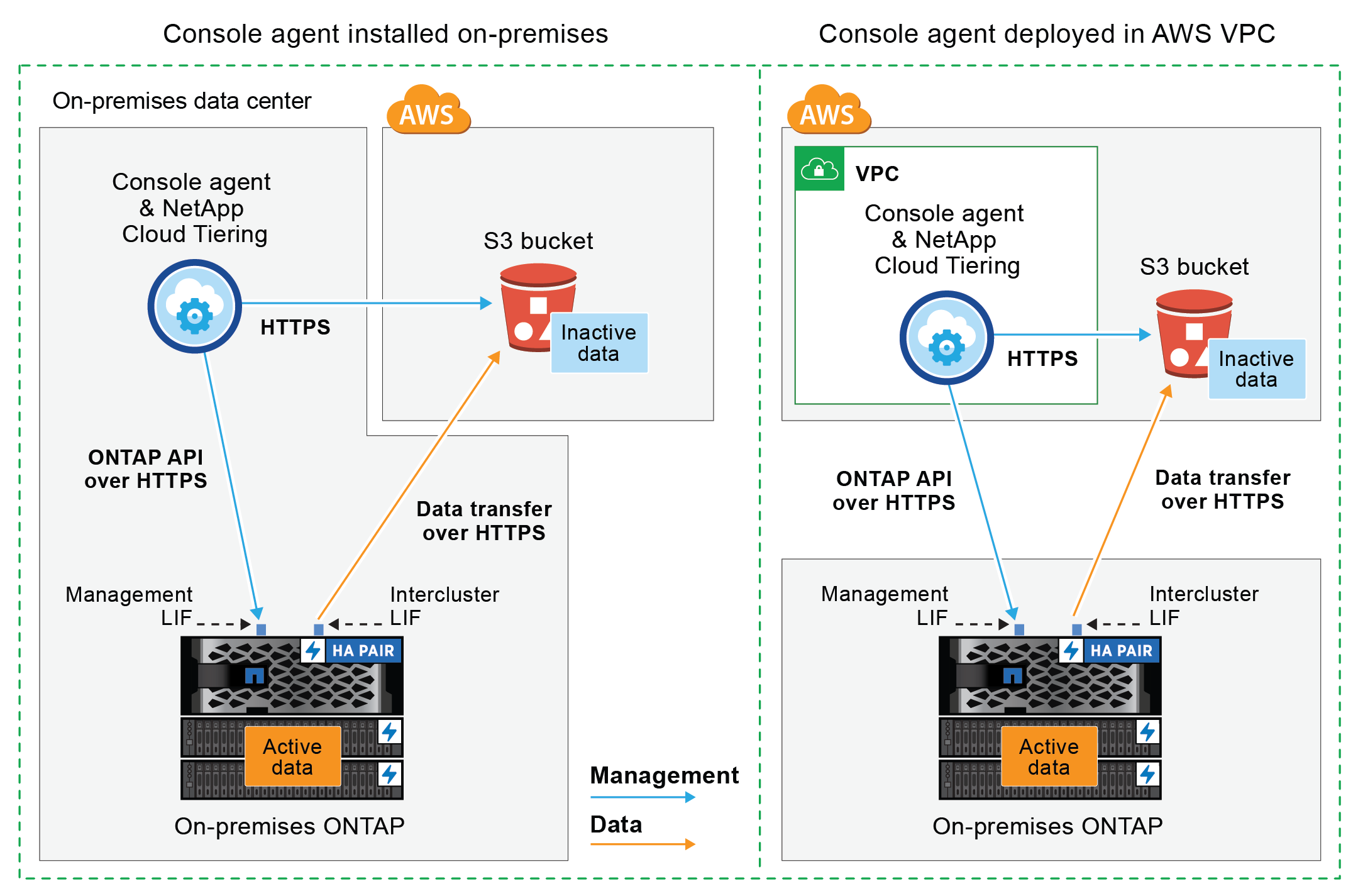
Il diagramma seguente mostra il metodo di connessione privata e le connessioni che è necessario preparare tra i componenti. Puoi utilizzare l'agente della console installato in sede oppure un agente distribuito nella VPC AWS.
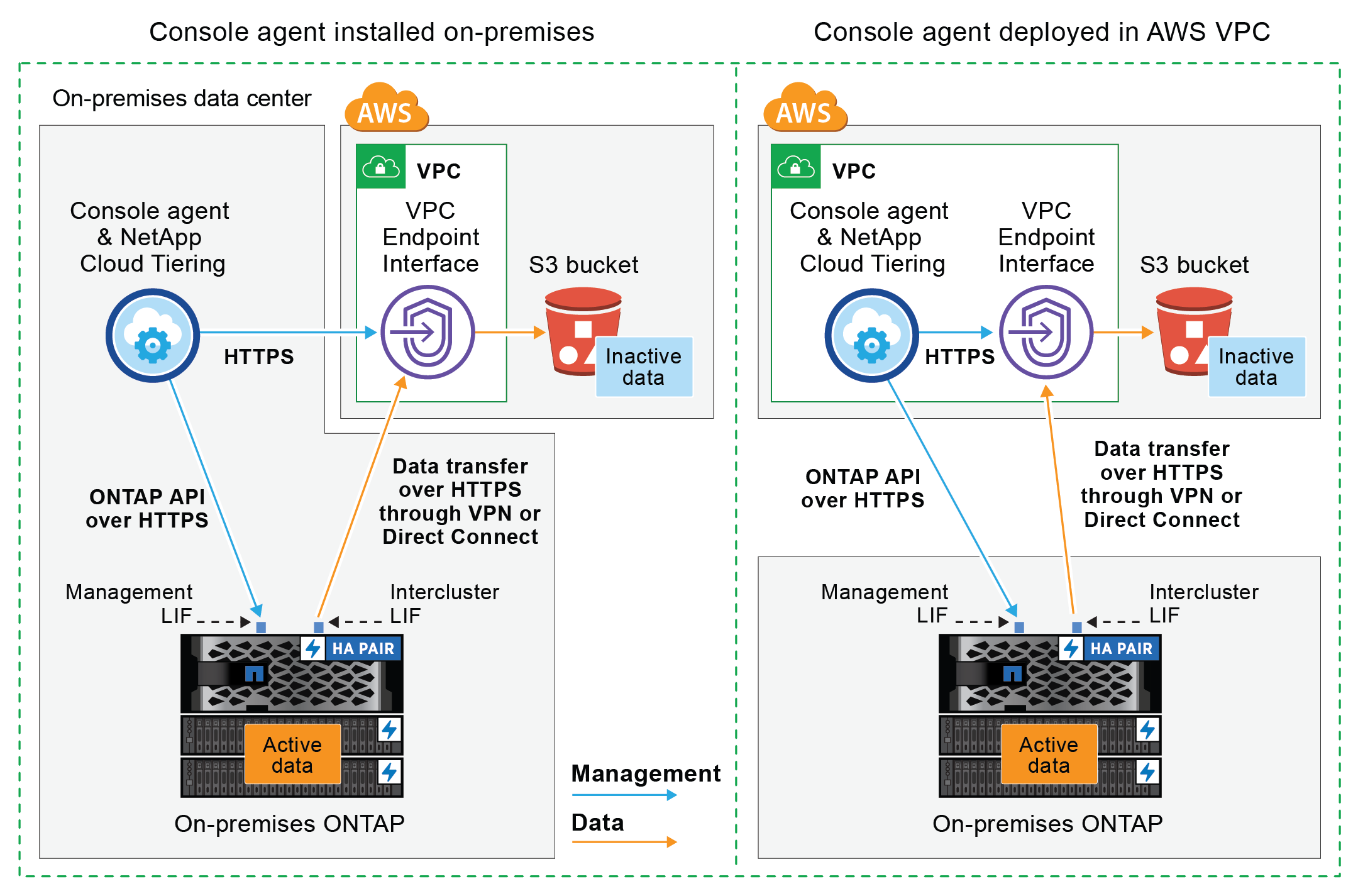

|
La comunicazione tra un agente e S3 è riservata esclusivamente alla configurazione dell'archiviazione degli oggetti. |
Prepara il tuo agente Console
L'agente abilita le funzionalità di suddivisione in livelli dalla NetApp Console. È necessario un agente per suddividere in livelli i dati ONTAP inattivi.
Crea o cambia agenti
Se hai già un agente distribuito nella tua AWS VPC o in sede, sei a posto. In caso contrario, sarà necessario creare un agente in una di queste posizioni per suddividere i dati ONTAP nello storage AWS S3. Non è possibile utilizzare un agente distribuito presso un altro provider cloud.
Requisiti di rete degli agenti
-
Assicurarsi che la rete in cui è installato l'agente consenta le seguenti connessioni:
-
Una connessione HTTPS sulla porta 443 al servizio Cloud Tiering e al tuo archivio oggetti S3("vedere l'elenco degli endpoint" )
-
Una connessione HTTPS sulla porta 443 al LIF di gestione del cluster ONTAP
-
-
"Assicurarsi che l'agente disponga delle autorizzazioni per gestire il bucket S3"
-
Se disponi di una connessione Direct Connect o VPN dal tuo cluster ONTAP alla VPC e desideri che la comunicazione tra l'agente e S3 rimanga nella tua rete interna AWS (una connessione privata), dovrai abilitare un'interfaccia VPC Endpoint per S3.Scopri come configurare un'interfaccia endpoint VPC.
Prepara il tuo cluster ONTAP
I cluster ONTAP devono soddisfare i seguenti requisiti quando si suddividono i dati in livelli su Amazon S3.
Requisiti ONTAP
- Piattaforme ONTAP supportate
-
-
Quando si utilizza ONTAP 9.8 e versioni successive: è possibile suddividere i dati dai sistemi AFF o dai sistemi FAS con aggregati tutti SSD o tutti HDD.
-
Quando si utilizza ONTAP 9.7 e versioni precedenti: è possibile suddividere in livelli i dati provenienti da sistemi AFF o sistemi FAS con aggregati completamente SSD.
-
- Versioni ONTAP supportate
-
-
ONTAP 9.2 o successivo
-
Se si prevede di utilizzare una connessione AWS PrivateLink per l'archiviazione di oggetti, è necessario ONTAP 9.7 o versione successiva.
-
- Volumi e aggregati supportati
-
Il numero totale di volumi che Cloud Tiering può suddividere in livelli potrebbe essere inferiore al numero di volumi presenti nel sistema ONTAP . Questo perché i volumi non possono essere suddivisi in livelli da alcuni aggregati. Fare riferimento alla documentazione ONTAP per "funzionalità o caratteristiche non supportate da FabricPool" .
|
|
Cloud Tiering supporta i volumi FlexGroup a partire da ONTAP 9.5. L'installazione funziona come per qualsiasi altro volume. |
Requisiti di rete del cluster
-
Il cluster richiede una connessione HTTPS in ingresso dall'agente della console al LIF di gestione del cluster.
Non è richiesta una connessione tra il cluster e Cloud Tiering.
-
È necessario un LIF intercluster su ciascun nodo ONTAP che ospita i volumi che si desidera suddividere in livelli. Questi LIF intercluster devono essere in grado di accedere all'archivio oggetti.
Il cluster avvia una connessione HTTPS in uscita tramite la porta 443 dai LIF intercluster allo storage Amazon S3 per le operazioni di suddivisione in livelli. ONTAP legge e scrive dati da e verso l'archiviazione di oggetti: l'archiviazione di oggetti non si avvia mai, si limita a rispondere.
-
I LIF intercluster devono essere associati allo IPspace che ONTAP deve utilizzare per connettersi all'archiviazione degli oggetti. "Scopri di più su IPspaces" .
Quando si imposta Cloud Tiering, viene richiesto di specificare lo spazio IP da utilizzare. Dovresti scegliere lo spazio IP a cui sono associati questi LIF. Potrebbe trattarsi dello spazio IP "predefinito" o di uno spazio IP personalizzato creato da te.
Se si utilizza uno spazio IP diverso da "Default", potrebbe essere necessario creare un percorso statico per accedere all'archiviazione degli oggetti.
Tutti i LIF intercluster all'interno dell'IPspace devono avere accesso all'archivio oggetti. Se non è possibile configurarlo per l'IPspace corrente, sarà necessario creare un IPspace dedicato in cui tutti i LIF intercluster abbiano accesso all'archivio oggetti.
-
Se si utilizza un endpoint di interfaccia VPC privata in AWS per la connessione S3, affinché venga utilizzato HTTPS/443 sarà necessario caricare il certificato dell'endpoint S3 nel cluster ONTAP .Scopri come configurare un'interfaccia endpoint VPC e caricare il certificato S3.
-
Assicurati che il tuo cluster ONTAP disponga delle autorizzazioni per accedere al bucket S3.
Scopri il tuo cluster ONTAP nella NetApp Console
È necessario individuare il cluster ONTAP locale nella NetApp Console prima di poter iniziare a suddividere i dati inattivi nell'archiviazione di oggetti. Per aggiungere il cluster, è necessario conoscere l'indirizzo IP di gestione del cluster e la password dell'account utente amministratore.
Prepara il tuo ambiente AWS
Quando si imposta la suddivisione in livelli dei dati per un nuovo cluster, viene chiesto se si desidera che il servizio crei un bucket S3 o se si desidera selezionare un bucket S3 esistente nell'account AWS in cui è configurato l'agente. L'account AWS deve disporre di autorizzazioni e di una chiave di accesso che è possibile immettere in Cloud Tiering. Il cluster ONTAP utilizza la chiave di accesso per suddividere i dati in livelli da e verso S3.
Per impostazione predefinita, il tiering nel cloud crea il bucket per te. Se desideri utilizzare un tuo bucket, puoi crearne uno prima di avviare la procedura guidata di attivazione dei livelli e quindi selezionare tale bucket nella procedura guidata. "Scopri come creare bucket S3 dalla NetApp Console" . Il bucket deve essere utilizzato esclusivamente per archiviare dati inattivi dai volumi e non può essere utilizzato per altri scopi. Il bucket S3 deve essere in un"regione che supporta Cloud Tiering" .
|
|
Se intendi configurare Cloud Tiering per utilizzare una classe di archiviazione a costi inferiori in cui i tuoi dati suddivisi in livelli verranno trasferiti dopo un certo numero di giorni, non devi selezionare alcuna regola del ciclo di vita quando configuri il bucket nel tuo account AWS. Cloud Tiering gestisce le transizioni del ciclo di vita. |
Imposta le autorizzazioni S3
Sarà necessario configurare due set di autorizzazioni:
-
Autorizzazioni per l'agente affinché possa creare e gestire il bucket S3.
-
Autorizzazioni per il cluster ONTAP locale in modo che possa leggere e scrivere dati nel bucket S3.
-
Autorizzazioni dell'agente della console:
-
Conferma che "queste autorizzazioni S3" fanno parte del ruolo IAM che fornisce all'agente le autorizzazioni. Avrebbero dovuto essere inclusi per impostazione predefinita quando hai distribuito per la prima volta l'agente. In caso contrario, sarà necessario aggiungere eventuali autorizzazioni mancanti. Vedi il "Documentazione AWS: modifica delle policy IAM" per istruzioni.
-
Il bucket predefinito creato da Cloud Tiering ha il prefisso "fabric-pool". Se vuoi usare un prefisso diverso per il tuo bucket, dovrai personalizzare le autorizzazioni con il nome che desideri usare. Nelle autorizzazioni S3 vedrai una riga
"Resource": ["arn:aws:s3:::fabric-pool*"]. Dovrai modificare "fabric-pool" con il prefisso che desideri utilizzare. Ad esempio, se vuoi usare "tiering-1" come prefisso per i tuoi bucket, cambierai questa riga in"Resource": ["arn:aws:s3:::tiering-1*"].Se si desidera utilizzare un prefisso diverso per i bucket che verranno utilizzati per cluster aggiuntivi nella stessa organizzazione NetApp Console , è possibile aggiungere un'altra riga con il prefisso per gli altri bucket. Per esempio:
"Resource": ["arn:aws:s3:::tiering-1*"]
"Resource": ["arn:aws:s3:::tiering-2*"]
Se stai creando il tuo bucket e non usi un prefisso standard, dovresti modificare questa riga in
"Resource": ["arn:aws:s3:::*"]in modo che qualsiasi bucket venga riconosciuto. Tuttavia, ciò potrebbe esporre tutti i bucket anziché quelli progettati per contenere dati inattivi dai volumi. -
-
Autorizzazioni cluster:
-
Quando attivi il servizio, la procedura guidata di suddivisione in livelli ti chiederà di immettere una chiave di accesso e una chiave segreta. Queste credenziali vengono trasmesse al cluster ONTAP in modo che ONTAP possa suddividere i dati nel bucket S3. Per farlo, dovrai creare un utente IAM con le seguenti autorizzazioni:
"s3:ListAllMyBuckets", "s3:ListBucket", "s3:GetBucketLocation", "s3:GetObject", "s3:PutObject", "s3:DeleteObject"Vedi il "Documentazione AWS: creazione di un ruolo per delegare le autorizzazioni a un utente IAM" per i dettagli.
-
-
Creare o individuare la chiave di accesso.
Cloud Tiering passa la chiave di accesso al cluster ONTAP . Le credenziali non vengono archiviate nel servizio Cloud Tiering.
Configura il tuo sistema per una connessione privata utilizzando un'interfaccia endpoint VPC
Se si prevede di utilizzare una connessione Internet pubblica standard, tutte le autorizzazioni vengono impostate dall'agente e non è necessario fare altro. Questo tipo di connessione è mostrato inprimo diagramma sopra .
Se desideri una connessione Internet più sicura dal tuo data center locale alla VPC, puoi selezionare una connessione AWS PrivateLink nella procedura guidata di attivazione del Tiering. È obbligatorio se si prevede di utilizzare una VPN o AWS Direct Connect per connettere il sistema locale tramite un'interfaccia VPC Endpoint che utilizza un indirizzo IP privato. Questo tipo di connessione è mostrato nelsecondo diagramma sopra .
-
Crea una configurazione dell'endpoint dell'interfaccia utilizzando la console Amazon VPC o la riga di comando. "Visualizza i dettagli sull'utilizzo di AWS PrivateLink per Amazon S3" .
-
Modificare la configurazione del gruppo di sicurezza associato all'agente. Devi modificare la policy in "Personalizzata" (da "Accesso completo") e deviaggiungere le autorizzazioni richieste per l'agente S3 come mostrato in precedenza.
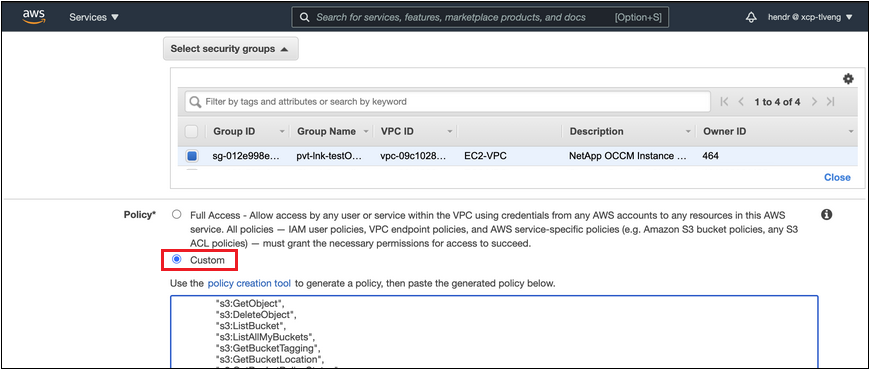
Se si utilizza la porta 80 (HTTP) per la comunicazione con l'endpoint privato, il problema è risolto. Ora puoi abilitare Cloud Tiering sul cluster.
Se si utilizza la porta 443 (HTTPS) per la comunicazione con l'endpoint privato, è necessario copiare il certificato dall'endpoint VPC S3 e aggiungerlo al cluster ONTAP , come mostrato nei 4 passaggi successivi.
-
Ottieni il nome DNS dell'endpoint dalla console AWS.
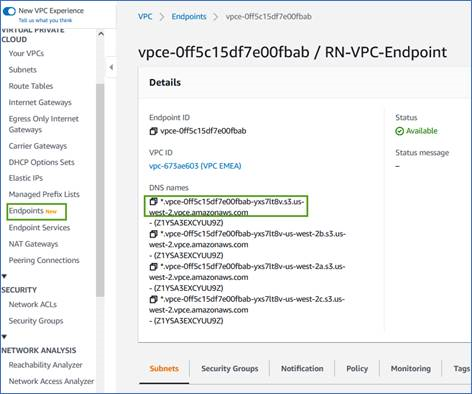
-
Ottieni il certificato dall'endpoint VPC S3. Lo fai tramite "accedendo alla VM che ospita l'agente" ed eseguendo il seguente comando. Quando si immette il nome DNS dell'endpoint, aggiungere "bucket" all'inizio, sostituendo "*":
[ec2-user@ip-10-160-4-68 ~]$ openssl s_client -connect bucket.vpce-0ff5c15df7e00fbab-yxs7lt8v.s3.us-west-2.vpce.amazonaws.com:443 -showcerts -
Dall'output di questo comando, copiare i dati per il certificato S3 (tutti i dati compresi tra i tag BEGIN / END CERTIFICATE inclusi):
Certificate chain 0 s:/CN=s3.us-west-2.amazonaws.com` i:/C=US/O=Amazon/OU=Server CA 1B/CN=Amazon -----BEGIN CERTIFICATE----- MIIM6zCCC9OgAwIBAgIQA7MGJ4FaDBR8uL0KR3oltTANBgkqhkiG9w0BAQsFADBG … … GqvbOz/oO2NWLLFCqI+xmkLcMiPrZy+/6Af+HH2mLCM4EsI2b+IpBmPkriWnnxo= -----END CERTIFICATE----- -
Accedi alla CLI del cluster ONTAP e applica il certificato copiato utilizzando il seguente comando (sostituisci il nome della tua VM di archiviazione):
cluster1::> security certificate install -vserver <svm_name> -type server-ca Please enter Certificate: Press <Enter> when done
Suddividi i dati inattivi dal tuo primo cluster ad Amazon S3
Dopo aver preparato l'ambiente AWS, inizia a suddividere in livelli i dati inattivi dal tuo primo cluster.
-
Una chiave di accesso AWS per un utente IAM che dispone delle autorizzazioni S3 richieste.
-
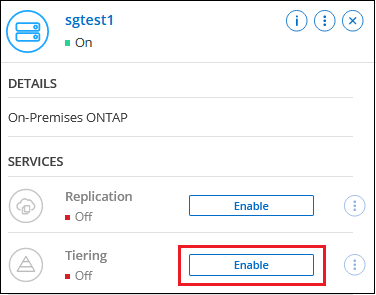
Selezionare il sistema ONTAP locale.
-
Fare clic su Abilita per Cloud Tiering dal pannello di destra.
Se la destinazione di tiering Amazon S3 esiste come sistema nella pagina Sistemi, è possibile trascinare il cluster sul sistema per avviare la procedura guidata di configurazione.
-
Definisci nome archivio oggetti: inserisci un nome per questo archivio oggetti. Deve essere univoco rispetto a qualsiasi altro archivio di oggetti che potresti utilizzare con gli aggregati su questo cluster.
-
Seleziona fornitore: seleziona Amazon Web Services e seleziona Continua.
-
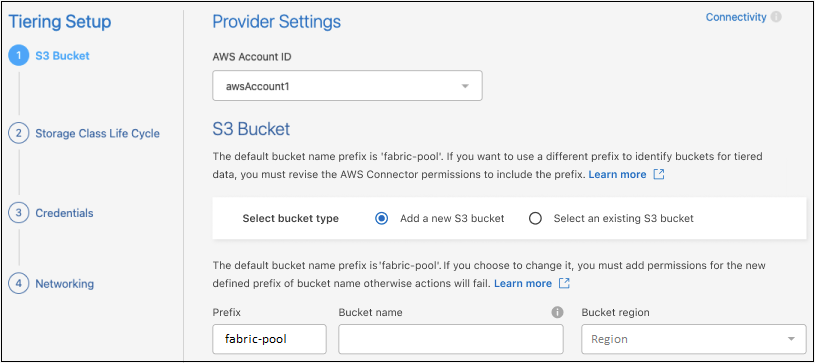
Completare le sezioni nella pagina Impostazione livelli:
-
S3 Bucket: aggiungi un nuovo bucket S3 o seleziona un bucket S3 esistente, seleziona la regione del bucket e seleziona Continua.
Quando si utilizza un agente locale, è necessario immettere l'ID dell'account AWS che fornisce l'accesso al bucket S3 esistente o al nuovo bucket S3 che verrà creato.
Il prefisso fabric-pool viene utilizzato per impostazione predefinita perché il criterio IAM per l'agente consente all'istanza di eseguire azioni S3 sui bucket denominati con quel prefisso esatto. Ad esempio, è possibile denominare il bucket S3 fabric-pool-AFF1, dove AFF1 è il nome del cluster. È possibile definire anche il prefisso per i bucket utilizzati per la suddivisione in livelli. Vedereimpostazione delle autorizzazioni S3 per assicurarti di disporre delle autorizzazioni AWS che riconoscono qualsiasi prefisso personalizzato che intendi utilizzare.
-
Classe di archiviazione: Cloud Tiering gestisce le transizioni del ciclo di vita dei dati suddivisi in livelli. I dati iniziano nella classe Standard, ma è possibile creare una regola per applicare una classe di archiviazione diversa ai dati dopo un certo numero di giorni.
Selezionare la classe di archiviazione S3 in cui si desidera trasferire i dati a livelli e il numero di giorni prima che i dati vengano assegnati a tale classe, quindi selezionare Continua. Ad esempio, lo screenshot seguente mostra che i dati a livelli vengono assegnati alla classe Standard-IA dalla classe Standard dopo 45 giorni nell'archiviazione degli oggetti.
Se si sceglie Mantieni i dati in questa classe di archiviazione, i dati rimangono nella classe di archiviazione Standard e non vengono applicate regole. "Visualizza le classi di archiviazione supportate".
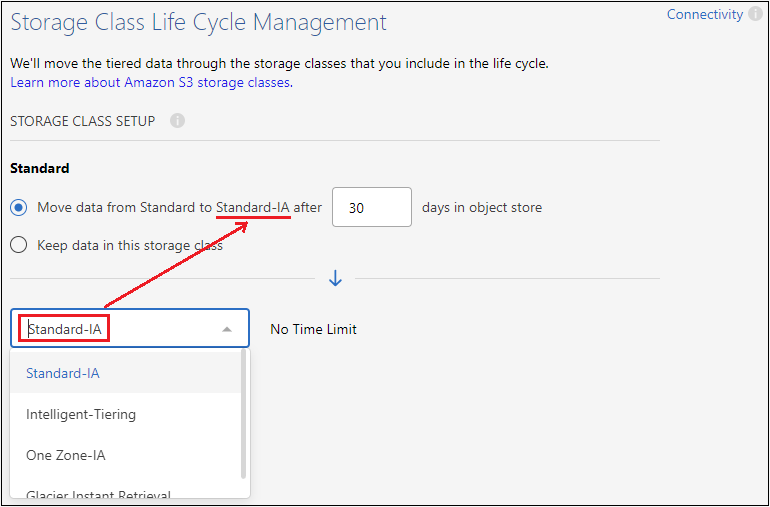
Si noti che la regola del ciclo di vita viene applicata a tutti gli oggetti nel bucket selezionato.
-
Credenziali: immettere l'ID della chiave di accesso e la chiave segreta per un utente IAM che dispone delle autorizzazioni S3 richieste e selezionare Continua.
L'utente IAM deve trovarsi nello stesso account AWS del bucket selezionato o creato nella pagina S3 Bucket.
-
Networking: inserisci i dettagli di rete e seleziona Continua.
Selezionare lo spazio IP nel cluster ONTAP in cui risiedono i volumi che si desidera suddividere in livelli. I LIF intercluster per questo spazio IP devono avere accesso a Internet in uscita per potersi connettere allo storage di oggetti del tuo provider cloud.
Facoltativamente, scegli se utilizzerai un AWS PrivateLink precedentemente configurato. Vedere le informazioni di configurazione sopra. Viene visualizzata una finestra di dialogo che ti guiderà nella configurazione dell'endpoint.
È anche possibile impostare la larghezza di banda di rete disponibile per caricare dati inattivi nell'archiviazione degli oggetti definendo la "Velocità di trasferimento massima". Selezionare il pulsante di opzione Limitato e immettere la larghezza di banda massima utilizzabile, oppure selezionare Illimitato per indicare che non vi è alcun limite.
-
-
Nella pagina Volumi a livelli, seleziona i volumi per i quali desideri configurare la suddivisione in livelli e avvia la pagina Criteri di suddivisione in livelli:
-
Per selezionare tutti i volumi, seleziona la casella nella riga del titolo (
 ) e seleziona Configura volumi.
) e seleziona Configura volumi. -
Per selezionare più volumi, seleziona la casella per ogni volume (
 ) e seleziona Configura volumi.
) e seleziona Configura volumi. -
Per selezionare un singolo volume, selezionare la riga (o
 icona) per il volume.
icona) per il volume.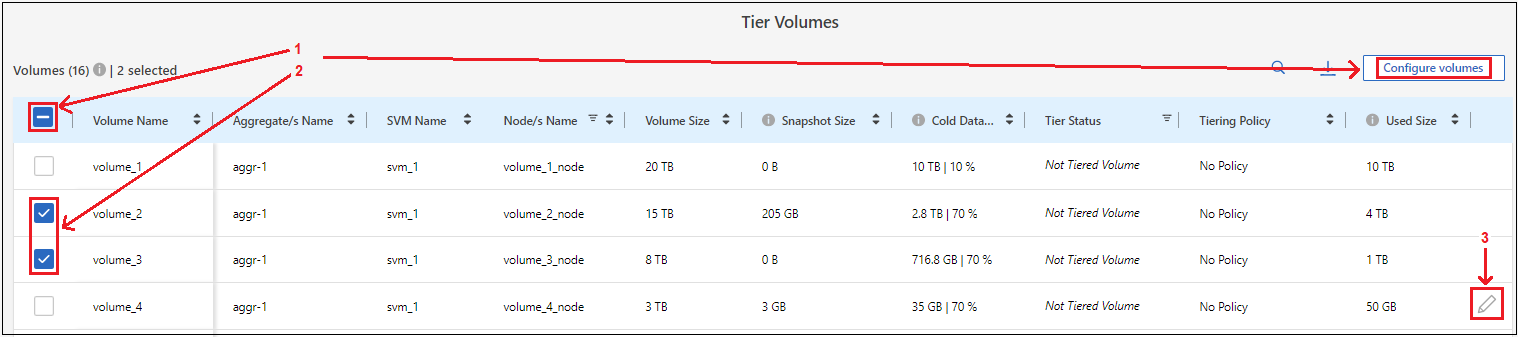
-
-
Nella finestra di dialogo Criterio di suddivisione in livelli, seleziona un criterio di suddivisione in livelli, modifica facoltativamente i giorni di raffreddamento per i volumi selezionati e seleziona Applica.
"Scopri di più sulle politiche di suddivisione in livelli di volume e sui giorni di raffreddamento".
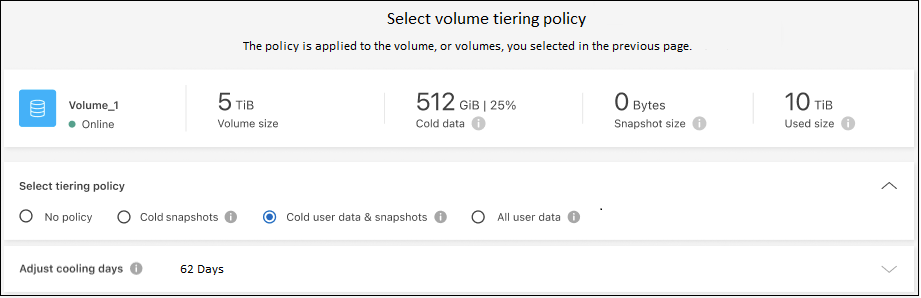
Hai configurato correttamente la suddivisione in livelli dei dati dai volumi sul cluster all'archiviazione di oggetti S3.
È possibile esaminare le informazioni sui dati attivi e inattivi del cluster. "Scopri di più sulla gestione delle impostazioni di suddivisione in livelli".
È anche possibile creare un archivio di oggetti aggiuntivo nei casi in cui si desideri suddividere i dati da determinati aggregati su un cluster in archivi di oggetti diversi. Oppure se si prevede di utilizzare FabricPool Mirroring, in cui i dati a livelli vengono replicati in un archivio oggetti aggiuntivo. "Scopri di più sulla gestione degli archivi di oggetti".