

Installa NetApp Data Classification su un host Linux senza accesso a Internet
 Suggerisci modifiche
Suggerisci modifiche
L'installazione di NetApp Data Classification su un host Linux in un sito locale che non dispone di accesso a Internet è nota come modalità privata. Questo tipo di installazione, che utilizza uno script di installazione, non ha connettività con il livello SaaS NetApp Console .

|
Per le implementazioni VMware on-premises vSphere, NetApp Data Classification supporta una versione semplificata "implementazione con OVA". |
Lo script di installazione di Data Classification inizia verificando se il sistema e l'ambiente soddisfano i prerequisiti richiesti. Se tutti i prerequisiti sono soddisfatti, l'installazione avrà inizio. Se si desidera verificare i prerequisiti indipendentemente dall'esecuzione dell'installazione di Data Classification, è possibile scaricare un pacchetto software separato che verifica solo i prerequisiti. "Scopri come verificare se il tuo host Linux è pronto per installare Data Classification" .
Fonti dati supportate
Quando è installata la modalità privata (talvolta chiamata "offline" o sito "dark"), Data Classification può analizzare solo i dati provenienti da fonti dati che sono anch'esse locali rispetto al sito on-premises. Al momento, Data Classification può analizzare le seguenti fonti dati locali:
-
Sistemi ONTAP on-premise
-
Schemi di database
Al momento non è disponibile alcun supporto per la scansione di Cloud Volumes ONTAP, Azure NetApp Files o FSx for ONTAP accounts quando la classificazione dei dati viene distribuita in modalità privata.
Limitazioni
La maggior parte delle funzionalità di Data Classification funziona quando viene distribuita in un sito senza accesso a Internet. Tuttavia, alcune funzionalità che richiedono l'accesso a Internet non sono supportate, ad esempio:
-
Impostazione dei ruoli della Console per utenti diversi (ad esempio, Account Admin o Compliance Viewer)
-
Copia e sincronizzazione dei file sorgente utilizzando NetApp Copy and Sync
-
Aggiornamenti software automatizzati dalla Console
Sia l'agente Console che Data Classification richiedono aggiornamenti manuali periodici per abilitare nuove funzionalità. Puoi vedere la versione di Data Classification in fondo alle pagine dell'interfaccia utente di Data Classification. Controlla il "Note sulla versione di Data Classification" per vedere le nuove funzionalità di ogni versione e se desideri tali funzionalità. Quindi puoi seguire i passaggi per "aggiornare l'agente Console" e aggiorna il tuo software di Data Classification.
Avvio rapido
Inizia subito seguendo questi passaggi oppure scorri verso il basso fino alle sezioni rimanenti per i dettagli completi.
 Installa l'agente Console
Installa l'agente ConsoleSe non hai ancora installato un agente Console in modalità privata, "distribuire l'agente Console" su un host Linux ora.
 Rivedere i prerequisiti per la classificazione dei dati
Rivedere i prerequisiti per la classificazione dei datiAssicurati che il tuo sistema Linux soddisfi i requisiti dell'host requisiti, che abbia installato tutto il software richiesto e che il tuo ambiente offline soddisfi i permessi e connettività requisiti.
 Scarica e distribuisci la classificazione dei dati
Scarica e distribuisci la classificazione dei datiScarica il software Data Classification dal NetApp Support Site e copia il file di installazione sull'host Linux che intendi utilizzare. Quindi avvia la procedura guidata di installazione e segui le istruzioni per distribuire l'istanza di Data Classification.
Installa l'agente Console
Se non hai già installato un agente Console in modalità privata, "distribuire l'agente Console" su un host Linux nel tuo sito offline.
Preparare il sistema host Linux
Il software Data Classification deve essere eseguito su un host che soddisfi specifici requisiti del sistema operativo, requisiti di RAM, requisiti software e così via.
-
La classificazione dei dati deve avvenire su un host dedicato. L'host non può essere condiviso con altre applicazioni o software di terze parti, come gli antivirus.
-
Scegli la dimensione più adatta al set di dati che intendi analizzare con Data Classification.
Dimensioni del sistema processore RAM (la memoria di swap deve essere disabilitata) Disco Extra Large
32 CPU
128 GB di RAM
-
SSD da 1 TiB su /, oppure 100 GiB disponibili su /opt
-
895 GiB disponibili su /var/lib/docker
-
5 GiB su /tmp
-
Per Podman, 30 GB su /var/tmp
Grande
16 CPU
64 GB di RAM
-
SSD da 500 GiB su /, oppure 100 GiB disponibili su /opt
-
400 GiB disponibili su /var/lib/docker o per Podman /var/lib/containers
-
5 GiB su /tmp
-
Per Podman, 30 GB su /var/tmp
-
-
Quando si distribuisce un'istanza di elaborazione nel cloud per l'installazione di Data Classification, si consiglia di utilizzare un sistema che soddisfi i requisiti di sistema "Large" sopra indicati:
-
Tipo di istanza Amazon Elastic Compute Cloud (Amazon EC2): "m6i.4xlarge". "Vedi altri tipi di istanze AWS" .
-
Dimensioni della macchina virtuale Azure: "Standard_D16_v5". "Visualizza altri tipi di istanze di Azure".
-
Tipo di macchina GCP: "n2-standard-16". "Vedi altri tipi di istanza GCP" .
-
-
Autorizzazioni cartella UNIX: sono richieste le seguenti autorizzazioni UNIX minime:
Cartella Permessi minimi /tmp
rwxrwxrwt/optare
rwxr-xr-x/var/lib/docker
rwx------/usr/lib/systemd/sistema
rwxr-xr-x -
Sistema operativo:
-
I seguenti sistemi operativi richiedono l'utilizzo del motore container Docker:
-
Red Hat Enterprise Linux versione 7.8 e 7.9
-
Ubuntu 22.04 (richiede Data Classification versione 1.23 o successiva)
-
Ubuntu 24.04 (richiede Data Classification versione 1.23 o successiva)
-
-
I seguenti sistemi operativi richiedono l'utilizzo del motore contenitore Podman e la versione 1.30 o successiva di Data Classification:
-
Red Hat Enterprise Linux version 8.8, 8.10, 9.0, 9.1, 9.2, 9.3, 9.4, 9.5, 9.6 e 9.7.
-
-
Le estensioni vettoriali avanzate (AVX2) devono essere abilitate sul sistema host.
-
-
Red Hat Subscription Management: l'host deve essere registrato presso Red Hat Subscription Management. Se non è registrato, il sistema non può accedere ai repository per aggiornare il software di terze parti richiesto durante l'installazione.
-
Software aggiuntivo: è necessario installare il seguente software sull'host prima di installare Data Classification:
-
A seconda del sistema operativo utilizzato, è necessario installare uno dei seguenti motori container:
-
Docker Engine versione 19.3.1 o successiva. "Visualizza le istruzioni di installazione" .
-
Podman versione 4 o successiva. Per installare Podman, inserisci(
sudo yum install podman netavark -y).
-
-
-
Python versione 3.6 o successiva. "Visualizza le istruzioni di installazione" .
-
Considerazioni su NTP: NetApp consiglia di configurare il sistema di classificazione dei dati per utilizzare un servizio Network Time Protocol (NTP). L'ora deve essere sincronizzata tra il sistema di classificazione dei dati e il sistema agente della console.
-
-
Considerazioni su Firewalld: se si prevede di utilizzare
firewalld, ti consigliamo di abilitarlo prima di installare Data Classification. Eseguire i seguenti comandi per configurarefirewalldin modo che sia compatibile con la classificazione dei dati:firewall-cmd --permanent --add-service=http firewall-cmd --permanent --add-service=https firewall-cmd --permanent --add-port=80/tcp firewall-cmd --permanent --add-port=8080/tcp firewall-cmd --permanent --add-port=443/tcp firewall-cmd --reload
Tieni presente che devi riavviare Docker o Podman ogni volta che abiliti o aggiorni
firewalldimpostazioni.
|
|
L'indirizzo IP del sistema host di classificazione dei dati non può essere modificato dopo l'installazione. |

|
Il programma di installazione di Data Classification riserva UID 4321 e GID 4321. Prima di iniziare l'installazione, assicurati che UID 4321 e GID 4321 non siano in uso sulla macchina host. Se sono già in uso, l'installazione fallirà con un messaggio di errore "invalid user". |
Verificare i prerequisiti di Console e Data Classification
Rivedere i seguenti prerequisiti per assicurarsi di disporre di una configurazione supportata prima di distribuire Data Classification.
-
Assicurarsi che l'agente Console disponga delle autorizzazioni per distribuire risorse e creare gruppi di sicurezza per l'istanza di Data Classification. È possibile trovare le autorizzazioni Console più recenti in "le politiche fornite da NetApp".
-
Assicurati di poter mantenere Data Classification in esecuzione. L'istanza di Data Classification deve rimanere attiva per analizzare continuamente i dati.
-
Assicurare la connettività del browser web a Data Classification. Dopo aver abilitato Data Classification, assicurarsi che gli utenti accedano all'interfaccia Console da un host che ha una connessione all'istanza di Data Classification.
L'istanza di Data Classification utilizza un indirizzo IP privato per garantire che i dati indicizzati non siano accessibili ad altri. Di conseguenza, il browser web che utilizzi per accedere alla Console deve avere una connessione a tale indirizzo IP privato. Questa connessione può provenire da un host che si trova all'interno della stessa rete dell'istanza di Data Classification.
Verificare che tutte le porte richieste siano abilitate
È necessario assicurarsi che tutte le porte necessarie siano aperte per la comunicazione tra l'agente della console, Data Classification, Active Directory e le origini dati.
| Tipo di connessione | porti | Descrizione |
|---|---|---|
Agente console <> Classificazione dati |
8080 (TCP), 6000 (TCP), 443 (TCP) e 80. 9000 |
Il gruppo di sicurezza per l'agente Console deve consentire il traffico in entrata e in uscita (inbound e outbound) sulle porte 6000 e 443 da e verso l'istanza Data Classification.
|
Agente console <> cluster ONTAP (NAS) |
443 (TCP) |
La console rileva i cluster ONTAP tramite HTTPS. Se si utilizzano criteri firewall personalizzati, questi devono soddisfare i seguenti requisiti:
|
Classificazione dei dati <> cluster ONTAP |
|
Data Classification necessita di una connessione di rete a ciascuna subnet di Cloud Volumes ONTAP o sistema ONTAP on-prem. I gruppi di sicurezza per Cloud Volumes ONTAP devono consentire le connessioni in ingresso dall'istanza di Data Classification. Assicurarsi che queste porte siano aperte all'istanza di classificazione dei dati:
I criteri di esportazione del volume NFS devono consentire l'accesso dall'istanza di classificazione dei dati. |
Classificazione dei dati <> Active Directory |
389 (TCP e UDP), 636 (TCP), 3268 (TCP) e 3269 (TCP) |
È necessario che sia già stata configurata una Active Directory per gli utenti della propria azienda. Inoltre, la classificazione dei dati necessita delle credenziali di Active Directory per analizzare i volumi CIFS. È necessario disporre delle informazioni per Active Directory:
|
Se un firewall è utilizzato su un host Linux |
9000 |
Necessario per i processi interni all'interno di un server Ubuntu. |
Installa Data Classification sull'host Linux locale
Per le configurazioni tipiche, installerai il software su un singolo sistema host.
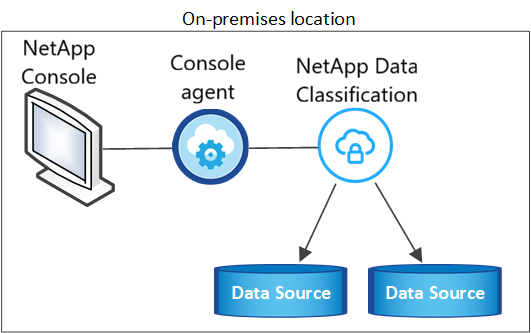
Seguire questi passaggi quando si installa il software di classificazione dei dati su un singolo host locale in un ambiente offline.
Si noti che tutte le attività di installazione vengono registrate durante l'installazione di Data Classification. Se si verificano problemi durante l'installazione, è possibile visualizzare il contenuto del registro di controllo dell'installazione. È scritto a /opt/netapp/install_logs/ .
-
Verifica che il tuo sistema Linux soddisfi i requisitirequisiti dell'host .
-
Verifica di aver installato i due pacchetti software prerequisiti (Docker Engine o Podman, e Python 3).
-
Assicurati di avere i privilegi di root sul sistema Linux.
-
Verifica che il tuo ambiente offline soddisfi i requisiti richiesti permessi e connettività.
-
Su un sistema configurato per Internet, scarica il software Data Classification dal "Sito di supporto NetApp". Il file che devi selezionare si chiama DataSense-offline-bundle-<version>.tar.gz.
-
Copia il pacchetto di installazione sull'host Linux che intendi utilizzare in modalità privata.
-
Decomprimere il pacchetto di installazione sul computer host, ad esempio:
tar -xzf DataSense-offline-bundle-v1.25.0.tar.gzQuesto estrae il software richiesto e il file di installazione effettivo cc_onprem_installer.tar.gz.
-
Decomprimere il file di installazione sul computer host, ad esempio:
tar -xzf cc_onprem_installer.tar.gz -
Da Data Classification, seleziona Deploy Classification On-Premises or Cloud.
-
Selezionare Deploy per avviare l'installazione on-prem.
-
Viene visualizzata la finestra di dialogo Distribuisci classificazione dati in locale. Copia il comando fornito (ad esempio:
sudo ./install.sh -a 12345 -c 27AG75 -t 2198qq --darksite) e incollalo in un file di testo per poterlo utilizzare in seguito. Quindi seleziona Chiudi per chiudere la finestra di dialogo. -
Sulla macchina host, immetti il comando che hai copiato e segui una serie di prompt, oppure puoi fornire il comando completo, inclusi tutti i parametri richiesti, come argomenti della riga di comando.
Tieni presente che il programma di installazione esegue un controllo preliminare per assicurarsi che i requisiti di sistema e di rete siano in atto per un'installazione riuscita.
Inserire i parametri come richiesto: Inserisci il comando completo: -
Incolla le informazioni che hai copiato dal passaggio 8:
sudo ./install.sh -a <account_id> -c <client_id> -t <user_token> --darksite -
Immettere l'indirizzo IP o il nome host della macchina host di classificazione dei dati in modo che sia accessibile al sistema agente della console.
-
Immettere l'indirizzo IP o il nome host della macchina host dell'agente Console in modo che sia accessibile al sistema di classificazione dei dati.
In alternativa, puoi creare l'intero comando in anticipo, fornendo i parametri host necessari:
sudo ./install.sh -a <account_id> -c <client_id> -t <user_token> --host <ds_host> --manager-host <cm_host> --no-proxy --darksiteValori variabili:
-
account_id = ID account NetApp
-
client_id = ID client dell'agente della console (aggiungere il suffisso "client" all'ID client se non è già presente)
-
user_token = token di accesso utente JWT
-
ds_host = Indirizzo IP o host name del sistema Data Classification.
-
cm_host = Indirizzo IP o nome host del sistema agente della console.
-
Il programma di installazione di Data Classification installa i pacchetti, registra l'installazione e installa Data Classification. L'installazione può richiedere dai 10 ai 20 minuti.
Se è presente connettività sulla porta 8080 tra la macchina host e l'istanza dell'agente Console, vedrai lo stato di avanzamento dell'installazione nella scheda Classificazione dati.
Dalla pagina Configurazione è possibile selezionare il dispositivo locale "cluster ONTAP on-prem" e "database" che si desidera sottoporre a scansione.
Aggiorna il software di classificazione dei dati
Poiché il software Data Classification viene aggiornato regolarmente con nuove funzionalità, è consigliabile controllare periodicamente la disponibilità di nuove versioni per assicurarsi di utilizzare il software e le funzionalità più recenti. Sarà necessario aggiornare manualmente il software Data Classification, poiché non è disponibile una connessione internet per eseguire l'aggiornamento automaticamente.
-
Ti consigliamo di aggiornare il software dell'agente della console alla versione più recente disponibile. "Consulta i passaggi per l'aggiornamento dell'agente Console"
-
A partire dalla versione 1.24 di Data Classification puoi eseguire aggiornamenti a qualsiasi versione futura del software.
Se il software di Data Classification utilizza una versione precedente alla 1.24, è possibile aggiornare solo una versione principale alla volta. Ad esempio, se è installata la versione 1.21.x, è possibile aggiornare solo alla 1.22.x. Se si è indietro di alcune versioni principali, sarà necessario aggiornare il software più volte.
-
Su un sistema configurato per Internet, scarica il software Data Classification dal "Sito di supporto NetApp". Il file che devi selezionare si chiama DataSense-offline-bundle-<version>.tar.gz.
-
Copia il pacchetto software sull'host Linux dove Data Classification è installato nel dark site.
-
Decomprimere il pacchetto software sul computer host, ad esempio:
tar -xvf DataSense-offline-bundle-v1.25.0.tar.gzQuesto estrae il file di installazione cc_onprem_installer.tar.gz.
-
Decomprimere il file di installazione sul computer host, ad esempio:
tar -xzf cc_onprem_installer.tar.gzQuesto estrae lo script di aggiornamento start_darksite_upgrade.sh e qualsiasi software di terze parti richiesto.
-
Eseguire lo script di aggiornamento sulla macchina host, ad esempio:
start_darksite_upgrade.sh
Il software Data Classification è stato aggiornato sul tuo host. L'aggiornamento può richiedere da 5 a 10 minuti.
È possibile verificare che il software sia stato aggiornato controllando la versione in fondo alle pagine dell'interfaccia utente Data Classification.