

NetApp Data Classificationを使用して組織内のデータを調査
 変更を提案
変更を提案
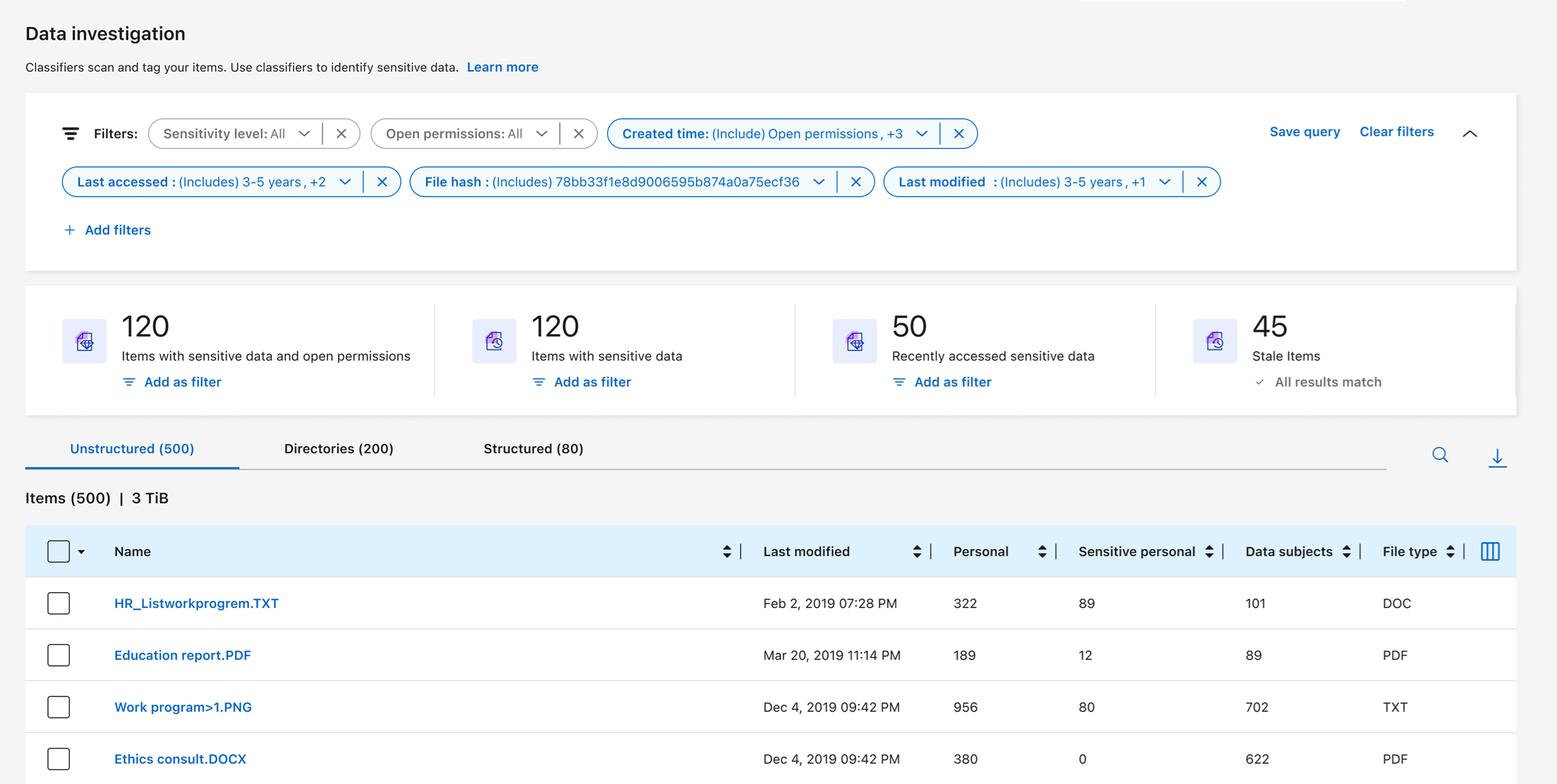
データ調査ダッシュボードには、ファイルおよびディレクトリレベルでのデータに関する詳細な情報が表示され、結果を並べ替えたりフィルタリングしたりすることができます。データ調査ページでは、ファイルとディレクトリのメタデータおよびアクセス許可に関する情報に加え、重複ファイルの特定方法も紹介されています。ファイル、ディレクトリ、データベースレベルの情報を活用することで、組織のコンプライアンスを向上させ、ストレージ容量を節約するための対策を講じることができます。データ調査ページは"ファイルの移動、コピー、削除"もサポートしています。

|
調査ページから有益な情報を得るには、データソースに対して完全な分類スキャンを実行する必要があります。マップのみのスキャンが行われたデータソースでは、ファイルレベルの詳細情報は表示されません。 |
データ調査構造
データ調査ページでは、データが 3 つのタブに分類されます。
-
非構造化データ: ファイルデータ
-
ディレクトリ: フォルダとファイル共有
-
構造化: データベース
データフィルター
データ調査ページには、必要なものだけを見つけるためにデータを並べ替えるためのさまざまなフィルターが用意されています。複数のフィルターを組み合わせて使うこともできます。
フィルターを追加するには、[フィルターを追加] ボタンを選択します。
フィルターの感度とコンテンツ
次のフィルターを使用して、データに含まれる機密情報の量を確認します。
| フィルタ | 詳細 |
|---|---|
カテゴリ |
を選択する"カテゴリーの種類"。 |
感度レベル |
機密レベルを選択します: 個人、機密個人、または非機密。 |
識別子の数 |
ファイルごとに検出された機密識別子の範囲を選択します。個人データおよび機密性の高い個人データが含まれます。ディレクトリでフィルタリングする場合、データ分類は各フォルダー (およびサブフォルダー) 内のすべてのファイルからの一致を合計します。注: 2023 年 12 月 (バージョン 1.26.6) のリリースでは、ディレクトリ別に個人識別情報 (PII) データの数を計算するオプションが削除されました。 |
個人データ |
を選択する"個人データの種類"。 |
機密性の高い個人データ |
を選択する"機密個人データの種類"。 |
データ主体 |
データ主体のフルネームまたは既知の識別子を入力します。"データ主体についての詳細はこちらをご覧ください" 。 |
ユーザー所有者とユーザー権限をフィルタリング
次のフィルターを使用して、ファイルの所有者とデータへのアクセス許可を表示します。
| フィルタ | 詳細 |
|---|---|
オープン権限 |
データ内およびフォルダー/共有内の権限の種類を選択します。 |
ユーザー/グループの権限 |
1 つまたは複数のユーザー名またはグループ名を選択するか、名前の一部を入力します。 |
ファイル所有者 |
ファイルの所有者名を入力します。 |
アクセス権を持つユーザーの数 |
1 つまたは複数のカテゴリ範囲を選択して、特定の数のユーザーに公開されているファイルとフォルダーを表示します。 |
時系列でフィルタリング
時間基準に基づいてデータを表示するには、次のフィルターを使用します。
| フィルタ | 詳細 |
|---|---|
作成時刻 |
ファイルが作成された時間の範囲を選択します。検索結果をさらに絞り込むために、カスタムの時間範囲を指定することもできます。 |
発見された時間 |
データ分類がファイルを検出した時間範囲を選択します。検索結果をさらに絞り込むために、カスタムの時間範囲を指定することもできます。 |
最終変更日時 |
ファイルが最後に変更された時間の範囲を選択します。検索結果をさらに絞り込むために、カスタムの時間範囲を指定することもできます。 |
最終アクセス日時 |
ファイルまたはディレクトリ* が最後にアクセスされた時間の範囲を選択します。検索結果をさらに絞り込むために、カスタムの時間範囲を指定することもできます。データ分類がスキャンするファイルの種類の場合、これはデータ分類がファイルを最後にスキャンした時刻です。 |
{アスタリスク} ディレクトリの最終アクセス時刻は、NFS または CIFS 共有でのみ使用できます。
メタデータをフィルタリング
場所、サイズ、ディレクトリまたはファイルの種類に基づいてデータを表示するには、次のフィルターを使用します。
| フィルタ | 詳細 |
|---|---|
ファイルパス |
クエリに含めるか除外する部分パスまたは完全パスを最大 20 個入力します。含めるパスと除外するパスの両方を入力すると、データ分類はまず含めるパス内のすべてのファイルを見つけ、次に除外するパスからファイルを削除して、結果を表示します。このフィルターで「*」を使用しても効果はなく、特定のフォルダーをスキャンから除外することはできないことに注意してください。構成された共有の下にあるすべてのディレクトリとファイルがスキャンされます。 |
ディレクトリタイプ |
ディレクトリの種類として「共有」または「フォルダー」を選択します。 |
ファイル タイプ |
を選択する"ファイルの種類"。 |
ファイル サイズ |
ファイルサイズの範囲を選択します。 |
ファイルハッシュ |
名前が異なっていても、特定のファイルを見つけるには、ファイルのハッシュを入力します。 |
フィルター収納タイプ
ストレージ タイプ別にデータを表示するには、次のフィルターを使用します。
| フィルタ | 詳細 |
|---|---|
システムタイプ |
システムの種類を選択します。 |
システム環境名 |
特定のシステムを選択します。 |
ストレージリポジトリ |
ボリュームやスキーマなどのストレージ リポジトリを選択します。 |
フィルタークエリ
保存されたクエリ別にデータを表示するには、次のフィルターを使用します。
| フィルタ | 詳細 |
|---|---|
保存されたクエリ |
保存したクエリを 1 つまたは複数選択します。に行く"保存されたクエリタブ"既存の保存済みクエリのリストを表示し、新しいクエリを作成します。 |
タグ |
選択"タグ"ファイルに割り当てられているもの。 |
フィルター分析ステータス
次のフィルターを使用して、データ分類スキャンのステータス別にデータを表示します。
| フィルタ | 詳細 |
|---|---|
分析ステータス |
最初のスキャンが保留中、スキャンが完了、再スキャンが保留中、またはスキャンに失敗したファイルのリストを表示するには、オプションを選択します。 |
スキャン分析イベント |
データ分類が最終アクセス時間を元に戻すことができなかったために分類されなかったファイルを表示するか、データ分類が最終アクセス時間を元に戻すことができなかったにもかかわらず分類されたファイルを表示するかを選択します。 |
"「最終アクセス時刻」のタイムスタンプの詳細を見る"スキャン分析イベントを使用してフィルタリングするときに調査ページに表示される項目の詳細については、こちらをご覧ください。
重複データによるフィルタリング
ストレージ内に重複しているファイルを表示するには、次のフィルターを使用します。
| フィルタ | 詳細 |
|---|---|
重複 |
リポジトリ内でファイルを複製するかどうかを選択します。 |

|
データをフィルタリングした後、"非構造化ファイルのコピー、移動、削除"してコンプライアンスを向上させたり、ストレージを最適化したりできます。 |
ファイルのメタデータを表示
メタデータには、ファイルが存在するシステムとボリュームが表示されるだけでなく、ファイルの権限、ファイルの所有者、このファイルの重複があるかどうかなど、さらに多くの情報が表示されます。この情報は、"保存したクエリを作成する"データをフィルタリングするために使用できるすべての情報を確認できるためです。
情報の可用性はデータ ソースによって異なります。たとえば、データベース ファイルのボリューム名とアクセス許可は共有されません。
-
データ分類メニューから、*調査*を選択します。
-
右側のデータ調査リストで、下向き矢印を選択します。
 ファイルのメタデータを表示するには、任意のファイルの右側にある をクリックします。
ファイルのメタデータを表示するには、任意のファイルの右側にある をクリックします。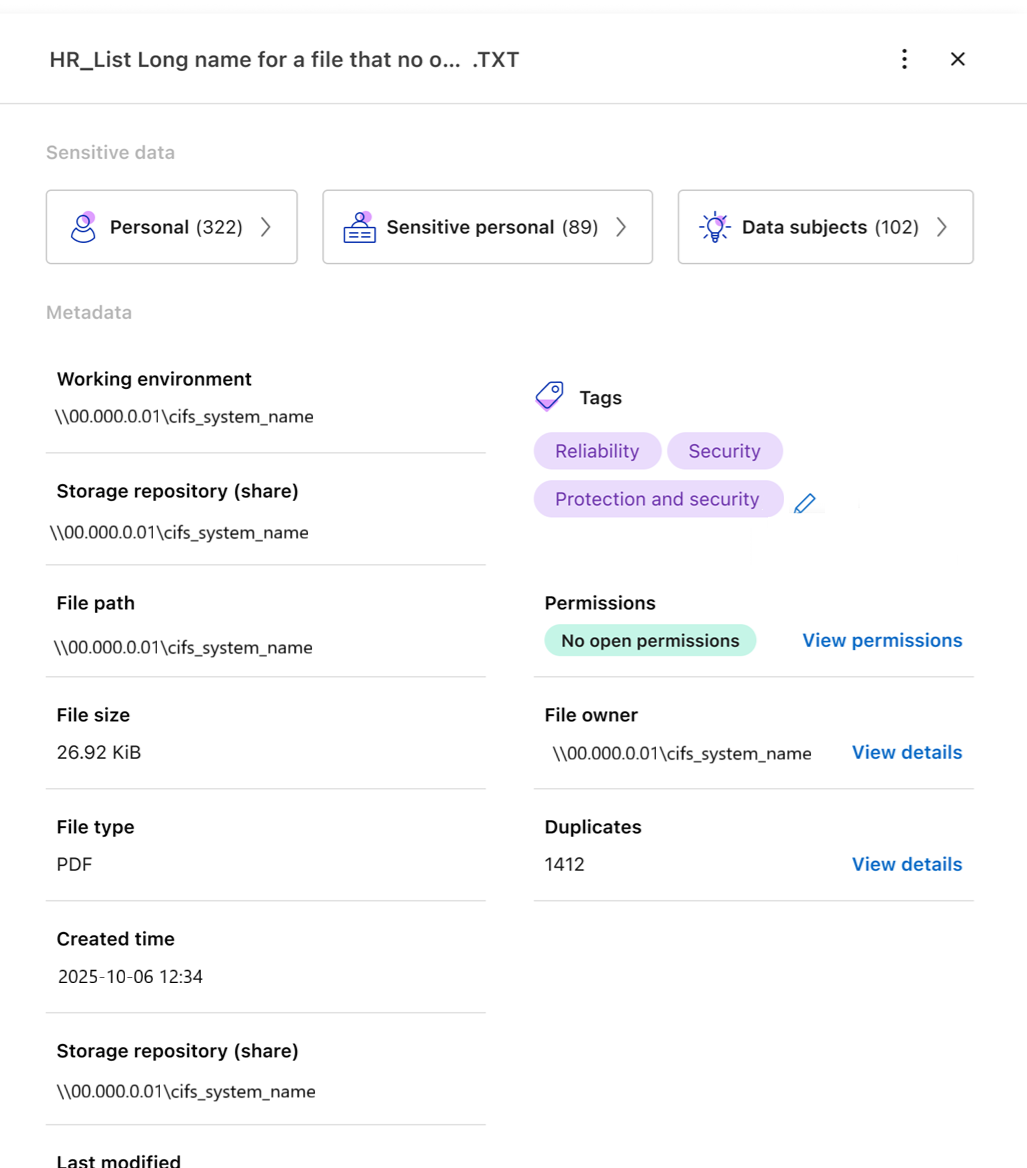
-
オプションで、[タグを作成] ボタンを使用してファイルにタグを作成または追加できます。ドロップダウン メニューから既存のタグを選択するか、[+ 追加] ボタンを使用して新しいタグを追加します。タグを使用してデータをフィルタリングできます。
ファイルとディレクトリのユーザー権限を表示する
ファイルまたはディレクトリへのアクセス権を持つすべてのユーザーまたはグループと、それらの権限の種類のリストを表示するには、[すべての権限を表示] を選択します。このオプションは、CIFS 共有内のデータに対してのみ使用できます。
ユーザー名やグループ名の代わりにセキュリティ識別子 (SID) を使用する場合は、Active Directory をデータ分類に統合する必要があります。詳細については、以下を参照してください。 "データ分類にActive Directoryを追加する" 。
-
データ分類メニューから、*調査*を選択します。
-
右側のデータ調査リストで、下向き矢印を選択します。
ファイルのメタデータを表示するには、任意のファイルの右側にある をクリックします。 -
ファイルまたはディレクトリへのアクセス権を持つすべてのユーザーまたはグループのリストと、それらの権限の種類を表示するには、[開く権限] フィールドで [すべての権限を表示] を選択します。
データ分類では、リストに最大 100 人のユーザーが表示されます。 -
下向き矢印を選択
任意のグループのボタンをクリックすると、そのグループに属しているユーザーのリストが表示されます。
グループの 1 レベルを展開すると、グループに属しているユーザーを表示できます。 -
ユーザーまたはグループの名前を選択して調査ページを更新し、そのユーザーまたはグループがアクセスできるすべてのファイルとディレクトリを表示できるようにします。
ストレージシステム内の重複ファイルをチェックする
ストレージ システムに重複したファイルが保存されているかどうかを確認できます。これは、ストレージスペースを節約できる領域を特定する場合に便利です。また、特定の権限や機密情報を持つ特定のファイルが、ストレージ システム内で不必要に重複しないようにすることも重要です。
データ分類では、次の場合にすべてのファイル (データベースを除く) の重複を比較します。
-
1 MB以上
-
または個人情報や機密性の高い個人情報が含まれている
データ分類では、ハッシュ テクノロジを使用して重複ファイルを判別します。いずれかのファイルに別のファイルと同じハッシュ コードがある場合、ファイル名が異なっていてもファイルは完全に重複しています。
-
データ分類メニューから、*調査*を選択します。
-
フィルター ペインで、「ファイル サイズ」と「重複」(「重複あり」) を選択して、環境内で重複している特定のサイズ範囲のファイルを確認します。
-
オプションで、重複ファイルのリストをダウンロードしてストレージ管理者に送信し、削除できるファイルがあるかどうかを管理者が判断できるようにします。
-
必要に応じて、重複ファイルを削除、タグ付け、または移動することもできます。アクションを実行するファイルを選択し、適切なアクションを選択します。
特定のファイルが重複しているかどうかを確認する
1 つのファイルに重複があるかどうかを確認できます。
-
データ分類メニューから、*調査*を選択します。
-
データ調査リストで、
ファイルのメタデータを表示するには、任意のファイルの右側にある をクリックします。ファイルに重複が存在する場合、この情報は [重複] フィールドの横に表示されます。
-
重複ファイルのリストとその保存場所を表示するには、[詳細の表示] を選択します。
-
次のページで「重複を表示」を選択し、調査ページでファイルを表示します。
-
必要に応じて、重複ファイルを削除、タグ付け、または移動することもできます。アクションを実行するファイルを選択し、適切なアクションを選択します。
|
|
このページで提供されている「ファイル ハッシュ」値を使用して、調査ページに直接入力し、いつでも特定の重複ファイルを検索できます。また、保存したクエリで使用することもできます。 |
レポートをダウンロードする
フィルタリングされた結果を CSV または JSON 形式でダウンロードできます。
データ分類がファイル (非構造化データ)、ディレクトリ (フォルダーとファイル共有)、およびデータベース (構造化データ) をスキャンしている場合、最大 3 つのレポート ファイルをダウンロードできます。
ファイルは、固定数の行またはレコードを持つファイルに分割されます。
-
JSON: レポートあたり10万件のレコード。生成には約5分かかります。
-
CSV: レポートあたり20万件のレコード、生成に約4分かかります
|
|
このブラウザで表示するには、CSV ファイルのバージョンをダウンロードできます。このバージョンは 10,000 件のレコードに制限されています。 |
ダウンロード可能なレポートに含まれるもの
*非構造化ファイル データ レポート*には、ファイルに関する次の情報が含まれます。
-
ファイル名
-
場所の種類
-
システム名
-
ストレージリポジトリ(ボリューム、バケット、共有など)
-
リポジトリの種類
-
ファイル パス
-
ファイル タイプ
-
ファイルサイズ(MB)
-
作成時間
-
最終更新日
-
最終アクセス
-
ファイルの所有者
-
ファイル所有者データには、Active Directory が構成されている場合のアカウント名、SAM アカウント名、および電子メール アドレスが含まれます。
-
-
カテゴリ
-
個人情報
-
機密個人情報
-
オープン権限
-
スキャン分析エラー
-
削除検出日
削除検出日は、ファイルが削除または移動された日付を識別します。これにより、機密ファイルが移動された時期を識別できるようになります。削除されたファイルは、ダッシュボードまたは調査ページに表示されるファイル数には含まれません。ファイルは CSV レポートにのみ表示されます。
*非構造化ディレクトリ データ レポート*には、フォルダーとファイル共有に関する次の情報が含まれます。
-
システムタイプ
-
システム名
-
ディレクトリ名
-
ストレージリポジトリ(フォルダやファイル共有など)
-
ディレクトリ所有者
-
作成時間
-
発見された時間
-
最終更新日
-
最終アクセス
-
オープン権限
-
ディレクトリタイプ
*構造化データ レポート*には、データベース テーブルに関する次の情報が含まれます。
-
DBテーブル名
-
場所の種類
-
システム名
-
ストレージリポジトリ(スキーマなど)
-
列数
-
行数
-
個人情報
-
機密個人情報
-
データ調査ページから、
 ページの右上にあるボタンをクリックします。
ページの右上にあるボタンをクリックします。 -
レポートタイプ(CSV または JSON)を選択します。
-
レポート名 を入力します。
-
完全なレポートをダウンロードするには、[システム] を選択し、それぞれのドロップダウン メニューから [システム] と [ボリューム] を選択します。 宛先フォルダーのパス を指定します。
ブラウザでレポートをダウンロードするには、[ローカル] を選択します。このオプションでは、レポートが最初の 10,000 行に制限され、CSV 形式に制限されることに注意してください。 ローカル を選択した場合は、他のフィールドを入力する必要はありません。
-
レポートのダウンロードを選択します。
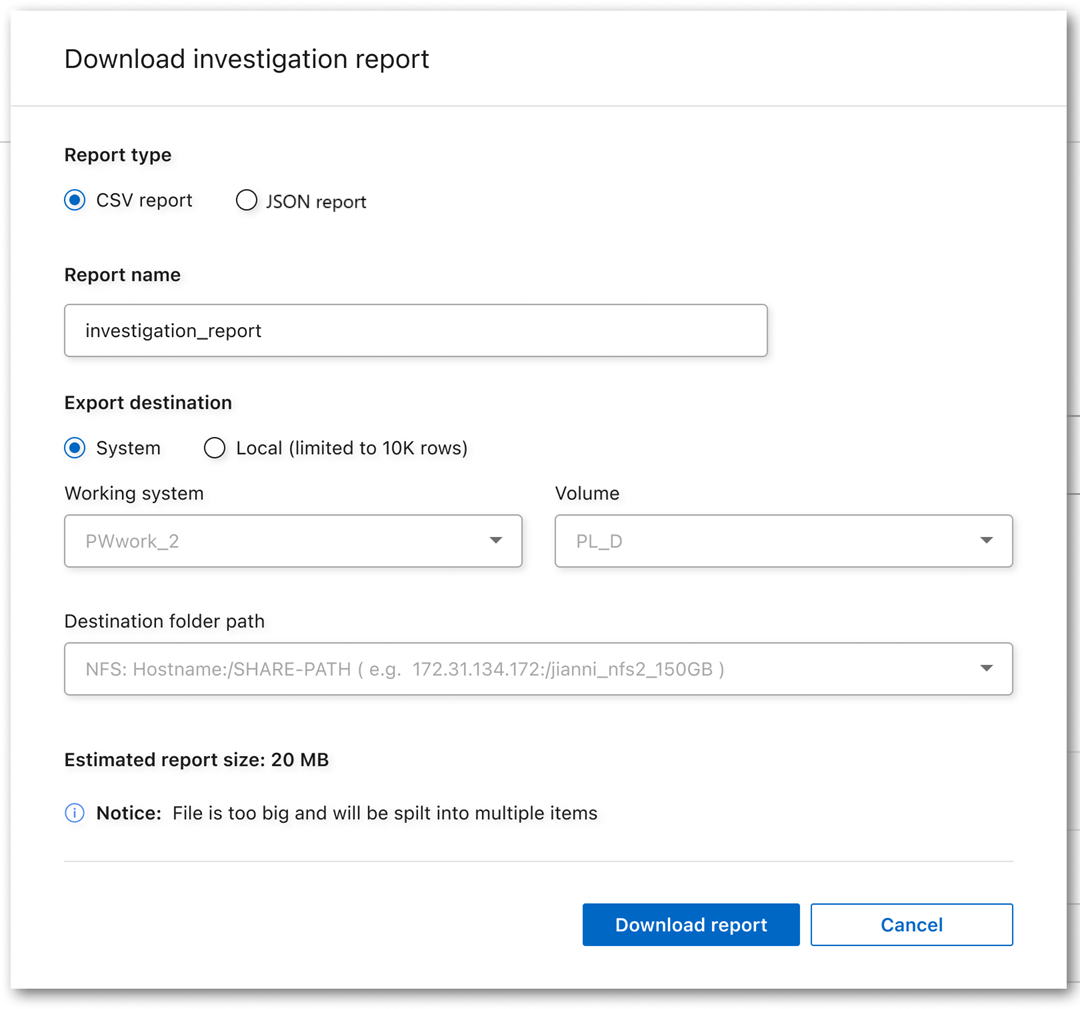
レポートをダウンロード中であることを示すメッセージがダイアログに表示されます。
選択したフィルターに基づいて保存されたクエリを作成する
-
「調査」タブで、使用するフィルターを選択して検索を定義します。見る"調査ページでのデータのフィルタリング"詳細については。
-
すべてのフィルター特性を好みに合わせて設定したら、「クエリを保存」を選択します。

-
保存したクエリに名前を付け、説明を追加します。名前は一意である必要があります。
-
オプションでクエリをポリシーとして保存できます。
-
クエリをポリシーとして保存するには、[ポリシーとして実行] トグルを切り替えます。
-
完全に削除 または 電子メールで更新を送信 を選択します。電子メールによる更新を選択した場合は、クエリ結果を毎日、毎週、または毎月、すべてのコンソール ユーザーに電子メールで送信できます。あるいは、同じ頻度で特定の電子メール アドレスに通知を送信することもできます。
-
-
*保存*を選択します。
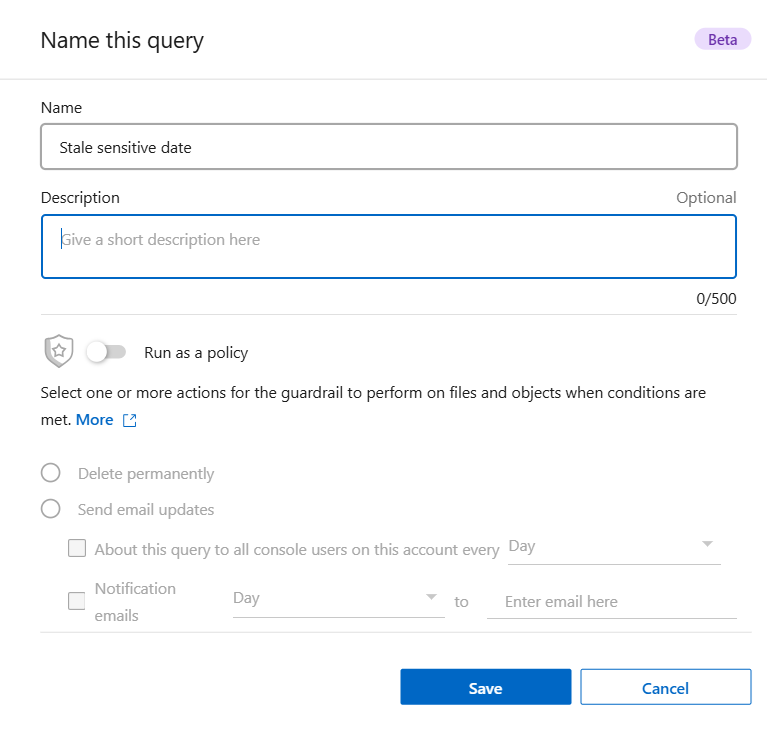
検索またはポリシーを作成したら、[保存したクエリ] タブで表示できます。
|
|
結果が「保存されたクエリ」ページに表示されるまで、最大 15 分かかる場合があります。 |