

NetApp Data Classification 에 대해 알아보세요
 변경 제안
변경 제안
NetApp Data Classification 는 NetApp Console 위한 데이터 거버넌스 서비스로, 기업의 온프레미스 및 클라우드 데이터 소스를 스캔하여 데이터를 매핑하고 분류하며 개인 정보를 식별합니다. 이를 통해 보안 및 규정 준수 위험을 줄이고, 스토리지 비용을 절감하고, 데이터 마이그레이션 프로젝트를 지원할 수 있습니다.

|
버전 1.31부터 데이터 분류가 NetApp Console 의 핵심 기능으로 제공됩니다. 추가 비용은 없습니다. 분류 라이센스나 구독이 필요하지 않습니다. + 기존 버전 1.30 또는 이전 버전을 사용 중이신 경우, 구독이 만료될 때까지 해당 버전을 사용할 수 있습니다. |
NetApp Console
데이터 분류는 NetApp Console 통해 접근할 수 있습니다.
NetApp Console 엔터프라이즈급 온프레미스 및 클라우드 환경 전반에서 NetApp 스토리지 및 데이터 서비스를 중앙에서 관리할 수 있는 기능을 제공합니다. NetApp 데이터 서비스에 액세스하고 사용하려면 콘솔이 필요합니다. 관리 인터페이스로서, 하나의 인터페이스에서 여러 스토리지 리소스를 관리할 수 있습니다. 콘솔 관리자는 기업 내 모든 시스템의 저장소와 서비스에 대한 액세스를 제어할 수 있습니다.
NetApp Console 사용하려면 라이선스나 구독이 필요하지 않으며, 스토리지 시스템이나 NetApp 데이터 서비스에 대한 연결을 보장하기 위해 클라우드에 Console 에이전트를 배포해야 할 때만 요금이 부과됩니다. 그러나 콘솔에서 액세스할 수 있는 일부 NetApp 데이터 서비스는 라이선스 기반이거나 구독 기반입니다.
자세히 알아보세요"NetApp Console" .
특징
데이터 분류는 인공지능(AI), 자연어 처리(NLP), 머신 러닝(ML)을 사용하여 스캔한 콘텐츠를 이해하고 엔터티를 추출하고 그에 따라 콘텐츠를 분류합니다. 이를 통해 데이터 분류는 다음과 같은 기능 영역을 제공할 수 있습니다.
데이터 분류는 규정 준수 노력에 도움이 되는 다양한 도구를 제공합니다. 데이터 분류를 사용하여 다음을 수행할 수 있습니다.
-
개인 식별 정보(PII)를 식별합니다.
-
GDPR, CCPA, PCI 및 HIPAA 개인정보 보호 규정에서 요구하는 대로 광범위한 민감한 개인 정보를 식별합니다.
-
이름이나 이메일 주소를 기반으로 데이터 주체 접근 요청(DSAR)에 응답합니다.
데이터 분류를 통해 범죄 목적으로 접근될 위험이 있는 데이터를 식별할 수 있습니다. 데이터 분류를 사용하여 다음을 수행할 수 있습니다.
-
전체 조직이나 대중에게 공개된, 공개 권한이 있는 모든 파일과 디렉토리(공유 및 폴더)를 식별합니다.
-
처음 지정된 위치 외부에 있는 민감한 데이터를 식별합니다.
-
데이터 보존 정책을 준수합니다.
-
정책을 사용하면 새로운 보안 문제를 자동으로 감지하여 보안 직원이 즉시 조치를 취할 수 있습니다.
데이터 분류는 스토리지 총 소유 비용(TCO)을 절감하는 데 도움이 되는 도구를 제공합니다. 데이터 분류를 사용하여 다음을 수행할 수 있습니다.
-
중복된 데이터나 업무와 관련 없는 데이터를 식별하여 저장 효율성을 높입니다.
-
비활성 데이터를 식별하여 비용이 덜 드는 개체 스토리지로 계층화하여 스토리지 비용을 절감하세요. "Cloud Volumes ONTAP 시스템의 계층화에 대해 자세히 알아보세요." . "온프레미스 ONTAP 시스템의 계층화에 대해 자세히 알아보세요." .
지원되는 시스템 및 데이터 소스
데이터 분류는 다음 유형의 시스템 및 데이터 소스에서 구조화된 데이터와 구조화되지 않은 데이터를 스캔하고 분석할 수 있습니다.
시스템
-
Amazon FSx for NetApp ONTAP
-
Azure NetApp Files
-
Cloud Volumes ONTAP (AWS, Azure 또는 GCP에 배포됨)
-
Google Cloud NetApp Volumes
-
온프레미스 ONTAP 클러스터
-
StorageGRID
데이터 출처
-
NetApp 파일 공유
-
데이터베이스:
-
Amazon 관계형 데이터베이스 서비스(Amazon RDS)
-
몽고디비
-
MySQL
-
신탁
-
포스트그레스큐엘
-
SAP 하나
-
SQL 서버(MSSQL)
-
데이터 분류는 NFS 버전 3.x, 4.0, 4.1과 CIFS 버전 1.x, 2.0, 2.1, 3.0을 지원합니다.
비용
데이터 분류는 무료로 사용할 수 있습니다. 분류 라이센스나 유료 구독이 필요하지 않습니다.
인프라 비용
-
클라우드에 데이터 분류를 설치하려면 클라우드 인스턴스를 배포해야 하며, 배포된 클라우드 제공업체에서 요금이 부과됩니다. 보다 각 클라우드 공급자에 배포되는 인스턴스 유형 . 온프레미스 시스템에 데이터 분류를 설치하는 경우 비용이 발생하지 않습니다.
-
데이터 분류를 위해서는 콘솔 에이전트를 배포해야 합니다. 많은 경우 콘솔에서 다른 저장소와 서비스를 사용하고 있기 때문에 이미 콘솔 에이전트가 있는 것입니다. 콘솔 에이전트 인스턴스는 배포된 클라우드 공급자로부터 요금이 부과됩니다. 를 참조하십시오 "각 클라우드 공급자에 배포되는 인스턴스 유형" . 온프레미스 시스템에 콘솔 에이전트를 설치하는 경우 비용이 발생하지 않습니다.
데이터 전송 비용
데이터 전송 비용은 설정에 따라 달라집니다. 데이터 분류 인스턴스와 데이터 소스가 동일한 가용성 영역 및 지역에 있는 경우 데이터 전송 비용이 발생하지 않습니다. 하지만 Cloud Volumes ONTAP 시스템과 같은 데이터 소스가 다른 가용성 영역이나 지역에 있는 경우 클라우드 공급자가 데이터 전송 비용을 청구합니다. 자세한 내용은 다음 링크를 참조하세요.
데이터 분류 인스턴스
클라우드에 데이터 분류를 배포하면 콘솔은 콘솔 에이전트와 동일한 서브넷에 인스턴스를 배포합니다. "콘솔 에이전트에 대해 자세히 알아보세요."
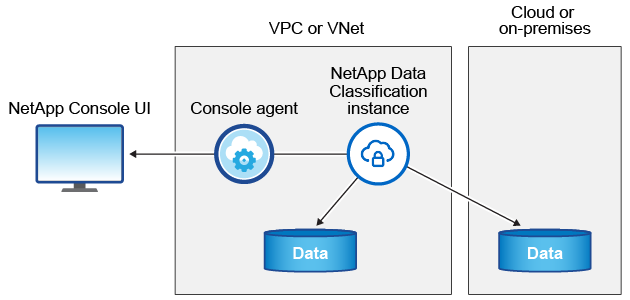
기본 인스턴스에 대해 다음 사항을 참고하세요.
-
AWS에서 Data Classification은 500 GiB GP2 디스크가 있는 "m6i.4xlarge 인스턴스"에서 실행됩니다. 운영 체제 이미지는 Amazon Linux 2입니다.
-
Azure에서 데이터 분류는 다음에서 실행됩니다."Standard_D16s_v3 VM" 500GiB 디스크 포함. 운영체제 이미지는 Ubuntu 22.04입니다.
-
GCP에서 데이터 분류는 다음에서 실행됩니다."n2-standard-16 VM" 500GiB 표준 영구 디스크를 사용합니다. 운영체제 이미지는 Ubuntu 22.04입니다.
-
기본 인스턴스를 사용할 수 없는 지역에서는 데이터 분류가 대체 인스턴스에서 실행됩니다. "대체 인스턴스 유형을 확인하세요" .
-
인스턴스 이름은 CloudCompliance_이고, 생성된 해시(UUID)가 여기에 연결됩니다. 예: _CloudCompliance-16bb6564-38ad-4080-9a92-36f5fd2f71c7
-
콘솔 에이전트당 하나의 데이터 분류 인스턴스만 배포됩니다.
사내 Linux 호스트나 선호하는 클라우드 공급업체의 호스트에 데이터 분류를 배포할 수도 있습니다. 어떤 설치 방법을 선택하든 소프트웨어의 기능은 정확히 동일합니다. 인스턴스에 인터넷 접속이 가능한 한 데이터 분류 소프트웨어 업그레이드는 자동화됩니다.

|
데이터 분류는 지속적으로 데이터를 스캔하므로 인스턴스는 항상 실행 상태를 유지해야 합니다. |
다양한 인스턴스 유형에 배포
인스턴스 유형에 대한 다음 사양을 검토하세요.
| 시스템 크기 | 명세서 | 제한 사항 |
|---|---|---|
특대 |
32개 CPU, 128GB RAM, 1TiB SSD |
최대 5억 개의 파일을 검색할 수 있습니다. |
대형(기본값) |
CPU 16개, 64GB RAM, 500GiB SSD |
최대 2억 5천만 개의 파일을 스캔할 수 있습니다. |
데이터 분류 스캐닝 작동 방식
높은 수준에서 데이터 분류 스캐닝은 다음과 같이 작동합니다.
-
콘솔에서 데이터 분류 인스턴스를 배포합니다.
-
하나 이상의 데이터 소스에 대한 검사를 활성화합니다.
-
데이터 분류는 AI 학습 프로세스를 사용하여 데이터를 스캔합니다.
-
제공된 대시보드와 보고 도구를 사용하면 규정 준수 및 거버넌스 활동에 도움이 됩니다.
데이터 분류를 활성화하고 스캔하려는 저장소(볼륨, 데이터베이스 스키마 또는 기타 사용자 데이터)를 선택하면 즉시 데이터 스캔을 시작하여 개인 및 민감한 데이터를 식별합니다. 대부분의 경우 백업, 미러 또는 DR 사이트 대신 라이브 프로덕션 데이터 스캔에 집중해야 합니다. 그런 다음 데이터 분류는 조직 데이터를 매핑하고, 각 파일을 분류하고, 데이터에서 엔터티와 사전 정의된 패턴을 식별하여 추출합니다. 검사 결과는 개인 정보, 민감한 개인 정보, 데이터 범주 및 파일 유형의 인덱스입니다.
데이터 분류는 NFS 및 CIFS 볼륨을 마운트하여 다른 클라이언트와 마찬가지로 데이터에 연결합니다. NFS 볼륨은 자동으로 읽기 전용으로 액세스되는 반면, CIFS 볼륨을 스캔하려면 Active Directory 자격 증명을 제공해야 합니다.
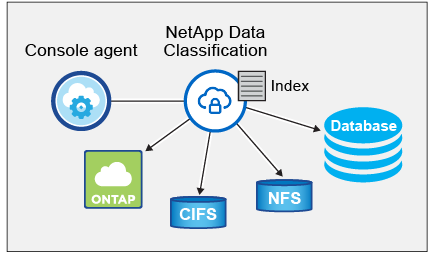
초기 스캔 이후, 데이터 분류는 라운드 로빈 방식으로 데이터를 지속적으로 스캔하여 증분적 변경 사항을 감지합니다. 인스턴스를 계속 실행하는 것이 중요한 이유가 여기에 있습니다.
볼륨 수준이나 데이터베이스 스키마 수준에서 검사를 활성화하거나 비활성화할 수 있습니다.

|
데이터 분류는 스캔할 수 있는 데이터 양에 제한을 두지 않습니다. 각 콘솔 에이전트는 500TiB의 데이터를 스캔하고 표시하는 것을 지원합니다. 500TiB 이상의 데이터를 스캔하려면"다른 콘솔 에이전트를 설치하세요" 그 다음에"다른 데이터 분류 인스턴스 배포" . + 콘솔 UI는 단일 커넥터의 데이터를 표시합니다. 여러 콘솔 에이전트의 데이터를 보는 방법에 대한 팁은 다음을 참조하세요."여러 콘솔 에이전트와 함께 작업" . |
매핑 및 전체 스캔
데이터 분류에서는 두 가지 유형의 스캔을 수행할 수 있습니다.
-
매핑 전용 스캔은 데이터에 대한 개략적인 개요만 제공하며 선택한 데이터 소스에서 수행됩니다. 매핑 전용 스캔은 내부 데이터를 보기 위해 파일에 액세스하지 않으므로 전체 스캔보다 시간이 덜 걸립니다. 처음에 이 방법을 사용하여 조사 영역을 식별한 다음 해당 영역에 대해 전체 스캔을 수행할 수 있습니다.
-
전체 스캔은 데이터에 대한 심층적인 스캔을 제공합니다. 전체 스캔에는 매핑 전용 스캔과 파일 내 데이터 분류가 포함됩니다.
맵 전용 스캔과 전체 스캔의 차이점에 대한 분석은 "매핑 스캔과 분류 스캔의 차이점은 무엇인가요?"을 참조하십시오.
데이터 분류가 분류하는 정보
데이터 분류는 다음 데이터를 수집, 색인화하고 범주를 지정합니다.
-
파일에 대한 표준 메타데이터: 파일 유형, 크기, 생성 및 수정 날짜 등.
-
개인 데이터: 이메일 주소, 신분증 번호 또는 신용 카드 번호와 같은 개인 식별 정보(PII)로, 데이터 분류는 파일에서 특정 단어, 문자열 및 패턴을 사용하여 이를 식별합니다. "개인 데이터에 대해 자세히 알아보세요" .
-
민감한 개인 정보: 건강 데이터, 민족적 기원 또는 정치적 의견과 같은 특수 유형의 민감한 개인 정보(SPII)로, 일반 데이터 보호 규정(GDPR) 및 기타 개인정보 보호 규정에 정의되어 있습니다. "민감한 개인 데이터에 대해 자세히 알아보세요" .
-
범주: 데이터 분류는 스캔한 데이터를 여러 유형의 범주로 분류합니다. 카테고리는 각 파일의 콘텐츠와 메타데이터에 대한 AI 분석을 기반으로 한 주제입니다. "카테고리에 대해 자세히 알아보세요".
-
이름 엔터티 인식: 데이터 분류는 AI를 사용하여 문서에서 사람들의 실제 이름을 추출합니다. "데이터 주체 접근 요청에 응답하는 방법에 대해 알아보세요" .
네트워킹 개요
데이터 분류는 클라우드나 온프레미스 등 원하는 곳에 단일 서버 또는 클러스터를 배포합니다. 서버는 표준 프로토콜을 통해 데이터 소스에 연결하고, 동일한 서버에 배포된 Elasticsearch 클러스터에서 검색 결과를 인덱싱합니다. 이를 통해 멀티 클라우드, 크로스 클라우드, 프라이빗 클라우드 및 온프레미스 환경을 지원할 수 있습니다.
콘솔은 콘솔 에이전트에서 인바운드 HTTP 연결을 활성화하는 보안 그룹과 함께 데이터 분류 인스턴스를 배포합니다.
SaaS 모드에서 콘솔을 사용하는 경우 콘솔 연결은 HTTPS를 통해 제공되고 브라우저와 데이터 분류 인스턴스 간에 전송되는 개인 데이터는 TLS 1.2를 사용하여 종단 간 암호화로 보호되므로 NetApp 과 타사가 해당 데이터를 읽을 수 없습니다.
아웃바운드 규칙은 완전히 공개되어 있습니다. 데이터 분류 소프트웨어를 설치하고 업그레이드하고 사용 지표를 전송하려면 인터넷 접속이 필요합니다.
엄격한 네트워킹 요구 사항이 있는 경우"데이터 분류가 접촉하는 엔드포인트에 대해 알아보세요" .