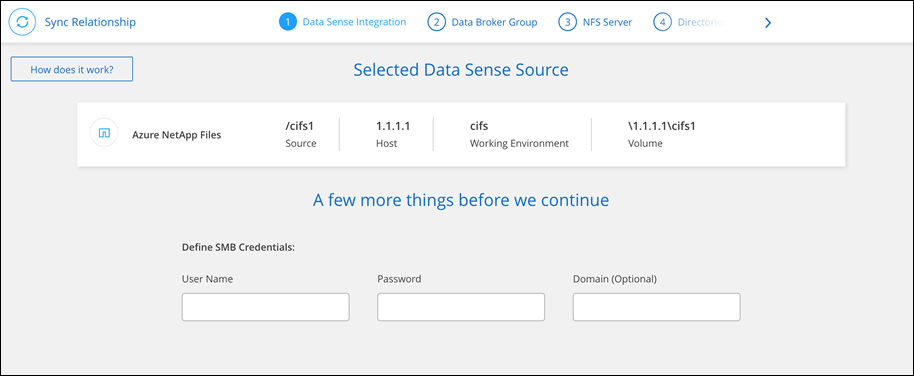
Crie relacionamentos de sincronização no NetApp Copy and Sync
 Sugerir alterações
Sugerir alterações
Quando você cria um relacionamento de sincronização, o NetApp Copy and Sync copia arquivos da origem para o destino. Após a cópia inicial, o Copy and Sync sincroniza todos os dados alterados a cada 24 horas.
Antes de criar alguns tipos de relacionamentos de sincronização, você primeiro precisará criar um sistema no NetApp Console.
Crie relacionamentos de sincronização para tipos específicos de sistemas
Se você quiser criar relacionamentos de sincronização para qualquer um dos seguintes, primeiro você precisa criar ou descobrir o sistema:
-
Amazon FSx para ONTAP
-
Azure NetApp Files
-
Cloud Volumes ONTAP
-
Clusters ONTAP locais
-
Crie ou descubra o sistema.
-
Selecione Página de sistemas.
-
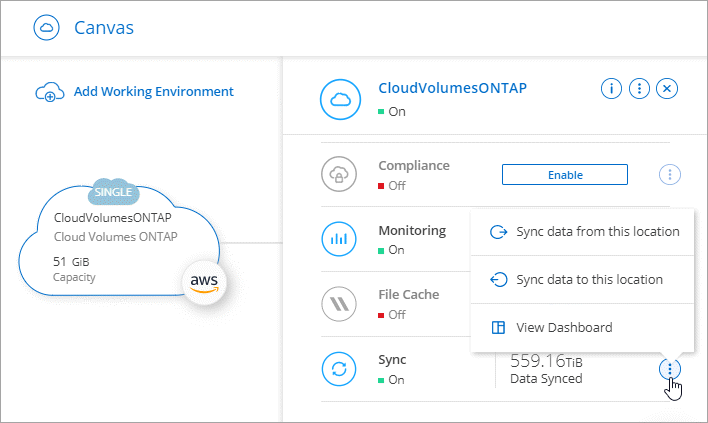
Selecione um sistema que corresponda a qualquer um dos tipos listados acima.
-
Selecione o menu de ação ao lado de Sincronizar.
-
Selecione Sincronizar dados deste local ou Sincronizar dados com este local e siga as instruções para configurar o relacionamento de sincronização.
Crie outros tipos de relacionamentos de sincronização
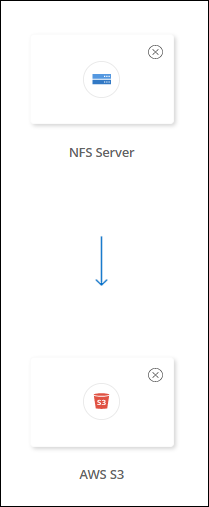
Use estas etapas para sincronizar dados de ou para um tipo de armazenamento compatível diferente do Amazon FSx para ONTAP, Azure NetApp Files, Cloud Volumes ONTAP ou clusters ONTAP locais. As etapas abaixo fornecem um exemplo que mostra como configurar um relacionamento de sincronização de um servidor NFS para um bucket S3.
-
No NetApp Console, selecione Sincronizar.
-
Na página Definir relacionamento de sincronização, escolha uma origem e um destino.
As etapas a seguir fornecem um exemplo de como criar um relacionamento de sincronização de um servidor NFS para um bucket S3.
-
Na página Servidor NFS, insira o endereço IP ou o nome de domínio totalmente qualificado do servidor NFS que você deseja sincronizar com a AWS.
-
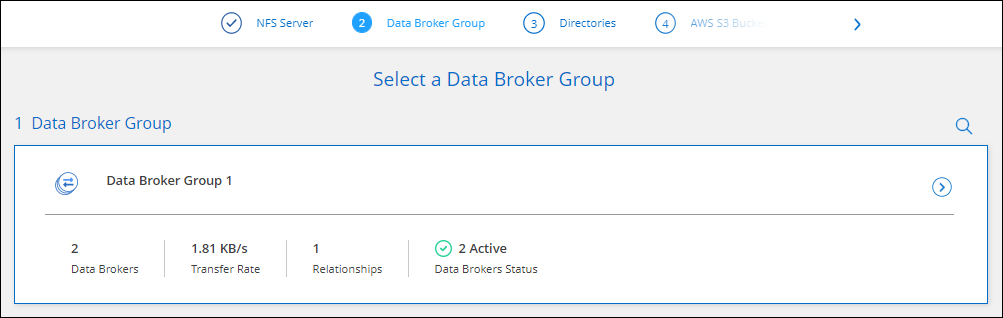
Na página Data Broker Group, siga as instruções para criar uma máquina virtual do data broker na AWS, Azure ou Google Cloud Platform, ou para instalar o software do data broker em um host Linux existente.
Para mais detalhes, consulte as seguintes páginas:
-
Depois de instalar o data broker, selecione Continuar.
-
Na página Diretórios, selecione um diretório ou subdiretório de nível superior.
Se Copiar e Sincronizar não conseguir recuperar as exportações, selecione Adicionar Exportação Manualmente e insira o nome de uma exportação NFS.

Se você quiser sincronizar mais de um diretório no servidor NFS, será necessário criar relacionamentos de sincronização adicionais após terminar. -
Na página AWS S3 Bucket, selecione um bucket:
-
Faça uma busca detalhada para selecionar uma pasta existente dentro do bucket ou para selecionar uma nova pasta que você criar dentro do bucket.
-
Selecione Adicionar à lista para selecionar um bucket S3 que não esteja associado à sua conta AWS. "Permissões específicas devem ser aplicadas ao bucket S3" .
-
-
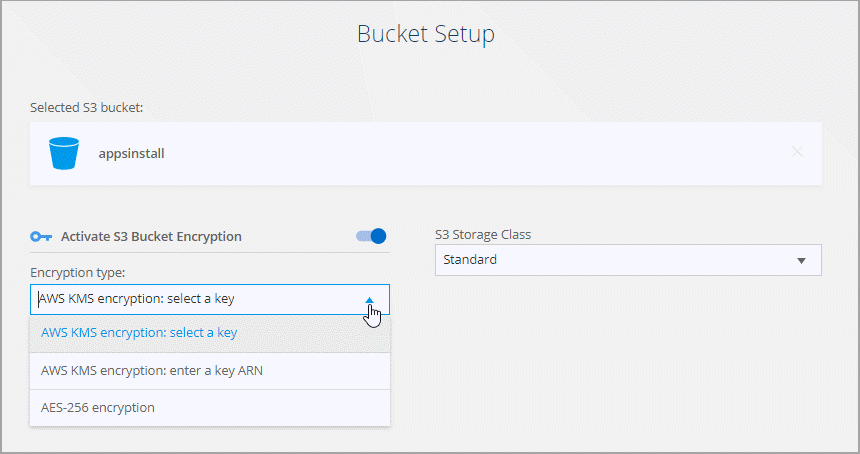
Na página Configuração do bucket, configure o bucket:
-
Escolha se deseja habilitar a criptografia do bucket S3 e, em seguida, selecione uma chave AWS KMS, insira o ARN de uma chave KMS ou selecione a criptografia AES-256.
-
Selecione uma classe de armazenamento S3. "Veja as classes de armazenamento suportadas" .
-
-
Na página Configurações, defina como os arquivos e pastas de origem são sincronizados e mantidos no local de destino:
- Agendar
-
Escolha uma programação recorrente para sincronizações futuras ou desative a programação de sincronização. Você pode agendar um relacionamento para sincronizar dados a cada 1 minuto.
- Tempo limite de sincronização
-
Defina se o Copiar e Sincronizar deve cancelar uma sincronização de dados se a sincronização não for concluída no número especificado de minutos, horas ou dias.
- Notificações
-
Permite que você escolha se deseja receber notificações de cópia e sincronização no Centro de notificações do NetApp Console. Você pode habilitar notificações para sincronizações de dados bem-sucedidas, sincronizações de dados com falha e sincronizações de dados canceladas.
- Tentativas
-
Defina o número de vezes que o Copiar e Sincronizar deve tentar sincronizar um arquivo novamente antes de ignorá-lo.
- Sincronização contínua
-
Após a sincronização inicial de dados, o Copy and Sync monitora as alterações no bucket S3 de origem ou no bucket do Google Cloud Storage e sincroniza continuamente quaisquer alterações no destino conforme elas ocorrem. Não há necessidade de verificar novamente a fonte em intervalos programados.
Esta configuração está disponível somente ao criar um relacionamento de sincronização e quando você sincroniza dados de um bucket do S3 ou do Google Cloud Storage para o armazenamento de Blobs do Azure, CIFS, Google Cloud Storage, IBM Cloud Object Storage, NFS, S3 e StorageGRID ou do armazenamento de Blobs do Azure para o armazenamento de Blobs do Azure, CIFS, Google Cloud Storage, IBM Cloud Object Storage, NFS e StorageGRID.
Se você habilitar esta configuração, ela afetará outros recursos da seguinte forma:
-
O agendamento de sincronização está desabilitado.
-
As seguintes configurações são revertidas para seus valores padrão: Tempo limite de sincronização, Arquivos modificados recentemente e Data de modificação.
-
Se S3 for a origem, o filtro por tamanho estará ativo somente em eventos de cópia (não em eventos de exclusão).
-
Depois que o relacionamento for criado, você só poderá acelerá-lo ou excluí-lo. Você não pode abortar sincronizações, modificar configurações ou visualizar relatórios.
É possível criar um relacionamento de Sincronização Contínua com um bucket externo. Para fazer isso, siga estes passos:
-
Acesse o console do Google Cloud para o projeto do bucket externo.
-
Acesse Armazenamento em nuvem > Configurações > Conta de serviço de armazenamento em nuvem.
-
Atualize o arquivo local.json:
{ "protocols": { "gcp": { "storage-account-email": <storage account email> } } } -
Reinicie o corretor de dados:
-
sudo pm2 parar tudo
-
sudo pm2 iniciar tudo
-
-
Crie um relacionamento de Sincronização Contínua com o bucket externo relevante.
Um corretor de dados usado para criar um relacionamento de sincronização contínua com um bucket externo não poderá criar outro relacionamento de Sincronização Contínua com um bucket em seu projeto.
-
-
- Comparar por
-
Escolha se Copiar e Sincronizar deve comparar determinados atributos ao determinar se um arquivo ou diretório foi alterado e deve ser sincronizado novamente.
Mesmo se você desmarcar esses atributos, o Copiar e Sincronizar ainda comparará a origem com o destino, verificando os caminhos, tamanhos de arquivo e nomes de arquivo. Se houver alguma alteração, ele sincroniza esses arquivos e diretórios.
Você pode escolher habilitar ou desabilitar Copiar e Sincronizar comparando os seguintes atributos:
-
mtime: A última hora de modificação de um arquivo. Este atributo não é válido para diretórios.
-
uid, gid e mode: sinalizadores de permissão para Linux.
-
- Copiar para Objetos
-
Habilite esta opção para copiar metadados e tags de armazenamento de objetos. Se um usuário alterar os metadados na fonte, o Copiar e Sincronizar copiará esse objeto na próxima sincronização, mas se um usuário alterar as tags na fonte (e não os dados em si), o Copiar e Sincronizar não copiará o objeto na próxima sincronização.
Você não pode editar esta opção depois de criar o relacionamento.
A cópia de tags é suportada com relacionamentos de sincronização que incluem o Azure Blob ou um ponto de extremidade compatível com S3 (S3, StorageGRID ou IBM Cloud Object Storage) como destino.
A cópia de metadados é suportada com relacionamentos "nuvem para nuvem" entre qualquer um dos seguintes pontos de extremidade:
-
AWS S3
-
Blob do Azure
-
Armazenamento em nuvem do Google
-
Armazenamento de objetos em nuvem da IBM
-
StorageGRID
-
- Arquivos modificados recentemente
-
Escolha excluir arquivos que foram modificados recentemente antes da sincronização agendada.
- Excluir arquivos na origem
-
Escolha excluir arquivos do local de origem depois que Copiar e Sincronizar copiar os arquivos para o local de destino. Esta opção inclui o risco de perda de dados porque os arquivos de origem são excluídos após serem copiados.
Se você habilitar esta opção, também precisará alterar um parâmetro no arquivo local.json no data broker. Abra o arquivo e atualize-o da seguinte maneira:
{ "workers":{ "transferrer":{ "delete-on-source": true } } }Após atualizar o arquivo local.json, você deve reiniciar:
pm2 restart all. - Excluir arquivos no alvo
-
Escolha excluir arquivos do local de destino, caso eles tenham sido excluídos da origem. O padrão é nunca excluir arquivos do local de destino.
- Tipos de arquivo
-
Defina os tipos de arquivo a serem incluídos em cada sincronização: arquivos, diretórios, links simbólicos e links físicos.
Links físicos estão disponíveis somente para relacionamentos NFS para NFS não seguros. Os usuários estarão limitados a um processo de scanner e uma simultaneidade de scanner, e as varreduras devem ser executadas a partir de um diretório raiz. - Excluir extensões de arquivo
-
Especifique a regex ou as extensões de arquivo a serem excluídas da sincronização digitando a extensão do arquivo e pressionando Enter. Por exemplo, digite log ou .log para excluir arquivos *.log. Um separador não é necessário para múltiplas extensões. O vídeo a seguir fornece uma breve demonstração:
Excluir extensões de arquivo para um relacionamento de sincronização
Regex, ou expressões regulares, são diferentes de curingas ou expressões globais. Este recurso somente funciona com regex. - Excluir diretórios
-
Especifique no máximo 15 regex ou diretórios a serem excluídos da sincronização digitando o nome ou o caminho completo do diretório e pressionando Enter. Os diretórios .copy-offload, .snapshot e ~snapshot são excluídos por padrão.
Regex, ou expressões regulares, são diferentes de curingas ou expressões globais. Este recurso somente funciona com regex. - Tamanho do arquivo
-
Escolha sincronizar todos os arquivos, independentemente do tamanho, ou apenas os arquivos que estejam em um intervalo de tamanho específico.
- Data de modificação
-
Escolha todos os arquivos, independentemente da data da última modificação, arquivos modificados após uma data específica, antes de uma data específica ou entre um intervalo de tempo.
- Data de criação
-
Quando um servidor SMB é a origem, essa configuração permite sincronizar arquivos que foram criados após uma data específica, antes de uma data específica ou entre um intervalo de tempo específico.
- ACL - Lista de Controle de Acesso
-
Copie somente ACLs, somente arquivos ou ACLs e arquivos de um servidor SMB habilitando uma configuração ao criar um relacionamento ou depois de criar um relacionamento.
-
Na página Tags/Metadados, escolha se deseja salvar um par chave-valor como uma tag em todos os arquivos transferidos para o bucket do S3 ou atribuir um par chave-valor de metadados em todos os arquivos.
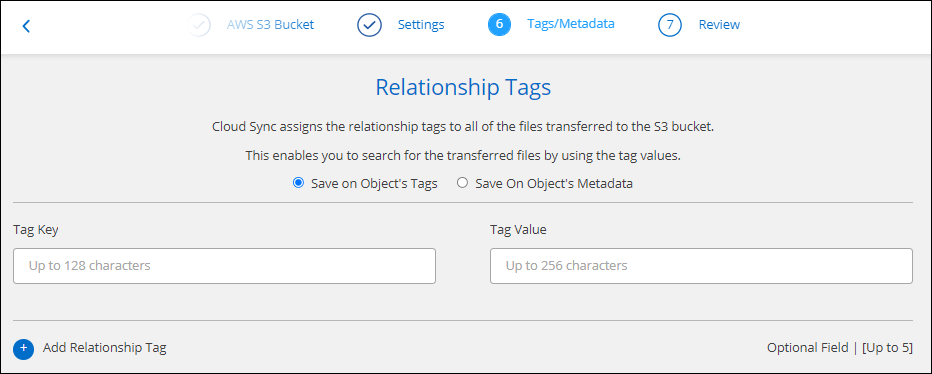

Esse mesmo recurso está disponível ao sincronizar dados com o StorageGRID e o IBM Cloud Object Storage. Para o Azure e o Google Cloud Storage, somente a opção de metadados está disponível. -
Revise os detalhes do relacionamento de sincronização e selecione Criar relacionamento.
Resultado
Copiar e sincronizar inicia a sincronização de dados entre a origem e o destino. Estatísticas de sincronização sobre quanto tempo a sincronização levou, se ela foi interrompida e quantos arquivos foram copiados, verificados ou excluídos estão disponíveis. Você pode então gerenciar seu "sincronizar relacionamentos" , "gerencie seus corretores de dados" , ou "crie relatórios para otimizar seu desempenho e configuração" .
Crie relacionamentos de sincronização a partir da NetApp Data Classification
O Copy and Sync é integrado ao NetApp Data Classification. Na NetApp Data Classification, você pode selecionar os arquivos de origem que deseja sincronizar com um local de destino usando Copiar e sincronizar.
Depois de iniciar uma sincronização de dados do NetApp Data Classification, todas as informações de origem ficam contidas em uma única etapa e exigem apenas que você insira alguns detalhes importantes. Em seguida, você escolhe o local de destino para o novo relacionamento de sincronização.