

 Inizia subito
Inizia subito
Verifica del progetto
 Suggerisci modifiche
Suggerisci modifiche
La progettazione di seconda generazione per la soluzione BeeGFS su NetApp è stata verificata utilizzando tre profili di configurazione a blocchi.
I profili di configurazione includono quanto segue:
-
Un singolo building block di base, che include gestione BeeGFS, metadati e servizi di storage.
-
Metadati BeeGFS più un building block per lo storage.
-
Un building block BeeGFS solo per lo storage.
I blocchi costitutivi erano collegati a due switch Mellanox Quantum InfiniBand (MQM8700). Dieci client BeeGFS sono stati collegati anche agli switch InfiniBand e utilizzati per eseguire utility di benchmark sintetiche.
La figura seguente mostra la configurazione BeeGFS utilizzata per validare la soluzione BeeGFS su NetApp.

Striping del file BeeGFS
Un vantaggio dei file system paralleli è la capacità di eseguire lo striping di singoli file su più destinazioni di storage, che potrebbero rappresentare volumi sullo stesso sistema di storage sottostante o su sistemi di storage diversi.
In BeeGFS, è possibile configurare lo striping per directory e per file per controllare il numero di destinazioni utilizzate per ogni file e per controllare la dimensione del blocco (o dimensione del blocco) utilizzata per ogni stripe di file. Questa configurazione consente al file system di supportare diversi tipi di carichi di lavoro e profili i/o senza dover riconfigurare o riavviare i servizi. È possibile applicare le impostazioni di stripe utilizzando beegfs-ctl Tool della riga di comando o con applicazioni che utilizzano l'API di striping. Per ulteriori informazioni, consultare la documentazione di BeeGFS per "Striping" e. "API di striping".
Per ottenere le migliori prestazioni, i modelli di stripe sono stati regolati durante l'intero test e vengono annotati i parametri utilizzati per ciascun test.
Test della larghezza di banda IOR: Client multipli
I test della larghezza di banda IOR hanno utilizzato OpenMPI per eseguire lavori paralleli dello strumento IOR (Synthetic i/o Generator Tool), disponibile presso "HPC GitHub") Su tutti i 10 nodi client a uno o più blocchi di base BeeGFS. Se non diversamente specificato:
-
Tutti i test utilizzavano l'i/o diretto con una dimensione di trasferimento di 1 MiB.
-
Lo striping dei file BeeGFS è stato impostato su una dimensione di blocco di 1 MB e su una destinazione per file.
I seguenti parametri sono stati utilizzati per IOR con il conteggio dei segmenti regolato per mantenere la dimensione del file aggregato a 5TiB per un building block e 40TiB per tre building block.
mpirun --allow-run-as-root --mca btl tcp -np 48 -map-by node -hostfile 10xnodes ior -b 1024k --posix.odirect -e -t 1024k -s 54613 -z -C -F -E -k
La figura seguente mostra i risultati del test IOR con un singolo building block di base BeeGFS (gestione, metadati e storage).
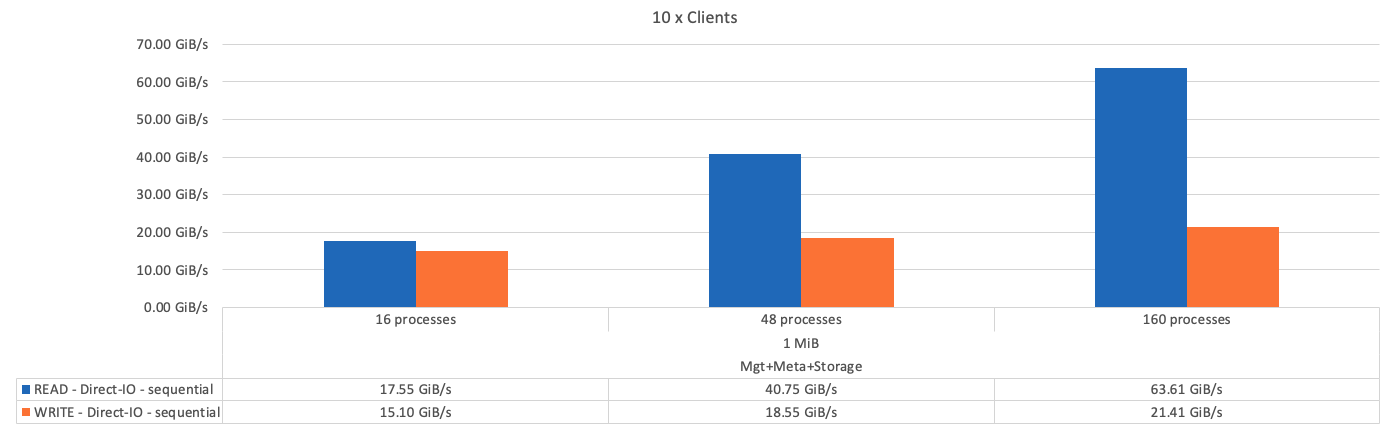
La figura seguente mostra i risultati del test IOR con un singolo metadata BeeGFS + building block dello storage.
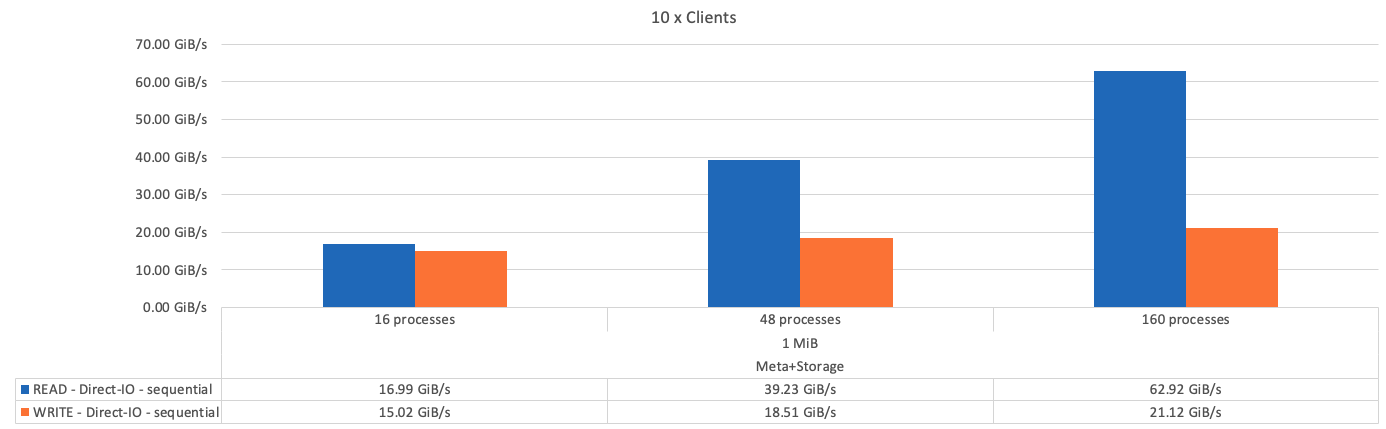
La figura seguente mostra i risultati del test IOR con un singolo building block BeeGFS solo per lo storage.
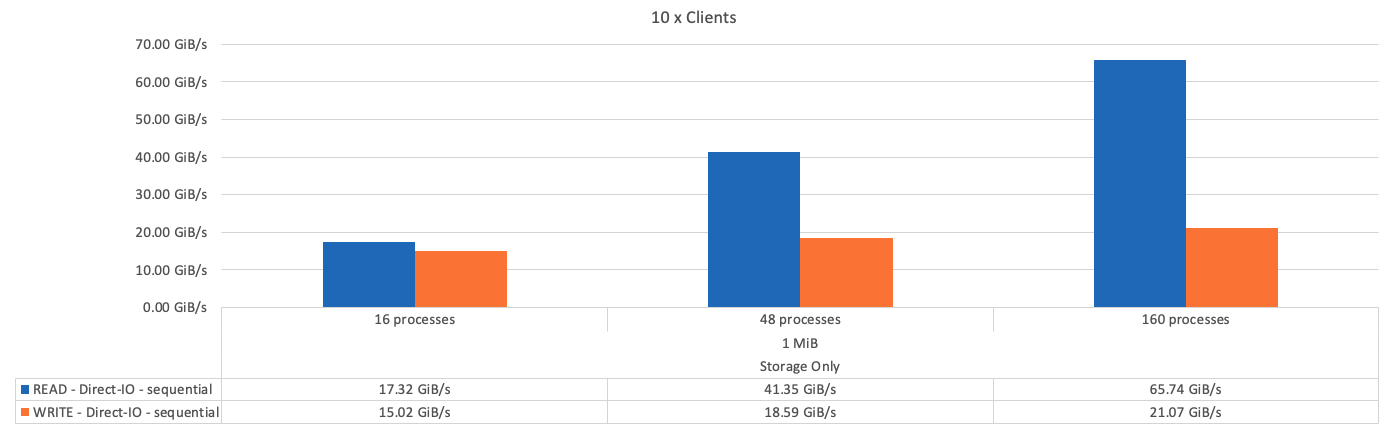
La figura seguente mostra i risultati del test IOR con tre blocchi di base BeeGFS.
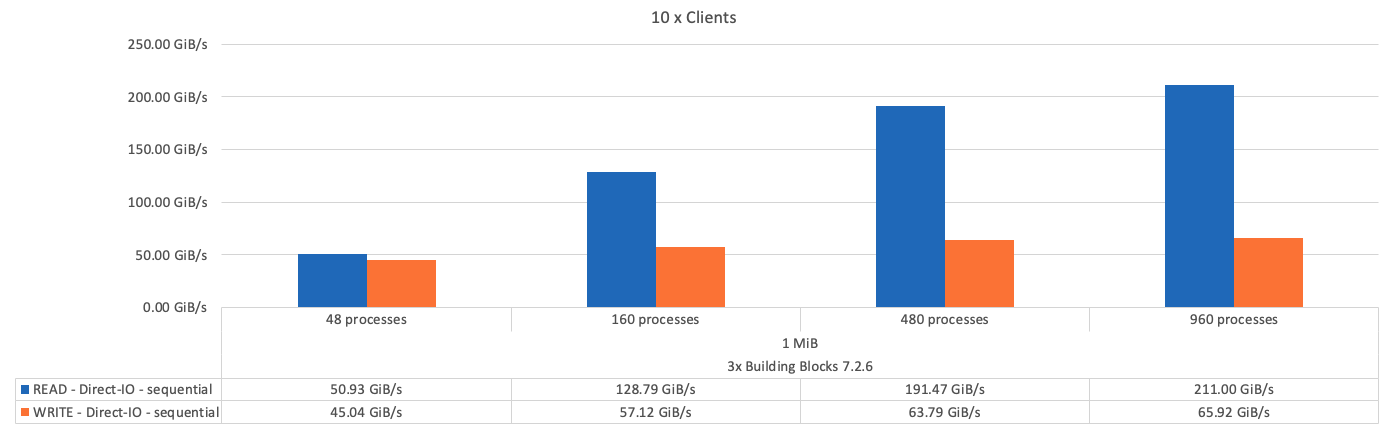
Come previsto, la differenza di performance tra il building block di base e i successivi metadati + building block di storage è trascurabile. Il confronto tra i metadati e il building block di storage e un building block di solo storage mostra un leggero aumento delle performance di lettura dovuto ai dischi aggiuntivi utilizzati come target di storage. Tuttavia, non vi è alcuna differenza significativa nelle prestazioni di scrittura. Per ottenere performance più elevate, è possibile aggiungere più elementi di base insieme per scalare le performance in modo lineare.
Test della larghezza di banda IOR: Singolo client
Il test della larghezza di banda IOR ha utilizzato OpenMPI per eseguire più processi IOR utilizzando un singolo server GPU dalle performance elevate per esplorare le performance ottenibili da un singolo client.
Questo test confronta anche il comportamento di rilettura e le performance di BeeGFS quando il client è configurato per utilizzare la paging-cache del kernel Linux (tuneFileCacheType = native) rispetto al valore predefinito buffered impostazione.
La modalità di caching nativa utilizza la paging-cache del kernel Linux sul client, consentendo alle operazioni di rilettura di provenire dalla memoria locale invece di essere ritrasmesse sulla rete.
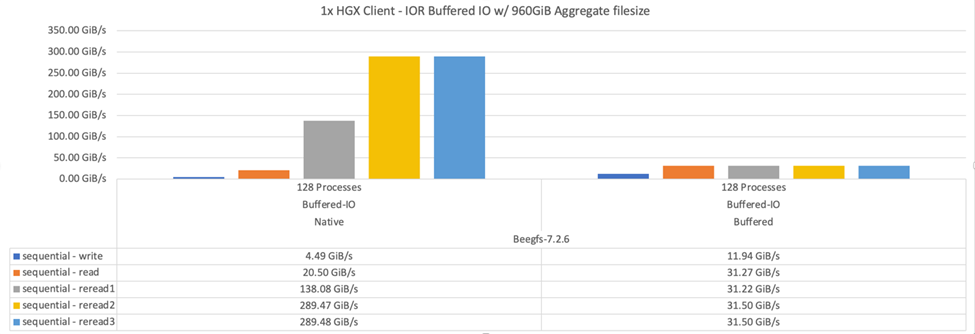
Il diagramma seguente mostra i risultati del test IOR con tre blocchi di base BeeGFS e un singolo client.

|
Lo striping di BeeGFS per questi test è stato impostato su una dimensione del blocco di 1 MB con otto destinazioni per file. |
Sebbene le performance di scrittura e lettura iniziale siano più elevate utilizzando la modalità buffer predefinita, per i carichi di lavoro che rileggono gli stessi dati più volte, la modalità caching nativa offre un significativo miglioramento delle performance. Questo miglioramento delle performance di rilettura è importante per i carichi di lavoro come il deep learning che rileggono lo stesso set di dati più volte in diverse epoche.
Test delle performance dei metadati
I test delle prestazioni dei metadati hanno utilizzato lo strumento MDTest (incluso come parte di IOR) per misurare le prestazioni dei metadati di BeeGFS. I test hanno utilizzato OpenMPI per eseguire lavori paralleli su tutti e dieci i nodi client.
I seguenti parametri sono stati utilizzati per eseguire il test di benchmark con il numero totale di processi scalati da 10 a 320 in incrementi di 2x e con una dimensione del file di 4k.
mpirun -h 10xnodes –map-by node np $processes mdtest -e 4k -w 4k -i 3 -I 16 -z 3 -b 8 -u
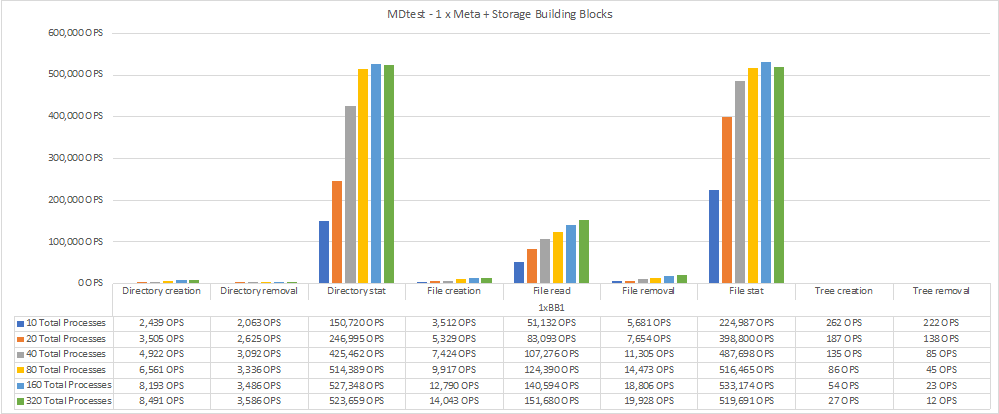
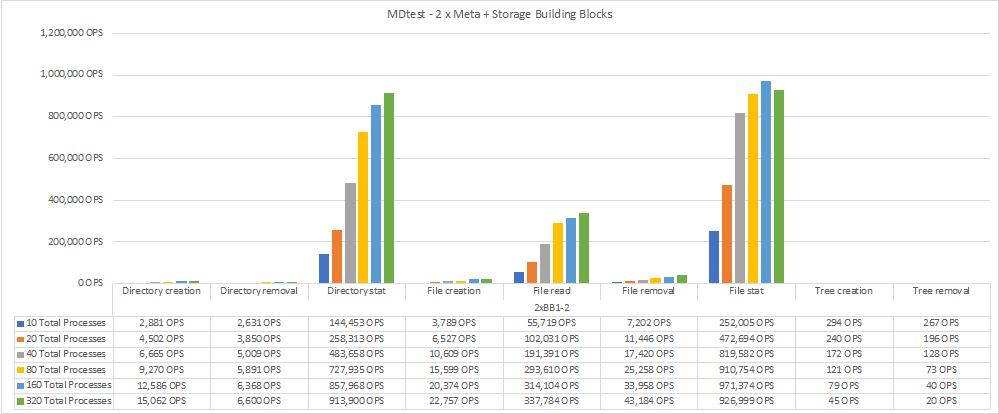
Le performance dei metadati sono state misurate prima con uno e due metadati + building block di storage per mostrare come le performance si ridimensionano aggiungendo ulteriori building block.
Il seguente diagramma mostra i risultati di MDTest con un solo metadata BeeGFS + blocchi di base dello storage.
Il seguente diagramma mostra i risultati di MDTest con due metadati BeeGFS + blocchi di base dello storage.
Validazione funzionale
Nell'ambito della convalida di questa architettura, NetApp ha eseguito diversi test funzionali, tra cui:
-
Errore di una singola porta InfiniBand client disattivando la porta dello switch.
-
Errore di una porta InfiniBand di un singolo server disattivando la porta dello switch.
-
Attivazione dello spegnimento immediato del server mediante BMC.
-
Posizionamento corretto di un nodo in standby e failover del servizio su un altro nodo.
-
Posizionamento corretto di un nodo di nuovo online e fallimento dei servizi di back nel nodo originale.
-
Spegnere uno degli switch InfiniBand utilizzando la PDU. Tutti i test sono stati eseguiti mentre era in corso il test di stress con
sysSessionChecksEnabled: falseSet di parametri sui client BeeGFS. Non sono stati osservati errori o interruzioni dell'i/O.
|
|
Si è verificato un problema noto (vedere "Changelog") Quando le connessioni RDMA client/server BeeGFS vengono interrompute inaspettatamente, a causa della perdita dell'interfaccia primaria (come definito nella connInterfacesFile) O un server BeeGFS non funzionante; l'i/o client attivo può bloccarsi per un massimo di dieci minuti prima della ripresa. Questo problema non si verifica quando i nodi BeeGFS vengono posizionati correttamente in standby o non sono in standby per la manutenzione pianificata o se TCP è in uso.
|
Convalida NVIDIA DGX A100 SuperPOD e BasePOD
NetApp ha validato una soluzione di storage per NVDIA DGX A100 SuperPOD utilizzando un file system BeeGFS simile costituito da tre blocchi di base con i metadati e il profilo di configurazione dello storage applicato. Il lavoro di qualificazione ha comportato il test della soluzione descritta da questo NVA con venti server GPU DGX A100 che eseguono una varietà di storage, machine learning e benchmark di deep learning. Tutto lo storage certificato per l'utilizzo in NVIDIA DGX A100 SuperPOD è certificato automaticamente per l'utilizzo anche nelle architetture NVIDIA BasePOD.
Per ulteriori informazioni, vedere "NVIDIA DGX SuperPOD con NetApp" e. "NVIDIA DGX BasePOD".