

 Commencez
Commencez
Vérification de la conception
 Suggérer des modifications
Suggérer des modifications
Le design de deuxième génération de la solution BeeGFS sur NetApp a été vérifié à l'aide de trois profils de configuration d'élément de base.
Les profils de configuration incluent les éléments suivants :
-
Un élément de base unique, incluant la gestion BeeGFS, les métadonnées et les services de stockage.
-
Des métadonnées BeeGFS plus un élément de base de stockage.
-
Un élément de base BeeGFS uniquement pour le stockage.
Les éléments de base ont été reliés à deux switchs Mellanox Quantum InfiniBand (MQM8700). Dix clients BeeGFS étaient également connectés aux commutateurs InfiniBand et utilisés pour exécuter des utilitaires de banc d'essai synthétiques.
La figure suivante montre la configuration BeeGFS utilisée pour valider la solution BeeGFS sur NetApp.

Répartition des fichiers BeeGFS
Les systèmes de fichiers parallèles ont notamment pour avantage de répartir les fichiers individuels sur plusieurs cibles de stockage, qui peuvent représenter des volumes sur les mêmes systèmes de stockage sous-jacents ou différents.
Dans BeeGFS, vous pouvez configurer la répartition par répertoire et par fichier pour contrôler le nombre de cibles utilisées pour chaque fichier et pour contrôler la taille chunksize (ou taille de bloc) utilisée pour chaque bande de fichier. Cette configuration permet au système de fichiers de prendre en charge différents types de charges de travail et de profils d'E/S sans avoir à reconfigurer ou à redémarrer des services. Vous pouvez appliquer les paramètres de bande à l'aide du beegfs-ctl Outil de ligne de commande ou avec des applications qui utilisent l'API de répartition. Pour plus d'informations, consultez la documentation BeeGFS pour "Répartition" et "API de répartition".
Pour obtenir les meilleures performances, les motifs de bande ont été ajustés tout au long des tests, et les paramètres utilisés pour chaque test sont notés.
Tests de bande passante IOR : plusieurs clients
Les tests de bande passante IOR ont utilisé OpenMPI pour exécuter des travaux parallèles du générateur d'E/S synthétique IOR (disponible à partir de "GitHub HPC") Sur l'ensemble des 10 nœuds clients à un ou plusieurs blocs de construction BeeGFS. Sauf mention contraire :
-
Tous les tests ont utilisé des E/S directes avec une taille de transfert de 1MiB.
-
La répartition des fichiers BeeGFS est définie sur une taille chunksize de 1 Mo et une cible par fichier.
Les paramètres suivants ont été utilisés pour IOR avec le nombre de segments ajusté afin de maintenir la taille de fichier d'agrégat à 5 Tio pour un élément de base et 40 Tio pour trois éléments de base.
mpirun --allow-run-as-root --mca btl tcp -np 48 -map-by node -hostfile 10xnodes ior -b 1024k --posix.odirect -e -t 1024k -s 54613 -z -C -F -E -k
La figure suivante montre les résultats du test IOR avec un seul élément de base BeeGFS (gestion, métadonnées et stockage).
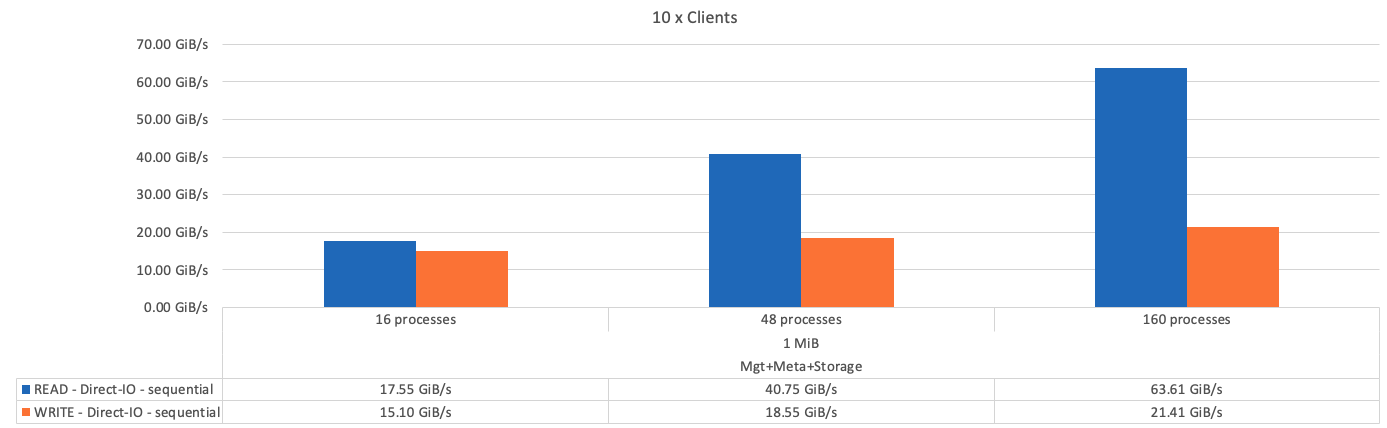
La figure suivante présente les résultats du test IOR avec un seul élément de base de stockage + métadonnées BeeGFS.

La figure suivante montre les résultats du test IOR avec un seul élément de base BeeGFS Storage uniquement.

La figure suivante montre les résultats du test IOR avec trois éléments de base BeeGFS.
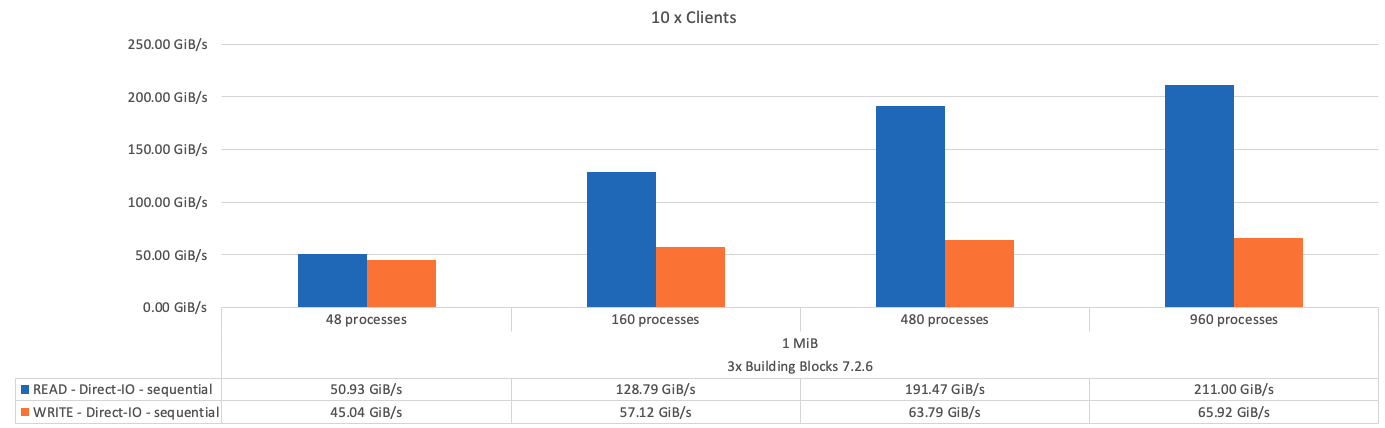
Comme on pouvait s'y attendre, la différence de performances entre l'élément de base et les métadonnées suivantes + l'élément de base du stockage est négligeable. En comparant les métadonnées + l'élément de base du stockage et un élément de base uniquement destiné au stockage, on constate une légère augmentation des performances de lecture en raison des disques supplémentaires utilisés comme cibles de stockage. Toutefois, il n'y a pas de différence significative dans les performances d'écriture. Pour améliorer les performances, vous pouvez ajouter plusieurs éléments de base pour faire évoluer les performances de manière linéaire.
Tests de bande passante IOR : client unique
Le test de bande passante IOR a utilisé OpenMPI pour exécuter plusieurs processus IOR à l'aide d'un seul serveur GPU hautes performances afin d'explorer les performances réalisables pour un même client.
Ce test compare également le comportement et les performances de relecture de BeeGFS lorsque le client est configuré pour utiliser le cache de page du noyau Linux (tuneFileCacheType = native) par rapport à la valeur par défaut buffered réglage.
Le mode de mise en cache native utilise le cache de page du noyau Linux sur le client, ce qui permet aux opérations de relecture de provenir de la mémoire locale au lieu d'être retransmises sur le réseau.
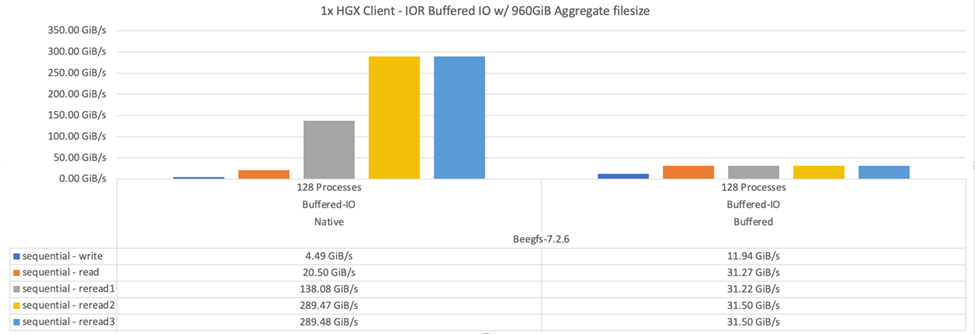
Le diagramme suivant montre les résultats du test IOR avec trois éléments de base BeeGFS et un seul client.

|
La répartition BeeGFS pour ces tests a été définie sur une taille chunksize de 1 Mo avec huit cibles par fichier. |
Bien que les performances d'écriture et de lecture initiale soient supérieures en mode tampon par défaut, pour les charges de travail qui relisent plusieurs fois les mêmes données, le mode de mise en cache natif a permis d'optimiser considérablement les performances. Cette amélioration des performances de relecture est importante pour les charges de travail telles que l'apprentissage profond qui relire le même dataset plusieurs fois sur plusieurs séries de tests.
Test de performance des métadonnées
Les tests de performance des métadonnées ont utilisé l'outil MDTest (inclus dans IOR) pour mesurer la performance des métadonnées de BeeGFS. Les tests ont utilisé OpenMPI pour exécuter des travaux parallèles sur les dix nœuds clients.
Les paramètres suivants ont été utilisés pour exécuter le test de référence avec le nombre total de processus passe de 10 à 320 par pas de 2x et avec une taille de fichier de 4 ko.
mpirun -h 10xnodes –map-by node np $processes mdtest -e 4k -w 4k -i 3 -I 16 -z 3 -b 8 -u
Les performances des métadonnées ont été mesurées en premier avec un ou deux blocs de base de stockage + métadonnées afin de montrer l'évolution des performances en ajoutant des éléments de base supplémentaires.
Le diagramme suivant montre les résultats MDTest avec un bloc de construction BeeGFS + stockage.

Le diagramme suivant montre les résultats MDTest avec deux métadonnées BeeGFS + des modules de stockage.

Validation fonctionnelle
Dans le cadre de la validation de cette architecture, NetApp a effectué plusieurs tests fonctionnels :
-
Défaillance d'un seul port InfiniBand client en désactivant le port de commutateur.
-
Défaillance d'un seul port InfiniBand de serveur en désactivant le port du commutateur.
-
Déclenchement d'une mise hors tension immédiate d'un serveur à l'aide du contrôleur BMC.
-
Placement normal d'un nœud en veille et basculement de service vers un autre nœud.
-
Il est normal de remettre un nœud en ligne et de renvoyer les services vers le nœud d'origine.
-
Mise hors tension de l'un des commutateurs InfiniBand à l'aide de la PDU. Tous les tests ont été réalisés alors que les tests de stress étaient en cours avec le
sysSessionChecksEnabled: falseParamètre défini sur les clients BeeGFS. Aucune erreur ni interruption des E/S n'a été observée.
|
|
Il y a un problème connu (voir "Changement") Lorsque les connexions RDMA BeeGFS client/serveur sont interrompues de façon inattendue, soit par la perte de l'interface principale (comme défini dans la section connInterfacesFile) Ou un serveur BeeGFS est défaillant ; les E/S du client actif peuvent se bloquer pendant dix minutes avant de reprendre. Ce problème ne se produit pas lorsque les nœuds BeeGFS sont correctement placés en attente pour la maintenance planifiée ou si TCP est utilisé.
|
Validation du superPOD et du BasePOD NVIDIA DGX A100
NetApp a validé une solution de stockage pour NVIDIA DGX A100 SuperPOD à l'aide d'un système de fichiers BeeGFS constitué de trois éléments de base avec les métadonnées plus le profil de configuration du stockage appliqué. L'effort de qualification a participé au test de la solution décrite par cette architecture NVA avec vingt serveurs GPU DGX A100 exécutant plusieurs bancs d'essai de stockage, d'apprentissage machine et d'apprentissage profond. Tout le stockage certifié pour une utilisation dans le superPOD DGX A100 de NVIDIA est automatiquement certifié pour une utilisation dans les architectures NVIDIA BasePOD.
Pour plus d'informations, voir "NVIDIA DGX SuperPOD avec NetApp" et "NVIDIA DGX BasePOD".