

 はじめに
はじめに
設計の検証
 変更を提案
変更を提案
NetApp解決策 のBeeGFSの第2世代設計は、3つのビルディングブロック構成プロファイルを使用して検証されました。
構成プロファイルには、次のものが含まれます。
-
BeeGFSの管理、メタデータ、ストレージサービスなど、単一のベースとなるビルディングブロックです。
-
BeeGFSメタデータとストレージビルディングブロック
-
BeeGFSストレージ専用のビルディングブロック。
このビルディングブロックは、2台のMellanox Quantum InfiniBand(M8700)スイッチに接続されました。また、10個のBeeGFSクライアントもInfiniBandスイッチに接続し、総合ベンチマークユーティリティの実行に使用しました。
次の図は、NetApp解決策 でBeeGFSを検証するために使用するBeeGFS設定を示しています。

BeeGFSファイルのストライピング
並列ファイルシステムの利点は、複数のストレージターゲットに個別のファイルをストライプすることです。これは、同一または異なる基盤となるストレージシステム上のボリュームを表すことができます。
BeeGFSでは'各ファイルに使用するターゲットの数を制御し'各ファイルストライプに使用するチャンクサイズ(またはブロックサイズ)を制御するために'ディレクトリ単位およびファイル単位でストライピングを構成できますこの構成では、サービスを再設定したり再開したりすることなく、ファイルシステムがさまざまなタイプのワークロードやI/Oプロファイルをサポートできます。ストライプ設定を適用するには'beegfs-ctl'コマンドラインツールを使用するか'ストライピングAPIを使用するアプリケーションを使用します詳細については、のBeeGFSのマニュアルを参照してください "ストライピング" および "ストライピングAPI"。
最高のパフォーマンスを得るために、テスト全体を通してストライプパターンを調整し、各テストに使用するパラメータを記録しました。
IOR帯域幅テスト:複数のクライアント
IOR帯域幅テストでは、OpenMPIを使用して、統合I/OジェネレータツールIOR(から入手可能)の並列ジョブを実行しました "HPC GitHub")を使用して、10のすべてのクライアントノードから1つ以上のBeeGFSビルディングブロックにアクセスします。特に明記されていない限り:
-
すべてのテストで、直接I/Oを使用し、転送サイズは1MiBに設定しました。
-
BeeGFSファイルのストライピングは'1 MBのチャンクサイズと1ファイルあたり1つのターゲットに設定されました
IORでは次のパラメータを使用し、1つのビルディングブロックではアグリゲートのファイルサイズが5TiB、3つのビルディングブロックでは40TiBにセグメント数を調整しました。
mpirun --allow-run-as-root --mca btl tcp -np 48 -map-by node -hostfile 10xnodes ior -b 1024k --posix.odirect -e -t 1024k -s 54613 -z -C -F -E -k
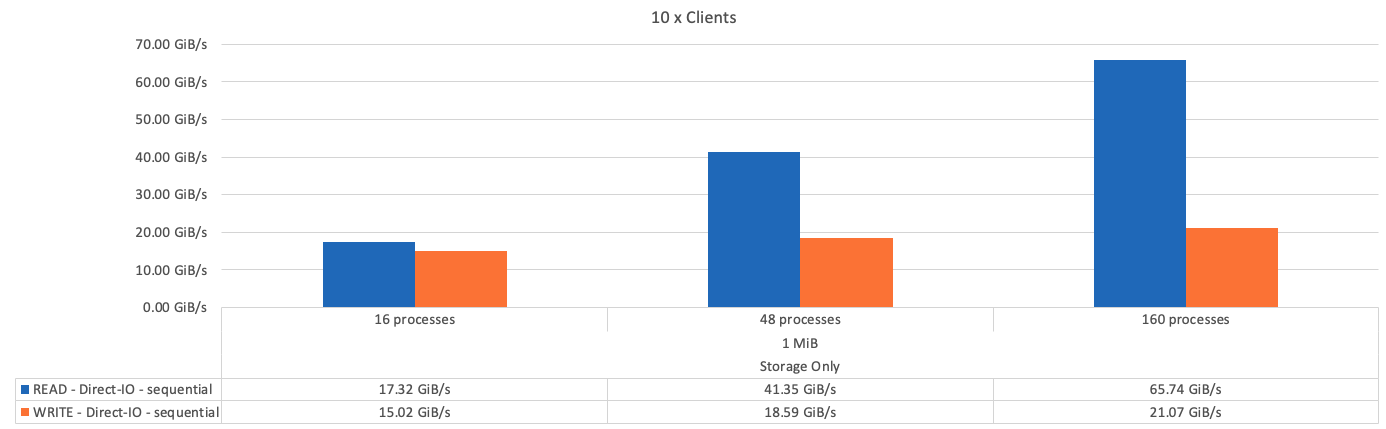
次の図に、1つのBeeGFSベース(管理、メタデータ、ストレージ)ビルディングブロックを使用したIORテスト結果を示します。
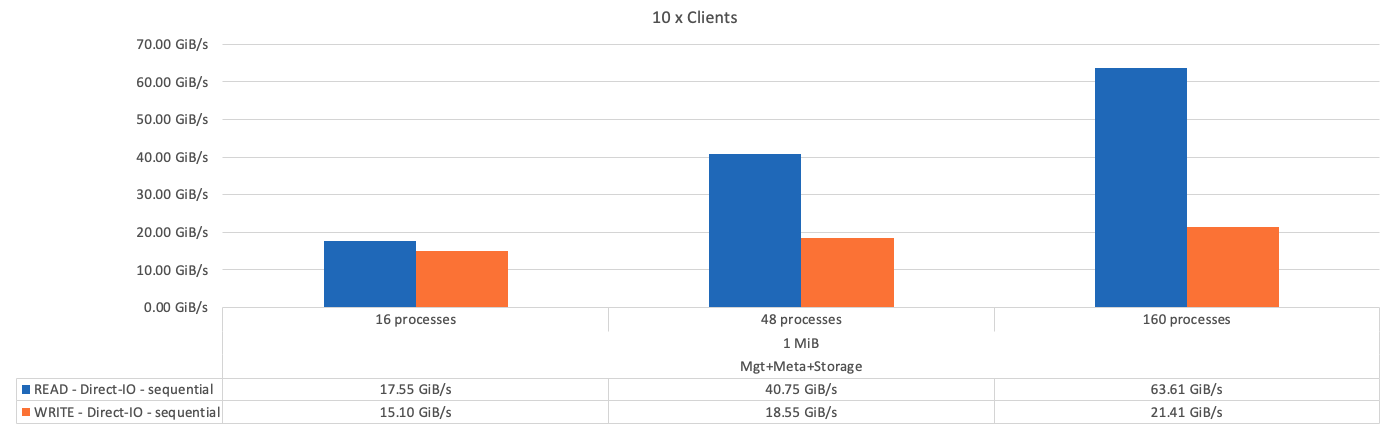
次の図は、1つのBeeGFSメタデータとストレージビルディングブロックを使用したIORテスト結果を示しています。
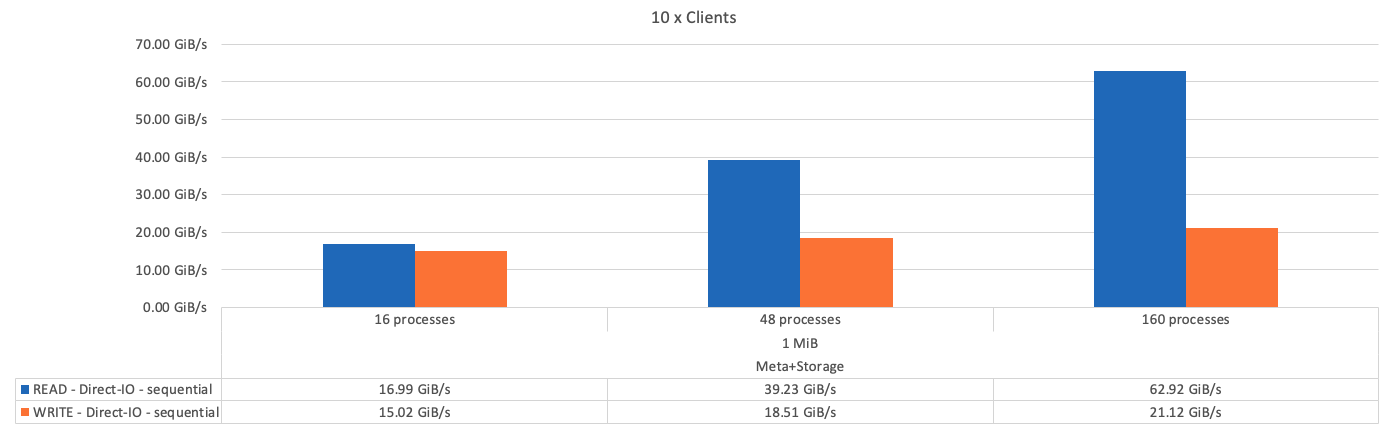
次の図に、1つのBeeGFSストレージ専用ビルディングブロックを使用したIORテスト結果を示します。
次の図に、3つのBeeGFSビルディングブロックを使用したIORテスト結果を示します。
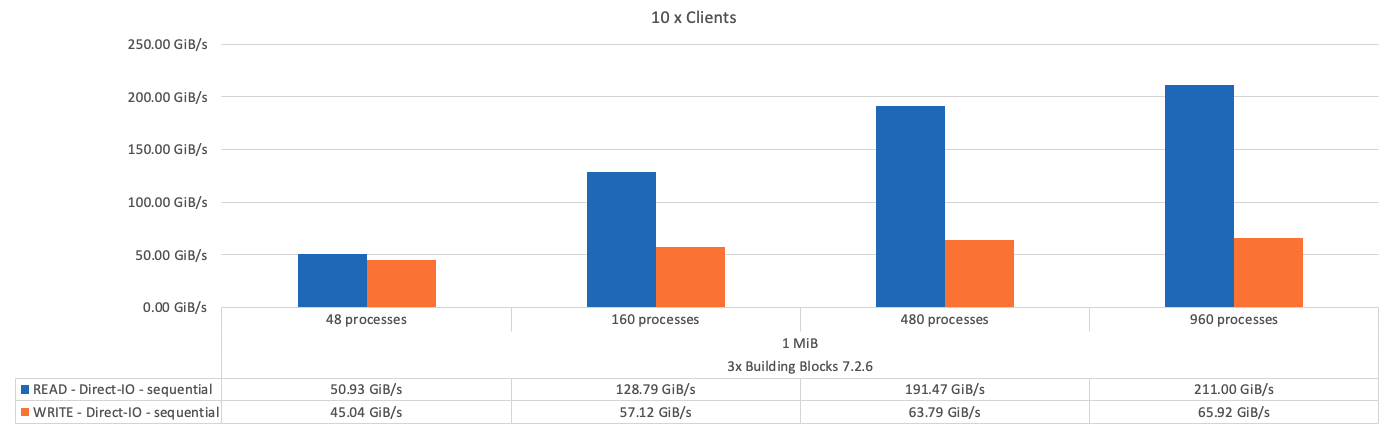
基本となるビルディングブロックと後続のメタデータとストレージビルディングブロックのパフォーマンスの違いは、想定どおりごくわずかです。メタデータとストレージのビルディングブロックおよびストレージ専用のビルディングブロックを比較した場合、ストレージターゲットとして使用される追加のドライブが原因で読み取りパフォーマンスがわずかに向上します。ただし、書き込みパフォーマンスに大きな違いはありません。パフォーマンスを向上させるには、複数のビルディングブロックを1つに追加して、パフォーマンスを直線的に拡張します。
IOR帯域幅テスト:単一クライアント
IOR帯域幅テストでは、OpenMPIを使用して、1台の高性能GPUサーバを使用して複数のIORプロセスを実行し、1台のクライアントで実現可能なパフォーマンスを検証しました。
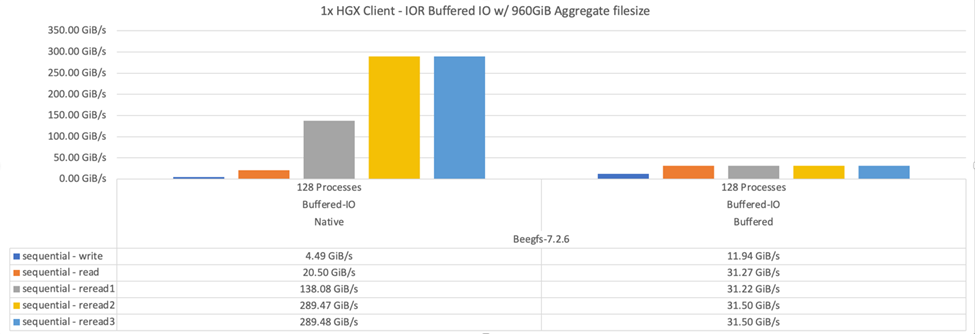
このテストでは'クライアントがLinuxカーネルのページキャッシュ(`tuneFileCacheType=native')を使用するように構成されている場合に'BeeGFSの再読み取り動作とパフォーマンスを'デフォルトのバッファ設定と比較します
ネイティブ・キャッシュ・モードでは'クライアント上のLinuxカーネル・ページ・キャッシュを使用するため'ネットワーク上で再送信されるのではなく'ローカル・メモリから再読み取り操作を行うことができます
次の図は、3つのBeeGFSビルディングブロックと1つのクライアントを使用したIORテスト結果を示しています。

|
これらのテストのBeeGFSストライピングは'ファイルあたり8つのターゲットを持つ1MBのチャンクサイズに設定されました |
デフォルトのバッファモードを使用した場合の書き込みと初期の読み取りパフォーマンスは向上しますが、同じデータを複数回再読み取りするワークロードでは、ネイティブのキャッシュモードを使用するとパフォーマンスが大幅に向上します。ディープラーニングなどのワークロードで多くの期間にわたって同じデータセットを複数回再読み取りする場合は、読み取りパフォーマンスの向上が重要になります。
メタデータパフォーマンステスト
メタデータパフォーマンステストでは、MDTestツール(IORの一部として含まれる)を使用してBeeGFSのメタデータパフォーマンスを測定しました。テストでは、OpenMPIを使用して、10個のクライアントノードすべてで並列ジョブを実行しました。
以下のパラメータを使用して、ステップ2xでステップ10から320まで、ファイルサイズ4Kのプロセスの合計数を使用して、ベンチマークテストを実行しました。
mpirun -h 10xnodes –map-by node np $processes mdtest -e 4k -w 4k -i 3 -I 16 -z 3 -b 8 -u
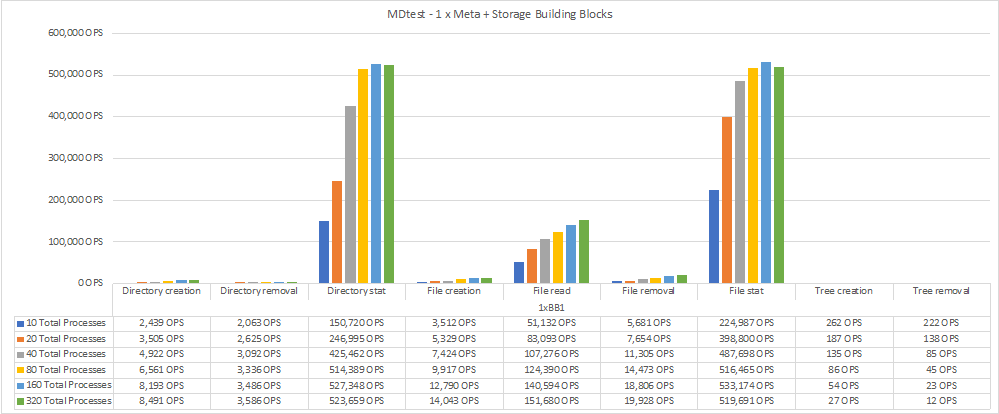
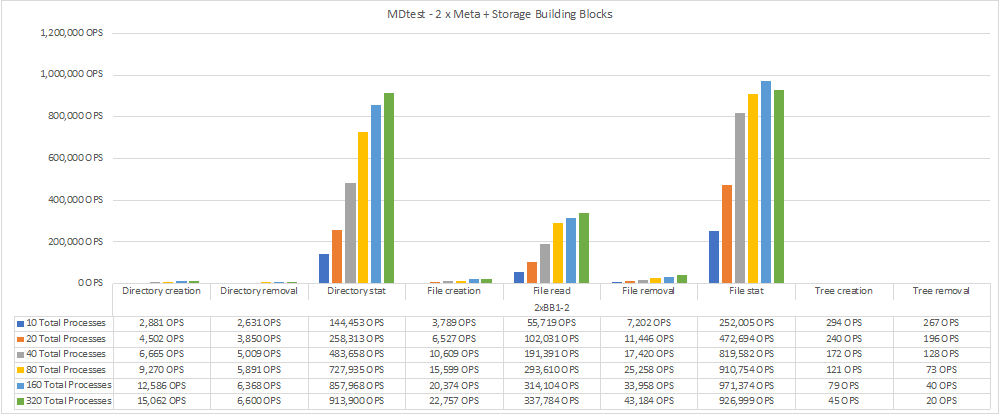
メタデータパフォーマンスは、まずメタデータとストレージのビルディングブロックを2つずつ使用して測定し、ビルディングブロックを追加してパフォーマンスがどのようにスケールアップするかを示しました。
次の図は、BeeGFSメタデータとストレージビルディングブロックを1つずつ使用したMDTestの結果を示しています。
次の図は、2つのBeeGFSメタデータとストレージビルディングブロックを使用したMDTestの結果を示しています。
機能検証
このアーキテクチャの検証の一環として、ネットアップは次の機能テストをいくつか実施しました。
-
スイッチポートを無効にして、単一のクライアントInfiniBandポートを障害状態にします。
-
スイッチポートを無効にして、単一サーバのInfiniBandポートを障害状態にします。
-
BMCを使用した即時サーバ電源オフのトリガー
-
ノードを正常にスタンバイにし、別のノードにサービスをフェイルオーバーします。
-
ノードを正常にオンラインに戻し、元のノードにサービスをフェイルバックします。
-
PDUを使用している一方のInfiniBandスイッチの電源をオフにします。すべてのテストは、BeeGFSクライアントで設定された「sysSessionChecksEnabled:false」パラメータを使用して、ストレステストの実行中に実行されました。エラーやI/Oの中断は発生しませんでした。
|
|
既知の問題 がある(を参照) "変更ログ") BeeGFSクライアント/サーバRDMA接続が予期せず中断される場合は、プライマリインターフェイスの喪失(「connInterfacesFile」で定義)またはBeeGFSサーバの障害のいずれかによって、アクティブなクライアントI/Oが最大10分間ハングアップしてから再開します。この問題 は、計画的メンテナンスのためにBeeGFSノードが正常に配置され、スタンバイ状態から外れたとき、またはTCPが使用中のときは発生しません。 |
NVIDIA DGX A100 SuperPODおよびBasePODの検証
ネットアップでは、3つのビルディングブロックにメタデータとストレージ構成プロファイルが適用されたBeeGFSファイルシステムを使用して、NVDIA DGX A100 SuperPOD向けのストレージ解決策 の検証を実施しました。認定には、このNVAで説明した解決策 を、さまざまなストレージ、機械学習、ディープラーニングのベンチマークを実行している20台のDGX A100 GPUサーバでテストすることが含まれます。NVIDIAのDGX A100 SuperPODの使用が認定されたストレージは、NVIDIA BasePODアーキテクチャでも自動的に認定されます。
詳細については、を参照してください "NVIDIA DGX SuperPODとネットアップ" および "NVIDIA DGX BasePOD"。