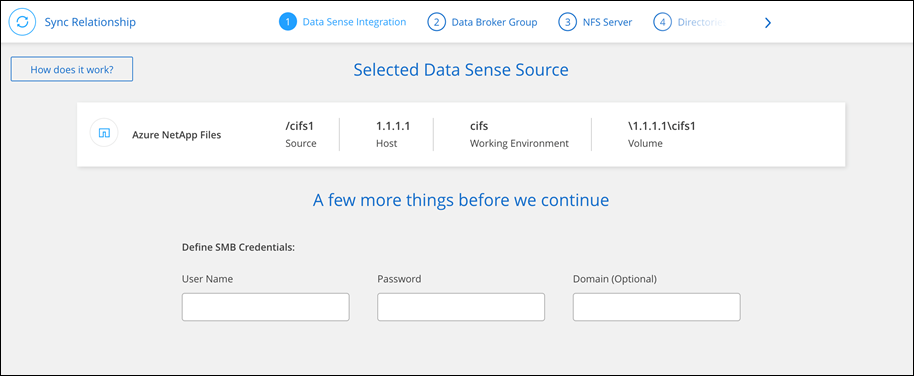
NetApp Copy and Syncで同期関係を作成する
 変更を提案
変更を提案
同期関係を作成すると、 NetApp Copy and Syncソースからターゲットにファイルがコピーされます。最初のコピーの後、コピーと同期は変更されたデータを 24 時間ごとに同期します。
一部のタイプの同期関係を作成するには、まずNetApp Consoleでシステムを作成する必要があります。
特定の種類のシステムの同期関係を作成する
次のいずれかの同期関係を作成する場合は、まずシステムを作成または検出する必要があります。
-
Amazon FSx for ONTAP
-
Azure NetApp Files
-
Cloud Volumes ONTAP
-
オンプレミスのONTAPクラスター
-
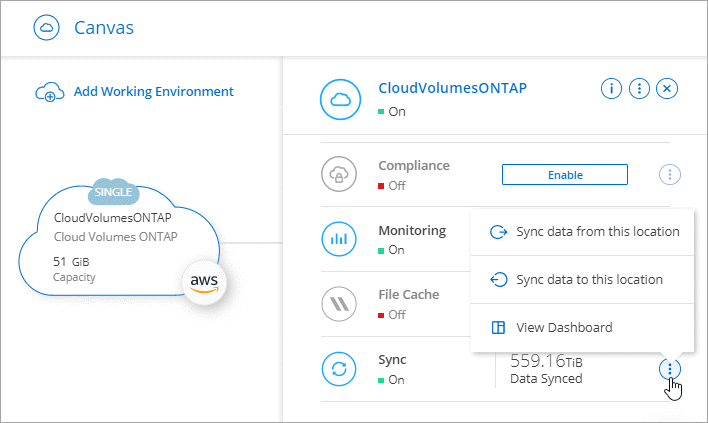
システムを作成または検出します。
-
*システムページ*を選択します。
-
上記のいずれかのタイプに一致するシステムを選択してください。
-
[同期]の横にあるアクション メニューを選択します。
-
*この場所からデータを同期*または*この場所にデータを同期*を選択し、プロンプトに従って同期関係を設定します。
他の種類の同期関係を作成する
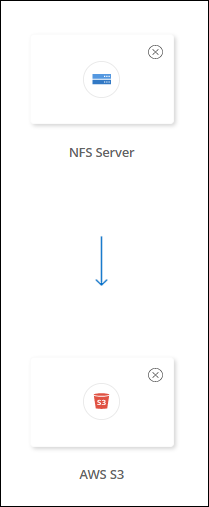
Amazon FSx for ONTAP、 Azure NetApp Files、 Cloud Volumes ONTAP、またはオンプレミスのONTAPクラスター以外のサポートされているストレージタイプとの間でデータを同期するには、次の手順に従います。以下の手順は、NFS サーバーから S3 バケットへの同期関係を設定する方法を示した例です。
-
NetApp Consoleで、[同期] を選択します。
-
*同期関係の定義*ページで、ソースとターゲットを選択します。
次の手順は、NFS サーバーから S3 バケットへの同期関係を作成する方法の例を示しています。
-
NFS サーバー ページで、AWS に同期する NFS サーバーの IP アドレスまたは完全修飾ドメイン名を入力します。
-
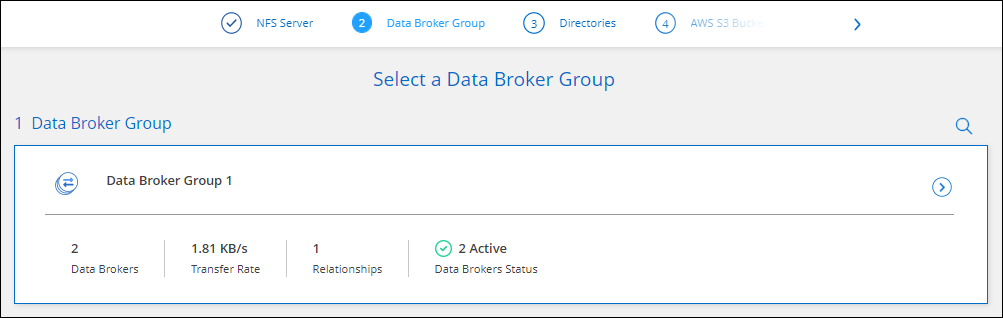
データ ブローカー グループ ページで、プロンプトに従って、AWS、Azure、または Google Cloud Platform にデータ ブローカー仮想マシンを作成するか、既存の Linux ホストにデータ ブローカー ソフトウェアをインストールします。
詳細については、次のページを参照してください。
-
データ ブローカーをインストールしたら、[続行] を選択します。
-
*ディレクトリ*ページで、最上位ディレクトリまたはサブディレクトリを選択します。
コピーと同期でエクスポートを取得できない場合は、「エクスポートを手動で追加」を選択し、NFS エクスポートの名前を入力します。

NFS サーバー上の複数のディレクトリを同期する場合は、完了後に追加の同期関係を作成する必要があります。 -
AWS S3 バケット ページで、バケットを選択します。
-
ドリルダウンしてバケット内の既存のフォルダを選択するか、バケット内に作成した新しいフォルダを選択します。
-
AWS アカウントに関連付けられていない S3 バケットを選択するには、[リストに追加] を選択します。"S3バケットに特定の権限を適用する必要がある" 。
-
-
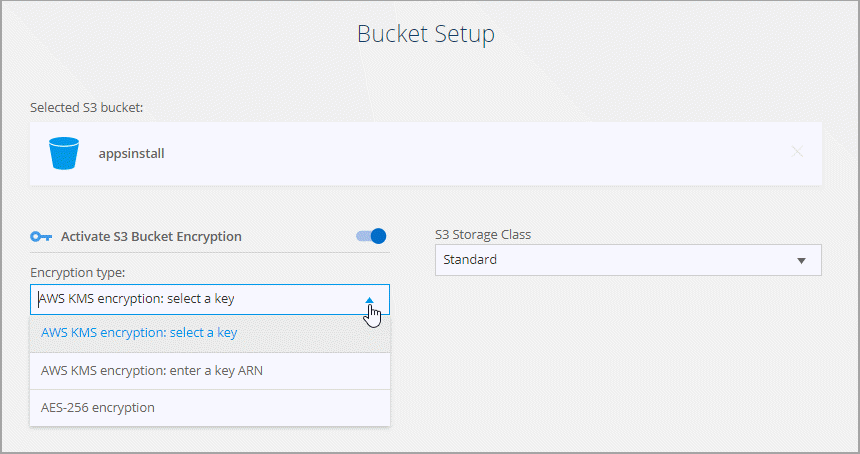
*バケット設定*ページでバケットを設定します。
-
S3 バケット暗号化を有効にするかどうかを選択し、AWS KMS キーを選択するか、KMS キーの ARN を入力するか、AES-256 暗号化を選択します。
-
S3 ストレージクラスを選択します。"サポートされているストレージクラスを表示する" 。
-
-
*設定*ページで、ソースファイルとフォルダをターゲットの場所で同期および維持する方法を定義します。
- スケジュール
-
今後の同期の定期スケジュールを選択するか、同期スケジュールをオフにします。関係を 1 分ごとに同期するようにスケジュールできます。
- 同期タイムアウト
-
指定された分数、時間数、または日数内に同期が完了しなかった場合に、コピーと同期でデータ同期をキャンセルするかどうかを定義します。
- 通知
-
NetAppコンソールの通知センターでコピーと同期の通知を受信するかどうかを選択できます。成功したデータ同期、失敗したデータ同期、キャンセルされたデータ同期に関する通知を有効にすることができます。
- 再試行
-
コピーと同期がファイルをスキップする前に同期を再試行する回数を定義します。
- 連続同期
-
最初のデータ同期の後、コピーと同期はソースの S3 バケットまたは Google Cloud Storage バケットの変更をリッスンし、変更が発生するたびにターゲットに継続的に同期します。スケジュールされた間隔でソースを再スキャンする必要はありません。
この設定は、同期関係を作成するとき、および S3 バケットまたは Google Cloud Storage から Azure Blob Storage、CIFS、Google Cloud Storage、IBM Cloud Object Storage、NFS、S3、 StorageGRIDに、または Azure Blob Storage から Azure Blob Storage、CIFS、Google Cloud Storage、IBM Cloud Object Storage、NFS、 StorageGRIDにデータを同期する場合にのみ使用できます。
この設定を有効にすると、他の機能に次の影響があります。
-
同期スケジュールは無効です。
-
次の設定はデフォルト値に戻ります: 同期タイムアウト、最近変更されたファイル、および変更日。
-
S3 がソースの場合、サイズによるフィルターはコピー イベントでのみアクティブになります (削除イベントではアクティブになりません)。
-
関係が作成された後は、関係を加速するか削除することしかできません。同期を中止したり、設定を変更したり、レポートを表示したりすることはできません。
外部バケットとの継続的な同期関係を作成できます。これを行うには、次の手順に従ってください。
-
外部バケットのプロジェクトの Google Cloud コンソールに移動します。
-
クラウド ストレージ > 設定 > クラウド ストレージ サービス アカウント に移動します。
-
local.json ファイルを更新します。
{ "protocols": { "gcp": { "storage-account-email": <storage account email> } } } -
データ ブローカーを再起動します。
-
sudo pm2 すべて停止
-
sudo pm2 すべて開始
-
-
関連する外部バケットとの継続的な同期関係を作成します。
外部バケットとの継続的な同期関係を作成するために使用されるデータ ブローカーは、プロジェクト内のバケットとの別の継続的な同期関係を作成することはできません。
-
-
- 比較する
-
ファイルまたはディレクトリが変更されたかどうか、再度同期する必要があるかどうかを判断するときに、コピーと同期で特定の属性を比較するかどうかを選択します。
これらの属性のチェックを外しても、コピーと同期はパス、ファイル サイズ、ファイル名をチェックしてソースとターゲットを比較します。変更があった場合は、それらのファイルとディレクトリが同期されます。
次の属性を比較して、コピーと同期を有効にするか無効にするかを選択できます。
-
mtime: ファイルの最終更新時刻。この属性はディレクトリには無効です。
-
uid、gid、および mode: Linux の権限フラグ。
-
- オブジェクトのコピー
-
オブジェクト ストレージのメタデータとタグをコピーするには、このオプションを有効にします。ユーザーがソースのメタデータを変更した場合、コピーと同期は次の同期でこのオブジェクトをコピーしますが、ユーザーがソースのタグを変更した場合 (データ自体ではなく)、コピーと同期は次の同期でオブジェクトをコピーしません。
関係を作成した後は、このオプションを編集することはできません。
タグのコピーは、Azure Blob または S3 互換エンドポイント (S3、 StorageGRID、または IBM Cloud Object Storage) をターゲットとして含む同期関係でサポートされます。
メタデータのコピーは、次のいずれかのエンドポイント間の「クラウド間」関係でサポートされます。
-
AWS S3
-
Azure ブロブ
-
Google Cloud Storage
-
IBM Cloud Object Storage
-
StorageGRID
-
- 最近変更されたファイル
-
スケジュールされた同期の前に最近変更されたファイルを除外することを選択します。
- ソース上のファイルを削除
-
コピーと同期によってファイルがターゲットの場所にコピーされた後、ソースの場所からファイルを削除することを選択します。このオプションでは、ソース ファイルがコピー後に削除されるため、データが失われるリスクがあります。
このオプションを有効にする場合は、データ ブローカーの local.json ファイル内のパラメーターも変更する必要があります。ファイルを開き、次のように更新します。
{ "workers":{ "transferrer":{ "delete-on-source": true } } }local.json ファイルを更新した後、再起動する必要があります。
pm2 restart all。 - ターゲット上のファイルを削除する
-
ソースからファイルが削除された場合は、ターゲットの場所からファイルを削除することを選択します。デフォルトでは、ターゲットの場所からファイルを削除しません。
- ファイルの種類
-
各同期に含めるファイルの種類(ファイル、ディレクトリ、シンボリック リンク、ハード リンク)を定義します。
ハード リンクは、セキュリティ保護されていない NFS と NFS の関係でのみ使用できます。ユーザーは 1 つのスキャナー プロセスと 1 つのスキャナー同時実行に制限され、スキャンはルート ディレクトリから実行する必要があります。 - ファイル拡張子を除外する
-
ファイル拡張子を入力して Enter キーを押すことで、同期から除外する正規表現またはファイル拡張子を指定します。たとえば、*.log ファイルを除外するには、「log」または「.log」と入力します。複数の拡張子の場合、区切り文字は必要ありません。次のビデオでは短いデモを紹介します。
同期関係のファイル拡張子を除外する
Regex または正規表現は、ワイルドカードや glob 表現とは異なります。この機能は正規表現でのみ動作します。 - ディレクトリを除外する
-
同期から除外する正規表現またはディレクトリを最大 15 個指定するには、名前またはディレクトリのフル パスを入力して Enter キーを押します。デフォルトでは、.copy-offload、.snapshot、~snapshot ディレクトリは除外されます。
Regex または正規表現は、ワイルドカードや glob 表現とは異なります。この機能は正規表現でのみ動作します。 - ファイル サイズ
-
サイズに関係なくすべてのファイルを同期するか、特定のサイズ範囲内のファイルのみを同期するかを選択します。
- 更新日
-
最終更新日に関係なくすべてのファイル、特定の日付以降、特定の日付前、または時間範囲内で更新されたファイルを選択します。
- 作成日
-
SMB サーバーがソースの場合、この設定により、特定の日付以降、特定の日付前、または特定の時間範囲内に作成されたファイルを同期できます。
- ACL - アクセス制御リスト
-
関係を作成するとき、または関係を作成した後に設定を有効にして、SMB サーバーから ACL のみ、ファイルのみ、または ACL とファイルをコピーします。
-
タグ/メタデータ ページで、S3 バケットに転送されるすべてのファイルにキーと値のペアをタグとして保存するか、すべてのファイルにメタデータのキーと値のペアを割り当てるかを選択します。
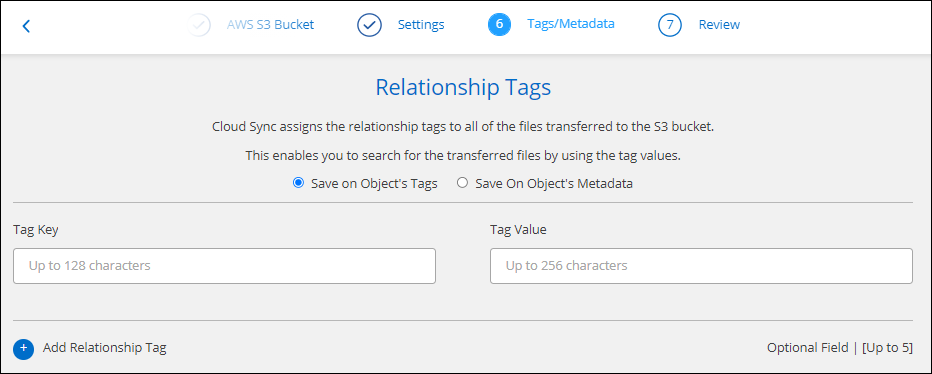

同じ機能は、 StorageGRIDおよび IBM Cloud Object Storage にデータを同期するときにも利用できます。 Azure および Google Cloud Storage の場合、メタデータ オプションのみが利用可能です。 -
同期関係の詳細を確認し、「関係の作成」を選択します。
結果
コピーと同期は、ソースとターゲット間のデータの同期を開始します。同期にかかった時間、同期が停止したかどうか、コピー、スキャン、または削除されたファイルの数に関する同期統計が利用できます。その後、 "同期関係" 、 "データブローカーを管理する" 、 または "パフォーマンスと構成を最適化するためのレポートを作成する"。
NetApp Data Classificationから同期関係を作成する
コピーと同期はNetApp Data Classificationと統合されています。 NetApp Data Classification内から、コピーと同期を使用してターゲットの場所に同期するソース ファイルを選択できます。
NetApp Data Classificationからデータ同期を開始すると、すべてのソース情報が 1 つの手順にまとめられ、いくつかの重要な詳細を入力するだけで済みます。次に、新しい同期関係のターゲットの場所を選択します。