

NetApp StorageGRID et l'analytique Big Data
 Suggérer des modifications
Suggérer des modifications
Utilisations de NetApp StorageGRID
La solution de stockage objet NetApp StorageGRID offre évolutivité, disponibilité des données, sécurité et hautes performances. Les entreprises de toutes tailles et de tous secteurs utilisent StorageGRID S3 pour un large éventail d'utilisations. Étudions quelques scénarios types :
Analytique Big Data : StorageGRID S3 est fréquemment utilisé comme data Lake, où les entreprises stockent de grandes quantités de données structurées et non structurées à des fins d'analyse à l'aide d'outils tels que Apache Spark, Splunk Smartstore et Dremio.
Tiering des données : les clients NetApp utilisent la fonctionnalité FabricPool d'ONTAP pour déplacer automatiquement les données entre un niveau local haute performance et StorageGRID. Le Tiering libère un stockage Flash coûteux pour les données actives tout en maintenant les données inactives disponibles dans un stockage objet à faible coût. Cela optimise les performances et les économies.
Sauvegarde des données et reprise après incident : les entreprises peuvent utiliser StorageGRID S3 comme une solution fiable et économique pour sauvegarder des données critiques et les restaurer en cas d'incident.
Stockage des données pour les applications : StorageGRID S3 peut être utilisé comme backend de stockage pour les applications, ce qui permet aux développeurs de stocker et de récupérer facilement des fichiers, des images, des vidéos et d'autres types de données.
Diffusion de contenu : StorageGRID S3 peut être utilisé pour stocker et fournir aux utilisateurs du monde entier du contenu statique, des fichiers multimédias et des téléchargements logiciels, en exploitant la répartition géographique et l'espace de noms global de StorageGRID pour une diffusion de contenu rapide et fiable.
Archives de données : StorageGRID offre différents types de stockage et prend en charge la hiérarchisation vers des options de stockage public à faible coût à long terme, en faisant une solution idéale pour l'archivage et la conservation à long terme des données qui doivent être conservées à des fins de conformité ou d'historique.
Cas d'utilisation du stockage objet
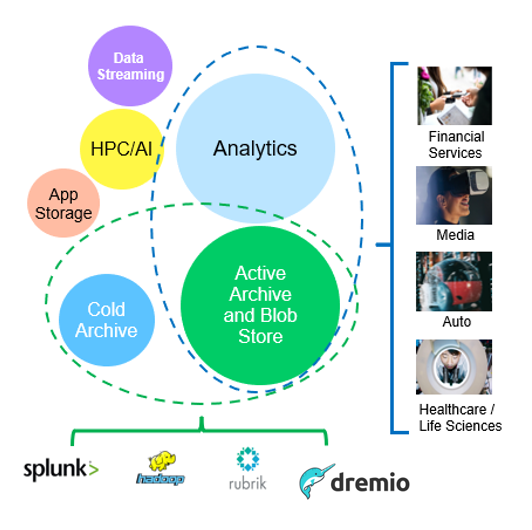
Parmi ces cas d'usage, l'analytique Big Data est l'un des plus utilisés, et son utilisation est en hausse.
Pourquoi choisir StorageGRID pour les data Lakes ?
-
Collaboration renforcée : colocation multisite partagée massive avec accès API standard
-
Coûts d'exploitation réduits : simplicité opérationnelle d'une seule architecture à autorétablissement
-
Évolutivité : contrairement aux solutions Hadoop et d'entrepôt de données classiques, le stockage objet StorageGRID S3 dissocie le stockage des ressources de calcul et de données pour vous permettre de faire évoluer vos besoins de stockage au fur et à mesure de leur croissance.
-
Durabilité et fiabilité : StorageGRID garantit une durabilité de 99.999999999 %, ce qui signifie que les données stockées sont hautement résistantes à la perte de données. Il assure également une haute disponibilité, garantissant ainsi un accès permanent aux données.
-
Sécurité : StorageGRID offre plusieurs fonctionnalités de sécurité, notamment le chiffrement, les règles de contrôle d'accès, la gestion du cycle de vie des données, le verrouillage d'objets et la gestion des versions pour protéger les données stockées dans des compartiments S3
StorageGRID S3 Data Lakes
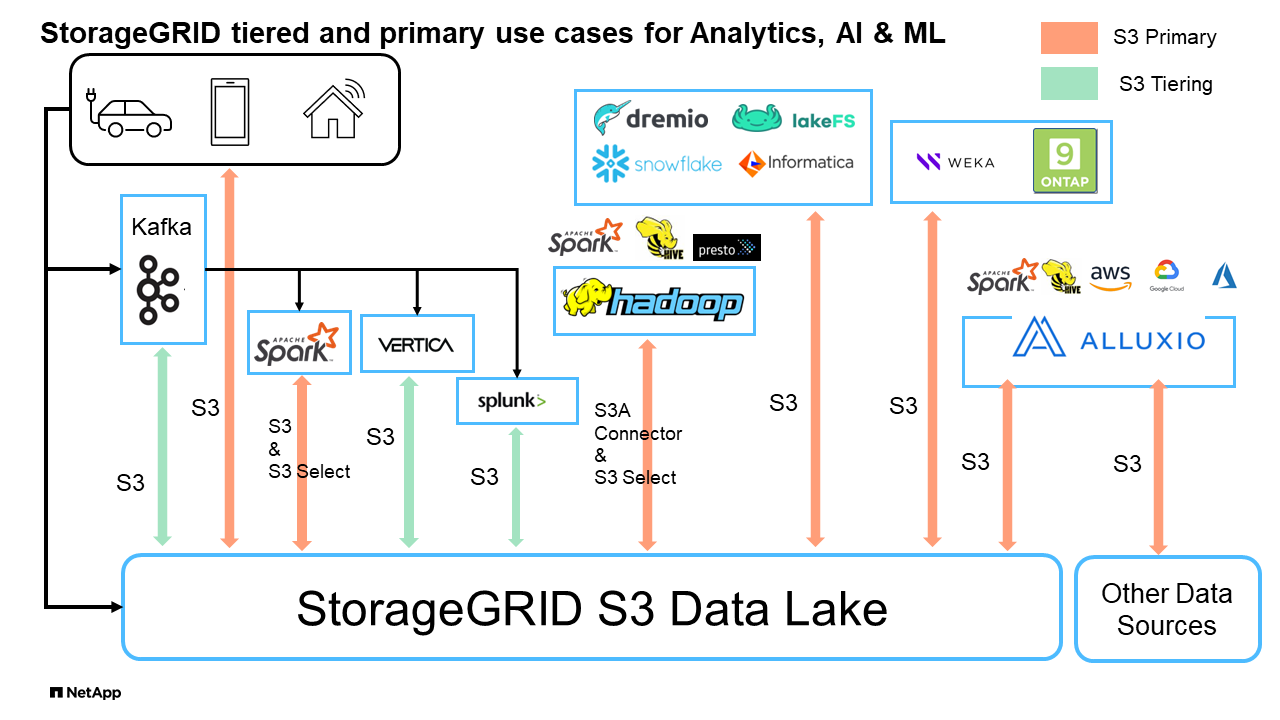
Étude comparative des entrepôts de données et des Lakehouses avec le stockage objet S3 : étude comparative
Cet article présente une analyse comparative complète de divers écosystèmes d'entrepôts de données et de lacs de données utilisant NetApp StorageGRID. L'objectif est de déterminer quel système offre les meilleures performances avec le stockage d'objets S3. Consultez cet "Apache Iceberg : guide de référence" pour en savoir plus sur les architectures d'entrepôts de données/lacs de données et les formats de tables (Parquet et Iceberg).
-
Outil de référence - TPC-DS - https://www.tpc.org/tpcds/
-
Les écosystèmes Big Data
-
Cluster de machines virtuelles, chacune avec 128 G de RAM et 24 vCPU, stockage SSD pour le disque système
-
Hadoop 3.3.5 avec Hive 3.1.3 (1 nœud de nom + 4 nœuds de données)
-
Delta Lake avec Spark 3.2.0 (1 maître + 4 employés) et Hadoop 3.3.5
-
Dremio v25.2 (1 coordinateur + 5 exécuteurs)
-
Trino v438 (1 coordinateur + 5 travailleurs)
-
Starburst v453 (1 coordinateur + 5 travailleurs)
-
-
Stockage objet
-
NetApp® StorageGRID® 11.8 avec 3 x SG6060 + 1 équilibreur de charge SG1000
-
Protection d'objet : 2 copies (le résultat est similaire à EC 2+1)
-
-
Taille de base de données : 1 000 Go
-
Le cache a été désactivé dans tous les écosystèmes pour chaque test de requête utilisant le format parquet. Pour le format Iceberg, nous avons comparé le nombre de requêtes GET S3 et le temps total d'interrogation entre les scénarios avec mise en cache désactivée et activée.
TPC-DS comprend 99 requêtes SQL complexes conçues pour l'analyse comparative. Nous avons mesuré le temps total nécessaire à l'exécution des 99 requêtes et réalisé une analyse détaillée en examinant le type et le nombre de requêtes S3. Nos tests ont comparé l'efficacité de deux formats de table courants : parquet et Iceberg.
Résultat de la requête TPC-DS avec le format de table parquet
| Écosystème | Ruche | Delta Lake | Dremio | Trino | En étoile |
|---|---|---|---|---|---|
Requêtes TPCDS 99 |
1084 1 |
55 |
36 |
32 |
28 |
Répartition des demandes S3 |
OBTENEZ |
1,117,184 |
2,074,610 |
3 939 690 |
1 504 212 |
1 495 039 |
observation: |
Plage de 80 % de 2 Ko à 2 Mo à partir d'objets de 32 Mo, 50 à 100 requêtes/sec |
Plage de 73 % inférieure à 100 Ko pour les objets de 32 Mo, 1000 à 1400 requêtes/sec |
90 % plage d'octets de 1 Mo provenant d'objets de 256 Mo, 2500 à 3000 requêtes/sec |
Taille GET de la plage : 50 % en dessous de 100 Ko, 16 % autour de 1 Mo, 27 % 2 Mo - 9 Mo, 3500 - 4000 requêtes/sec |
Taille GET de la plage : 50 % en dessous de 100 Ko, 16 % autour de 1 Mo, 27 % 2 Mo - 9 Mo, 4000 à 5000 requêtes/sec |
Liste des objets |
312,053 |
24,158 |
120 |
509 |
512 |
TÊTE |
156,027 |
12,103 |
96 |
0 |
0 |
TÊTE |
982,126 |
922,732 |
0 |
0 |
0 |
Nombre total de demandes |
2,567,390 |
3,033,603 |
3 939,906 |
1 504 721 |
1 Hive Impossible de compléter la requête numéro 72
Résultat de la requête TPC-DS avec format de table Iceberg
| Écosystème | Dremio | Trino | En étoile |
|---|---|---|---|
Requêtes TPCDS 99 + minutes totales (cache désactivé) |
22 |
28 |
22 |
Requêtes TPCDS 99 + minutes totales 2 (mémoire cache activée) |
16 |
28 |
21,5 |
Répartition des demandes S3 |
OBTENIR (cache désactivé) |
1 985 922 |
938 639 |
931 582 |
OBTENIR (cache activé) |
611 347 |
30 158 |
3 281 |
observation: |
Taille GET de plage : 67 % 1 Mo, 15 % 100 Ko, 10 % 500 Ko, 3500 à 4500 requêtes/sec |
Taille GET de la plage : 42 % en dessous de 100 Ko, 17 % autour de 1 Mo, 33 % 2 Mo - 9 Mo, 3500 - 4000 requêtes/sec |
Taille GET de la plage : 43 % en dessous de 100 Ko, 17 % autour de 1 Mo, 33 % 2 Mo - 9 Mo, 4000 - 5000 requêtes/sec |
Liste des objets |
1465 |
0 |
0 |
TÊTE |
1464 |
0 |
0 |
TÊTE |
3 702 |
509 |
509 |
Nombre total de requêtes (cache désactivé) |
1 992 553 |
939 148 |
2 les performances de Trino/Starburst sont des engorgements dus aux ressources de calcul ; l'ajout de RAM au cluster réduit le temps total de requête.
Comme le montre le premier tableau, Hive est beaucoup plus lente que les autres écosystèmes de maisons de données modernes. Nous avons observé qu'Hive a envoyé un grand nombre de requêtes d'objets de liste S3, qui sont généralement lentes sur toutes les plateformes de stockage objet, en particulier lorsqu'il s'agit de compartiments contenant de nombreux objets. Cela augmente considérablement la durée globale des requêtes. En outre, les écosystèmes de lakehouse modernes peuvent envoyer un grand nombre de requêtes GET en parallèle, allant de 2,000 à 5,000 requêtes par seconde, contre 50 à 100 requêtes par seconde de Hive. La copie de système de fichiers standard de Hive et Hadoop S3A contribue à la lenteur d'Hive lors de l'interaction avec le stockage objet S3.
L'utilisation d'Hadoop (HDFS ou le stockage objet S3) avec Hive ou Spark nécessite une connaissance approfondie de Hadoop et Hive/Spark, ainsi qu'une compréhension des interactions entre les paramètres de chaque service. Ensemble, ils ont plus de 1,000 réglages, dont beaucoup sont liés et ne peuvent pas être modifiés indépendamment. Trouver la combinaison optimale de paramètres et de valeurs nécessite beaucoup de temps et d'efforts.
En comparant les résultats du parquet et de l'Iceberg, nous constatons que le format du tableau est un facteur de performance important. Le format de table Iceberg est plus efficace que le parquet en termes de nombre de requêtes S3, avec 35 à 50 % de demandes en moins par rapport au format parquet.
Les performances de Dremio, Trino ou Starburst sont principalement déterminées par la puissance de calcul du cluster. Bien que les trois utilisent le connecteur S3A pour la connexion de stockage objet S3, ils ne nécessitent pas Hadoop et la plupart des paramètres fs.s3a de Hadoop ne sont pas utilisés par ces systèmes. Cela simplifie le réglage des performances, éliminant ainsi la nécessité d'apprendre et de tester les différents paramètres Hadoop S3A.
À partir de ce résultat du banc d'essai, nous pouvons conclure que le système d'analytique Big Data optimisé pour les workloads S3 constitue un facteur de performance majeur. Les blanchisseurs modernes optimisent l'exécution des requêtes, utilisent efficacement les métadonnées et fournissent un accès transparent aux données S3. Ils offrent ainsi de meilleures performances que Hive avec le stockage S3.
Reportez-vous à cette "page" section pour configurer la source de données Dremio S3 avec StorageGRID.
Cliquez sur les liens ci-dessous pour découvrir comment StorageGRID et Dremio travaillent en collaboration pour fournir une infrastructure de data Lake moderne et efficace, et comment NetApp a migré de Hive + HDFS vers Dremio + StorageGRID pour améliorer considérablement l'efficacité de l'analyse Big Data.