

NetApp StorageGRID y análisis de Big Data
 Sugerir cambios
Sugerir cambios
Casos de uso de NetApp StorageGRID
La solución de almacenamiento de objetos NetApp StorageGRID ofrece escalabilidad, disponibilidad de datos, seguridad y alto rendimiento. Organizaciones de todos los tamaños y sectores utilizan StorageGRID S3 para una amplia gama de casos de uso. Vamos a explorar algunos escenarios típicos:
-
Análisis de grandes volúmenes de datos: * StorageGRID S3 se utiliza con frecuencia como un lago de datos, donde las empresas almacenan grandes cantidades de datos estructurados y no estructurados para el análisis utilizando herramientas como Apache Spark, Splunk Smartstore y Dremio.
-
Organización en niveles de datos* Los clientes de NetApp utilizan la función FabricPool de ONTAP para mover datos automáticamente entre un nivel local de alto rendimiento a StorageGRID. La organización en niveles reserva el costoso almacenamiento flash para los datos calientes y mantiene los datos fríos disponibles en el almacenamiento de objetos de bajo coste. Esto maximiza el rendimiento y el ahorro.
Respaldo de datos y recuperación de desastres: Las empresas pueden utilizar StorageGRID S3 como una solución confiable y rentable para hacer copias de seguridad de datos críticos y recuperarlos en caso de desastre.
Almacenamiento de datos para aplicaciones: StorageGRID S3 se puede utilizar como backend de almacenamiento para aplicaciones, lo que permite a los desarrolladores almacenar y recuperar fácilmente archivos, imágenes, videos y otros tipos de datos.
Entrega de contenido: StorageGRID S3 se puede utilizar para almacenar y entregar contenido estático del sitio web, archivos multimedia y descargas de software a usuarios de todo el mundo, aprovechando la distribución geográfica y el espacio de nombres global de StorageGRID para una entrega de contenido rápida y confiable.
-
Archivo de datos:* StorageGRID ofrece diferentes tipos de almacenamiento y admite la clasificación por niveles en opciones de almacenamiento público de bajo costo a largo plazo, lo que lo convierte en una solución ideal para el archivado y la retención a largo plazo de datos que deben conservarse para fines de cumplimiento o históricos.
Casos de uso de almacenamiento de objetos
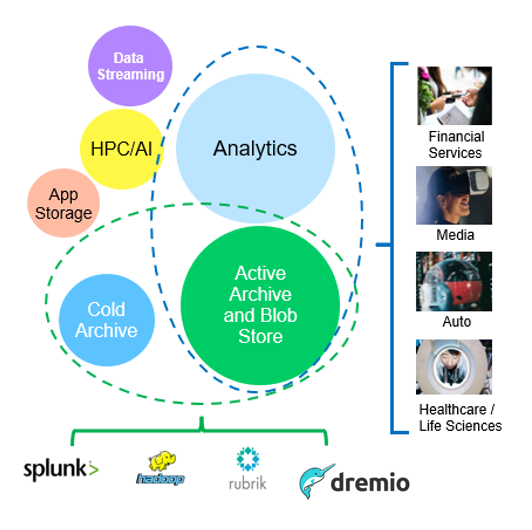
Entre los anteriores, el análisis de Big Data es uno de los casos de uso más importantes y su uso es tendencia al alza.
¿Por qué elegir StorageGRID para lagos de datos?
-
Mayor colaboración: Multi-tenancy compartido masivo con acceso a API estándar del sector
-
Costes operativos reducidos: Sencillez operativa de una única arquitectura de escalado horizontal automatizada y de reparación automática
-
Escalabilidad: A diferencia de las soluciones tradicionales Hadoop y almacenes de datos, el almacenamiento de objetos S3 de StorageGRID separa el almacenamiento de la computación y los datos, lo que permite a la empresa escalar sus necesidades de almacenamiento a medida que crecían.
-
Durabilidad y fiabilidad: StorageGRID proporciona una durabilidad del 99,999999999 %, lo que significa que los datos almacenados son muy resistentes a la pérdida de datos. También ofrece una alta disponibilidad, lo que garantiza la accesibilidad de los datos en todo momento.
-
Seguridad: StorageGRID ofrece distintas funciones de seguridad, como el cifrado, la política de control de acceso, la gestión del ciclo de vida de los datos, el bloqueo de objetos y el control de versiones para proteger los datos almacenados en bloques de S3
StorageGRID S3 lagos de datos
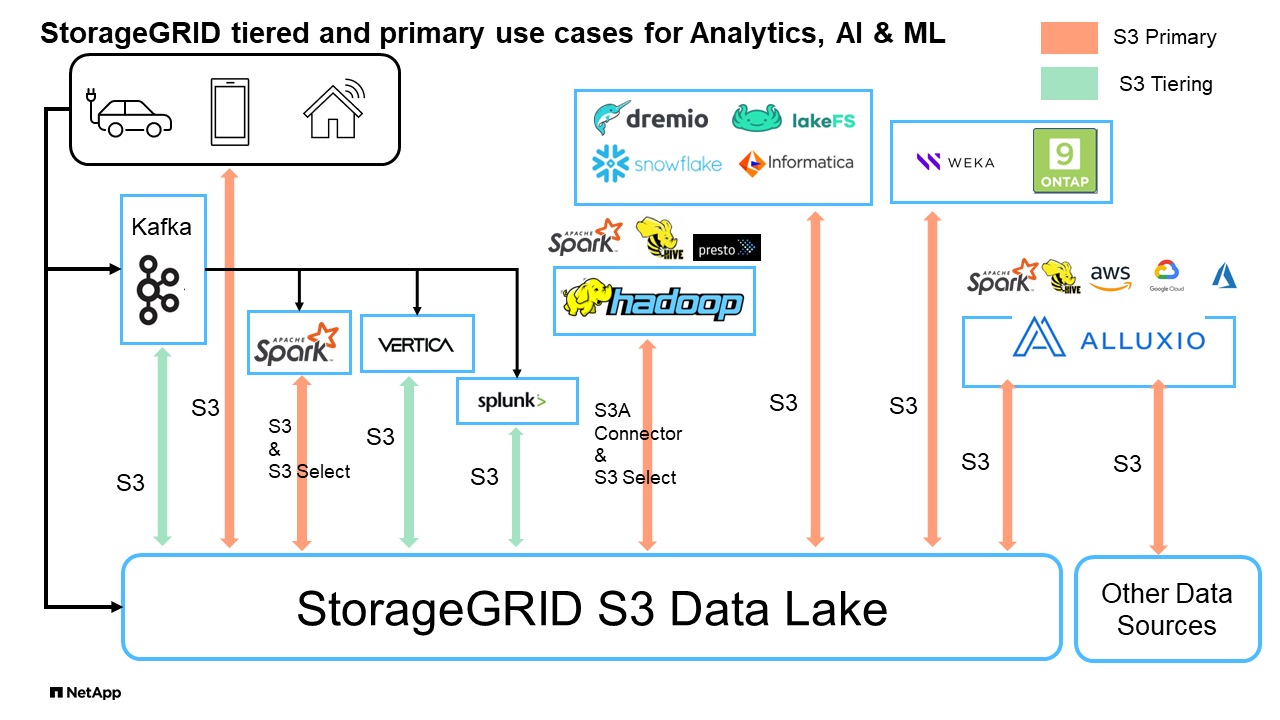
Comparación de almacenes de datos y casas de campo con almacenamiento de objetos S3: Un estudio comparativo
Este artículo presenta una comparativa exhaustiva de diversos ecosistemas de almacenes de datos y lakehouse utilizando NetApp StorageGRID. El objetivo es determinar qué sistema ofrece un mejor rendimiento con el almacenamiento de objetos S3. Consulta este "Apache Iceberg: La guía definitiva" para obtener más información sobre las arquitecturas de almacenes de datos y lakehouse y el formato de tabla (Parquet e Iceberg).
-
Herramienta de referencia - TPC-DS - https://www.tpc.org/tpcds/
-
Ecosistemas de Big Data
-
Clúster de equipos virtuales, cada uno con 128G GB de RAM y 24 vCPU, almacenamiento SSD para disco del sistema
-
Hadoop 3.3.5 con Hive 3.1.3 (1 nodo de nombres + 4 nodos de datos)
-
Delta Lake con Spark 3.2.0 (1 maestro + 4 trabajadores) y Hadoop 3.3.5
-
Dremio v25,2 (1 coordinador + 5 ejecutores)
-
Trino v438 (1 coordinador + 5 trabajadores)
-
Starburst v453 (1 coordinador + 5 trabajadores)
-
-
Almacenamiento de objetos
-
NetApp® StorageGRID® 11,8 con equilibrador de carga 3 x SG6060 + 1x SG1000
-
Protección de objetos: 2 copias (el resultado es similar con EC 2+1)
-
-
Tamaño de base de datos 1000GB
-
La caché se ha desactivado en todos los ecosistemas para cada prueba de consulta utilizando el formato Parquet. Para el formato iceberg, comparamos el número de S3 solicitudes GET y el tiempo total de consulta entre los escenarios con caché desactivada y con caché habilitada.
TPC-DS incluye 99 consultas SQL complejas diseñadas para la evaluación comparativa. Medimos el tiempo total necesario para ejecutar las 99 consultas y realizamos un análisis detallado examinando el tipo y el número de solicitudes S3. Nuestras pruebas compararon la eficiencia de dos formatos de mesa populares: Parquet e iceberg.
Resultado de consulta TPC-DS con formato de tabla de parquet
| Ecosistema | Subárbol | Lago Delta | Dremio | Trino | Estallido |
|---|---|---|---|---|---|
TPCDS 99 consultas |
1084 1 |
55 |
36 |
32 |
28 |
S3 Desglose de solicitudes |
OBTENGA |
1.117.184 |
2.074.610 |
3.939.690 |
1.504.212 |
1.495.039 |
observación: |
80% rango de obtención de 2KB a 2MB de 32MB objetos, 50 - 100 solicitudes/seg |
El rango del 73% se obtiene por debajo de 100KB de 32MB objetos, de 1000 a 1400 solicitudes por segundo |
90% 1M bytes de rango de obtención de 256MB objetos, 2500 - 3000 solicitudes/seg |
Rango OBTENER tamaño: 50% por debajo de 100KB, 16% alrededor de 1MB, 27% 2MB-9MB, 3500 - 4000 solicitudes/seg |
Rango OBTENER tamaño: 50% por debajo de 100KB, 16% alrededor de 1MB, 27% 2MB-9MB, 4000 - 5000 solicitud/seg |
Mostrar objetos |
312.053 |
24.158 |
120 |
509 |
512 |
CABEZAL |
156.027 |
12.103 |
96 |
0 |
0 |
CABEZAL |
982.126 |
922.732 |
0 |
0 |
0 |
Total de solicitudes |
2.567.390 |
3.033.603 |
3.939,906 |
1.504.721 |
1 Hive no ha podido completar la consulta número 72
Resultado de consulta TPC-DS con formato de tabla iceberg
| Ecosistema | Dremio | Trino | Estallido |
|---|---|---|---|
TPCDS 99 consultas + total de minutos (caché desactivada) |
22 |
28 |
22 |
Consultas TPCDS 99 + total de minutos 2 (caché habilitada) |
16 |
28 |
21,5 |
S3 Desglose de solicitudes |
OBTENER (caché deshabilitada) |
1.985.922 |
938.639 |
931.582 |
OBTENER (caché habilitada) |
611.347 |
30.158 |
3.281 |
observación: |
Tamaño DE OBTENCIÓN DE rango: 67% 1MB, 15% 100KB, 10% 500KB, 3500 - 4500 solicitudes/seg |
Rango OBTENER tamaño: 42% por debajo de 100KB, 17% alrededor de 1MB, 33% 2MB-9MB, 3500 - 4000 solicitudes/seg |
Rango OBTENER tamaño: 43% por debajo de 100KB, 17% alrededor de 1MB, 33% 2MB-9MB, 4000 - 5000 solicitudes/seg |
Mostrar objetos |
1465 |
0 |
0 |
CABEZAL |
1464 |
0 |
0 |
CABEZAL |
3.702 |
509 |
509 |
Total de Solicitudes (Caché Desactivada) |
1.992.553 |
939.148 |
2 El rendimiento de Trino/Starburst se encuentra en un cuello de botella debido a los recursos informáticos; al agregar más RAM al clúster, se reduce el tiempo total de consulta.
Como se muestra en la primera tabla, Hive es significativamente más lento que otros ecosistemas modernos de data lakehouse. Observamos que Hive envió un gran número de solicitudes de objetos de lista S3, que suelen ser lentas en todas las plataformas de almacenamiento de objetos, especialmente cuando se trata de cubos que contienen muchos objetos. Esto aumenta significativamente la duración general de la consulta. Además, los ecosistemas modernos de los lagos pueden enviar un gran número de SOLICITUDES GET en paralelo, que van desde 2.000 a 5.000 solicitudes por segundo, en comparación con las 50 a 100 solicitudes por segundo de Hive. El mimetismo del sistema de archivos estándar de Hive y Hadoop S3A contribuye a la lentitud de Hive al interactuar con el almacenamiento de objetos S3.
El uso de Hadoop (ya sea en HDFS o en el almacenamiento de objetos S3) con Hive o Spark requiere un amplio conocimiento de Hadoop y Hive/Spark, así como un entendimiento de cómo interactúan los ajustes de cada servicio. Juntos, tienen más de 1.000 configuraciones, muchas de las cuales están interrelacionadas y no se pueden cambiar de forma independiente. Encontrar la combinación óptima de ajustes y valores requiere una gran cantidad de tiempo y esfuerzo.
Comparando los resultados de Parquet e Iceberg, notamos que el formato de tabla es un factor de rendimiento importante. El formato de tabla Iceberg es más eficiente que el Parquet en cuanto al número de solicitudes S3, con un 35% a un 50% menos de solicitudes en comparación con el formato Parquet.
El rendimiento de Dremio, Trino o Starburst está impulsado principalmente por la potencia de cálculo del clúster. Aunque los tres utilizan el conector S3A para la conexión de almacenamiento de objetos S3, no requieren Hadoop, por lo que estos sistemas no utilizan la mayoría de la configuración fs.S3A de Hadoop. Esto simplifica el ajuste del rendimiento, por lo que elimina la necesidad de aprender y probar diferentes configuraciones de Hadoop S3A.
A partir de estos resultados de las pruebas de rendimiento, podemos concluir que el sistema de análisis de Big Data optimizado para cargas de trabajo basadas en S3 es un factor de rendimiento importante. Los centros de almacenamiento modernos optimizan la ejecución de las consultas, utilizan metadatos de manera eficiente y proporcionan un acceso fluido a los datos S3, lo que resulta en un mejor rendimiento en comparación con Hive cuando se trabaja con almacenamiento S3.
Consulte esto "página" para configurar el origen de datos Dremio S3 con StorageGRID.
Visite los enlaces siguientes para obtener más información sobre cómo StorageGRID y Dremio trabajan juntos para proporcionar una infraestructura de lago de datos moderna y eficiente y cómo NetApp migró de Hive + HDFS a Dremio + StorageGRID para mejorar drásticamente la eficiencia del análisis de Big Data.