

Meilleures pratiques opérationnelles
 Suggérer des modifications
Suggérer des modifications
Les sections suivantes présentent les meilleures pratiques opérationnelles pour VMware SRM et le stockage ONTAP.
Datastores et protocoles
-
Si possible, utilisez toujours les outils ONTAP pour provisionner les datastores et les volumes. Cela vérifie que les volumes, les chemins de jonction, les LUN, les igroups, les règles d'exportation, et d'autres paramètres sont configurés de manière compatible.
-
SRM prend en charge iSCSI, Fibre Channel et NFS version 3 avec ONTAP 9 lors de l'utilisation d'une réplication basée sur les baies via SRA. SRM ne prend pas en charge la réplication basée sur la baie pour NFS version 4.1 avec des datastores traditionnels ou vvols.
-
Pour confirmer la connectivité, vérifiez toujours que vous pouvez monter et démonter un nouveau datastore test sur le site de reprise sur incident à partir du cluster ONTAP de destination. Testez chaque protocole que vous envisagez d'utiliser pour la connectivité du datastore. L'une des meilleures pratiques est d'utiliser les outils ONTAP pour créer votre datastore de test, car elle effectue toutes les automatisations du datastore telles que dirigées par SRM.
-
Les protocoles SAN doivent être homogènes pour chaque site. Vous pouvez combiner les protocoles NFS et SAN, mais les protocoles SAN ne doivent pas être combinés dans un même site. Par exemple, vous pouvez utiliser FCP sur Le site A et iSCSI sur le site B. vous ne devez pas utiliser FCP ou iSCSI sur le site A.
-
Les guides précédents ont recommandé de créer la LIF pour la localisation des données. C'est-à-dire toujours monter un datastore à l'aide d'une LIF située sur le nœud qui détient physiquement le volume. Bien que ce soit toujours la meilleure pratique, ce n'est plus une exigence dans les versions modernes de ONTAP 9. Dans la mesure du possible, et si des informations d'identification avec périmètre du cluster sont fournies, les outils ONTAP choisissent toujours d'équilibrer la charge entre les LIF locales aux données, mais il ne s'agit pas d'une exigence de haute disponibilité ou de performance.
-
ONTAP 9 peut être configuré pour supprimer automatiquement les snapshots afin de préserver la disponibilité en cas de manque d'espace lorsque la taille automatique ne peut pas fournir une capacité d'urgence suffisante. Le paramètre par défaut de cette fonctionnalité ne supprime pas automatiquement les snapshots créés par SnapMirror. Si des snapshots SnapMirror sont supprimés, NetApp SRA ne peut pas inverser et resynchroniser la réplication pour le volume affecté. Pour empêcher ONTAP de supprimer des snapshots SnapMirror, configurez la fonction de suppression automatique des snapshots sur « essayer ».
snap autodelete modify -volume -commitment try
-
La taille automatique du volume doit être définie sur
growpour les volumes contenant des datastores SAN etgrow_shrinkpour les datastores NFS. Pour en savoir plus sur ce sujet"Configurez les volumes pour qu'ils augmentent ou réduisent automatiquement leur taille", rendez-vous sur . -
SRM fonctionne mieux lorsque le nombre de datastores et donc les groupes de protection sont limités dans vos plans de reprise d'activité. Par conséquent, vous devez envisager d'optimiser la densité des machines virtuelles dans les environnements protégés par SRM où le RTO est essentiel.
-
Utilisez Distributed Resource Scheduler (DRS) pour équilibrer la charge sur vos clusters ESXi protégés et de récupération. N'oubliez pas que si vous prévoyez de revenir en arrière, lorsque vous exécutez une reprotection, les clusters précédemment protégés deviennent les nouveaux clusters de récupération. Le DRS contribue à équilibrer le placement dans les deux sens.
-
Dans la mesure du possible, évitez d'utiliser la personnalisation IP avec SRM car cela peut augmenter votre RTO.
À propos des paires de baies
Un gestionnaire de matrices est créé pour chaque paire de matrices. Avec les outils SRM et ONTAP, chaque association de baie s'effectue au sein d'un SVM, même si vous utilisez les identifiants du cluster. Vous pouvez ainsi segmenter les flux de travail de reprise après incident entre des locataires, en fonction des SVM qu'ils ont affectés à la gestion. Vous pouvez créer plusieurs gestionnaires de baies pour un cluster donné, qui peuvent être asymétriques. Vous pouvez « Fan-Out » ou « Fan-In » sur différents clusters ONTAP 9. Par exemple, il peut y avoir des SVM-A et SVM-B dans le Cluster-1 en cours de réplication vers SVM-C dans le Cluster-2, SVM-D dans le Cluster-3 ou vice-versa.
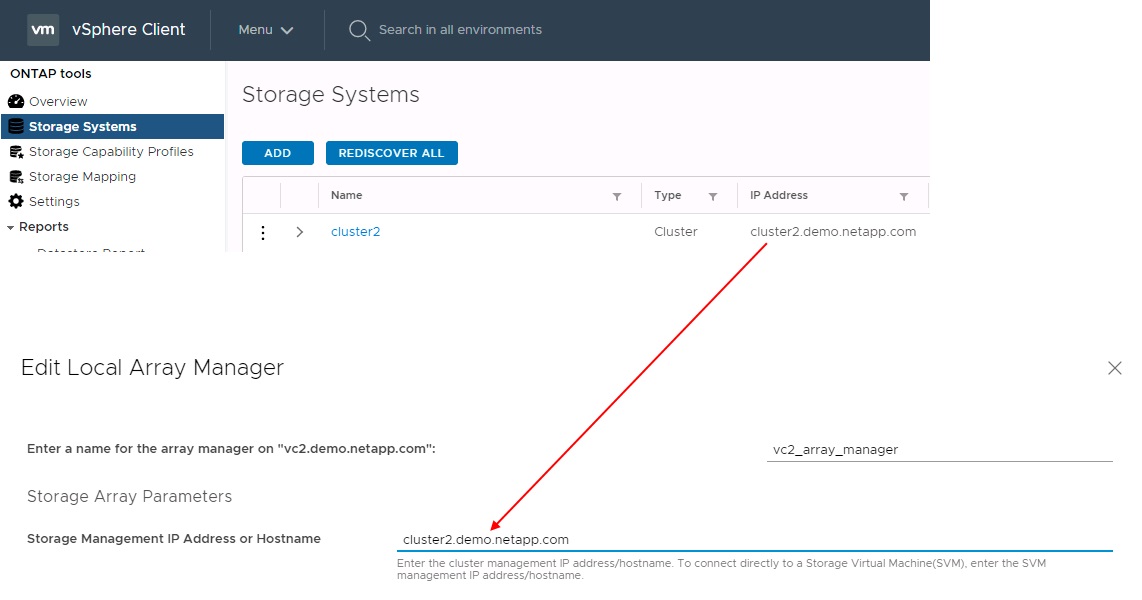
Lors de la configuration des paires de baies dans SRM, vous devez toujours les ajouter à SRM de la même manière que vous les avez ajoutés à ONTAP Tools : autrement dit, ils doivent utiliser le même nom d'utilisateur, mot de passe et LIF de gestion. Cette exigence garantit que SRA communique correctement avec la baie. La copie d'écran suivante montre comment un cluster peut s'afficher dans les outils ONTAP et comment il peut être ajouté à un gestionnaire de baies.
À propos des groupes de réplication
Les groupes de réplication contiennent des ensembles logiques de machines virtuelles qui sont restaurées ensemble. Étant donné que la réplication SnapMirror de ONTAP se produit au niveau du volume, toutes les machines virtuelles d'un volume se trouvent dans le même groupe de réplication.
Il existe plusieurs facteurs à prendre en compte dans les groupes de réplication et dans la manière dont vous distribuez les machines virtuelles sur les volumes FlexVol. Le regroupement de machines virtuelles similaires dans un même volume peut améliorer l'efficacité du stockage avec les systèmes ONTAP plus anciens qui n'offrent pas de déduplication au niveau de l'agrégat. Cependant, ce regroupement augmente la taille du volume et réduit la simultanéité E/S du volume. Les systèmes ONTAP modernes offrent un équilibre parfait entre performance et efficacité du stockage en distribuant les machines virtuelles entre les volumes FlexVol au sein d'un même agrégat. La déduplication au niveau de l'agrégat améliore la parallélisation des E/S sur plusieurs volumes. Vous pouvez restaurer des VM dans les volumes simultanément, car un groupe de protection (voir ci-dessous) peut contenir plusieurs groupes de réplication. L'inconvénient de cette disposition est que les blocs peuvent être transmis plusieurs fois via le réseau, car SnapMirror ne prend pas en compte la déduplication dans l'agrégat.
Dernier point à prendre en compte pour les groupes de réplication : chacun d'entre eux est, par nature, un groupe de cohérence logique (à ne pas confondre avec les groupes de cohérence SRM). En effet, toutes les machines virtuelles du volume sont transférées ensemble à l'aide du même snapshot. Ainsi, si vous disposez de machines virtuelles qui doivent être cohérentes les unes avec les autres, envisagez de les stocker dans le même FlexVol.
À propos des groupes de protection
Les groupes de protection définissent les VM et les datastores dans des groupes restaurés à partir du site protégé. Le site protégé est là où existent les VM configurées dans un groupe de protection pendant les opérations stables. Il est important de noter que même si SRM peut afficher plusieurs gestionnaires de baies pour un groupe de protection, un groupe de protection ne peut pas s'étendre sur plusieurs gestionnaires de baies. Pour cette raison, vous ne devez pas couvrir les fichiers de machine virtuelle sur plusieurs datastores sur différents SVM.
À propos des plans de reprise
Les plans de reprise définissent les groupes de protection qui sont restaurés au cours du même processus. Plusieurs groupes de protection peuvent être configurés dans le même plan de reprise. Par ailleurs, pour activer davantage d'options pour l'exécution des plans de reprise, un seul groupe de protection peut être inclus dans plusieurs plans de restauration.
Les plans de restauration permettent aux administrateurs SRM de définir les flux de travail de restauration en affectant des VM à un groupe de priorité compris entre 1 (le plus élevé) et 5 (le plus faible), dont la valeur par défaut est 3 (moyen). Au sein d'un groupe de priorités, les VM peuvent être configurés pour les dépendances.
Par exemple, votre entreprise peut disposer d'une application stratégique de niveau 1 qui repose sur un serveur Microsoft SQL pour sa base de données. Vous décidez donc de placer vos machines virtuelles dans le groupe de priorité 1. Au sein du groupe de priorité 1, vous commencez à planifier la commande afin d'obtenir des services. Vous souhaitez probablement que votre contrôleur de domaine Microsoft Windows démarre avant votre serveur Microsoft SQL, qui doit être en ligne avant votre serveur d'applications, et ainsi de suite. Vous devez ajouter toutes ces machines virtuelles au groupe de priorité, puis définir les dépendances, car elles ne s'appliquent qu'à un groupe de priorité donné.
NetApp recommande fortement de travailler avec vos équipes en charge des applications pour comprendre l'ordre des opérations requises dans un scénario de basculement et pour élaborer vos plans de reprise en conséquence.
Tester le basculement
Il est recommandé d'effectuer systématiquement un basculement de test lorsqu'une modification est apportée à la configuration du stockage protégé des machines virtuelles. Ainsi, en cas d'incident, vous avez l'assurance que site Recovery Manager peut restaurer les services au sein de la cible de délai de restauration prévue.
NetApp recommande également de confirmer occasionnellement les fonctionnalités des applications chez l'invité, en particulier après la reconfiguration du stockage des machines virtuelles.
Lors de l'exécution d'une opération de restauration test, un réseau de bulles de test privé est créé sur l'hôte ESXi pour les machines virtuelles. Cependant, ce réseau n'est pas automatiquement connecté à aucune carte réseau physique et ne fournit donc pas de connectivité entre les hôtes ESXi. Pour permettre la communication entre les machines virtuelles s'exécutant sur différents hôtes ESXi lors du test de reprise après incident, un réseau privé physique est créé entre les hôtes ESXi du site de reprise après incident. Pour vérifier que le réseau de test est privé, le réseau de bulles de test peut être séparé physiquement ou à l'aide de VLAN ou de balisage VLAN. Ce réseau doit être isolé du réseau de production car les machines virtuelles sont restaurées. En effet, ils ne peuvent pas être placés sur le réseau de production avec des adresses IP qui pourraient entrer en conflit avec les systèmes de production réels. Lors de la création d'un plan de reprise d'activité dans SRM, le réseau test créé peut être sélectionné comme réseau privé afin de connecter les VM à pendant le test.
Une fois le test validé et n'est plus nécessaire, effectuez une opération de nettoyage. Le nettoyage en cours d'exécution renvoie l'état initial des machines virtuelles protégées à leur état initial et réinitialise le plan de restauration en mode prêt.
Considérations relatives au basculement
Il y a plusieurs autres considérations lorsqu'il s'agit de basculer sur un site en plus de l'ordre des opérations mentionné dans ce guide.
Vous devrez peut-être résoudre ce problème en tenant compte des différences de réseau entre les sites. Certains environnements peuvent utiliser les mêmes adresses IP réseau à la fois sur le site primaire et sur le site de reprise après incident. Cette fonctionnalité est appelée VLAN (Virtual LAN) étendu ou configuration réseau étendu. Dans d'autres environnements, il est parfois nécessaire d'utiliser différentes adresses IP réseau (par exemple, sur différents VLAN) sur le site primaire par rapport au site de reprise.
VMware offre plusieurs moyens de résoudre ce problème. Pour la première, des technologies de virtualisation de réseau comme VMware NSX-T Data Center extraient la pile réseau des couches 2 à 7 de l'environnement d'exploitation, afin d'offrir des solutions plus portables. En savoir plus sur "Options NSX-T avec SRM".
SRM vous permet également de modifier la configuration réseau d'une machine virtuelle lors de sa restauration. Cette reconfiguration inclut des paramètres tels que les adresses IP, les adresses de passerelle et les paramètres du serveur DNS. Différents paramètres réseau, qui sont appliqués aux machines virtuelles individuelles au fur et à mesure qu'elles sont restaurées, peuvent être spécifiés dans les paramètres de propriété d'une machine virtuelle dans le plan de reprise.
Pour configurer SRM de façon à appliquer différents paramètres réseau à plusieurs machines virtuelles sans devoir modifier les propriétés de chacune d'entre elles dans le plan de reprise, VMware fournit un outil appelé dr-ip-customizer. Pour savoir comment utiliser cet utilitaire, reportez-vous à la section "Documentation de VMware".
Reprotéger
Après une restauration, le site de reprise devient le nouveau site de production. Comme l'opération de reprise a rompue la réplication SnapMirror, le nouveau site de production n'est pas protégé contre un futur incident. Il est recommandé de protéger le nouveau site de production sur un autre site immédiatement après une restauration. Si le site de production d'origine est opérationnel, l'administrateur VMware peut utiliser le site de production d'origine comme nouveau site de reprise pour protéger le nouveau site de production, ce qui inversera efficacement la direction de la protection. La reprotection est disponible uniquement en cas de défaillance majeure. Par conséquent, les serveurs vCenter d'origine, les serveurs ESXi, les serveurs SRM et les bases de données correspondantes doivent être récupérables. S'ils ne sont pas disponibles, un nouveau groupe de protection et un nouveau plan de récupération doivent être créés.
Du rétablissement
Une opération de retour arrière est fondamentalement un basculement dans une direction différente de celle précédente. Il est recommandé de vérifier que le site d'origine fonctionne à un niveau de fonctionnalité acceptable avant de tenter un retour arrière ou, en d'autres termes, un basculement vers le site d'origine. Si le site d'origine est toujours compromis, vous devez reporter la restauration jusqu'à ce que la défaillance soit suffisamment remédiée.
Une autre meilleure pratique de restauration consiste à toujours effectuer un basculement de test après avoir terminé la reprotection et avant de procéder à la restauration finale. Cela vérifie que les systèmes en place sur le site initial peuvent mener à bien l'opération.
Reprotéger le site d'origine
Après la restauration, vous devez confirmer auprès de toutes les parties prenantes que leurs services ont été renvoyés à la normale avant d'exécuter à nouveau reprotéger.
La reprotection après le retour arrière reprend l'état où il était au début, avec la réplication SnapMirror à nouveau en cours d'exécution depuis le site de production vers le site de reprise.