Configuration de la synchronisation active SnapMirror
 Suggérer des modifications
Suggérer des modifications
Cet article décrit les étapes de configuration requises pour cette solution.
Conditions préalables
Les clusters de stockage et les SVM correspondants doivent être peering.
Le médiateur ONTAP doit être disponible et configuré au niveau des deux clusters de stockage.


Configuration de l'infrastructure de stockage et des groupes de cohérence
Dans la documentation ONTAP "Présentation de la synchronisation active SnapMirror dans ONTAP", le concept de groupes de cohérence avec la synchronisation active SnapMirror est décrit comme suit :
Un groupe de cohérence est un ensemble de volumes FlexVol qui garantit la cohérence de la charge de travail applicative. Pour assurer la continuité de l'activité, il est nécessaire de protéger cette dernière.
L'objectif d'un groupe de cohérence est de prendre des images Snapshot simultanées de plusieurs volumes, ce qui garantit des copies cohérentes après panne d'un ensemble de volumes à un moment donné. Un groupe de cohérence garantit que tous les volumes d'un dataset sont suspendus, puis aimantés précisément au même point dans le temps. Cela offre un point de restauration cohérent avec les données sur l'ensemble des volumes prenant en charge le dataset. Un groupe de cohérence conserve ainsi une cohérence dépendante de l'ordre d'écriture. Si vous décidez de protéger les applications pour la continuité de l'activité, le groupe de volumes correspondant à cette application doit être ajouté à un groupe de cohérence de sorte qu'une relation de protection des données soit établie entre un groupe de cohérence source et un groupe de cohérence de destination. La cohérence source et destination doit contenir le même nombre et le même type de volumes.
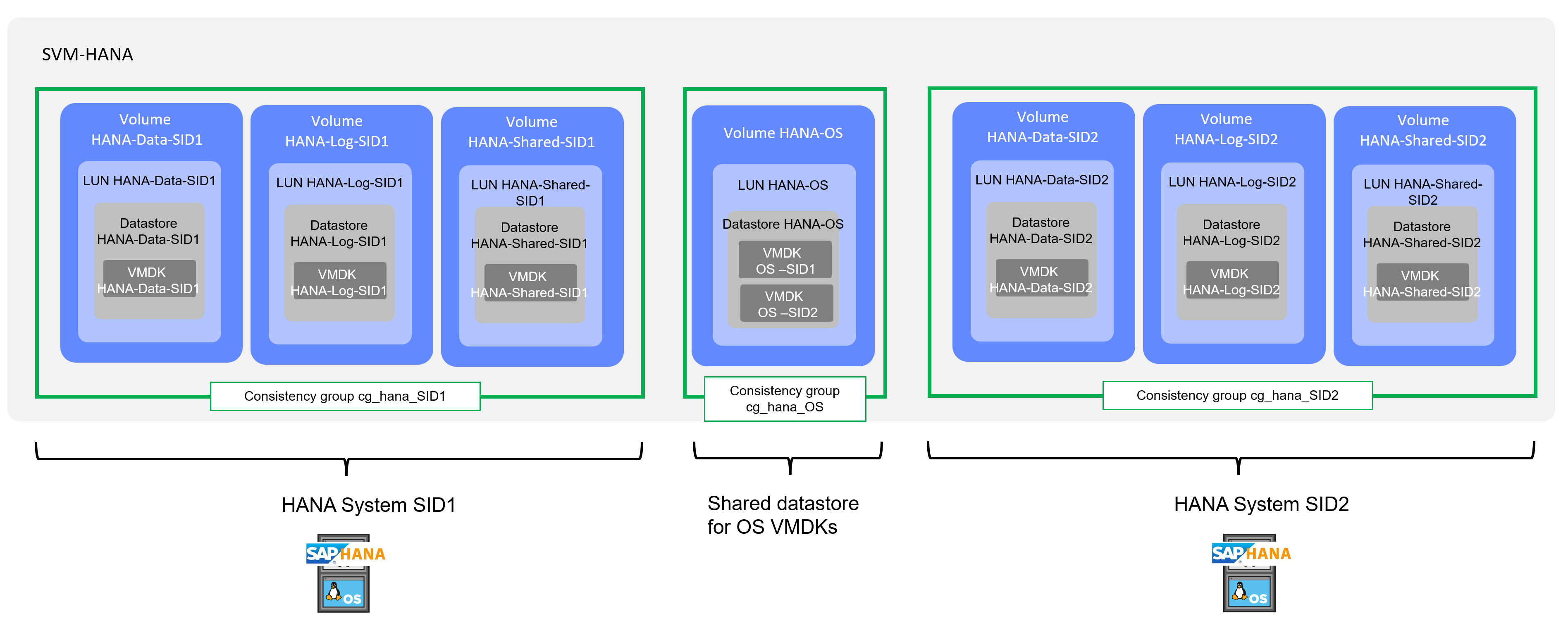
Pour la réplication des systèmes HANA, le groupe de cohérence doit inclure tous les volumes utilisés par le système HANA individuel (données, journal et partagé). Les volumes qui doivent faire partie d'un groupe de cohérence doivent être stockés sur la même SVM. Les images du système d'exploitation peuvent être stockées dans un volume distinct avec son propre groupe de cohérence. La figure ci-dessous illustre un exemple de configuration avec deux systèmes HANA.
Configuration du groupe initiateur
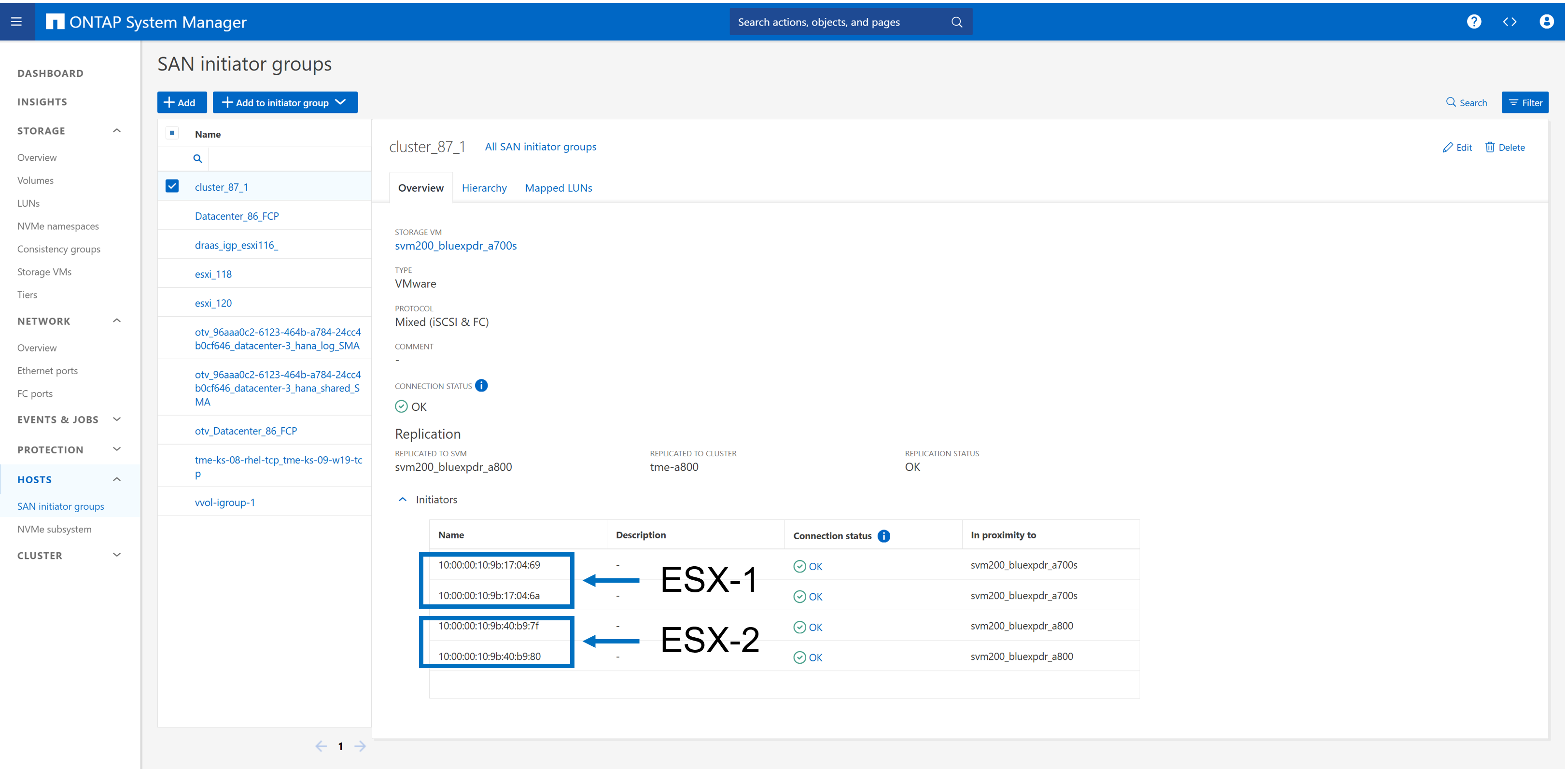
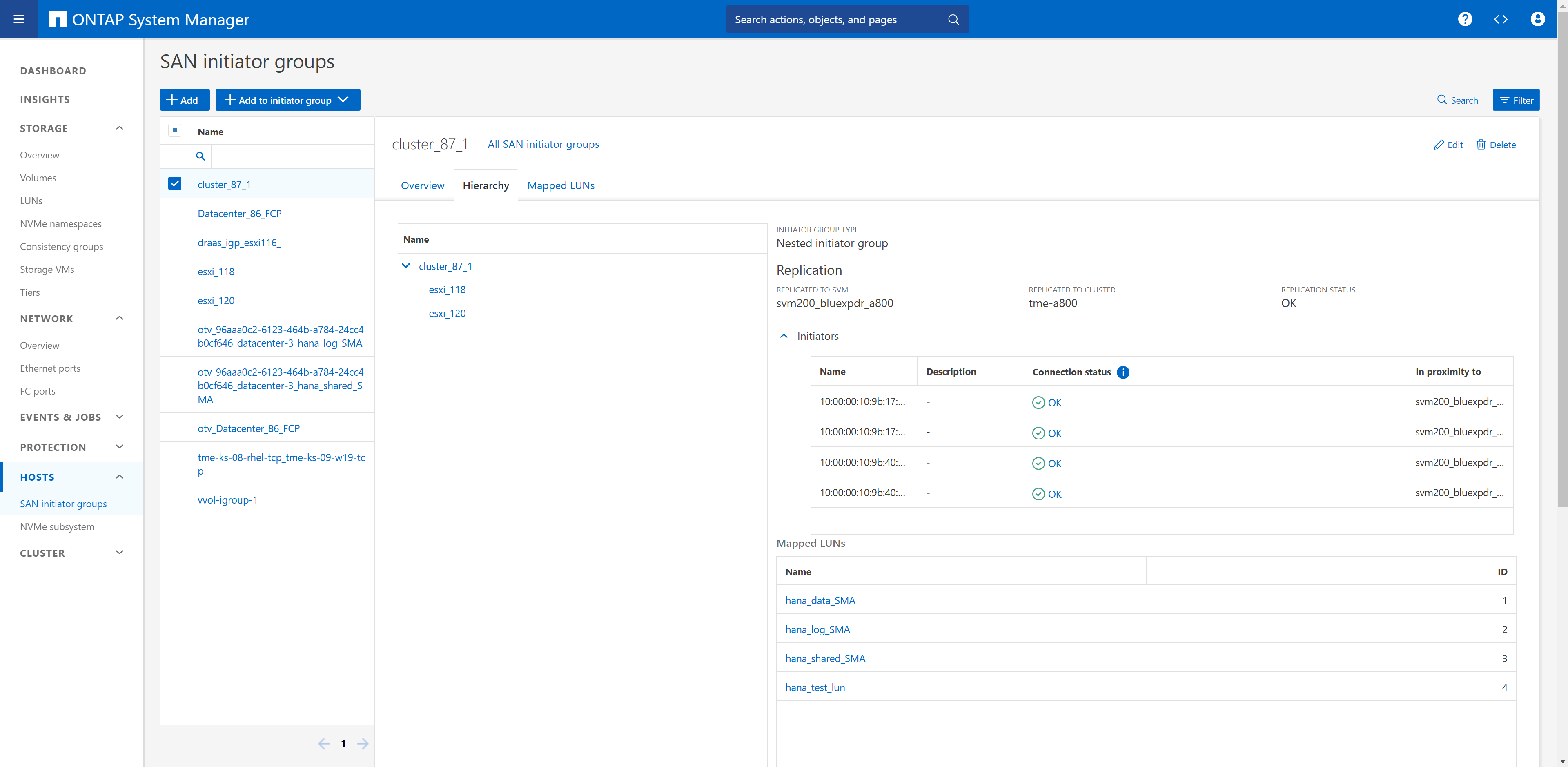
Dans la configuration de notre laboratoire, nous avons créé un groupe initiateur comprenant les deux SVM de stockage utilisés pour la réplication active Sync de SnapMirror. Dans la configuration de synchronisation active SnapMirror décrite plus loin, nous définissons que le groupe initiateur fera partie de la réplication.
En utilisant les paramètres de proximité, nous avons défini l'hôte ESX le plus proche de quel cluster de stockage. Dans notre cas, le système A700 est proche de ESX-1 et le système A800 est proche de ESX-2.

|
Dans une configuration d'accès non uniforme, le groupe initiateur du cluster de stockage principal (A700) doit inclure uniquement les initiateurs de l'hôte ESX-1, car il n'y a pas de connexion SAN à ESX-2. En outre, vous devez configurer un autre groupe initiateur sur le second cluster de stockage (A800) qui inclut uniquement les initiateurs de l'hôte ESX-2. La configuration de proximité et la réplication des groupes initiateurs ne sont pas requises. |
Configurez la protection à l'aide de ONTAP System Manager
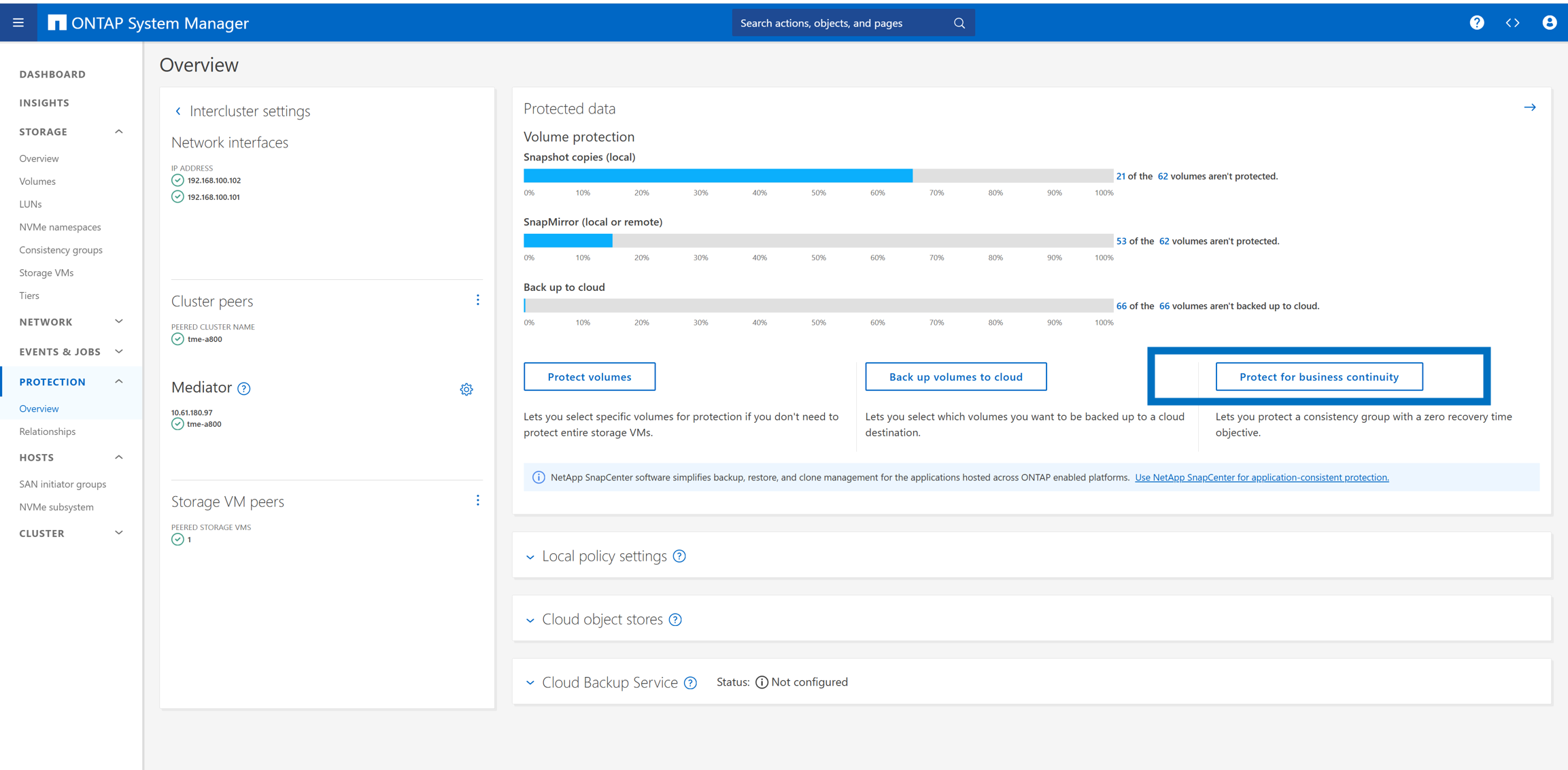
Réplication de groupe de cohérence et de groupe initiateur
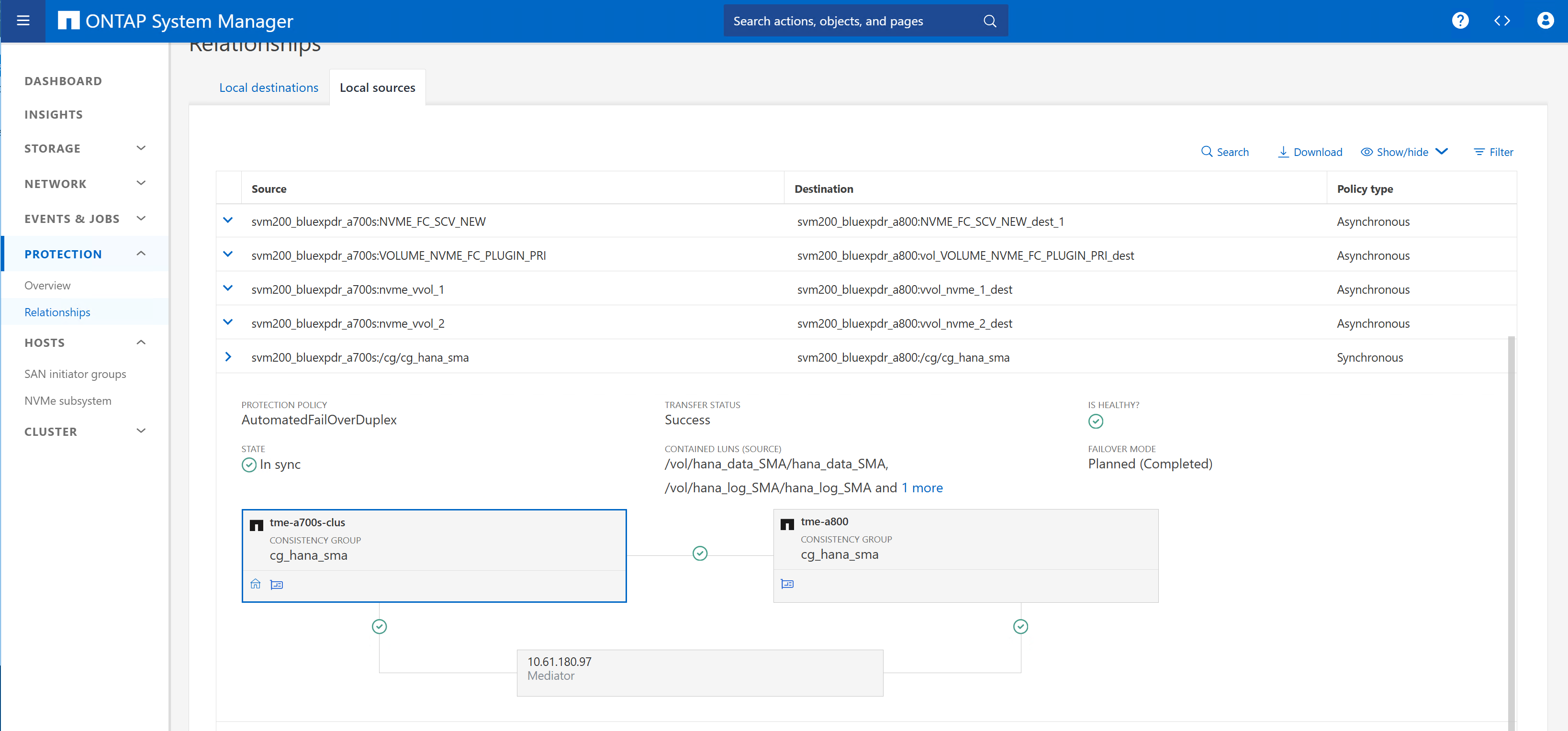
Vous devez créer un nouveau groupe de cohérence et ajouter les trois LUN du système HANA au groupe de cohérence.
« Replicate initiator group » a été activé. Le groupe imitateur reste ensuite synchronisé indépendamment de l'endroit où des modifications sont apportées.
|
|
Dans une configuration d'accès non uniforme, le groupe initiateur ne doit pas être répliqué, car un groupe initiateur distinct doit être configuré sur le second cluster de stockage. |
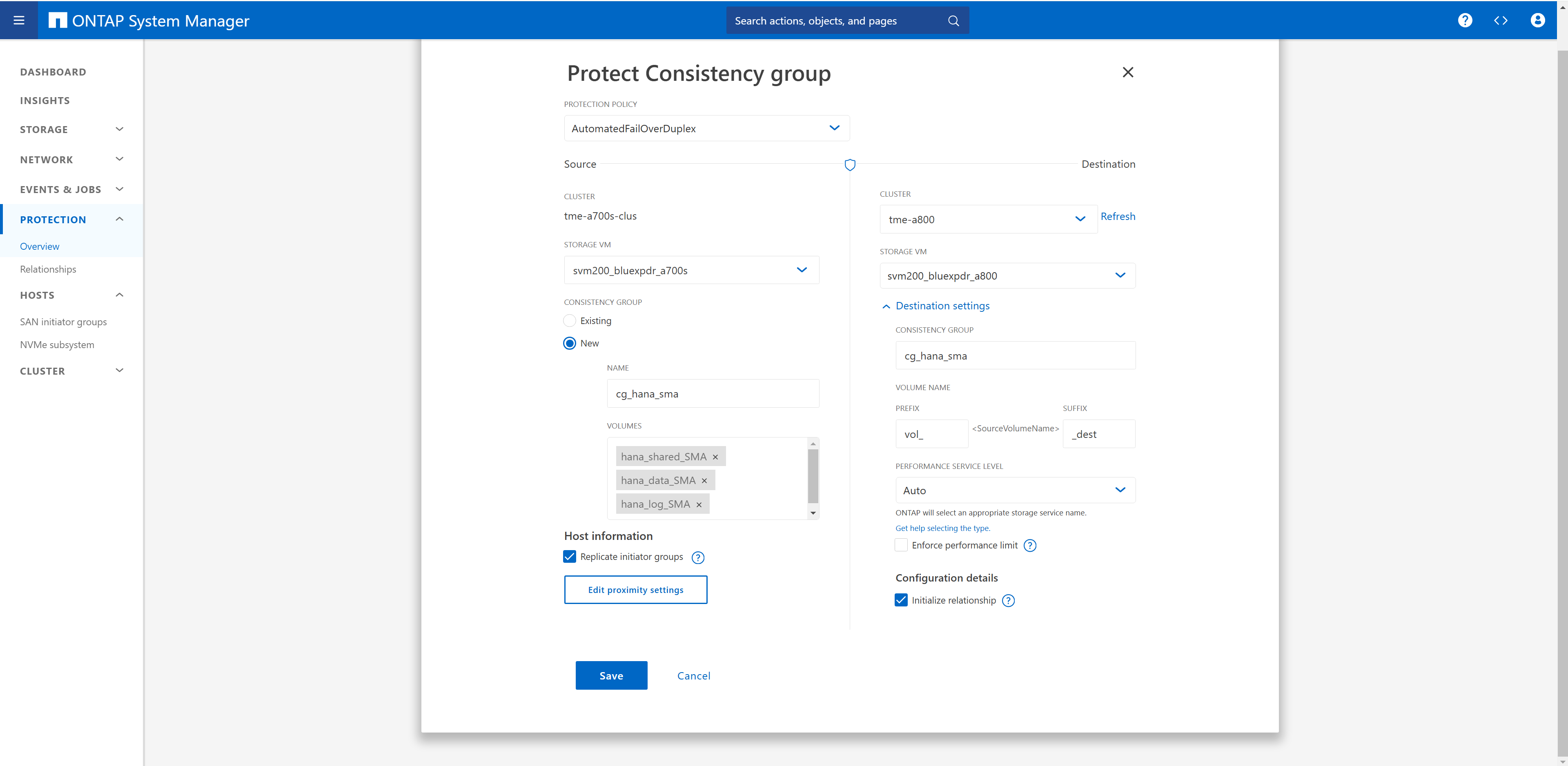
En cliquant sur les paramètres de proximité, vous pouvez vérifier la configuration effectuée auparavant dans la configuration des groupes initiateurs.
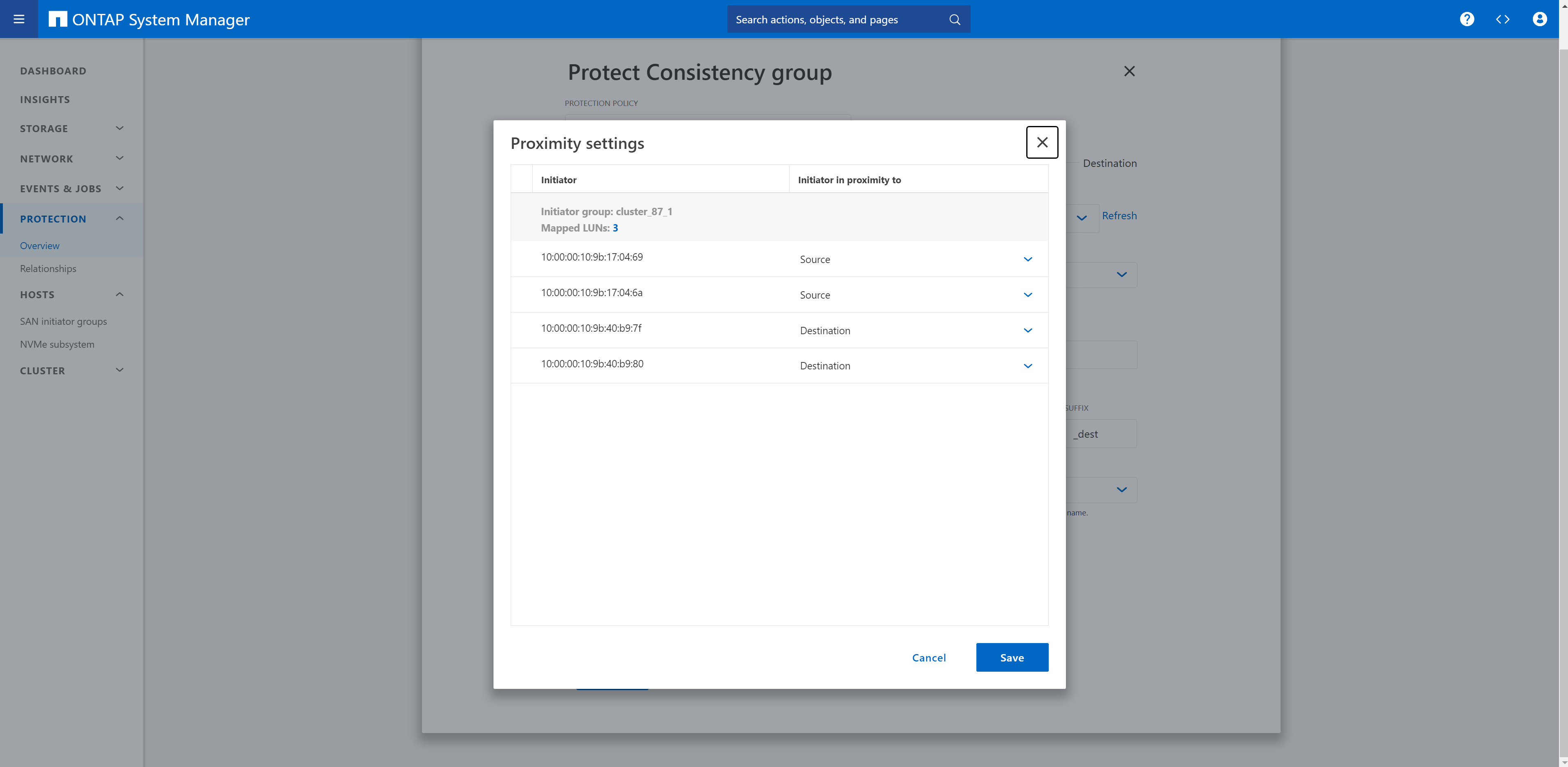
Le cluster de stockage de destination doit être configuré et « initialize relation » doit être activé.
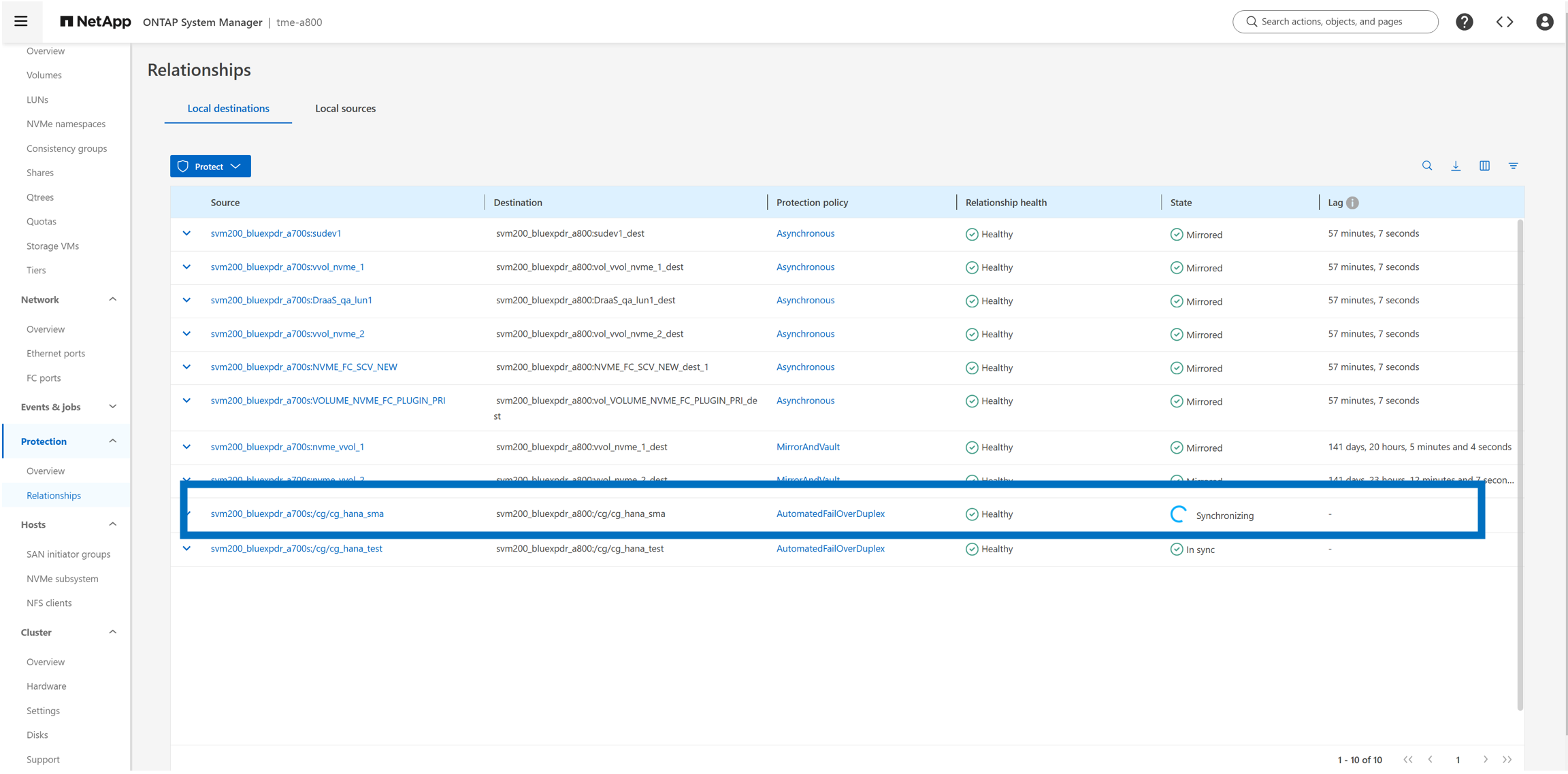
Synchronisation
La nouvelle relation est maintenant répertoriée dans le cluster de stockage A700 (source).
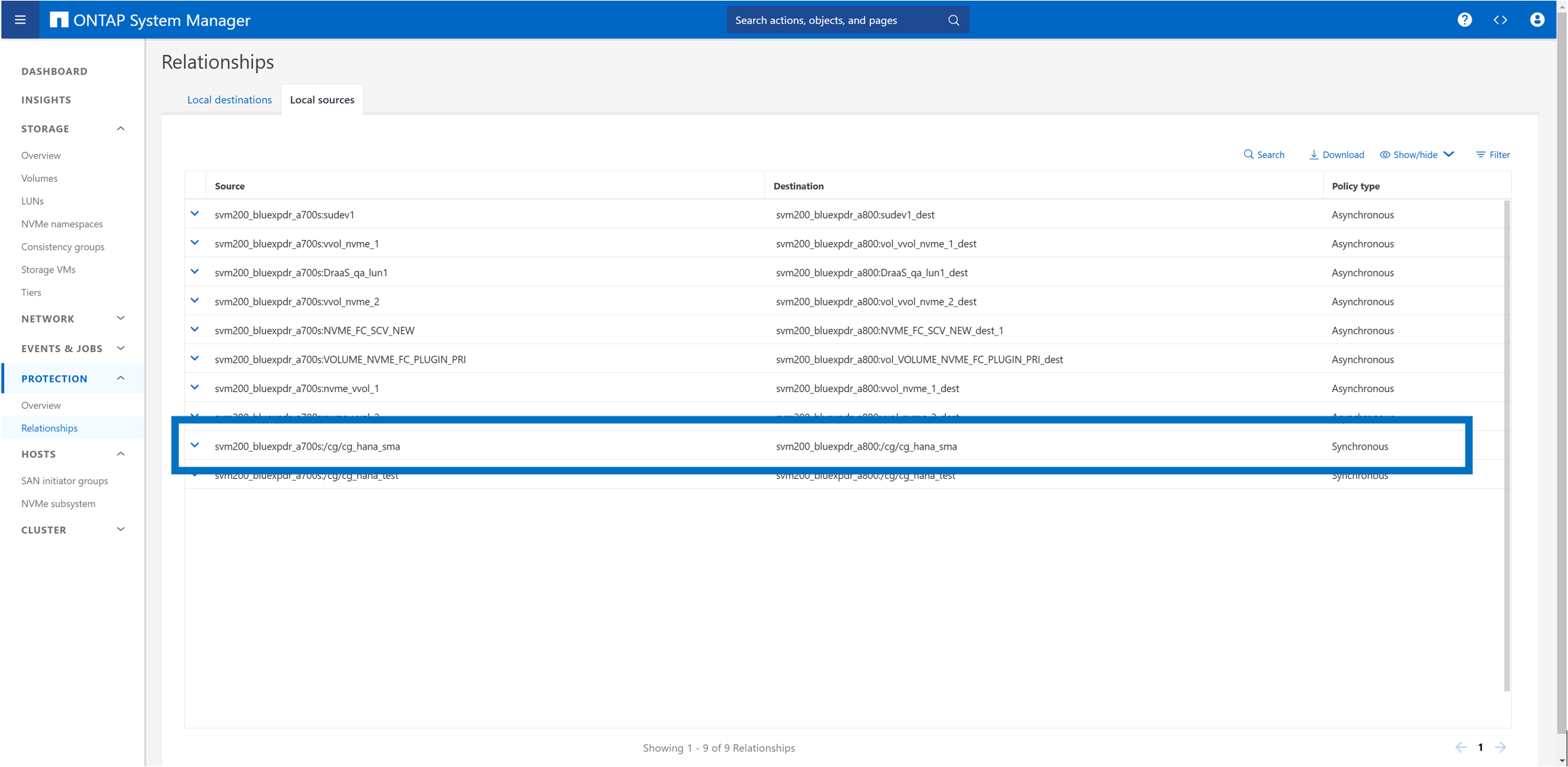
Sur le cluster de stockage A800 (destination), la nouvelle relation et l'état de la réplication sont répertoriés.
Datastore de l'infrastructure
Le datastore, où les images du système d'exploitation du système HANA, SnapCenter et le plug-in vSphere sont stockés, est répliqué de la même manière que pour les datastores de base de données HANA.
Site primaire
Le comportement de la synchronisation active SnapMirror est symétrique, avec une exception importante : la configuration du site principal.
La synchronisation active SnapMirror considère un site comme la « source » et l'autre comme la « destination ». Cela implique une relation de réplication unidirectionnelle, mais cela ne s'applique pas au comportement d'E/S. La réplication est bidirectionnelle et symétrique. Les temps de réponse d'E/S sont identiques de part et d'autre du miroir.
En cas de perte du lien de réplication, les chemins de LUN sur la copie source continueront à transmettre des données tandis que les chemins de LUN sur la copie de destination deviendront indisponibles jusqu'à ce que la réplication soit rétablie et que SnapMirror passe à un état synchrone. Les chemins reprennent alors le service des données.
La désignation d'un cluster comme source contrôle simplement le cluster qui survit en tant que système de stockage en lecture/écriture en cas de perte du lien de réplication.
Le site primaire est détecté par SnapCenter et utilisé pour exécuter les opérations de sauvegarde, de restauration et de clonage.
|
|
N'oubliez pas que la source et la destination ne sont pas liées au SVM ou au cluster de stockage, mais peuvent être différentes pour chaque relation de réplication. |