

Hadoop S3A 튜닝
 변경 제안
변경 제안
안젤라 청 _ 에 의해
Hadoop S3A 커넥터는 Hadoop 기반 애플리케이션과 S3 오브젝트 스토리지 간의 원활한 상호 작용을 지원합니다. S3 오브젝트 스토리지로 작업할 때 성능을 최적화하려면 Hadoop S3A Connector를 튜닝해야 합니다. 세부 조정을 시작하기에 앞서, Hadoop과 그 구성 요소에 대한 기본적인 이해를 갖췄습니다.
Hadoop이란?
-
Hadoop * 은 대규모 데이터 처리 및 스토리지를 처리하도록 설계된 강력한 오픈 소스 프레임워크입니다. 이를 통해 컴퓨터 클러스터 간에 분산 스토리지 및 병렬 처리가 가능합니다.
Hadoop의 3가지 핵심 구성 요소는 다음과 같습니다.
-
* Hadoop HDFS (Hadoop 분산 파일 시스템) * : 스토리지를 처리하고 데이터를 블록으로 분할하여 노드에 분산시킵니다.
-
* Hadoop MapReduce *: 작업을 작은 청크로 분할하고 병렬로 실행하여 데이터를 처리합니다.
-
* Hadoop YARN (또 다른 리소스 협상 담당자) : * "리소스를 관리하고 작업을 효율적으로 예약합니다"
Hadoop HDFS 및 S3A 커넥터
HDFS는 Hadoop 에코시스템의 핵심 구성 요소로, 효율적인 빅 데이터 처리에 중요한 역할을 합니다. HDFS는 안정적인 스토리지 및 관리를 지원합니다. 병렬 처리 및 최적화된 데이터 스토리지를 보장하여 데이터 액세스 및 분석 속도가 빨라집니다.
빅데이터 처리 시 HDFS는 대규모 데이터 세트를 위한 내결함성 스토리지를 제공하는 데 탁월합니다. 이 점은 데이터 복제를 통해 실현됩니다. 데이터 웨어하우스 환경에서 대량의 정형 데이터와 비정형 데이터를 저장하고 관리할 수 있습니다. 또한 Apache Spark, Hive, Pig 및 Flink와 같은 선도적인 빅 데이터 처리 프레임워크와 원활하게 통합되어 확장 가능하고 효율적인 데이터 처리가 가능합니다. Unix 기반(Linux) 운영 체제와 호환되기 때문에 빅 데이터 처리를 위해 Linux 기반 환경을 사용하는 것을 선호하는 기업에 이상적인 선택입니다.
시간이 지나면서 데이터 볼륨이 증가함에 따라 자체 컴퓨팅 및 스토리지를 사용하여 Hadoop 클러스터에 새 시스템을 추가하는 방식이 비효율적이 되었습니다. 선형적으로 확장하면 리소스를 효율적으로 사용하고 인프라를 관리하는 데 어려움이 발생합니다.
이러한 과제를 해결하기 위해 Hadoop S3A 커넥터는 S3 오브젝트 스토리지에 대한 고성능 I/O를 제공합니다. S3A를 사용하여 Hadoop 워크플로우를 구축하면 오브젝트 스토리지를 데이터 저장소로 활용할 수 있으며, 컴퓨팅과 스토리지를 독립적으로 확장할 수 있는 분리된 컴퓨팅 및 스토리지를 사용할 수 있습니다. 또한 컴퓨팅과 스토리지를 분리하면 컴퓨팅 작업에 적절한 양의 리소스를 투입하고 데이터 세트의 크기에 따라 용량을 제공할 수 있습니다. 따라서 Hadoop 워크플로우의 전체 TCO를 줄일 수 있습니다.
Hadoop S3A 커넥터 튜닝
S3는 HDFS와 다르게 동작하며 파일 시스템의 모양을 유지하려는 일부 시도는 공격적으로 최적화되지 않습니다. S3 리소스를 가장 효율적으로 활용하려면 신중한 튜닝/테스트/실험이 필요합니다.
이 문서의 Hadoop 옵션은 Hadoop 3.3.5를 기반으로 합니다. 을 참조하십시오 "Hadoop 3.3.5 core-site.xml" 사용 가능한 모든 옵션
참고 – 일부 Hadoop fs.s3a 설정의 기본값은 Hadoop 버전마다 다릅니다. 현재 Hadoop 버전과 관련된 기본값을 확인하십시오. 이러한 설정이 Hadoop core-site.xml에 지정되지 않은 경우 기본값이 사용됩니다. Spark 또는 Hive 구성 옵션을 사용하여 런타임에 값을 재정의할 수 있습니다.
이 페이지로 이동해야 합니다 "아파치 하둡 페이지" 각 fs.s3a 옵션을 이해합니다. 가능한 경우 비운영 Hadoop 클러스터에서 테스트하여 최적의 값을 찾습니다.
읽어야 합니다 "S3A 커넥터로 작업할 때 성능을 극대화합니다" 기타 튜닝 권장 사항
몇 가지 주요 고려 사항을 살펴보겠습니다.
-
1. 데이터 압축 *
StorageGRID 압축을 활성화하지 마십시오. 대부분의 빅 데이터 시스템은 전체 객체를 검색하는 대신 바이트 범위 GET를 사용합니다. 압축된 객체와 함께 GET 바이트 범위를 사용하면 GET 성능이 크게 저하됩니다.
-
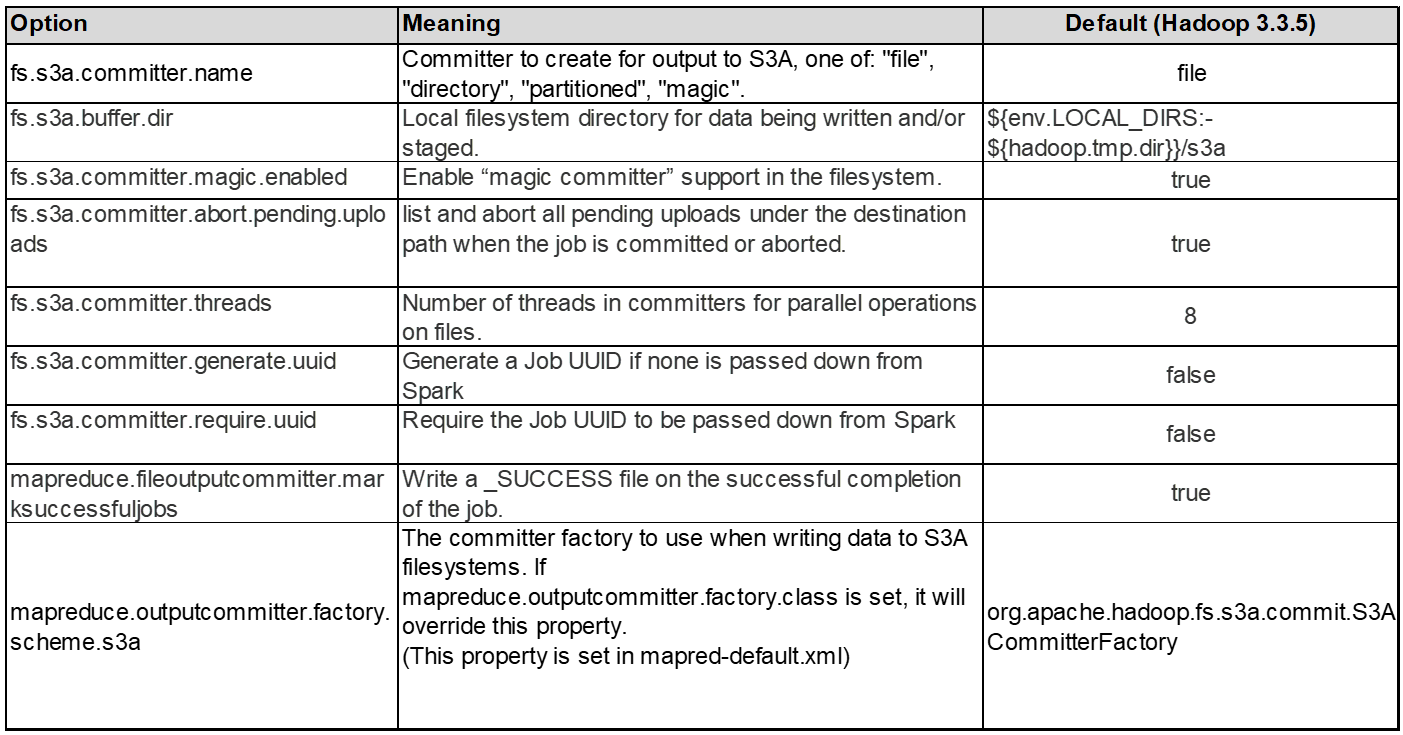
2. S3A 커밋 *
일반적으로 magic s3a committer가 권장됩니다. 이를 참조하십시오 "일반 S3A 커밋 옵션 페이지" 마법 커밋 및 관련 s3a 설정에 대한 더 나은 이해를 얻기 위해.
매직 커미터:
Magic Committer는 특히 S3Guard에 의존하여 S3 오브젝트 저장소에서 일관된 디렉토리 목록을 제공합니다.
이제 일관된 S3(이 경우)를 통해 Magic Committer를 모든 S3 버킷과 함께 안전하게 사용할 수 있습니다.
선택 및 실험:
사용 사례에 따라 클러스터 HDFS 파일 시스템에 의존하는 스테이징 커밋자와 Magic committer 중에서 선택할 수 있습니다.
두 가지를 모두 실험하여 귀사의 워크로드 및 요구사항에 가장 적합한 솔루션을 결정하십시오.
요약하면, S3A committers는 S3에 대한 일관적이고, 고성능의 안정적인 출력 약속이라는 근본적인 과제에 대한 솔루션을 제공합니다. 내부 설계로 데이터 무결성을 유지하면서 효율적인 데이터 전송을 보장합니다.
-
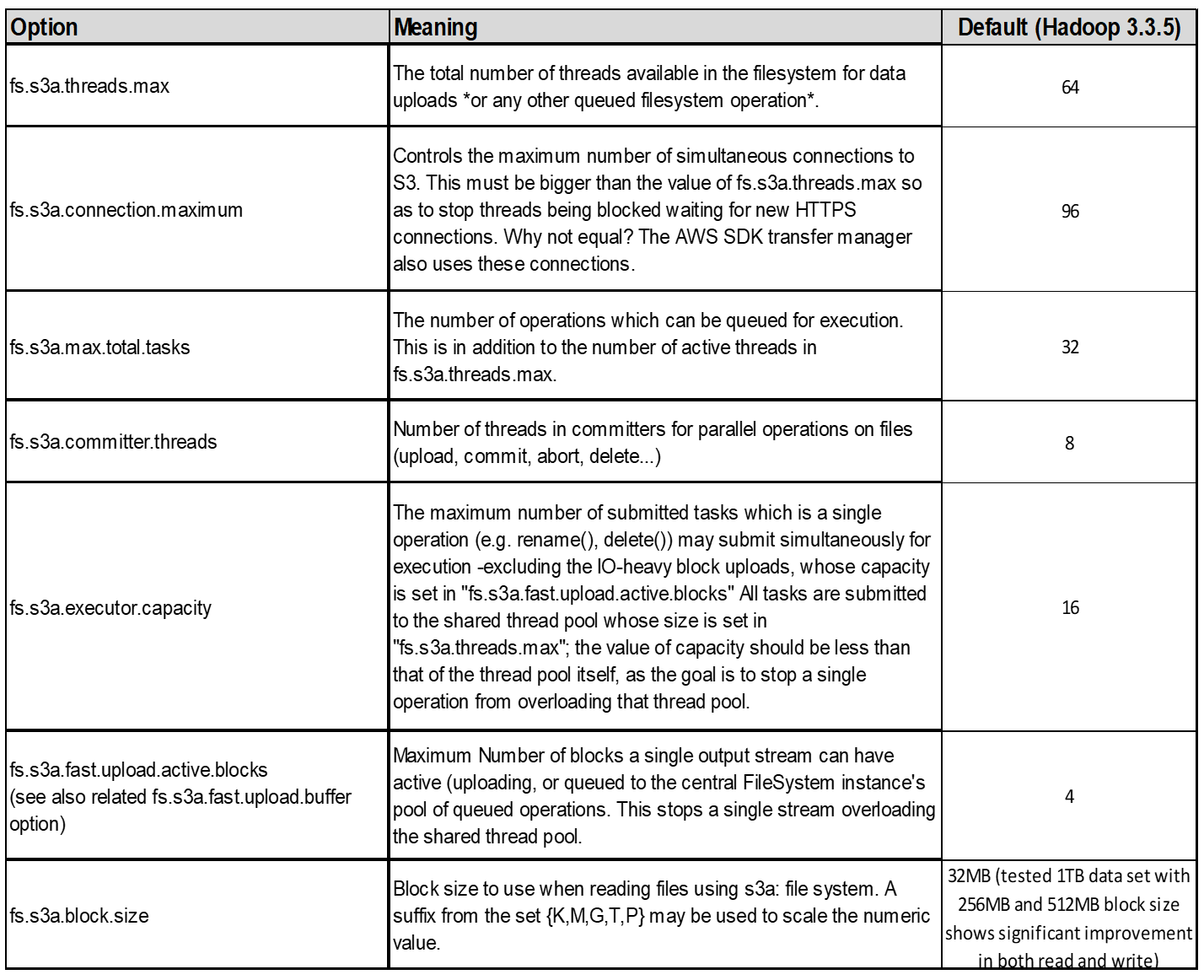
3. 스레드, 연결 풀 크기 및 블록 크기 *
-
단일 버킷과 상호 작용하는 각 * S3A * 클라이언트에는 업로드 및 복사 작업을 위한 개방형 HTTP 1.1 연결 전용 풀과 스레드가 있습니다.
-
S3에 데이터를 업로드하면 블록으로 나뉩니다. 기본 블록 크기는 32MB입니다. fs.s3a.block.size 속성을 설정하여 이 값을 사용자 지정할 수 있습니다.
-
블록 크기가 클수록 업로드 시 다중 파트 관리 오버헤드를 줄여 대용량 데이터 업로드의 성능을 향상시킬 수 있습니다. 대용량 데이터 세트의 권장 값은 256MB 이상입니다.
-
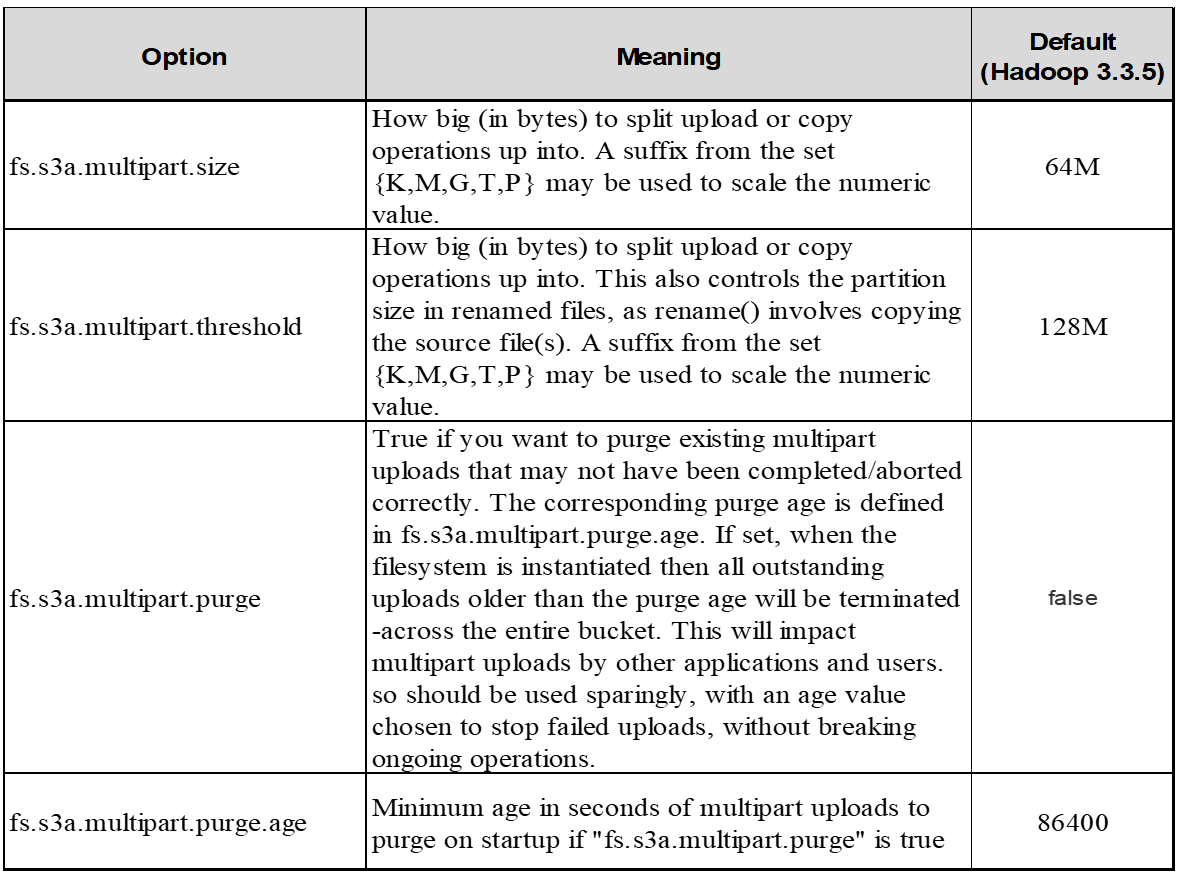
4. 멀티 파트 업로드 *
s3a committers * 항상 * MPU(멀티 파트 업로드)를 사용하여 데이터를 S3 버킷에 업로드합니다. 작업 실패, 추측에 의한 작업 실행, 커밋 전 작업 중단 등을 허용하기 위해 필요합니다. 다음은 다중 파트 업로드와 관련된 몇 가지 주요 사양입니다.
-
최대 개체 크기: 5TiB(테라바이트)
-
업로드당 최대 부품 수: 10,000.
-
부품 번호: 1 ~ 10,000 범위(포함).
-
부품 크기: 5MiB에서 5GiB 사이. 멀티 파트 업로드의 마지막 부분에 대한 최소 크기 제한은 없습니다.
S3 멀티 파트 업로드에 더 작은 파트 크기를 사용하면 장점과 단점이 모두 있습니다.
-
장점 *:
-
네트워크 문제에서 빠른 복구: 작은 부품을 업로드하면 네트워크 오류로 인해 실패한 업로드를 다시 시작할 때의 영향이 최소화됩니다. 부품에 오류가 발생하면 전체 오브젝트가 아닌 특정 부분만 다시 업로드하면 됩니다.
-
향상된 병렬 처리: 다중 스레딩 또는 동시 연결을 활용하여 더 많은 파트를 병렬로 업로드할 수 있습니다. 이 병렬화는 특히 큰 파일을 처리할 때 성능을 향상시킵니다.
-
단점 *:
-
네트워크 오버헤드: 파트 크기가 작을수록 업로드할 파트가 더 많아지며 각 파트마다 자체 HTTP 요청이 필요합니다. HTTP 요청이 많을수록 개별 요청을 시작 및 완료하는 데 따르는 오버헤드가 증가합니다. 많은 수의 작은 파트를 관리하면 성능에 영향을 줄 수 있습니다.
-
복잡성: 주문 관리, 부품 추적, 성공적인 업로드 보장은 번거로울 수 있습니다. 업로드를 중단해야 하는 경우 이미 업로드한 모든 부품을 추적하고 제거해야 합니다.
Hadoop의 경우 fs.s3a.multipart.size에 256MB 이상의 파트 크기가 권장됩니다. 항상 fs.s3a.mutlipart.threshold 값을 2 x fs.s3a.multipart.size 값으로 설정하십시오. 예를 들어 fs.s3a.multipart.size=256M,fs.s3a.mullipart.threshold는 512M이어야 합니다.
대형 데이터 세트에 더 큰 파트 크기를 사용합니다. 특정 사용 사례와 네트워크 상태에 따라 이러한 요소의 균형을 맞추는 부품 크기를 선택하는 것이 중요합니다.
다중 부분 업로드는 입니다 "3단계 프로세스":
-
업로드가 시작되면 StorageGRID에서 업로드 ID를 반환합니다.
-
개체 부분은 upload-id를 사용하여 업로드됩니다.
-
모든 객체 부분이 업로드되면 는 업로드 ID와 함께 완전한 멀티 파트 업로드 요청을 보냅니다. StorageGRID는 업로드된 부분에서 객체를 생성하며 클라이언트는 객체에 액세스할 수 있습니다.
전체 다중 파트 업로드 요청이 성공적으로 전송되지 않으면 부품은 StorageGRID에 남아 있고 객체를 생성하지 않습니다. 이 문제는 작업이 중단, 실패 또는 중단될 때 발생합니다. 업로드가 시작된 후 15일이 경과하면 멀티 파트 업로드가 완료되거나 중단되거나 StorageGRID가 이러한 부품을 제거할 때까지 파트가 그리드에 남아 있습니다. 버킷에 여러 개의(수억 ~ 수백만) 진행 중인 멀티 파트 업로드가 있는 경우 Hadoop이 'list-multipart-uploads'를 전송할 때(이 요청은 업로드 ID로 필터링되지 않음) 요청을 완료하는 데 시간이 오래 걸리거나 시간이 초과될 수 있습니다. 적절한 fs.s3a.mutlipart.purge를 true로 설정하여 적절한 fs.s3a.multipart.purge.age 값을 설정할 수 있습니다(예: 5-7일, 기본값 86400, 즉 1일을 사용하지 마십시오). 또는 NetApp 지원 팀에 문의하여 상황을 조사하십시오.
-
5. 메모리의 버퍼 쓰기 데이터 *
성능을 높이기 위해 쓰기 데이터를 S3에 업로드하기 전에 메모리에 버퍼링할 수 있습니다. 이렇게 하면 작은 쓰기 수를 줄이고 효율성을 높일 수 있습니다.

S3 및 HDFS는 서로 다른 방식으로 작동한다는 점을 기억하십시오. S3 리소스를 가장 효율적으로 활용하려면 신중한 튜닝/테스트/실험이 필요합니다.