

Der Netapp Architektur Sind
 Änderungen vorschlagen
Änderungen vorschlagen
Die FlexPod-Architektur bietet Hochverfügbarkeit, wenn eine Komponente oder ein Link im gesamten Computing-, Netzwerk- und Storage Stack ausfällt. Mehrere Netzwerkpfade für Client-Zugriff und Storage-Zugriff ermöglichen Lastausgleich und eine optimale Ressourcenauslastung.
Die folgende Abbildung zeigt die 16-GB-FC-/40-GB-Ethernet-Topologie (40 GbE) für den Einsatz der Lösung für medizinische Bildgebsysteme.
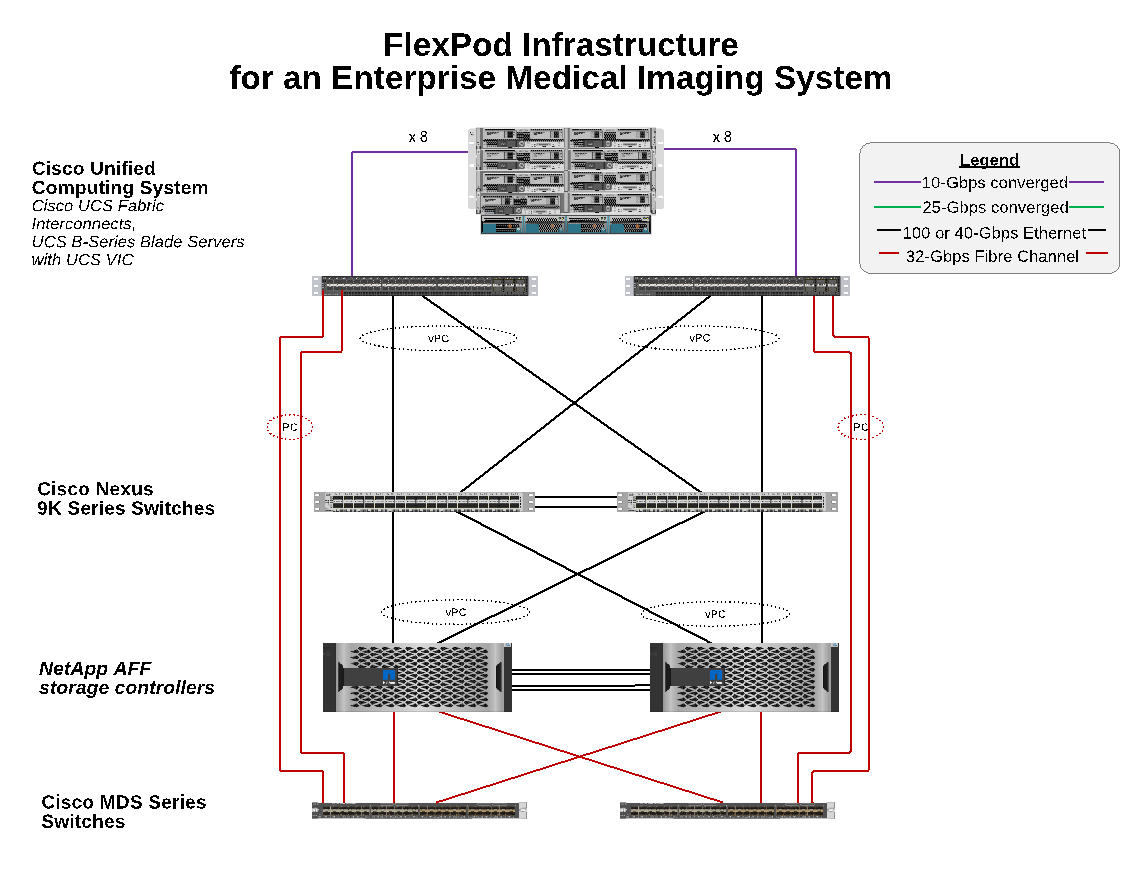
Storage-Architektur
Mithilfe der in diesem Abschnitt aufgeführten Richtlinien zur Storage-Architektur können Sie Ihre Storage-Infrastruktur für ein medizinisches Bildgebungssystem eines Unternehmens konfigurieren.
Storage-Tiers
Eine typische medizinische Bildgebungsumgebung in Unternehmen setzt sich aus mehreren unterschiedlichen Storage-Tiers zusammen. Jeder Tier verfügt über spezifische Anforderungen an Performance und Storage-Protokoll. NetApp Storage unterstützt verschiedene RAID-Technologien, weitere Informationen sind verfügbar "Hier". Im Folgenden erfahren Sie, wie NetApp AFF Storage-Systeme die Anforderungen verschiedener Storage Tiers für das Bildgebungssystem erfüllen:
-
Performance Storage (Tier 1). dieser Tier bietet eine hohe Leistung und hohe Redundanz für Datenbanken, Betriebssystemlaufwerke, VMware Virtual Machine File System (VMFS) Datenspeicher und so weiter. Block-I/O wird wie in ONTAP konfiguriert über Fibre in ein Shared-Storage-Array von SSD verschoben. Die minimale Latenz beträgt 1 ms bis 3 ms, wobei gelegentlich 5 ms Spitzenwert liegt. Diese Speicherebene wird in der Regel für den kurzfristigen Speicher-Cache verwendet, in der Regel 6 bis 12 Monate Bildspeicher für den schnellen Zugriff auf Online-DICOM-Bilder. Dieser Tier bietet hohe Performance und hohe Redundanz für Image-Caches, Datenbank-Backup usw. NetApp All-Flash-Arrays bieten eine Latenz von <1 ms bei einer kontinuierlichen Bandbreite, die weit unter den für eine typische medizinische Bildgebungsumgebung der Enterprise-Klasse erwarteten Servicezeiten liegt. NetApp ONTAP unterstützt sowohl RAID-TEC (Triple-Parity RAID zur Aufrechterhaltung des Ausfalls von drei Festplatten) als auch RAID DP (Double-Parity RAID zur Erhaltung von zwei Festplattenausfällen).
-
Archivspeicher (Tier 2). dieser Tier wird für typischen kostenoptimierten Dateizugriff, RAID 5- oder RAID 6-Speicher für größere Volumes und langfristige Archivierung mit geringeren Kosten/Leistung verwendet. NetApp ONTAP unterstützt sowohl RAID-TEC (Triple-Parity RAID zur Aufrechterhaltung des Ausfalls von drei Festplatten) als auch RAID DP (Double-Parity RAID zur Erhaltung von zwei Festplattenausfällen). Die NetApp FAS in FlexPod ermöglicht die I/O-Bildgebung von Applikationen über NFS/SMB auf ein SAS-Festplatten-Array. NetApp FAS Systeme bieten eine Latenz von ~10 ms bei kontinuierlicher Bandbreite. Dies ist weit unter den für Storage Tier 2 in einer Umgebung mit medizinischen Bildgebungssystemen eines Unternehmens erwarteten Servicezeiten.
Die Cloud-basierte Archivierung in einer Hybrid-Cloud-Umgebung kann für die Archivierung bei einem Public-Cloud-Storage-Provider mit S3 oder ähnlichen Protokollen verwendet werden. Die NetApp SnapMirror Technologie ermöglicht die Replizierung Imaging-Daten von All-Flash- oder FAS-Arrays auf langsamere festplattenbasierte Storage-Arrays oder auf Cloud Volumes ONTAP für AWS, Azure oder Google Cloud.
NetApp SnapMirror bietet branchenführende Datenreplizierungsfunktionen, um medizinische Bildgebungssysteme durch eine einheitliche Datenreplizierung zu schützen. Vereinfachtes Datensicherungsmanagement in einer Data-Fabric-Umgebung mit plattformübergreifender Replizierung – von Flash über Festplatten bis hin zur Cloud:
-
Nahtloser und effizienter Datentransport zwischen NetApp Storage-Systemen zur Unterstützung von Backup und Disaster Recovery mit demselben Ziel-Volume und I/O-Datenstrom
-
Failover auf ein beliebiges sekundäres Volume Wiederherstellung von zeitpunktgenauen Snapshots auf sekundärem Storage
-
Schutz Ihrer wichtigsten Workloads durch eine synchrone Replikation ohne jeglichen Datenverlust (RPO=0)
-
Weniger Netzwerk-Traffic: Geringerer Storage-Bedarf durch effiziente Abläufe
-
Reduzierter Netzwerk-Traffic durch Beschränkung des Transports auf geänderte Datenblöcke
-
Kein Verlust der Vorteile der Storage-Effizienz auf dem primären Storage während des Transports – einschließlich Deduplizierung, Komprimierung und Data-Compaction
-
Zusätzliche Inline-Effizienz mit Netzwerkkomprimierung
Weitere Informationen finden Sie "Hier".
Die folgende Tabelle führt die einzelnen Tiers auf, die für ein typisches Bildgebungssystem benötigt werden, um eine bestimmte Latenz und Durchsatzleistung zu liefern.
| Storage-Tier | Anforderungen | NetApp Empfehlung |
|---|---|---|
1 |
Eine Latenz von 1 bis 5 ms beträgt ein Durchsatz von 35 bis 500 MB/s |
AFF mit <1 ms Latenz AFF A300 HA-Paar mit zwei Festplatten-Shelfs kann einen Durchsatz von bis zu ~1,6 GB/s verarbeiten |
2 |
Archivierung vor Ort |
FAS mit einer Latenz von bis zu 30 ms |
Archivierung in Cloud |
SnapMirror Replizierung auf Cloud Volumes ONTAP oder Backup-Archivierung mit NetApp StorageGRID Software |
Konnektivität zum Storage-Netzwerk
FC Fabric
-
Die FC Fabric eignet sich für I/O-Vorgänge des Host-Betriebssystems vom Computing bis zum Storage.
-
Zwei FC-Fabrics (Fabric A und Fabric B) sind mit Cisco UCS Fabric A und UCS Fabric B verbunden.
-
Auf jedem Controller-Node befindet sich eine Storage Virtual Machine (SVM) mit zwei logischen FC-Schnittstellen (LIFs). Auf jedem Node ist eine logische Schnittstelle mit Fabric A verbunden, und die andere ist mit Fabric B verbunden
-
Ende-zu-End-Konnektivität mit 16 Gbit/s erfolgt über Cisco MDS Switches. Es sind ein einzelner Initiator, mehrere Ziel-Ports und Zoning konfiguriert.
-
FC SAN Boot wird verwendet, um ein vollständiges Statusfreies Computing zu erstellen. Server werden aus LUNs im Boot-Volume gestartet, das auf dem AFF Storage-Cluster gehostet wird.
IP-Netzwerk für Storage-Zugriff über iSCSI, NFS und SMB/CIFS
-
An jedem Controller-Node befinden sich zwei iSCSI LIFs in der SVM. Auf jedem Node ist eine logische Schnittstelle mit Fabric A verbunden, und die zweite ist mit Fabric B verbunden
-
An jedem Controller-Node befinden sich zwei NAS-Daten-LIFs in der SVM. Auf jedem Node ist eine logische Schnittstelle mit Fabric A verbunden, und die zweite ist mit Fabric B verbunden
-
Storage Port Interface Groups (virtueller Port Channel [vPC]) für 10 GB/s Link zum Switch N9k-A und für 10 GB/s Link zum Switch N9k-B.
-
Workload in Ext4 oder NTFS-Dateisystemen von VM zum Storage:
-
ISCSI-Protokoll über IP:
-
-
VMs gehostet im NFS-Datenspeicher:
-
VM-I/O-Vorgänge erfolgen über mehrere Ethernet-Pfade durch Nexus Switches.
-
In-Band-Management (aktiv/Passiv-Bond)
-
1-Gbit/s-Link zum Management-Switch N9k-A und 1 Gbit/s-Link zum Management-Switch N9k-B.
Backup und Recovery
FlexPod Datacenter basiert auf einem Storage-Array, das von der Datenmanagement-Software NetApp ONTAP gemanagt wird. Die ONTAP Software hat sich über 20 Jahre lang weiterentwickelt und bietet viele Datenmanagement-Funktionen für VMs, Oracle Datenbanken, SMB/CIFS-Dateifreigaben und NFS. Zudem stellt sie Sicherungstechnologien wie die NetApp Snapshot Technologie, die SnapMirror Technologie und die Datenreplizierungstechnologie NetApp FlexClone bereit. Die NetApp SnapCenter Software verfügt über einen Server und einen GUI-Client zur Verwendung von ONTAP Snapshot, SnapRestore und FlexClone Funktionen für VM, SMB/CIFS File Shares, NFS und Oracle Datenbanken Backup und Recovery.
Die NetApp SnapCenter Software beschäftigt "Patentiert" Snapshot Technologie, um sofort ein Backup einer kompletten VM oder Oracle-Datenbank auf einem NetApp-Speicher-Volume zu erstellen. Im Vergleich mit Oracle Recovery Manager (RMAN) benötigen Snapshot Kopien keine vollständige Baseline Backup-Kopie, da sie nicht als physische Kopien von Blöcken gespeichert werden. Snapshot-Kopien werden als Zeiger auf die Storage-Blöcke gespeichert, während sie sich beim Erstellen der Snapshot Kopien im ONTAP WAFL File-System befanden. Aufgrund dieser engen physischen Beziehung verbleiben die Snapshot Kopien im selben Storage Array wie die Originaldaten. Zudem können Snapshot Kopien auf Dateiebene erstellt werden, um Ihnen eine granularere Kontrolle für das Backup zu bieten.
Die Snapshot Technologie basiert auf einer Redirect-on-Write-Technik. Er enthält anfangs nur Metadaten-Zeiger und verbraucht erst dann viel Speicherplatz, wenn sich die ersten Daten in einen Storage-Block ändern. Wenn ein vorhandener Block von einer Snapshot Kopie gesperrt wird, wird ein neuer Block vom Dateisystem ONTAP WAFL als aktive Kopie geschrieben. Dieser Ansatz vermeidet die doppelten Schreibvorgänge, die bei der Change-on-Write-Technik auftreten.
Bei Datenbank-Backups von Oracle erzielen Snapshot Kopien unglaubliche Zeiteinsparungen. Ein Backup, das beispielsweise mit RMAN allein 26 Stunden dauerte, kann mithilfe der SnapCenter Software weniger als zwei Minuten dauern.
Und da bei der Datenwiederherstellung keine Datenblöcke kopiert, sondern stattdessen die Zeiger auf die applikationskonsistenten Snapshot Block-Images überträgt, wenn die Snapshot Kopie erstellt wurde, kann eine Snapshot Backup-Kopie fast sofort wiederhergestellt werden. Klonen von SnapCenter erstellt eine separate Kopie von Metadaten-Pointern auf eine vorhandene Snapshot Kopie und bindet die neue Kopie an einen Ziel-Host. Dieser Prozess läuft auch schnell und speichereffizient ab.
In der folgenden Tabelle sind die Hauptunterschiede zwischen Oracle RMAN und NetApp SnapCenter Software zusammengefasst.
| Backup | Wiederherstellen | Klon | Vollständige Backups Erforderlich | Speicherplatznutzung | Externer Text | |
|---|---|---|---|---|---|---|
RMAN |
Langsam |
Langsam |
Langsam |
Ja. |
Hoch |
Ja. |
SnapCenter |
Schnell |
Schnell |
Schnell |
Nein |
Niedrig |
Ja. |
Die folgende Abbildung zeigt die SnapCenter Architektur.
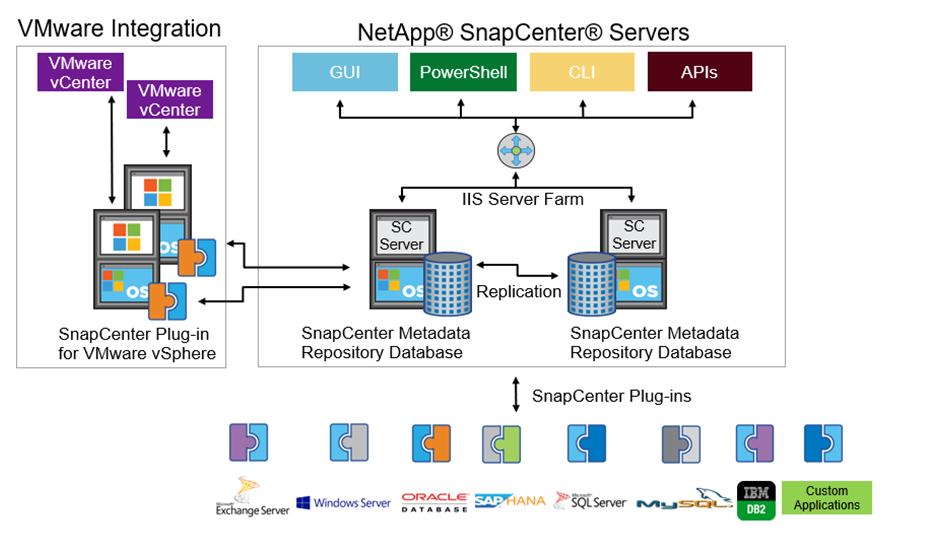
NetApp MetroCluster Konfigurationen werden von Tausenden von Unternehmen weltweit für Hochverfügbarkeit (HA), null Datenverlust und unterbrechungsfreie Abläufe innerhalb und außerhalb des Rechenzentrums eingesetzt. MetroCluster ist eine kostenlose Funktion der ONTAP Software, die Daten und Konfigurationen zwischen zwei ONTAP Clustern an verschiedenen Standorten oder Ausfalldomänen synchron spiegelt. MetroCluster bietet kontinuierlich verfügbaren Speicher für Anwendungen, indem zwei Ziele automatisch erfüllt werden: Null Recovery Point Objective (RPO) durch synchrones Spiegeln der in den Cluster geschriebenen Daten. Nahezu Null Recovery Time Objective (RTO) durch Spiegeln der Konfiguration und automatisierten Zugriff auf Daten am zweiten Standort. MetroCluster bietet Einfachheit durch die automatische Spiegelung von Daten und Konfigurationen zwischen den beiden unabhängigen Clustern an den beiden Standorten. Wenn Speicher in einem Cluster bereitgestellt wird, wird er automatisch auf den zweiten Cluster am zweiten Standort gespiegelt. NetApp SyncMirror Technologie erstellt eine vollständige Kopie aller Daten mit einem RPO von Null. Daher können Workloads von einem Standort jederzeit auf den anderen Standort umgeschaltet werden und die Datenbereitstellung erfolgt ohne Datenverlust. Weitere Informationen sind verfügbar "Hier".
Netzwerkbetrieb
Ein Cisco Nexus Switch-Paar stellt redundante Pfade für den IP-Datenverkehr vom Computing zum Storage und für externe Clients der Image-Viewer des medizinischen Bildgebungssystems bereit:
-
Die Link-Aggregation, die Port-Kanäle und vPCs nutzt, wird durchgehend verwendet, was das Design für eine höhere Bandbreite und hohe Verfügbarkeit ermöglicht:
-
VPC wird zwischen dem NetApp Storage-Array und den Cisco Nexus Switches verwendet.
-
VPC wird zwischen dem Cisco UCS Fabric Interconnect und den Cisco Nexus Switches verwendet.
-
Jeder Server verfügt über virtuelle Netzwerk-Schnittstellenkarten (vNICs) mit redundanter Konnektivität zum Unified Fabric. Für Redundanz wird NIC Failover zwischen Fabric Interconnects verwendet.
-
Jeder Server verfügt über virtuelle Host Bus Adapter (vHBAs) mit redundanter Konnektivität zum Unified Fabric.
-
-
Die Cisco UCS Fabric Interconnects sind gemäß der Empfehlung im End-Host-Modus konfiguriert, sodass vNICs dynamisch an Uplink-Switches gepinnen werden.
-
Ein FC-Storage-Netzwerk wird von einem Paar Cisco MDS Switches bereitgestellt.
Computing – Cisco Unified Computing System
Zwei Cisco UCS Fabrics über verschiedene Fabric Interconnects bieten zwei Ausfall-Domains. Jede Fabric ist sowohl mit IP-Netzwerk-Switches als auch mit unterschiedlichen FC-Netzwerk-Switches verbunden.
Zum Ausführen von VMware ESXi werden für jedes Cisco UCS Blade identische Service-Profile gemäß den Best Practices von FlexPod erstellt. Jedes Service-Profil sollte die folgenden Komponenten aufweisen:
-
Zwei vNICs (eine pro Fabric) für NFS, SMB/CIFS und Client- oder Management-Datenverkehr
-
Zusätzliche erforderliche VLANs für die vNICs für NFS, SMB/CIFS und Client- oder Managementdatenverkehr
-
Zwei vNICs (einer auf jeder Fabric) für den iSCSI-Datenverkehr
-
Zwei Storage FC HBAs (einer pro Fabric) für FC-Datenverkehr zum Storage
-
SAN Booting
Einheitliche
Auf dem VMware ESXi-Host-Cluster werden Workload-VMs ausgeführt. Der Cluster umfasst ESXi Instanzen, die auf Cisco UCS Blade-Servern ausgeführt werden.
Jeder ESXi-Host umfasst die folgenden Netzwerkkomponenten:
-
SAN Booting über FC oder iSCSI
-
Boot-LUNs auf NetApp Storage (in einem dedizierten FlexVol für Boot OS)
-
Zwei vmnics (Cisco UCS vNIC) für NFS, SMB/CIFS oder Managementverkehr
-
Zwei Storage HBAs (Cisco UCS FC vHBA) für FC-Datenverkehr zum Storage
-
Standard-Switch oder verteilter virtueller Switch (je nach Bedarf)
-
NFS-Datenspeicher für Workload VMs
-
Management, Client-Traffic-Netzwerk und Storage-Netzwerk-Port-Gruppen für VMs
-
Netzwerkadapter für Management, Client-Traffic und Storage-Zugriff (NFS, iSCSI oder SMB/CIFS) für jede VM
-
VMware DRS ist aktiviert
-
Natives Multipathing für FC- oder iSCSI-Pfade zum Storage aktiviert
-
Deaktiviert die VMware Snapshots für VM
-
NetApp SnapCenter für VMware für VM-Backups implementiert
Architektur des Bildgebungssystems für den medizinischen Bereich
In medizinischen Einrichtungen sind Bildgebungssysteme wichtige Applikationen und gut in die klinischen Workflows integriert – angefangen bei der Registrierung von Patienten bis hin zur Abrechnung über Aktivitäten im Umsatzzyklus.
Das folgende Diagramm zeigt die verschiedenen Systeme in einem typischen großen Krankenhaus; dieses Diagramm soll einen architektonischen Kontext zu einem medizinischen Bildgebungssystem liefern, bevor wir in die architektonischen Komponenten eines typischen medizinischen Bildgebungssystems hineinzoomen. Die Workflows unterscheiden sich sehr stark und sind für Krankenhäuser und Anwendungsfälle spezifisch.
Die Abbildung unten zeigt das medizinische Bildgebungssystem im Kontext eines Patienten, einer Gemeinschaftsklinik und eines großen Krankenhauses.
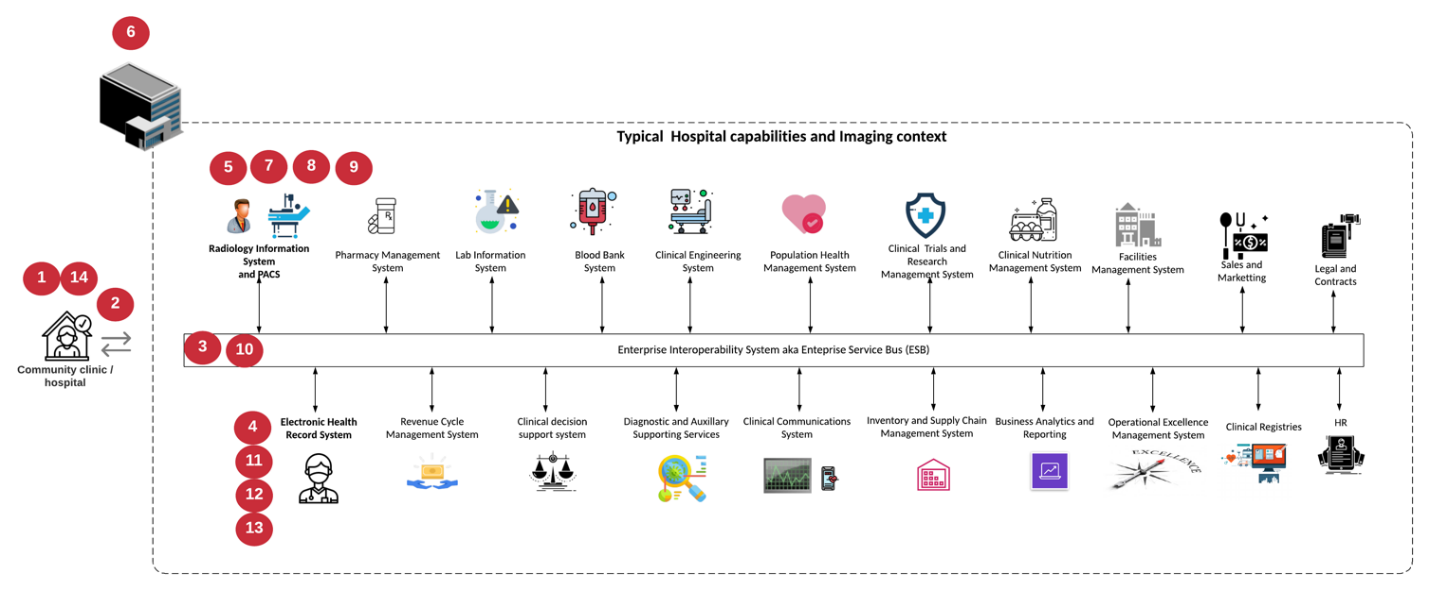
-
Der Patient besucht die Gemeinschaftsklinik mit Symptomen. Während der Konsultation legt der Gemeindearzt einen Bildgebungsauftrag auf, der in Form einer HL7-Auftragsnachricht an das größere Krankenhaus geschickt wird.
-
Das EHR-System des Hausarztes sendet die HL7 Order/ORD-Nachricht an das große Krankenhaus.
-
Das Enterprise-Interoperabilitätssystem (auch bekannt als Enterprise Service Bus [ESB]) verarbeitet die Auftragsmeldung und sendet die Auftragsnachricht an das EHR-System.
-
Das EHR verarbeitet die Auftragsnachricht. Wenn kein Patientendatensatz vorhanden ist, wird ein neuer Patientendatensatz erstellt.
-
Der EHR-Auftrag sendet an das medizinische Bildgebungssystem.
-
Der Patient ruft das große Krankenhaus für einen Bildgebungstermin an.
-
Der Bildgebungs-Empfang und der Registrierungstisch planen den Patienten für einen Bildgebungstermin mit Hilfe von Radiologie-Informationen oder ähnlichen Systemen.
-
Der Patient kommt zum Termin für die Bildgebung, und die Bilder oder Videos werden erstellt und an das PACS gesendet.
-
Der Radiologe liest die Bilder und kommentiert die Bilder im PACS mit einem High-End-/GPU-Grafikprogramm. Bestimmte Bildgebungssysteme verfügen über AI-gestützte Funktionen zur Effizienzsteigerung, die in die Workflows für die Bildgebung integriert sind.
-
Die Ergebnisse der Bildbestellung werden in Form eines Auftragsergebnisses HL7 ORU über das ESB an die EHR gesendet.
-
Das EHR verarbeitet die Auftragsergebnisse in den Patientendatensatz, platziert das Miniaturbild mit einem kontextgerechten Link zum tatsächlichen DICOM-Bild. Ärzte können die Diagnose-Anzeige starten, wenn ein Bild mit höherer Auflösung aus dem EHR-System benötigt wird.
-
Der Arzt überprüft das Bild und gibt Arztnotizen in die Patientenakte ein. Der Arzt könnte das klinische Entscheidungsunterstützungssystem nutzen, um den Review-Prozess zu verbessern und bei der richtigen Diagnose für den Patienten zu helfen.
-
Das EHR-System sendet dann die Auftragsergebnisse in Form einer Auftragsergebnismeldung an das Gemeinschaftskrankenhaus. Wenn das Gemeinschaftskrankenhaus das vollständige Bild erhalten konnte, wird das Bild entweder über WADO oder DICOM gesendet.
-
Der Hausarzt schließt die Diagnose ab und stellt dem Patienten weitere Schritte zur Verfügung.
Ein typisches Bildgebungssystem verwendet eine N- Tiered Architecture. Die Kernkomponente eines medizinischen Bildgebungssystems ist ein Anwendungsserver, auf dem verschiedene Anwendungskomponenten gehostet werden. Typische Anwendungsserver basieren entweder auf Java Runtime oder auf C# .Net CLR. Die meisten medizinischen Bildgebungslösungen für Unternehmen verwenden einen Oracle Database Server, MS SQL Server oder Sybase als primäre Datenbank. Darüber hinaus verwenden einige medizinische Bildgebungssysteme der Enterprise-Klasse Datenbanken auch zur Content-Beschleunigung und zum Caching über eine geografische Region. Einige medizinische Bildgebungssysteme in Unternehmen verwenden auch NoSQL Datenbanken wie MongoDB, Redis usw. in Verbindung mit Servern zur Unternehmensintegration für DICOM-Schnittstellen und oder APIs.
Ein typisches medizinisches Bildgebungssystem bietet Zugriff auf Bilder für zwei unterschiedliche Benutzer: Diagnostischer Benutzer/Radiologe oder Arzt, der die Bildgebung bestellt hat.
Radiologen nutzen normalerweise High-End-, Grafikprogramme, die auf High-End-Computing- und Grafikworkstationen ausgeführt werden, die entweder physisch oder als Teil einer virtuellen Desktop-Infrastruktur ausgeführt werden. Wenn Sie den Weg hin zu einer Virtual Desktop Infrastructure antreten möchten, finden Sie weitere Informationen "Hier".
Als der Hurrikan Katrina zwei der größten Lehrkrankenhäuser Louisianas zerstörte, kamen führende Persönlichkeiten zusammen und bauten ein stabiles elektronisches Krankenakten-System mit mehr als 3000 virtuellen Desktops in Rekordzeit auf. Weitere Informationen zur Referenzarchitektur für Anwendungsfälle und zu FlexPod Referenzpaketen finden Sie "Hier".
Klinikpersonal kann auf zwei primäre Arten auf Bilder zugreifen:
-
Webbasierter Zugriff., der in der Regel von EHR-Systemen verwendet wird, um PACS-Bilder als kontextbezogene Links in die elektronische Patientenakte (Electronic Medical Record, EMR) des Patienten zu integrieren, und Links, die in Bildgebungs-Workflows, Verfahren-Workflows, Fortschrittsnotizen-Workflows usw. platziert werden können. Über webbasierte Links können Patienten auch über Patientenportale auf Bilder zugreifen. Der webbasierte Zugriff verwendet ein Technologiemuster, das kontextbezogene Links genannt wird. Kontextbezogene Verknüpfungen können entweder statische Links/URIs mit den DICOM-Medien direkt oder dynamisch generierte Links/URIs unter Verwendung benutzerdefinierter Makros sein.
-
Thick Client. einige medizinische Systeme des Unternehmens ermöglichen es Ihnen auch, einen Thick-Client-basierten Ansatz zu verwenden, um die Bilder anzuzeigen. Sie können einen Thick Client über das EMR des Patienten oder als eigenständige Anwendung starten.
Das medizinische Bildgebungssystem kann einen Bildzugriff auf eine Ärztegemeinschaft oder an CIN-beteiligte Ärzte ermöglichen. Typische medizinische Bildgebungssysteme umfassen Komponenten, die die Interoperabilität von Bildern mit anderen IT-Systemen im Gesundheitswesen innerhalb und außerhalb Ihres Unternehmens ermöglichen. Community-Ärzte können entweder über eine webbasierte Anwendung auf Bilder zugreifen oder eine Image Exchange-Plattform für die Interoperabilität von Bildern nutzen. Bildaustauschplattformen verwenden normalerweise entweder WADO oder DICOM als zugrunde liegendes Bildaustauschprotokoll.
Medizinische Bildgebungssysteme können auch akademische medizinische Zentren unterstützen, die PACS- oder Bildgebungssysteme für den Einsatz in einem Klassenzimmer benötigen. Zur Unterstützung akademischer Aktivitäten kann ein typisches System für medizinische Bildgebung die Funktionen eines PACS-Systems in einem kleineren System oder einer nur für Lehre bestimmten Bildgebungsumgebung nutzen. Typische anbieterunabhängige Archivierungssysteme und einige medizinische Bildgebungssysteme der Enterprise-Klasse bieten Funktionen zum Morphing von DICOM-Bildern, um die für Lehrzwecke verwendeten Bilder zu anonymisieren. Durch Tag Morphing können medizinische Einrichtungen DICOM-Bilder anbieterunabhängig zwischen medizinischen Bildgebungssystemen verschiedener Anbieter austauschen. Durch Tag Morphing können medizinische Bildgebungssysteme eine unternehmensweite, anbieterneutrale Archivierungsfunktion für medizinische Bilder implementieren.
Medizinische Bildgebungssysteme werden "GPU-basierte Computing-Funktionen" allmählich zur Verbesserung menschlicher Workflows genutzt, indem sie die Bilder vorverarbeiten und so die Effizienz erhöhen. Typische medizinische Bildgebungssysteme der Enterprise-Klasse nutzen die branchenführenden NetApp Storage-Effizienzfunktionen. Medizinische Bildgebungssysteme der Enterprise-Klasse verwenden RMAN für Backup-, Recovery- und Wiederherstellungsvorgänge. Um die Performance zu verbessern und die für das Backup benötigte Zeit zu verkürzen, ist die Snapshot Technologie für Backup-Vorgänge verfügbar. Zudem ist die SnapMirror Technologie für die Replizierung verfügbar.
Die Abbildung unten zeigt die logischen Applikationskomponenten in einer vielschichtigen Architekturansicht.
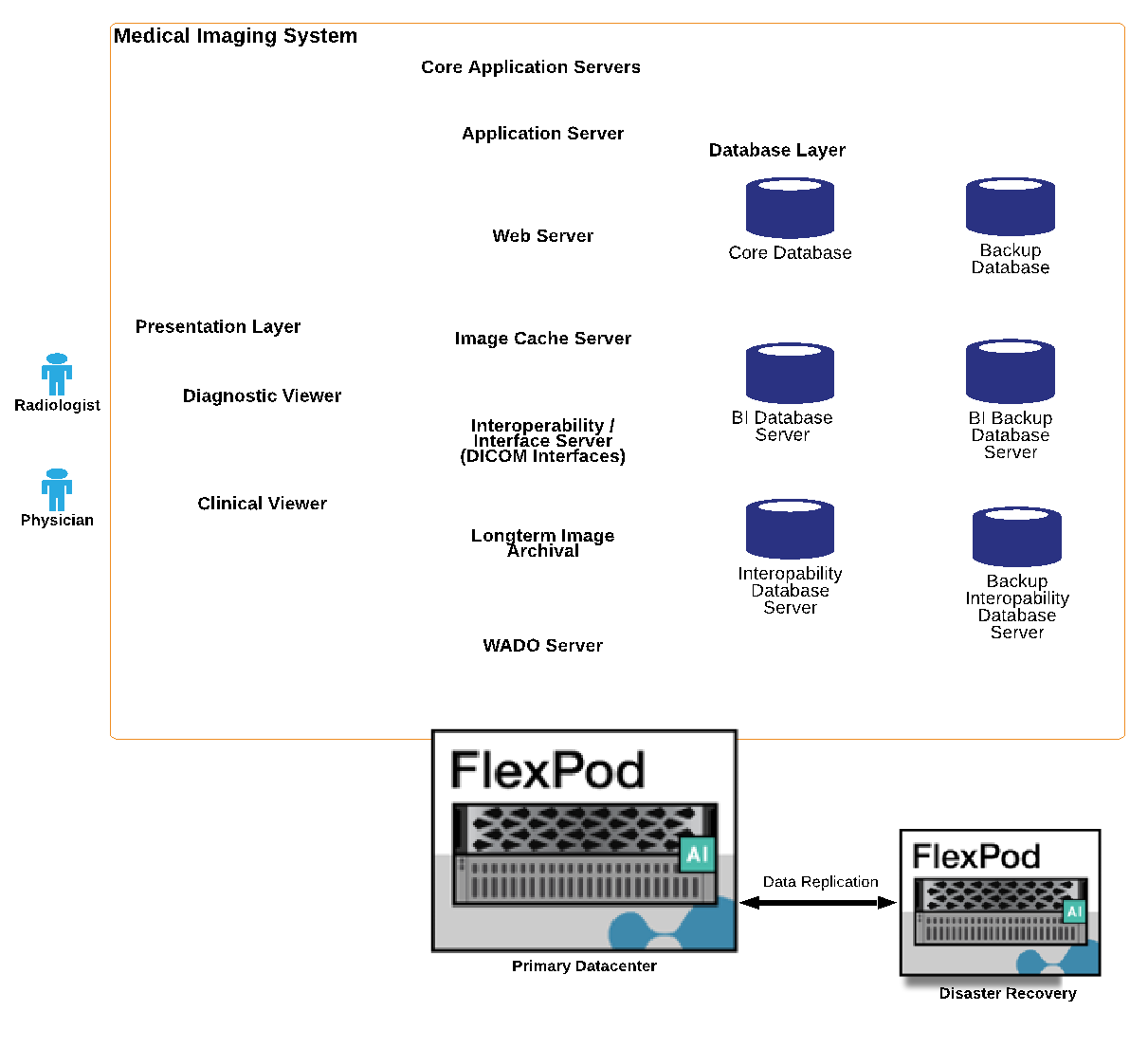
Die Abbildung unten zeigt die physischen Applikationskomponenten.
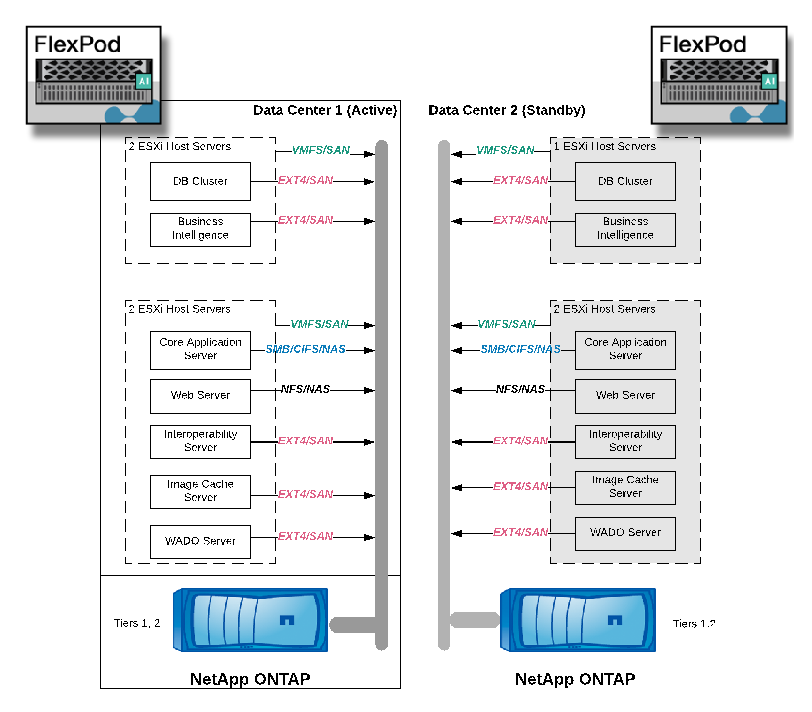
Die logischen Applikationskomponenten erfordern, dass die Infrastruktur eine Vielzahl von Protokollen und Filesystemen unterstützt. Die NetApp ONTAP Software unterstützt branchenführende Protokolle und Filesysteme.
In der folgenden Tabelle sind die Applikationskomponenten, das Storage-Protokoll und die Anforderungen an das Filesystem aufgeführt.
| Anwendungskomponente | SAN/NAS | Typ des Filesystems | Storage-Tier | Replizierungstyp |
|---|---|---|---|---|
VMware Host-Prod DB |
Vor Ort |
San |
VMFS |
Tier 1 |
Applikation |
VMware Host-Prod DB |
REP |
San |
VMFS |
Tier 1 |
Applikation |
VMware Host-Prod-Applikation |
Vor Ort |
San |
VMFS |
Tier 1 |
Applikation |
VMware Host-Prod-Applikation |
REP |
San |
VMFS |
Tier 1 |
Applikation |
Hauptdatenbankserver |
San |
Ext4 |
Tier 1 |
Applikation |
Backup-Datenbankserver |
San |
Ext4 |
Tier 1 |
Keine |
Image-Cache-Server |
NAS |
SMB/CIFS |
Tier 1 |
Keine |
Archiv-Server |
NAS |
SMB/CIFS |
Ebene 2 |
Applikation |
Web-Server |
NAS |
SMB/CIFS |
Tier 1 |
Keine |
WADO Server |
San |
NFS |
Tier 1 |
Applikation |
Business Intelligence Server |
San |
NTFS |
Tier 1 |
Applikation |
Business Intelligence Backup |
San |
NTFS |
Tier 1 |
Applikation |
Interoperabilitäts-Server |
San |
Ext4 |
Tier 1 |
Applikation |
Interoperabilitäts-Datenbankserver |