

 Notas de la versión de MetroCluster
Notas de la versión de MetroCluster
Actualización de controladoras en una configuración IP de MetroCluster mediante conmutación de sitios y conmutación de estado (ONTAP 9.8 y versiones posteriores)
 Sugerir cambios
Sugerir cambios
A partir de ONTAP 9.8, puede utilizar la operación de conmutación de sitios de MetroCluster para ofrecer servicios no disruptivos a los clientes mientras se actualizan los módulos de controladoras del clúster de partners. Como parte de este procedimiento, no se pueden actualizar otros componentes (como bandejas de almacenamiento o switches).
Plataformas compatibles con este procedimiento
-
Las plataformas deben ejecutar ONTAP 9.8 o una versión posterior.
-
La plataforma de destino (nueva) debe ser un modelo diferente al de la plataforma original.
-
No se admiten los modelos de plataforma con bandejas internas.
-
Solo puede actualizar modelos de plataforma específicos mediante este procedimiento en una configuración IP de MetroCluster.
-
Para obtener información acerca de las combinaciones de actualización de plataforma compatibles, consulte la tabla de actualización IP de MetroCluster en "Elija un procedimiento de actualización de la controladora".
Consulte "Seleccione un método de actualización o actualización" para procedimientos adicionales.
-
Acerca de esta tarea
-
Este procedimiento se aplica a los módulos de la controladora en una configuración de IP de MetroCluster.
-
Todas las controladoras de la configuración deben actualizarse durante el mismo período de mantenimiento.
No se puede utilizar la configuración MetroCluster con diferentes tipos de controladoras fuera de esta actividad de mantenimiento.
-
Los switches IP deben ejecutar una versión de firmware compatible.
-
Si la plataforma nueva tiene menos ranuras que el sistema original, o si tiene menos puertos o diferentes tipos, puede que necesite agregar un adaptador al nuevo sistema.
Para obtener más información, consulte "Hardware Universe de NetApp".
-
Si está activado en el sistema, "Deshabilite el cifrado integral" antes de realizar la actualización de la controladora.
-
Reutilizará las direcciones IP, las máscaras de red y las puertas de enlace de las plataformas originales en las nuevas plataformas.
-
En este procedimiento se utilizan los nombres de ejemplo siguientes:
-
Sitio_a
-
Antes de la actualización:
-
Node_a_1-old
-
Node_A_2-old
-
-
Después de la actualización:
-
Node_A_1-new
-
Node_A_2-New
-
-
-
Centro_B
-
Antes de la actualización:
-
Node_B_1-old
-
Node_B_2-old
-
-
Después de la actualización:
-
Node_B_1-New
-
Node_B_2-New
-
-
-
Flujo de trabajo para actualizar controladoras en una configuración de IP de MetroCluster
Puede usar el diagrama de flujo de trabajo como ayuda para planificar las tareas de actualización.
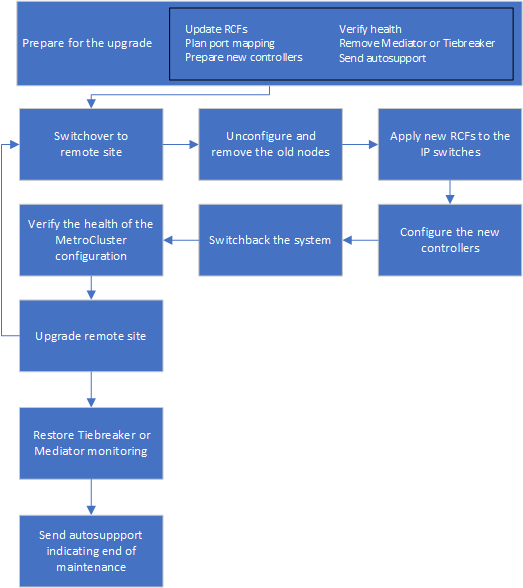
Preparando la actualización
Antes de realizar cambios en la configuración existente de MetroCluster, debe comprobar el estado de la configuración, preparar las nuevas plataformas y realizar otras tareas diversas.
Actualizar los archivos RCF del switch MetroCluster antes de actualizar las controladoras
Dependiendo de los modelos de plataforma antiguos, o si la configuración del switch no está en la versión mínima, o si desea cambiar los identificadores de VLAN utilizados por las conexiones MetroCluster back-end, debe actualizar los archivos RCF del switch antes de iniciar el procedimiento de actualización de la plataforma.
Debe actualizar el archivo RCF en las siguientes situaciones:
-
Para determinados modelos de plataforma, los switches deben utilizar un identificador de VLAN compatible para las conexiones IP de MetroCluster back-end. Si los modelos de plataforma nuevos o antiguos se encuentran en la siguiente tabla, y no utilizando un identificador de VLAN admitido, deberá actualizar los archivos RCF del conmutador.

Las conexiones de clúster local pueden utilizar cualquier VLAN; no es necesario que estén en el rango determinado. Modelo de plataforma (antiguo o nuevo)
ID de VLAN compatibles
-
AFF A400
-
10
-
20
-
Cualquier valor en el rango 101 a 4096 inclusive.
-
-
La configuración del conmutador no se configuró con la versión RCF mínima admitida:
Modelo de switch
Versión de archivo RCF necesaria
Cisco 3132Q-V
1.7 o posterior
Cisco 3232C
1.7 o posterior
Broadcom BES-53248
1.3 o posterior
-
Desea cambiar la configuración de VLAN.
El intervalo del ID de VLAN es de 101 a 4096 incluido.
Los switches de Site_A se actualizarán cuando se actualicen las controladoras de Site_A.
-
Prepare los switches IP para la aplicación de los nuevos archivos RCF.
Siga los pasos de la sección correspondiente a su proveedor de switches desde el "Instalación y configuración de IP de MetroCluster".
-
Descargue e instale los archivos RCF.
Siga los pasos de la "Instalación y configuración de IP de MetroCluster".
Asignando los puertos de los nodos antiguos a los nodos nuevos
Debe verificar que los puertos físicos de node_A_1-old se asignan correctamente a los puertos físicos en node_A_1-new, que permitirá que node_A_1-new se comunique con otros nodos del clúster y con la red después de la actualización.
Cuando el nuevo nodo se arranque por primera vez durante el proceso de actualización, reproducirá la configuración más reciente del nodo antiguo al que desea sustituir. Cuando arranca node_A_1-new, ONTAP intenta alojar LIF en los mismos puertos que se usaron en el node_A_1-old. Por lo tanto, como parte de la actualización debe ajustar la configuración de puerto y LIF para que sea compatible con la del nodo antiguo. Durante el procedimiento de actualización, deberá realizar los pasos tanto en los nodos antiguos como en los nuevos para garantizar que la configuración correcta de LIF de datos, gestión y clúster.
En la siguiente tabla se muestran ejemplos de cambios de configuración relacionados con los requisitos de puerto de los nuevos nodos.
Puertos físicos de Cluster Interconnect |
||
La controladora anterior |
Nueva controladora |
Acción requerida |
e0a y e0b |
e3a, e3b |
No hay puerto que coincida. Después de la actualización, debe volver a crear los puertos del clúster. |
e0c, e0d |
e0a, e0b, e0c y e0d |
los puertos e0c y e0d son coincidentes. No tiene que cambiar la configuración, pero tras la actualización puede propagar las LIF del clúster a través de los puertos de clúster disponibles. |
-
Determine qué puertos físicos están disponibles en las nuevas controladoras y qué LIF se pueden alojar en los puertos.
El uso del puerto de la controladora depende del módulo de la plataforma y de los switches que se usarán en la configuración IP de MetroCluster. Puede recopilar el uso del puerto de las nuevas plataformas desde la "Hardware Universe de NetApp".
-
Planifique el uso de su puerto y rellene las siguientes tablas como referencia para cada uno de los nodos nuevos.
Consulte la tabla a medida que lleve a cabo el procedimiento de actualización.
Node_a_1-old
Node_A_1-new
LUN
Puertos
Espacios IP
Dominios de retransmisión
Puertos
Espacios IP
Dominios de retransmisión
Clúster 1
Clúster 2
Clúster 3
Clúster 4
Gestión de nodos
Gestión de clústeres
Datos 1
Datos 2
Datos 3
Datos 4
SAN
Puerto de interconexión de clústeres
Netarrancando los nuevos controladores
Después de instalar los nodos nuevos, debe reiniciar el sistema para asegurarse de que los nuevos nodos estén ejecutando la misma versión de ONTAP que los nodos originales. El término arranque desde red significa que se arranca desde una imagen ONTAP almacenada en un servidor remoto. Al prepararse para reiniciar el sistema, debe colocar una copia de la imagen de arranque ONTAP 9 en un servidor web al que pueda acceder el sistema.
-
Reiniciar el sistema de las nuevas controladoras:
-
Acceda a "Sitio de soporte de NetApp" para descargar los archivos utilizados para realizar el arranque desde red del sistema.
-
Descargue el software ONTAP adecuado de la sección de descarga de software del sitio de soporte de NetApp y almacene el
ontap-version_image.tgzarchivo en un directorio accesible a través de la web. -
Cambie al directorio accesible a la Web y compruebe que los archivos que necesita están disponibles.
Si el modelo de plataforma…
Realice lo siguiente…
sistemas de la serie 8000
Extraiga el contenido del
ontap-version_image.tgzarchivo al directorio de destino:tar -zxvf ontap-version_image.tgz
Si va a extraer el contenido en Windows, utilice 7-Zip o WinRAR para extraer la imagen netboot. El listado de directorios debe contener una carpeta para reiniciar el sistema con un archivo de kernel:netboot/kernel El listado de directorios debe contener una carpeta netboot con un archivo de kernel:
netboot/kernelTodos los demás sistemas
El listado de directorios debe contener una carpeta netboot con un archivo de kernel:
_ontap-version_image.tgzUsted no necesita extraer el
_ontap-version_image.tgzarchivo. -
En el símbolo del sistema del CARGADOR, configure la conexión para reiniciar el sistema para una LIF de gestión:
Si el direccionamiento IP es…
Realice lo siguiente…
DHCP
Configure la conexión automática:
ifconfig e0M -autoEstático
Configure la conexión manual:
ifconfig e0M -addr=ip_addr -mask=netmask -gw=gateway -
Reiniciar el sistema.
Si el modelo de plataforma…
Realice lo siguiente…
Sistemas de la serie FAS/AFF8000
netboot http://web_server_ip/path_to_web-accessible_directory/netboot/kernelTodos los demás sistemas
netboot http://_web_server_ip/path_to_web-accessible_directory/ontap-version_image.tgz -
En el menú de inicio, seleccione la opción (7) instale primero el nuevo software para descargar e instalar la nueva imagen de software en el dispositivo de arranque.
Ignore el siguiente mensaje:
"This procedure is not supported for Non-Disruptive Upgrade on an HA pair". Se aplica a las actualizaciones no disruptivas del software, no a las actualizaciones de controladoras.-
Si se le solicita que continúe el procedimiento, introduzca `y`Y cuando se le solicite el paquete, escriba la dirección URL del archivo de imagen:
http://web_server_ip/path_to_web-accessible_directory/ontap-version_image.tgz -
Introduzca el nombre de usuario y la contraseña, si procede, o pulse Intro para continuar.
-
No olvide entrar
npara omitir la recuperación de backup cuando observe un símbolo del sistema similar a lo siguiente:Do you want to restore the backup configuration now? {y|n} **n** -
Reinicie introduciendo
ycuando vea un símbolo del sistema similar a lo siguiente:The node must be rebooted to start using the newly installed software. Do you want to reboot now? {y|n}
-
Borrar la configuración en un módulo del controlador
Antes de utilizar un nuevo módulo de controladora en la configuración de MetroCluster, debe borrar la configuración existente.
-
Si es necesario, detenga el nodo para mostrar el símbolo del sistema del CARGADOR:
halt -
En el símbolo del sistema del CARGADOR, establezca las variables de entorno en los valores predeterminados:
set-defaults -
Guarde el entorno:
saveenv -
En el símbolo del sistema del CARGADOR, inicie el menú de arranque:
boot_ontap menu -
En el símbolo del sistema del menú de inicio, borre la configuración:
wipeconfigResponda
yesa la solicitud de confirmación.El nodo se reinicia y el menú de arranque se muestra de nuevo.
-
En el menú de inicio, seleccione la opción 5 para arrancar el sistema en modo de mantenimiento.
Responda
yesa la solicitud de confirmación.
Verificación del estado de MetroCluster antes de la actualización del sitio
Debe verificar el estado y la conectividad de la configuración de MetroCluster antes de realizar la actualización.
-
Compruebe el funcionamiento de la configuración de MetroCluster en ONTAP:
-
Compruebe si los nodos son multipathed:
node run -node node-name sysconfig -aDebe emitir este comando para cada nodo en la configuración de MetroCluster.
-
Verificar que no hay discos rotos en la configuración:
storage disk show -brokenDebe emitir este comando en cada nodo de la configuración de MetroCluster.
-
Compruebe cualquier alerta de estado:
system health alert showDebe emitir este comando en cada clúster.
-
Verifique las licencias en los clústeres:
system license showDebe emitir este comando en cada clúster.
-
Compruebe los dispositivos conectados a los nodos:
network device-discovery showDebe emitir este comando en cada clúster.
-
Compruebe que la zona horaria y la hora están configuradas correctamente en ambos sitios:
cluster date show
Debe emitir este comando en cada clúster. Puede utilizar el
cluster datepara configurar la hora y la zona horaria. -
-
Confirmar el modo operativo de la configuración de MetroCluster y realizar una comprobación de MetroCluster.
-
Confirme la configuración del MetroCluster y que el modo operativo es
normal:
metrocluster show -
Confirme que se muestran todos los nodos esperados:
metrocluster node show -
Emita el siguiente comando:
metrocluster check run -
Mostrar los resultados de la comprobación de MetroCluster:
metrocluster check show
-
-
Compruebe el cableado MetroCluster con la herramienta Config Advisor.
-
Descargue y ejecute Config Advisor.
-
Después de ejecutar Config Advisor, revise el resultado de la herramienta y siga las recomendaciones del resultado para solucionar los problemas detectados.
-
Obteniendo información antes de la actualización
Antes de la actualización, debe recopilar información para cada uno de los nodos y, si fuera necesario, ajustar los dominios de retransmisión de red, quitar las VLAN y los grupos de interfaces, y recopilar información sobre el cifrado.
-
Registre el cableado físico de cada nodo y etiquetando los cables según sea necesario para permitir el cableado correcto de los nuevos nodos.
-
Recopile información sobre las interconexiones, los puertos y las LIF de cada nodo.
Debe recopilar el resultado de los siguientes comandos para cada nodo:
-
metrocluster interconnect show -
metrocluster configuration-settings connection show -
network interface show -role cluster,node-mgmt -
network port show -node node_name -type physical -
network port vlan show -node node-name -
network port ifgrp show -node node_name -instance -
network port broadcast-domain show -
network port reachability show -detail -
network ipspace show -
volume show -
storage aggregate show -
system node run -node node-name sysconfig -a -
vserver fcp initiator show -
storage disk show -
metrocluster configuration-settings interface show
-
-
Recopile los UUID para el sitio_B (el sitio cuyas plataformas se están actualizando actualmente):
metrocluster node show -fields node-cluster-uuid, node-uuidEstos valores deben configurarse con precisión en los nuevos módulos del controlador Site_B para garantizar que la actualización se realice correctamente. Copie los valores en un archivo para poder copiarlos en los comandos adecuados más adelante en el proceso de actualización.
En el ejemplo siguiente se muestra la salida del comando con los UUID:
cluster_B::> metrocluster node show -fields node-cluster-uuid, node-uuid (metrocluster node show) dr-group-id cluster node node-uuid node-cluster-uuid ----------- --------- -------- ------------------------------------ ------------------------------ 1 cluster_A node_A_1 f03cb63c-9a7e-11e7-b68b-00a098908039 ee7db9d5-9a82-11e7-b68b-00a098908039 1 cluster_A node_A_2 aa9a7a7a-9a81-11e7-a4e9-00a098908c35 ee7db9d5-9a82-11e7-b68b-00a098908039 1 cluster_B node_B_1 f37b240b-9ac1-11e7-9b42-00a098c9e55d 07958819-9ac6-11e7-9b42-00a098c9e55d 1 cluster_B node_B_2 bf8e3f8f-9ac4-11e7-bd4e-00a098ca379f 07958819-9ac6-11e7-9b42-00a098c9e55d 4 entries were displayed. cluster_B::*
Es recomendable que registre los UUID en una tabla similar a la siguiente.
Clúster o nodo
UUID
Cluster_B
07958819-9ac6-11e7-9b42-00a098c9e55d
Node_B_1
f37b240b-9ac1-11e7-9b42-00a098c9e55d
Node_B_2
bf8e3f8f-9ac4-11e7-bd4e-00a098ca379f
Cluster_a
ee7db9d5-9a82-11e7-b68b-00a098908039
Node_a_1
f03cb63c-9a7e-11e7-b68b-00a098908039
Node_A_2
aa9a7a7a-9a81-11e7-a4e9-00a098908c35
-
Si los nodos MetroCluster tienen una configuración SAN, recopile la información pertinente.
Debe recopilar el resultado de los siguientes comandos:
-
fcp adapter show -instance -
fcp interface show -instance -
iscsi interface show -
ucadmin show
-
-
Si el volumen raíz está cifrado, recopile y guarde la clave de acceso usada para Key-Manager:
security key-manager backup show -
Si los nodos de MetroCluster utilizan el cifrado de volúmenes o agregados, copie información sobre las claves y las Passphrases.
Para obtener más información, consulte "Realizar un backup manual de la información de gestión de claves incorporada".
-
Si el gestor de claves incorporado está configurado:
security key-manager onboard show-backupNecesitará la contraseña más adelante en el procedimiento de actualización.
-
Si está configurada la gestión de claves empresariales (KMIP), ejecute los siguientes comandos:
security key-manager external show -instancesecurity key-manager key query
-
-
Recopile los ID del sistema de los nodos existentes:
metrocluster node show -fields node-systemid,ha-partner-systemid,dr-partner-systemid,dr-auxiliary-systemidLa siguiente salida muestra las unidades reasignadas.
::> metrocluster node show -fields node-systemid,ha-partner-systemid,dr-partner-systemid,dr-auxiliary-systemid dr-group-id cluster node node-systemid ha-partner-systemid dr-partner-systemid dr-auxiliary-systemid ----------- ----------- -------- ------------- ------------------- ------------------- --------------------- 1 cluster_A node_A_1 537403324 537403323 537403321 537403322 1 cluster_A node_A_2 537403323 537403324 537403322 537403321 1 cluster_B node_B_1 537403322 537403321 537403323 537403324 1 cluster_B node_B_2 537403321 537403322 537403324 537403323 4 entries were displayed.
Eliminación de la monitorización de Mediator o tiebreaker
Antes de actualizar las plataformas, debe eliminar la supervisión si la configuración de MetroCluster se supervisa con tiebreaker o la utilidad Mediator.
-
Recopile el resultado del siguiente comando:
storage iscsi-initiator show -
Elimine la configuración de MetroCluster existente de tiebreaker, Mediator u otro software que pueda iniciar la conmutación.
Si está usando…
Utilice este procedimiento…
Tiebreaker
Mediador
Ejecute el siguiente comando desde el símbolo del sistema de ONTAP:
metrocluster configuration-settings mediator removeAplicaciones de terceros
Consulte la documentación del producto.
Envío de un mensaje de AutoSupport personalizado antes del mantenimiento
Antes de realizar el mantenimiento, debe emitir un mensaje de AutoSupport para notificar al soporte técnico de NetApp que se está realizando el mantenimiento. Al informar al soporte técnico de que el mantenimiento está en marcha, se evita que abran un caso basándose en que se ha producido una interrupción.
Esta tarea debe realizarse en cada sitio MetroCluster.
-
Inicie sesión en el clúster.
-
Invoque un mensaje de AutoSupport que indique el inicio del mantenimiento:
system node autosupport invoke -node * -type all -message MAINT=maintenance-window-in-hoursLa
maintenance-window-in-hoursel parámetro especifica la longitud de la ventana de mantenimiento, con un máximo de 72 horas. Si el mantenimiento se completa antes de que haya transcurrido el tiempo, puede invocar un mensaje de AutoSupport que indique el final del período de mantenimiento:system node autosupport invoke -node * -type all -message MAINT=end -
Repita estos pasos en el sitio para partners.
Cambiar de la configuración de MetroCluster
Debe cambiar la configuración a site_A para que las plataformas en site_B puedan actualizarse.
Esta tarea debe realizarse en site_A.
Tras completar esta tarea, Cluster_A está activo y está sirviendo datos para ambos sitios. Cluster_B está inactivo y está listo para comenzar el proceso de actualización.
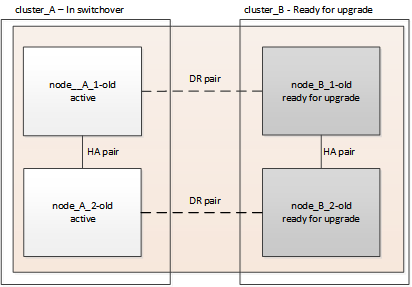
-
Cambie de la configuración de MetroCluster a site_A para que los nodos de site_B puedan actualizarse:
-
Emita el siguiente comando en cluster_A:
metrocluster switchover -controller-replacement trueLa operación puede tardar varios minutos en completarse.
-
Supervise la operación de switchover:
metrocluster operation show -
Una vez finalizada la operación, confirme que los nodos están en estado de conmutación:
metrocluster show -
Compruebe el estado de los nodos de MetroCluster:
metrocluster node show
Reparación automática de los agregados después de deshabilitar la conmutación negociada durante la actualización de la controladora.
-
Eliminar las configuraciones de la interfaz y desinstalar las controladoras antiguas
Debe mover las LIF de datos a un puerto común, quitar las VLAN y los grupos de interfaces de las controladoras anteriores y, a continuación, desinstalar físicamente las controladoras.
-
Estos pasos se realizan en las controladoras antiguas (node_B_1-old, node_B_2-old).
-
Vea la información recopilada en "Asignando los puertos de los nodos antiguos a los nodos nuevos".
-
Arranque los nodos antiguos e inicie sesión en los nodos:
boot_ontap -
Asigne el puerto de inicio de todos los LIF de datos de la controladora anterior a un puerto común que sea el mismo en los módulos de controladora nuevos y antiguos.
-
Mostrar las LIF:
network interface showTodos los LIF de datos, incluidos SAN y NAS, estarán admin arriba y operativamente inactivos ya que estos están en el sitio de conmutación (cluster_A).
-
Revise el resultado para encontrar un puerto de red física común que sea el mismo en las controladoras anterior y nueva que no se use como puerto de clúster.
Por ejemplo, e0d es un puerto físico de las controladoras antiguas y también está presente en las nuevas controladoras. e0d no se utiliza como puerto de clúster ni de otro modo en las nuevas controladoras.
Para el uso de puertos para los modelos de plataforma, consulte "Hardware Universe de NetApp"
-
Modifique todas las LIF de datos para utilizar el puerto común como puerto de inicio:
network interface modify -vserver svm-name -lif data-lif -home-port port-idEn el siguiente ejemplo, es «e0d».
Por ejemplo:
network interface modify -vserver vs0 -lif datalif1 -home-port e0d
-
-
Quite todos los puertos VLAN que utilicen puertos de clúster como puertos miembro e ifgrps usando puertos de clúster como puertos miembro.
-
Eliminar puertos VLAN:
network port vlan delete -node node-name -vlan-name portid-vlandidPor ejemplo:
network port vlan delete -node node1 -vlan-name e1c-80
-
Quite puertos físicos de los grupos de interfaces:
network port ifgrp remove-port -node node-name -ifgrp interface-group-name -port portidPor ejemplo:
network port ifgrp remove-port -node node1 -ifgrp a1a -port e0d
-
Quite puertos VLAN y de grupo de interfaces del dominio de retransmisión:
network port broadcast-domain remove-ports -ipspace ipspace -broadcast-domain broadcast-domain-name -ports nodename:portname,nodename:portname,.. -
Modifique los puertos del grupo de interfaces para utilizar otros puertos físicos como miembro según sea necesario.:
ifgrp add-port -node node-name -ifgrp interface-group-name -port port-id
-
-
Detenga los nodos del símbolo del sistema del CARGADOR:
halt -inhibit-takeover true -
Conéctese a la consola de serie de las controladoras antiguas (node_B_1-old y node_B_2-old) en Site_B y compruebe que muestra el aviso DEL CARGADOR.
-
Recopile los valores bootarg:
printenv -
Desconecte las conexiones de almacenamiento y red de node_B_1-old y node_B_2-old y etiquete los cables para que puedan volver a conectarse a los nodos nuevos.
-
Desconecte los cables de alimentación de node_B_1-old y node_B_2-old.
-
Quite las controladoras node_B_1-old y node_B_2-old del rack.
Actualización de los RCF de switch para acomodar las nuevas plataformas
Debe actualizar los switches a una configuración que admita los nuevos modelos de plataforma.
Esta tarea debe realizarse en el sitio que contiene las controladoras que se están actualizando. En los ejemplos mostrados en este procedimiento, estamos actualizando site_B primero.
Los switches de Site_A se actualizarán cuando se actualicen las controladoras de Site_A.
-
Prepare los switches IP para la aplicación de los nuevos archivos RCF.
Siga los pasos del procedimiento para su proveedor de switches:
-
Descargue e instale los archivos RCF.
Siga los pasos de la sección correspondiente a su proveedor de switches desde el "Instalación y configuración de IP de MetroCluster".
Configurar las nuevas controladoras
Debe montar en rack e instalar las controladoras, realizar la configuración necesaria en modo de mantenimiento y, a continuación, arrancar las controladoras y comprobar la configuración de LIF en las controladoras.
Configurar las nuevas controladoras
Debe montar en rack y cablear las nuevas controladoras.
-
Planifique la colocación de los nuevos módulos de controladora y bandejas de almacenamiento según sea necesario.
El espacio en rack depende del modelo de plataforma de los módulos de la controladora, los tipos de switch y el número de bandejas de almacenamiento de la configuración.
-
Puesta a tierra apropiadamente usted mismo.
-
Instale los módulos de la controladora en el rack o armario.
-
Conecte los cables de las controladoras a los switches IP como se describe en "Instalación y configuración de IP de MetroCluster".
-
Encienda los nodos nuevos y arranque en modo de mantenimiento.
Restaurar la configuración de HBA
Dependiendo de la presencia y configuración de tarjetas HBA en el módulo de controlador, debe configurarlas correctamente para el uso de su sitio.
-
En el modo de mantenimiento configure los ajustes para cualquier HBA del sistema:
-
Compruebe la configuración actual de los puertos:
ucadmin show -
Actualice la configuración del puerto según sea necesario.
Si tiene este tipo de HBA y el modo que desea…
Se usa este comando…
CNA FC
ucadmin modify -m fc -t initiator adapter-nameEthernet de CNA
ucadmin modify -mode cna adapter-nameDestino FC
fcadmin config -t target adapter-nameIniciador FC
fcadmin config -t initiator adapter-name -
-
Salir del modo de mantenimiento:
haltDespués de ejecutar el comando, espere hasta que el nodo se detenga en el símbolo del sistema DEL CARGADOR.
-
Vuelva a arrancar el nodo en modo de mantenimiento para permitir que los cambios de configuración surtan efecto:
boot_ontap maint -
Compruebe los cambios realizados:
Si tiene este tipo de HBA…
Se usa este comando…
CNA
ucadmin showFC
fcadmin show
Configurar el estado de alta disponibilidad en las nuevas controladoras y el chasis
Debe comprobar el estado de alta disponibilidad de las controladoras y el chasis y, si es necesario, actualizar el estado para que coincida con la configuración del sistema.
-
En el modo de mantenimiento, muestre el estado de alta disponibilidad del módulo de controladora y el chasis:
ha-config showEl estado ha de todos los componentes debería ser «mccip».
-
Si el estado del sistema mostrado de la controladora o el chasis no es correcto, establezca el estado de alta disponibilidad:
ha-config modify controller mccipha-config modify chassis mccip
Configuración de las variables bootarg IP de MetroCluster
Ciertos valores de arranque IP de MetroCluster deben configurarse en los nuevos módulos de la controladora. Los valores deben coincidir con los configurados en los módulos de la controladora anteriores.
En esta tarea, utilizará los UUID y los identificadores del sistema identificados anteriormente en el procedimiento de actualización en "Obteniendo información antes de la actualización".
-
Si los nodos que se van a actualizar son modelos AFF A400, FAS8300 o FAS8700, establezca los siguientes bootargs en el símbolo del sistema del CARGADOR:
setenv bootarg.mcc.port_a_ip_config local-IP-address/local-IP-mask,0,HA-partner-IP-address,DR-partner-IP-address,DR-aux-partnerIP-address,vlan-idsetenv bootarg.mcc.port_b_ip_config local-IP-address/local-IP-mask,0,HA-partner-IP-address,DR-partner-IP-address,DR-aux-partnerIP-address,vlan-id
Si las interfaces utilizan las VLAN predeterminadas, no es necesario disponer de la VLAN-id. Los siguientes comandos establecen los valores de node_B_1-new mediante VLAN 120 para la primera red y VLAN 130 para la segunda red:
setenv bootarg.mcc.port_a_ip_config 172.17.26.10/23,0,172.17.26.11,172.17.26.13,172.17.26.12,120 setenv bootarg.mcc.port_b_ip_config 172.17.27.10/23,0,172.17.27.11,172.17.27.13,172.17.27.12,130
Los siguientes comandos establecen los valores de node_B_2-new mediante VLAN 120 para la primera red y VLAN 130 para la segunda red:
setenv bootarg.mcc.port_a_ip_config 172.17.26.11/23,0,172.17.26.10,172.17.26.12,172.17.26.13,120 setenv bootarg.mcc.port_b_ip_config 172.17.27.11/23,0,172.17.27.10,172.17.27.12,172.17.27.13,130
En el siguiente ejemplo, se muestran los comandos node_B_1-new cuando se utiliza la VLAN predeterminada:
setenv bootarg.mcc.port_a_ip_config 172.17.26.10/23,0,172.17.26.11,172.17.26.13,172.17.26.12 setenv bootarg.mcc.port_b_ip_config 172.17.27.10/23,0,172.17.27.11,172.17.27.13,172.17.27.12
En el siguiente ejemplo, se muestran los comandos node_B_2-new cuando se utiliza la VLAN predeterminada:
setenv bootarg.mcc.port_a_ip_config 172.17.26.11/23,0,172.17.26.10,172.17.26.12,172.17.26.13 setenv bootarg.mcc.port_b_ip_config 172.17.27.11/23,0,172.17.27.10,172.17.27.12,172.17.27.13
-
Si los nodos que se van a actualizar no son sistemas enumerados en el paso anterior, en el símbolo del sistema DEL CARGADOR para cada uno de los nodos supervivientes, defina los siguientes bootargs con local_IP/mask:
setenv bootarg.mcc.port_a_ip_config local-IP-address/local-IP-mask,0,HA-partner-IP-address,DR-partner-IP-address,DR-aux-partnerIP-addresssetenv bootarg.mcc.port_b_ip_config local-IP-address/local-IP-mask,0,HA-partner-IP-address,DR-partner-IP-address,DR-aux-partnerIP-addressLos siguientes comandos establecen los valores de node_B_1-new:
setenv bootarg.mcc.port_a_ip_config 172.17.26.10/23,0,172.17.26.11,172.17.26.13,172.17.26.12 setenv bootarg.mcc.port_b_ip_config 172.17.27.10/23,0,172.17.27.11,172.17.27.13,172.17.27.12
Los siguientes comandos establecen los valores de node_B_2-new:
setenv bootarg.mcc.port_a_ip_config 172.17.26.11/23,0,172.17.26.10,172.17.26.12,172.17.26.13 setenv bootarg.mcc.port_b_ip_config 172.17.27.11/23,0,172.17.27.10,172.17.27.12,172.17.27.13
-
En el símbolo del sistema DEL CARGADOR de nodos nuevos, establezca los UUID:
setenv bootarg.mgwd.partner_cluster_uuid partner-cluster-UUIDsetenv bootarg.mgwd.cluster_uuid local-cluster-UUIDsetenv bootarg.mcc.pri_partner_uuid DR-partner-node-UUIDsetenv bootarg.mcc.aux_partner_uuid DR-aux-partner-node-UUIDsetenv bootarg.mcc_iscsi.node_uuid local-node-UUID-
Establezca los UUID en node_B_1-new.
En el ejemplo siguiente se muestran los comandos para configurar los UUID en node_B_1-new:
setenv bootarg.mgwd.cluster_uuid ee7db9d5-9a82-11e7-b68b-00a098908039 setenv bootarg.mgwd.partner_cluster_uuid 07958819-9ac6-11e7-9b42-00a098c9e55d setenv bootarg.mcc.pri_partner_uuid f37b240b-9ac1-11e7-9b42-00a098c9e55d setenv bootarg.mcc.aux_partner_uuid bf8e3f8f-9ac4-11e7-bd4e-00a098ca379f setenv bootarg.mcc_iscsi.node_uuid f03cb63c-9a7e-11e7-b68b-00a098908039
-
Establezca los UUID en node_B_2-new:
En el ejemplo siguiente se muestran los comandos para configurar los UUID en node_B_2-new:
setenv bootarg.mgwd.cluster_uuid ee7db9d5-9a82-11e7-b68b-00a098908039 setenv bootarg.mgwd.partner_cluster_uuid 07958819-9ac6-11e7-9b42-00a098c9e55d setenv bootarg.mcc.pri_partner_uuid bf8e3f8f-9ac4-11e7-bd4e-00a098ca379f setenv bootarg.mcc.aux_partner_uuid f37b240b-9ac1-11e7-9b42-00a098c9e55d setenv bootarg.mcc_iscsi.node_uuid aa9a7a7a-9a81-11e7-a4e9-00a098908c35
-
-
Si los sistemas originales estaban configurados para ADP, en cada solicitud DEL CARGADOR de los nodos de sustitución, habilite ADP:
setenv bootarg.mcc.adp_enabled true -
Configure las siguientes variables:
setenv bootarg.mcc.local_config_id original-sys-idsetenv bootarg.mcc.dr_partner dr-partner-sys-id
La setenv bootarg.mcc.local_config_idLa variable se debe establecer en sys-id del módulo de controlador original, node_B_1-old.-
Establezca las variables en node_B_1-new.
En el ejemplo siguiente se muestran los comandos para configurar los valores en node_B_1-new:
setenv bootarg.mcc.local_config_id 537403322 setenv bootarg.mcc.dr_partner 537403324
-
Establezca las variables en node_B_2-new.
En el ejemplo siguiente se muestran los comandos para configurar los valores en node_B_2-new:
setenv bootarg.mcc.local_config_id 537403321 setenv bootarg.mcc.dr_partner 537403323
-
-
Si utiliza cifrado con gestor de claves externo, defina los bootargs necesarios:
setenv bootarg.kmip.init.ipaddrsetenv bootarg.kmip.kmip.init.netmasksetenv bootarg.kmip.kmip.init.gatewaysetenv bootarg.kmip.kmip.init.interface
Reasignar discos de agregado raíz
Reasigne los discos del agregado raíz al nuevo módulo de la controladora mediante los sides recogidos anteriormente.
Estos pasos se realizan en modo de mantenimiento.
|
|
Los discos de agregado raíz son los únicos discos que se deben volver a asignar durante el proceso de actualización de la controladora. La propiedad de disco de los agregados de datos se trata como parte de la operación de conmutación de sitios/conmutación de estado. |
-
Arranque el sistema en modo de mantenimiento:
boot_ontap maint -
Muestre los discos en node_B_1-new en la indicación Maintenance mode:
disk show -aEl resultado del comando muestra el ID del sistema del nuevo módulo de la controladora (1574774970). Sin embargo, los discos del agregado raíz siguen siendo propiedad del ID de sistema anterior (537403322). En este ejemplo, no se muestran las unidades que pertenecen a otros nodos en la configuración MetroCluster.
*> disk show -a Local System ID: 1574774970 DISK OWNER POOL SERIAL NUMBER HOME DR HOME ------------ --------- ----- ------------- ------------- ------------- prod3-rk18:9.126L44 node_B_1-old(537403322) Pool1 PZHYN0MD node_B_1-old(537403322) node_B_1-old(537403322) prod4-rk18:9.126L49 node_B_1-old(537403322) Pool1 PPG3J5HA node_B_1-old(537403322) node_B_1-old(537403322) prod4-rk18:8.126L21 node_B_1-old(537403322) Pool1 PZHTDSZD node_B_1-old(537403322) node_B_1-old(537403322) prod2-rk18:8.126L2 node_B_1-old(537403322) Pool0 S0M1J2CF node_B_1-old(537403322) node_B_1-old(537403322) prod2-rk18:8.126L3 node_B_1-old(537403322) Pool0 S0M0CQM5 node_B_1-old(537403322) node_B_1-old(537403322) prod1-rk18:9.126L27 node_B_1-old(537403322) Pool0 S0M1PSDW node_B_1-old(537403322) node_B_1-old(537403322) . . .
-
Reasigne los discos de agregado raíz en las bandejas de unidades a las nuevas controladoras.
Si está utilizando ADP…
A continuación, se usa este comando…
Sí
disk reassign -s old-sysid -d new-sysid -r dr-partner-sysidNo
disk reassign -s old-sysid -d new-sysid -
Reasigne los discos de agregado raíz de las bandejas de unidades a las nuevas controladoras:
disk reassign -s old-sysid -d new-sysidEn el siguiente ejemplo, se muestra la reasignación de unidades en una configuración que no sea de ADP:
*> disk reassign -s 537403322 -d 1574774970 Partner node must not be in Takeover mode during disk reassignment from maintenance mode. Serious problems could result!! Do not proceed with reassignment if the partner is in takeover mode. Abort reassignment (y/n)? n After the node becomes operational, you must perform a takeover and giveback of the HA partner node to ensure disk reassignment is successful. Do you want to continue (y/n)? y Disk ownership will be updated on all disks previously belonging to Filer with sysid 537403322. Do you want to continue (y/n)? y
-
Compruebe que los discos del agregado raíz se han reasignado correctamente a la eliminación anterior:
disk showstorage aggr status*> disk show Local System ID: 537097247 DISK OWNER POOL SERIAL NUMBER HOME DR HOME ------------ ------------- ----- ------------- ------------- ------------- prod03-rk18:8.126L18 node_B_1-new(537097247) Pool1 PZHYN0MD node_B_1-new(537097247) node_B_1-new(537097247) prod04-rk18:9.126L49 node_B_1-new(537097247) Pool1 PPG3J5HA node_B_1-new(537097247) node_B_1-new(537097247) prod04-rk18:8.126L21 node_B_1-new(537097247) Pool1 PZHTDSZD node_B_1-new(537097247) node_B_1-new(537097247) prod02-rk18:8.126L2 node_B_1-new(537097247) Pool0 S0M1J2CF node_B_1-new(537097247) node_B_1-new(537097247) prod02-rk18:9.126L29 node_B_1-new(537097247) Pool0 S0M0CQM5 node_B_1-new(537097247) node_B_1-new(537097247) prod01-rk18:8.126L1 node_B_1-new(537097247) Pool0 S0M1PSDW node_B_1-new(537097247) node_B_1-new(537097247) ::> ::> aggr status Aggr State Status Options aggr0_node_B_1 online raid_dp, aggr root, nosnap=on, mirrored mirror_resync_priority=high(fixed) fast zeroed 64-bit
Arrancar las nuevas controladoras
Debe arrancar los nuevos controladores, teniendo cuidado de asegurarse de que las variables bootarg son correctas y, si es necesario, llevar a cabo los pasos de recuperación de cifrado.
-
Detenga los nuevos nodos:
halt -
Si se configura el gestor de claves externo, defina los bootargs relacionados:
setenv bootarg.kmip.init.ipaddr ip-addresssetenv bootarg.kmip.init.netmask netmasksetenv bootarg.kmip.init.gateway gateway-addresssetenv bootarg.kmip.init.interface interface-id -
Compruebe si la sísid del compañero es la actual:
printenv partner-sysidSi el sid del socio no es correcto, configúrelo:
setenv partner-sysid partner-sysID -
Abra el menú de inicio de ONTAP:
boot_ontap menu -
Si se utiliza el cifrado de raíz, seleccione la opción de menú de inicio para la configuración de administración de claves.
Si está usando…
Seleccione esta opción del menú de inicio…
Gestión de claves incorporada
Opción
10Siga las instrucciones para proporcionar las entradas necesarias para recuperar y restaurar la configuración de Key-Manager.
Gestión de claves externas
Opción
11Siga las instrucciones para proporcionar las entradas necesarias para recuperar y restaurar la configuración de Key-Manager.
-
En el menú de inicio, seleccione "'(6) Actualizar flash desde backup config'".
La opción 6 reiniciará el nodo dos veces antes de que finalice. Responda «'y'» a los mensajes de cambio de ID del sistema. Espere a que aparezcan los segundos mensajes de reinicio:
Successfully restored env file from boot media... Rebooting to load the restored env file...
-
En LOADER, compruebe dos veces los valores bootarg y actualice los valores según sea necesario.
Utilice los pasos de "Configuración de las variables bootarg IP de MetroCluster".
-
Compruebe que la sísid del compañero es la correcta:
printenv partner-sysidSi el sid del socio no es correcto, configúrelo:
setenv partner-sysid partner-sysID -
Si se utiliza el cifrado de raíz, seleccione de nuevo la opción de menú de inicio para la configuración de administración de claves.
Si está usando…
Seleccione esta opción del menú de inicio…
Gestión de claves incorporada
Opción
10Siga las instrucciones para proporcionar las entradas necesarias para recuperar y restaurar la configuración de Key-Manager.
Gestión de claves externas
Opción «'11»
Siga las instrucciones para proporcionar las entradas necesarias para recuperar y restaurar la configuración de Key-Manager.
En función del ajuste del gestor de claves, realice el procedimiento de recuperación seleccionando la opción «'10'» o la opción «'11'», seguida de la opción
6en el primer símbolo del sistema del menú de inicio. Para arrancar los nodos por completo, puede que necesite repetir el procedimiento de recuperación seguido de la opción «'1'» (arranque normal). -
Espere a que los nodos sustituidos se inicien.
Si alguno de los nodos está en modo de toma de control, realice una devolución mediante el
storage failover givebackcomando. -
Si se utiliza el cifrado, restaure las claves con el comando correcto para la configuración de gestión de claves.
Si está usando…
Se usa este comando…
Gestión de claves incorporada
security key-manager onboard syncPara obtener más información, consulte "Restauración de las claves de cifrado de gestión de claves incorporadas".
Gestión de claves externas
`security key-manager external restore -vserver SVM -node node -key-server _host_name
-
Verifique que todos los puertos estén en un dominio de retransmisión:
-
Vea los dominios de retransmisión:
network port broadcast-domain show -
Añada cualquier puerto a un dominio de retransmisión según sea necesario.
-
Vuelva a crear las VLAN y los grupos de interfaces según sea necesario.
La pertenencia a la VLAN y al grupo de interfaces puede ser diferente de la del nodo antiguo.
-
Verificación y restauración de la configuración de LIF
Confirmar que las LIF se alojan en los nodos y puertos adecuados, según lo asignado al principio del procedimiento de actualización.
-
Esta tarea se realiza en el sitio_B.
-
Consulte el plan de asignación de puertos que ha creado en "Asignando los puertos de los nodos antiguos a los nodos nuevos".
-
Verifique que los LIF se alojan en el nodo y los puertos apropiados antes de regresar.
-
Cambie al nivel de privilegio avanzado:
set -privilege advanced -
Anule la configuración de puertos para garantizar una ubicación correcta de las LIF:
vserver config override -command "network interface modify -vserver vserver_name -home-port active_port_after_upgrade -lif lif_name -home-node new_node_name"
Al introducir el comando de modificación de la interfaz de red dentro del
vserver config overrideno se puede utilizar la función de tabulación automática. Puede crear la redinterface modifycon la opción de autocompletar y, a continuación, escríbala en lavserver config overridecomando.-
Vuelva al nivel de privilegio de administrador:
set -privilege admin
-
-
Revierte las interfaces a su nodo de inicio:
network interface revert * -vserver vserver-nameRealice este paso en todas las SVM según sea necesario.
Volver a cambiar la configuración de MetroCluster
En esta tarea, podrá llevar a cabo la operación de conmutación de estado, y la configuración de MetroCluster volverá al funcionamiento normal. Los nodos en site_A siguen esperando una actualización.
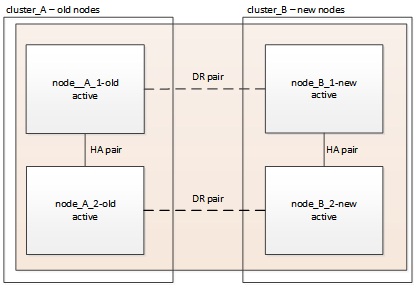
-
Emita el
metrocluster node showComando en site_B y compruebe la salida.-
Compruebe que los nodos nuevos se representen correctamente.
-
Verifique que los nuevos nodos estén en "esperando el estado de conmutación de estado".
-
-
Lleve a cabo la reparación y la conmutación de estado; para ello, ejecute los comandos necesarios desde cualquier nodo del clúster activo (el clúster no está sometido a actualización).
-
Reparar los agregados de datos:
metrocluster heal aggregates -
Reparar los agregados raíz:
metrocluster heal root -
Regreso al clúster:
metrocluster switchback
-
-
Compruebe el progreso de la operación de regreso:
metrocluster showLa operación de conmutación de estado aún está en curso cuando se muestra el resultado
waiting-for-switchback:cluster_B::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode switchover AUSO Failure Domain - Remote: cluster_A Configuration state configured Mode waiting-for-switchback AUSO Failure Domain -La operación de conmutación de estado se completa cuando el resultado muestra normal:
cluster_B::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode normal AUSO Failure Domain - Remote: cluster_A Configuration state configured Mode normal AUSO Failure Domain -Si una conmutación de regreso tarda mucho tiempo en terminar, puede comprobar el estado de las líneas base en curso utilizando el
metrocluster config-replication resync-status showcomando. Este comando se encuentra en el nivel de privilegio avanzado.
Comprobar el estado de la configuración de MetroCluster
Después de actualizar los módulos de controladora, debe verificar el estado de la configuración de MetroCluster.
Esta tarea se puede realizar en cualquier nodo de la configuración de MetroCluster.
-
Compruebe el funcionamiento de la configuración de MetroCluster:
-
Confirme la configuración del MetroCluster y que el modo operativo es normal:
metrocluster show -
Realice una comprobación de MetroCluster:
metrocluster check run -
Mostrar los resultados de la comprobación de MetroCluster:
metrocluster check show
-
-
Compruebe el estado y la conectividad de MetroCluster.
-
Compruebe las conexiones IP de MetroCluster:
storage iscsi-initiator show -
Compruebe que los nodos están funcionando:
metrocluster node show -
Compruebe que las interfaces IP de MetroCluster estén en funcionamiento:
metrocluster configuration-settings interface show -
Compruebe que la conmutación por error local está activada:
storage failover show
-
Actualizar los nodos en cluster_A
Debe repetir las tareas de actualización en cluster_A.
-
Repita los pasos para actualizar los nodos en cluster_A, empezando por "Preparando la actualización".
Al realizar las tareas, se revierten todas las referencias de ejemplo a los clústeres y los nodos. Por ejemplo, cuando se dé el ejemplo para cambiar de cluster_A, se cambiará de cluster_B.
Restaurar la supervisión de tiebreaker o de Mediator
Después de completar la actualización de la configuración de MetroCluster, puede reanudar la supervisión con tiebreaker o la utilidad Mediator.
-
Restaure la supervisión si es necesario, siguiendo el procedimiento para su configuración.
Si está usando… Utilice este procedimiento Tiebreaker
Mediador
Link:../install-ip/concept_mediator_requirements.html [Configuración del servicio Mediador ONTAP desde una configuración IP de MetroCluster].
Aplicaciones de terceros
Consulte la documentación del producto.
Envío de un mensaje de AutoSupport personalizado tras el mantenimiento
Después de completar la actualización, debe enviar un mensaje de AutoSupport que indique el fin del mantenimiento para que se pueda reanudar la creación automática de casos.
-
Para reanudar la generación automática de casos de soporte, envíe un mensaje de AutoSupport para indicar que se ha completado el mantenimiento.
-
Emita el siguiente comando:
system node autosupport invoke -node * -type all -message MAINT=end -
Repita el comando en el clúster de partners.
-
Configurar el cifrado integral
Si es compatible con su sistema, puede cifrar el tráfico de back-end, como NVlog y los datos de replicación de almacenamiento, entre los sitios IP de MetroCluster. Consulte "Configurar el cifrado integral" si quiere más información.