

Overview SAP HANA high availability
 Suggest changes
Suggest changes
This chapter provides an overview of high availability options for SAP HANA comparing replication on application layer with storage replication.
SAP HANA system replication (HSR)
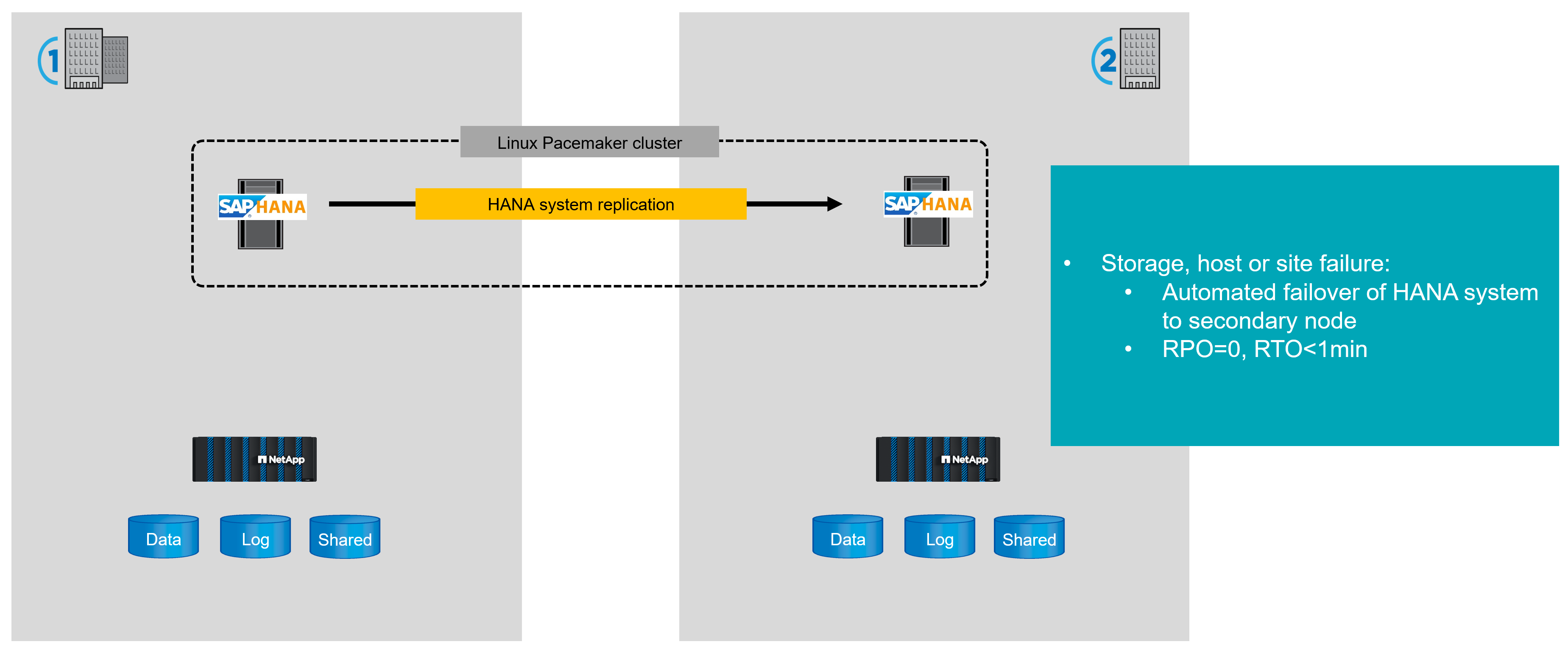
SAP HANA system replication offers an operation mode in which the data is replicated synchronously, preloaded into memory and continuously updated at the secondary host. This mode enables very low RTO values, approximately 1 minute or less, but it also requires a dedicated server that is only used to receive the replication data from the source system. Because of the low failover time, SAP HANA system replication is also often used for near-zero-downtime maintenance operations, such as HANA software upgrades. Linux Pacemaker cluster solutions are typically used to automate failover operations.
In case of any failure at the primary site, storage, host or complete site, the HANA system automatically fails over to the secondary site controlled by the Linux Pacemaker cluster.
For a full description of all configuration options and replication scenarios, see SAP HANA System Replication | SAP Help Portal.
NetApp SnapMirror active sync
SnapMirror active sync enables business services to continue operating even through a complete site failure, supporting applications to fail over transparently using a secondary copy. There is no manual intervention or custom scripting required to trigger a failover with SnapMirror active sync. SnapMirror active sync is supported on AFF clusters, All-Flash SAN Array (ASA) clusters, and C-Series (AFF or ASA). SnapMirror active sync protects applications with iSCSI or FCP LUNs.
Beginning with ONTAP 9.15.1, SnapMirror active sync supports a symmetric active/active capability. Symmetric active/active enable read and write I/O operations from both copies of a protected LUN with bidirectional synchronous replication so that both LUN copies can serve I/O operations locally.
More details can be found at SnapMirror active sync overview in ONTAP.
HANA bare metal
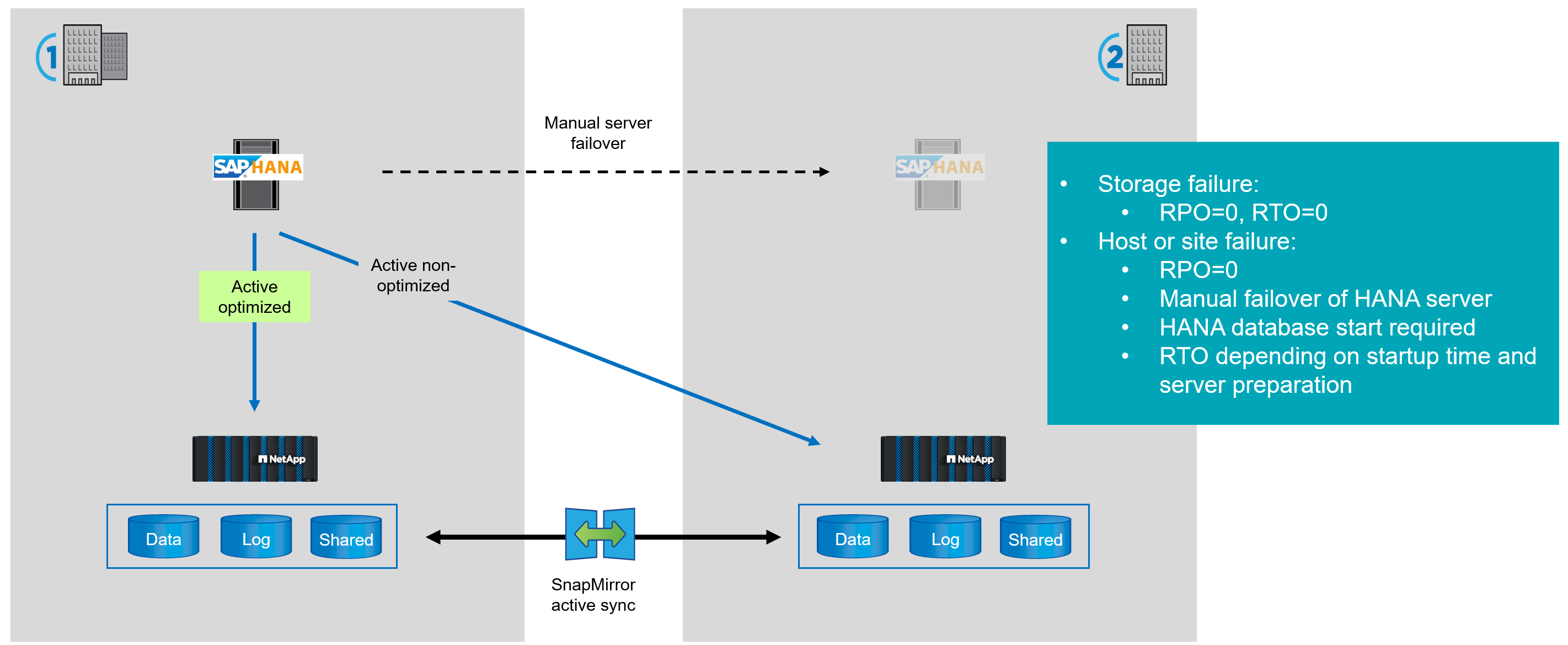
When running SAP HANA on a bare metal server, you can use SnapMirror active sync to provide a high available storage solution. The data is replicated synchronously therefore providing an RPO=0.
In case of a storage failure, the HANA system will transparently access the mirrored copy at the secondary site using the second FCP path providing an RTO=0.
In case of a host or complete site failure, a new server at the secondary site needs to be provided to access the data from the failed host. This would typically be a test or QA system of the same size as production which will now be shut down and be used to run the production system. After the LUNs at the secondary site are connected to the new host, the HANA database needs to be started. The total RTO therefore depends on the time needed to provision the host and the startup time of the HANA database.
vSphere Metro Storage Cluster (vMSC)
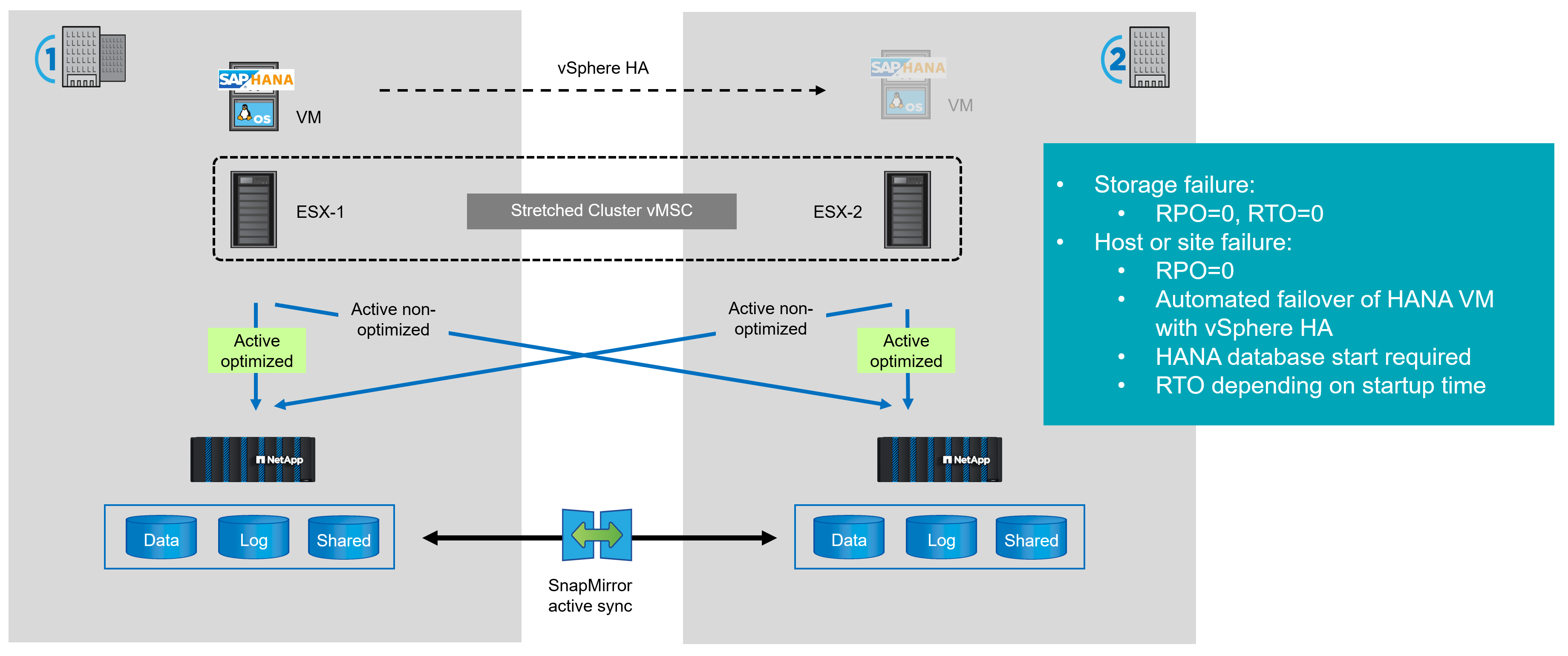
When running SAP HANA in a VMware environment using FCP attached datastores you can use SnapMirror active sync to build a VMware Metro Storage Cluster. In such a setup the datastores used by the HANA system are replicated synchronously to the secondary site.
In case of a storage failure, the ESX host will automatically access the mirrored copy at the secondary site providing an RTO=0.
In case of a host or complete site failure, vSphere HA is used to start the HANA VM at the secondary ESX host. When the HANA VM is running, the HANA database needs to be started. The total RTO therefore mainly depends on the startup time of the HANA database.
Solution comparison
The following table provides a summary of the key characteristics of the solutions described above.
| HANA System Replication | SnapMirror active sync – bare metal | SnapMirror active sync – Vmware vMSC | |
|---|---|---|---|
RPO with any failure |
RPO=0 |
||
RTO with storage failure |
RTO < 1min |
RTO=0 |
|
RTO |
RTO < 1min |
RTO: Depending on the time required for server preparation and HANA database startup. |
RTO: Depending on the time required for HANA database startup. |
Failover automation |
Yes, automated failover to secondary HSR host controlled by pacemaker cluster. |
Yes, for storage failure No, for host or site failure (Provisioning of host, connect storage resources, HANA database start) |
Yes, for storage failure Yes, for host or site failure (Failover of VM to other site automated with vSphere HA, HANA database start) |
Dedicated server at secondary site required |
Yes, required to preload data into memory and enable fast failover w/o database startup. |
No, server is only required in case of failover. Typically, the server used for QA would then be used for production. |
No, Resources at ESX host are only required in case of a failover. Typically, QA resources would then be used for production. |