

Solution verification overview
 Suggest changes
Suggest changes
In this section, we have executed SQL test queries from multiple sources to verify the functionality, test and verify the spillover to NetApp storage.
SQL query on Object storage
-
Set the memory to 250GB per server in dremio.env
root@hadoopmaster:~# for i in hadoopmaster hadoopnode1 hadoopnode2 hadoopnode3 hadoopnode4; do ssh $i "hostname; grep -i DREMIO_MAX_MEMORY_SIZE_MB /opt/dremio/conf/dremio-env; cat /proc/meminfo | grep -i memtotal"; done hadoopmaster #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515760 kB hadoopnode1 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515860 kB hadoopnode2 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515864 kB hadoopnode3 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 264004556 kB node4 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515484 kB root@hadoopmaster:~#
-
Check the spill over location (${DREMIO_HOME}"/dremiocache) in dremio.conf file and storage details.
paths: { # the local path for dremio to store data. local: ${DREMIO_HOME}"/dremiocache" # the distributed path Dremio data including job results, downloads, uploads, etc #dist: "hdfs://hadoopmaster:9000/dremiocache" dist: "dremioS3:///dremioconf" } services: { coordinator.enabled: true, coordinator.master.enabled: true, executor.enabled: false, flight.use_session_service: false } zookeeper: "10.63.150.130:2181,10.63.150.153:2181,10.63.150.151:2181" services.coordinator.master.embedded-zookeeper.enabled: false -
Point the Dremio spill over location to NetApp NFS storage
root@hadoopnode1:~# ls -ltrh /dremiocache total 4.0K drwx------ 3 nobody nogroup 4.0K Sep 13 16:00 spilling_stlrx2540m4-12-10g_45678 root@hadoopnode1:~# ls -ltrh /opt/dremio/dremiocache/ total 8.0K drwxr-xr-x 3 dremio dremio 4.0K Aug 22 18:19 spill_old drwxr-xr-x 4 dremio dremio 4.0K Aug 22 18:19 cm lrwxrwxrwx 1 root root 12 Aug 22 19:03 spill -> /dremiocache root@hadoopnode1:~# ls -ltrh /dremiocache total 4.0K drwx------ 3 nobody nogroup 4.0K Sep 13 16:00 spilling_stlrx2540m4-12-10g_45678 root@hadoopnode1:~# df -h /dremiocache Filesystem Size Used Avail Use% Mounted on 10.63.150.159:/dremiocache_hadoopnode1 2.1T 209M 2.0T 1% /dremiocache root@hadoopnode1:~#
-
Select the context. In our test, we ran the test against TPCDS generated parquet files residing in ONTAP S3. Dremio Dashboard → SQL runner → context → NetAppONTAPS3→Parquet1TB
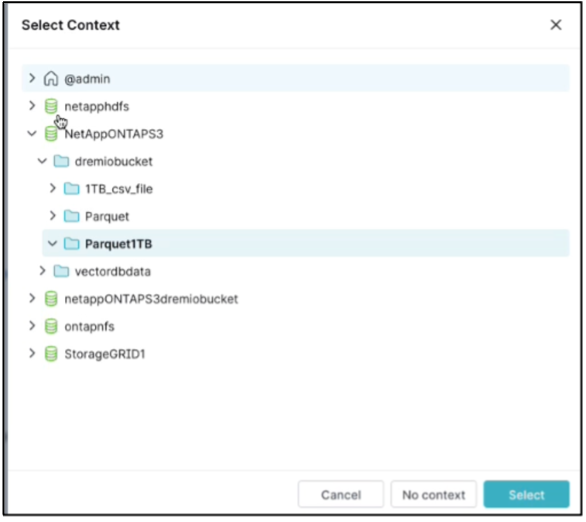
-
Run the TPC-DS query67 from the Dremio dashboard

-
Check that the job is running on all executor. Dremio dashboard → jobs → <jobid> → raw profile → select EXTERNAL_SORT → Hostname
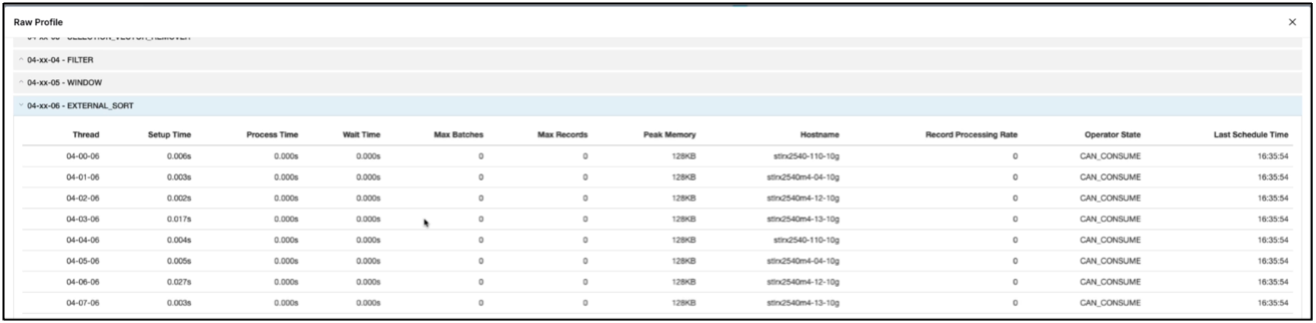
-
When the SQL query running, you can check the split folder for data caching in NetApp storage controller.
root@hadoopnode1:~# ls -ltrh /dremiocache total 4.0K drwx------ 3 nobody nogroup 4.0K Sep 13 16:00 spilling_stlrx2540m4-12-10g_45678 root@hadoopnode1:~# ls -ltrh /dremiocache/spilling_stlrx2540m4-12-10g_45678/ total 4.0K drwxr-xr-x 2 root daemon 4.0K Sep 13 16:23 1726243167416
-
The SQL query completed with spill over

-
Job completion summary.
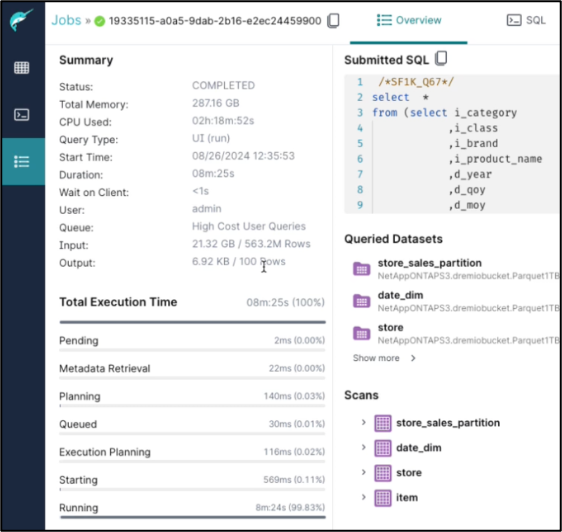
-
Check the spilled data size
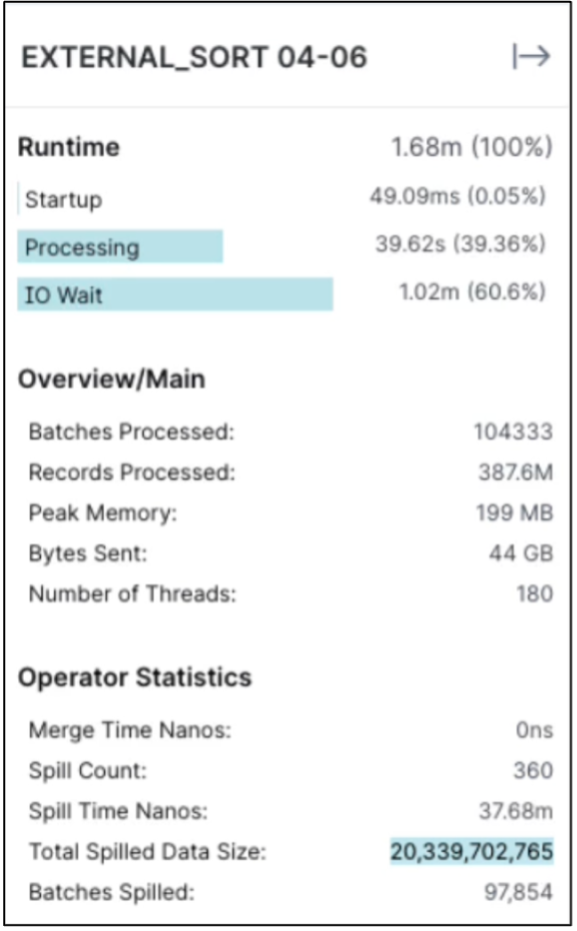
The same procedure applicable for NAS and StorageGRID Object storage.