

Performance event analysis and notification
 Suggest changes
Suggest changes
Performance events notify you about I/O performance issues on a volume workload caused by contention on a cluster component. Unified Manager analyzes the event to identify all workloads involved, the component in contention, and whether the event is still an issue that you might need to resolve.
Unified Manager monitors the I/O latency (response time) and IOPS (operations) for volumes on a cluster. When other workloads overuse a cluster component, for example, the component is in contention and cannot perform at an optimal level to meet workload demands. The performance of other workloads that are using the same component might be impacted, causing their latencies to increase. If the latency crosses the performance threshold, Unified Manager triggers a performance event and sends an email alert to notify you.
Event analysis
Unified Manager performs the following analyses, using the previous 15 days of performance statistics, to identify the victim workloads, bully workloads, and the cluster component involved in an event:
-
Identifies victim workloads whose latency has crossed the performance threshold, which is the upper boundary of the expected range:
-
For volumes on HDD or Flash Pool (hybrid) aggregates, events are triggered only when the latency is greater than 5 milliseconds (ms) and the IOPS are more than 10 operations per second (ops/sec).
-
For volumes on all-SSD aggregates or FabricPool (composite) aggregates, events are triggered only when the latency is greater than 1 ms and the IOPS are more than 100 ops/sec.
-
-
Identifies the cluster component in contention.

If the latency of victim workloads at the cluster interconnect is greater than 1 ms, Unified Manager treats this as significant and triggers an event for the cluster interconnect.
-
Identifies the bully workloads that are overusing the cluster component and causing it to be in contention.
-
Ranks the workloads involved, based on their deviation in utilization or activity of a cluster component, to determine which bullies have the highest change in usage of the cluster component and which victims are the most impacted.
An event might occur for only a brief moment and then correct itself after the component it is using is no longer in contention. A continuous event is one that reoccurs for the same cluster component within a five-minute interval and remains in the active state. For continuous events, Unified Manager triggers an alert after detecting the same event during two consecutive analysis intervals. Events that remain unresolved, which have a state of new, can display different description messages as workloads involved in the event change.
When an event is resolved, it remains available in Unified Manager as part of the record of past performance issues for a volume. Each event has a unique ID that identifies the event type and the volumes, cluster, and cluster components involved.
|
|
A single volume can be involved in more than one event at the same time. |
Event state
Events can be in one of the following states:
-
Active
Indicates that the performance event is currently active (new or acknowledged). The issue causing the event has not corrected itself or has not been resolved. The performance counter for the storage object remains above the performance threshold.
-
Obsolete
Indicates that the event is no longer active. The issue causing the event has corrected itself or has been resolved. The performance counter for the storage object is no longer above the performance threshold.
Event notification
The event alerts are displayed on the Dashboards/Overview page, Dashboards/Performance page, Performance/Volume Details page, and they are sent to specified email addresses. You can view detailed analysis information about an event and get suggestions for resolving it on the Event details page.
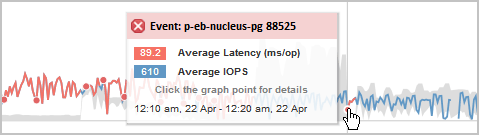
In this example, an event is indicated by a red dot (![]() ) on the Latency chart on the Performance/Volume Details page. Hovering your mouse cursor over the red dot displays a popup with more details about the event and options for analyzing it.
) on the Latency chart on the Performance/Volume Details page. Hovering your mouse cursor over the red dot displays a popup with more details about the event and options for analyzing it.
Event interaction
On the Performance/Volume Details page, you can interact with events in the following ways:
-
Moving the pointer over a red dot displays a message that shows the event ID, along with the latency, number of operations per second, and the date and time when the event was detected.
If there are multiple events for the same time period, the message shows the number of events, along with the average latency and operations per second for the volume.
-
Clicking a single event displays a dialog box that shows more detailed information about the event, including the cluster components that are involved, similar to the Summary section on the Event details page.
The component in contention is circled and highlighted red. You can click either the event ID or View full analysis to view the full analysis on the Event details page. If there are multiple events for the same time period, the dialog box shows details about the three most recent events. You can click an event ID to view the event analysis on the Event details page. If there are more than three events for the same time period, clicking the red dot does not display the dialog box.