

查看节点页面
 建议更改
建议更改
如果您需要比信息板提供的信息更详细的 StorageGRID 系统信息,则可以使用节点页面查看整个网格,网格中的每个站点以及站点上的每个节点的指标。
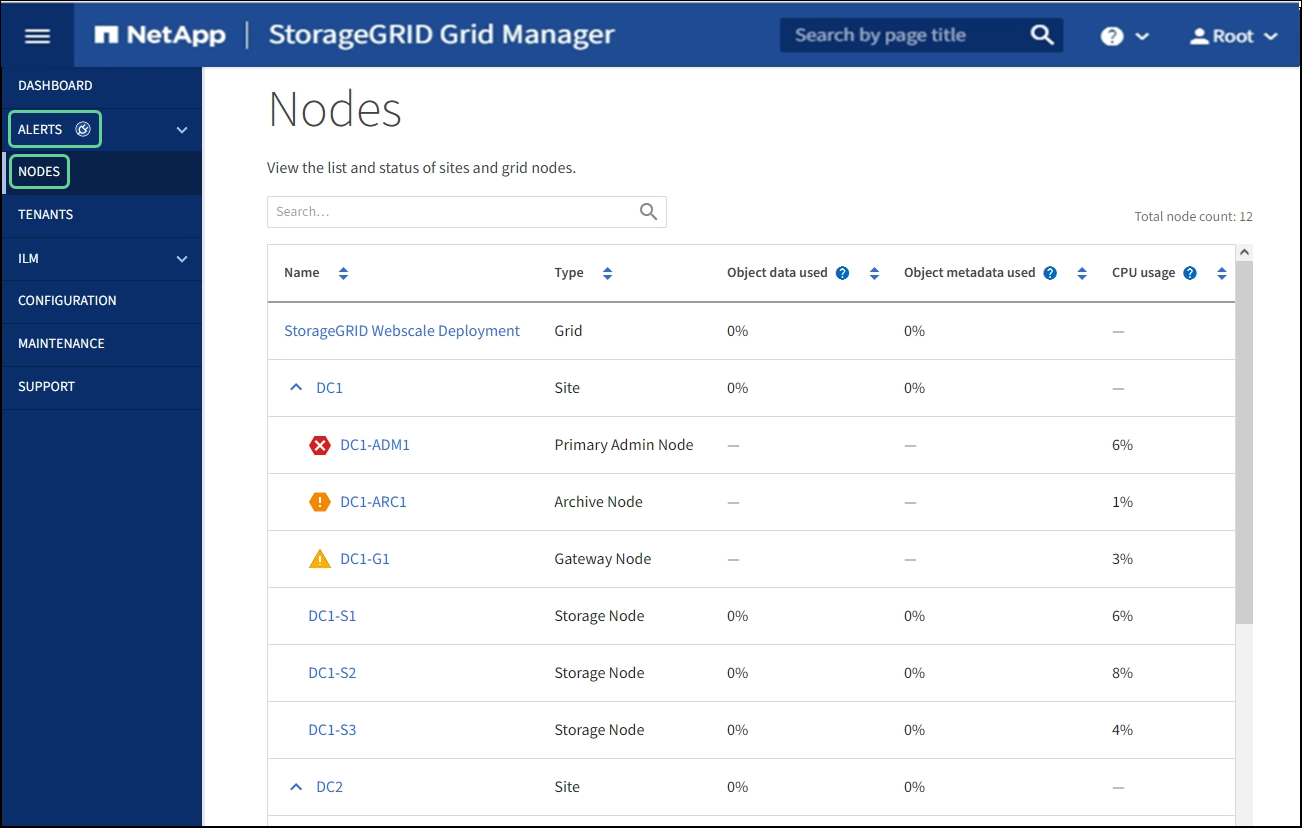
节点表列出了 StorageGRID 系统中的所有站点和节点。系统将显示每个节点的摘要信息。如果节点具有活动警报,则节点名称旁边会显示一个图标。如果节点已连接且没有活动警报,则不会显示任何图标。
连接状态图标
-
* 未连接 - 未知 *
 :节点未连接到网格,原因未知。例如,节点之间的网络连接已断开或电源已关闭。此外,可能还会触发 * 无法与节点 * 通信 " 警报。其他警报可能也处于活动状态。这种情况需要立即引起关注。
:节点未连接到网格,原因未知。例如,节点之间的网络连接已断开或电源已关闭。此外,可能还会触发 * 无法与节点 * 通信 " 警报。其他警报可能也处于活动状态。这种情况需要立即引起关注。
在受管关闭操作期间,节点可能会显示为未知。在这些情况下,您可以忽略未知状态。 -
* 未连接 - 已管理员关闭 *
 :由于预期原因,节点未连接到网格。例如,节点或节点上的服务已正常关闭,节点正在重新启动或软件正在升级。一个或多个警报可能也处于活动状态。
:由于预期原因,节点未连接到网格。例如,节点或节点上的服务已正常关闭,节点正在重新启动或软件正在升级。一个或多个警报可能也处于活动状态。
如果节点与网格断开连接,则可能存在底层警报,但仅会显示 "`Not connected` " 图标。要查看节点的活动警报,请选择节点。
警报图标
如果节点存在活动警报,则节点名称旁边会显示以下图标之一:
-
* 严重 *
 :存在已停止 StorageGRID 节点或服务正常运行的异常情况。您必须立即解决底层问题描述 。如果未解决问题描述 ,可能会导致服务中断和数据丢失。
:存在已停止 StorageGRID 节点或服务正常运行的异常情况。您必须立即解决底层问题描述 。如果未解决问题描述 ,可能会导致服务中断和数据丢失。 -
* 主要 *
 :存在影响当前操作或接近严重警报阈值的异常情况。您应调查主要警报并解决任何根本问题,以确保异常情况不会停止 StorageGRID 节点或服务的正常运行。
:存在影响当前操作或接近严重警报阈值的异常情况。您应调查主要警报并解决任何根本问题,以确保异常情况不会停止 StorageGRID 节点或服务的正常运行。 -
* 次要 *
 :系统运行正常,但存在异常情况,如果系统继续运行,可能会影响系统的运行能力。您应监控和解决自身未清除的小警报,以确保它们不会导致更严重的问题。
:系统运行正常,但存在异常情况,如果系统继续运行,可能会影响系统的运行能力。您应监控和解决自身未清除的小警报,以确保它们不会导致更严重的问题。
系统,站点或节点的详细信息
要查看可用信息,请按如下所示选择网格,站点或节点的名称:
-
选择网格名称可查看整个 StorageGRID 系统统计信息的聚合摘要。(屏幕截图显示了一个名为 StorageGRID 部署的系统。)
-
选择一个特定的数据中心站点,以查看该站点上所有节点的统计信息的聚合摘要。
-
选择一个特定节点以查看该节点的详细信息。
节点页面的选项卡
节点页面顶部的选项卡取决于您从左侧树中选择的内容。
| 选项卡名称 | Description | 包括的 |
|---|---|---|
概述 |
|
所有节点 |
硬件 |
|
所有节点 |
网络 |
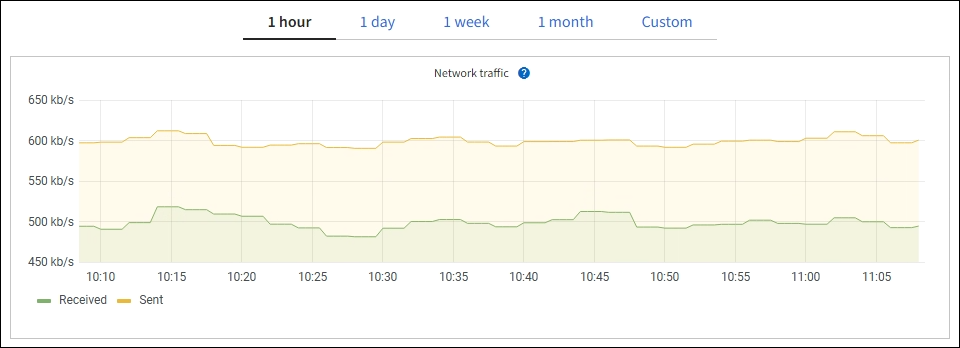
显示一个图形,其中显示了通过网络接口接收和发送的网络流量。单个节点的视图显示该节点的追加信息 。 |
所有节点,每个站点和整个网格 |
存储 |
|
所有节点,每个站点和整个网格 |
对象 |
|
存储节点,每个站点和整个网格 |
ILM |
提供有关信息生命周期管理( ILM )操作的信息。
|
存储节点,每个站点和整个网格 |
负载平衡器 |
包括与负载平衡器服务相关的性能和诊断图。
|
管理节点和网关节点,每个站点和整个网格 |
平台服务 |
提供有关站点上任何 S3 平台服务操作的信息。 |
每个站点 |
SANtricity 系统管理器 |
提供对 SANtricity System Manager 的访问权限。在 SANtricity System Manager 中,您可以查看存储控制器的硬件诊断和环境信息以及与驱动器相关的问题。 |
存储设备节点 注:如果存储设备上的控制器固件早于8.70 (11.70)、则不会显示SANtricity 系统管理器选项卡。 |
Prometheus 指标
管理节点上的 Prometheus 服务从所有节点上的服务收集时间序列指标。
Prometheus 收集的指标会在网格管理器的许多位置使用:
-
* 节点页面 * :节点页面上提供的选项卡上的图形和图表使用 Grafana 可视化工具显示 Prometheus 收集的时间序列指标。Grafana 以图形和图表格式显示时间序列数据,而 Prometheus 用作后端数据源。
-
* 警报 * :如果使用 Prometheus 指标的警报规则条件评估为 true ,则会在特定严重性级别触发警报。
-
* 网格管理 APi* :您可以在自定义警报规则中使用 Prometheus 指标,也可以使用外部自动化工具来监控 StorageGRID 系统。有关完整的 Prometheus 指标列表,请访问网格管理 API 。(从网格管理器的顶部,选择帮助图标并选择 * API Documentation* > * 指标 * 。) 虽然有 1000 多个指标可用,但监控最关键的 StorageGRID 操作只需要相对较少的指标。
名称中包含 private 的指标仅供内部使用,在 StorageGRID 版本之间可能会发生更改,恕不另行通知。 -
* 支持 * > * 工具 * > * 诊断 * 页面和 * 支持 * > * 工具 * > * 指标 * 页面:这些页面主要供技术支持使用,提供了许多工具和图表,这些工具和图表使用了 Prometheus 指标的值。
指标页面中的某些功能和菜单项有意不起作用,可能会发生更改。
StorageGRID 属性
属性可报告 StorageGRID 系统许多功能的值和状态。每个网格节点,每个站点和整个网格均可使用属性值。
StorageGRID 属性在网格管理器中的许多位置使用:
-
* 节点页面 * :节点页面上显示的许多值都是 StorageGRID 属性。( Prometheus 指标也显示在节点页面上。)
-
* 警报 * :当属性达到定义的阈值时, StorageGRID 警报(原有系统)将在特定严重性级别触发。
-
* 网格拓扑树 * :属性值显示在网格拓扑树中( * 支持 * > * 工具 * > * 网格拓扑 * )。
-
* 事件 * :当某些属性记录节点的错误或故障情况时,发生系统事件,包括网络错误等错误。
属性值
属性会尽力报告,并且大致正确。在某些情况下,属性更新可能会丢失,例如服务崩溃或网格节点故障和重建。
此外,传播延迟可能会减慢属性报告的速度。大多数属性的更新值会按固定间隔发送到 StorageGRID 系统。更新可能需要几分钟才能在系统中显示出来,并且可以在稍不同的时间报告同时更改的两个属性。