

Recovering from a multi-controller or storage failure
 Suggest changes
Suggest changes
If the controller failure extends to all controller modules on one side of a DR group in a MetroCluster configuration (including a single controller in a two-node MetroCluster configuration), or storage has been replaced, you must replace the equipment and reassign ownership of drives to recover from the disaster.
Verify that you have checked and performed the following tasks before using this procedure:
-
Review the available recovery procedures before deciding to use this procedure.
-
Confirm that console logging is enabled on your devices.
-
Ensure that the disaster site is fenced off.
-
Verify that switchover was performed.
-
Verify that the replacement drives and the controller modules are new and must not have been assigned ownership previously.
-
The examples in this procedure show two or four-node configurations. If you have an eight-node configuration (two DR groups), you must take into account any failures and perform the required recovery task on the additional controller modules.
This procedure uses the following workflow:
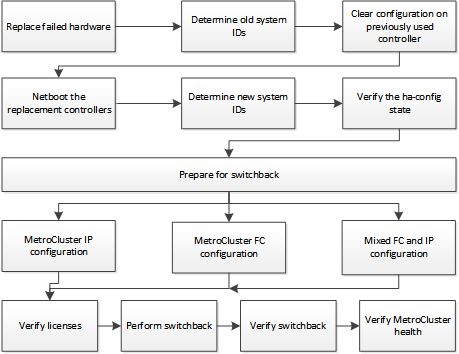
This procedure can be used when performing recovery on a system that was in mid-transition when the failure occurred. In that case, you must perform the appropriate steps when preparing for switchback, as indicated in the procedure.