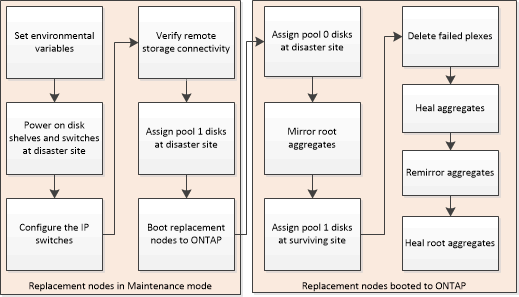
Prepare for switchback in a MetroCluster IP configuration
Contributors





 Suggest changes
Suggest changes
You must perform certain tasks in order to prepare the MetroCluster IP configuration for the switchback operation.
About this task