

High-availability pairs
 Suggest changes
Suggest changes
Cluster nodes are configured in high-availability (HA) pairs for fault tolerance and nondisruptive operations. If a node fails or if you need to bring a node down for routine maintenance, its partner can take over its storage and continue to serve data from it. The partner gives back storage when the node is brought back on line.
HA pairs always consist of like controller models. The controllers typically reside in the same chassis with redundant power supplies.
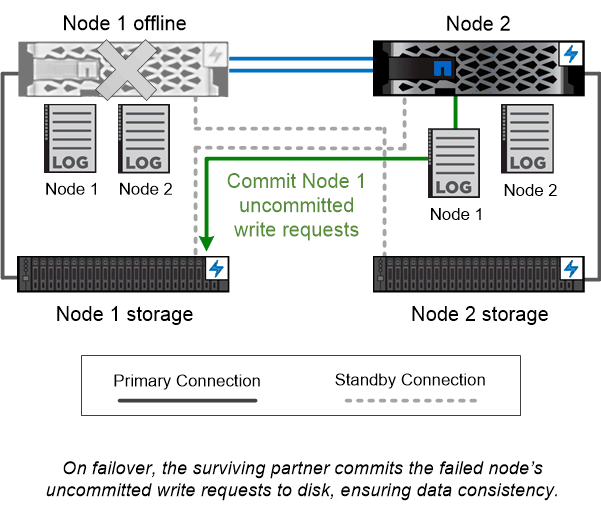
The HA pairs are fault tolerant nodes that can communicate with each other in different ways to allow each node to continually check whether its partner is functioning and to mirror log data for the other's nonvolatile memory. When a write request is made to a node, it is logged in NVRAM on both nodes before a response is sent back to the client or host. On failover, the surviving partner commits the failed node's uncommitted write requests to disk, ensuring data consistency. The surviving node continues logging the writes into the NVRAM partition, which previously acted as the mirror of the failed Node's NVRAM.
Connections to the other controller's storage media allow each node to access the other's storage in the event of a takeover. Network path failover mechanisms ensure that clients and hosts continue to communicate with the surviving node.
To assure availability, you should keep performance capacity utilization on either node at 50% to accommodate the additional workload in the failover case. For the same reason, you may want to configure no more than 50% of the maximum number of NAS virtual network interfaces for a node.
Takeover and giveback in virtualized ONTAP implementations Storage isn't shared between nodes in virtualized “shared-nothing” ONTAP implementations like ONTAP Select. When a node goes down, its partner continues to serve data from a synchronously mirrored copy of the node's data. It does not take over the node's storage, only its data serving function. |