

プラットフォームサービスのトラブルシューティングを行う
 変更を提案
変更を提案
プラットフォームサービスで使用されるエンドポイントは、テナントユーザが Tenant Manager で作成および管理します。ただし、テナントでプラットフォームサービスの設定または使用に関する問題がテナントで発生した場合は、グリッドマネージャを使用して問題 を解決できる可能性があります。
新しいエンドポイントに関する問題
テナントでプラットフォームサービスを使用するには、 Tenant Manager を使用してエンドポイントを 1 つ以上作成する必要があります。各エンドポイントは、 StorageGRID S3 バケット、 Amazon Web Services バケット、 Simple Notification Service トピック、ローカルまたは AWS でホストされる Elasticsearch クラスタなど、 1 つのプラットフォームサービスの外部のデスティネーションを表します。各エンドポイントには、外部リソースの場所と、そのリソースへのアクセスに必要なクレデンシャルが含まれます。
テナントでエンドポイントを作成すると、 StorageGRID システムによって、そのエンドポイントが存在するかどうかと、指定されたクレデンシャルでアクセスできるかどうかが検証されます。エンドポイントへの接続は、各サイトの 1 つのノードから検証されます。
エンドポイントの検証が失敗した場合は、その理由を記載したエラーメッセージが表示されます。テナントユーザは、問題 を解決してから、エンドポイントの作成をもう一度実行する必要があります。

|
テナントアカウントでプラットフォームサービスが有効でない場合は、エンドポイントの作成が失敗します。 |
既存のエンドポイントに関する問題
StorageGRID が既存のエンドポイントにアクセスしようとしたときにエラーが発生した場合は、テナントマネージャのダッシュボードにメッセージが表示されます。

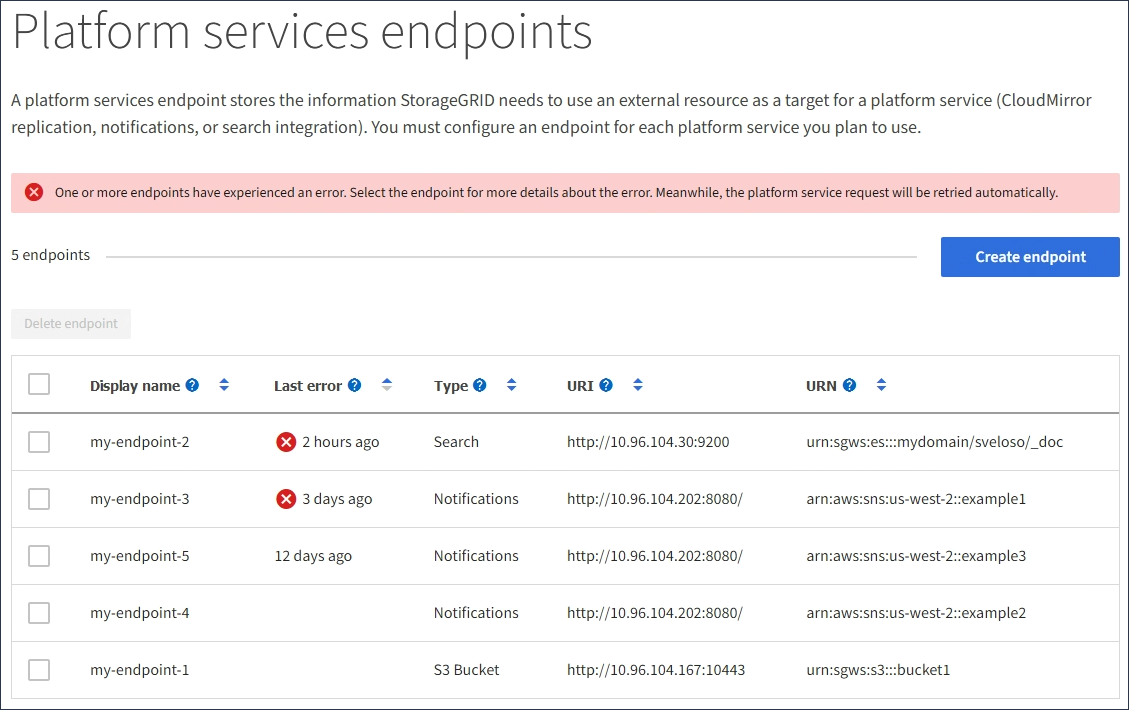
テナントユーザは、エンドポイントページに移動して各エンドポイントの最新のエラーメッセージを確認し、エラーが発生してからの時間を特定できます。[* Last error*] 列には、各エンドポイントの最新のエラーメッセージとエラーが発生してからの経過時間が表示されます。が含まれるエラーです ![]() アイコンは過去 7 日以内に発生しました。
アイコンは過去 7 日以内に発生しました。
|
|
「 * Last error * 」列の一部のエラーメッセージには、かっこ内にログ ID が含まれている場合があります。グリッド管理者やテクニカルサポートは、この ID を使用して、 bycast.log のエラーに関する詳細情報を確認できます。 |
プロキシサーバに関連する問題
ストレージノードとプラットフォームサービスエンドポイントの間にストレージプロキシを設定している場合、プロキシサービスで StorageGRID からのメッセージが許可されていないとエラーが発生する可能性があります。これらの問題を解決するには、プロキシサーバの設定を調べて、プラットフォームサービス関連のメッセージがブロックされていないことを確認してください。
エラーが発生したかどうかを確認します
過去 7 日間にエンドポイントエラーが発生した場合は、 Tenant Manager のダッシュボードにアラートメッセージが表示されます。エラーの詳細を確認するには、エンドポイントのページに移動します。
クライアント処理が失敗する
一部のプラットフォームサービスの問題により、 S3 バケットに対する原因 クライアント処理が失敗することがあります。たとえば、内部の Replicated State Machine ( RSM )サービスが停止した場合や、配信のためにキューに登録されたプラットフォームサービスメッセージが多すぎる場合は、 S3 クライアント処理が失敗します。
サービスのステータスを確認するには、次の手順に従います。
-
サポート * > * ツール * > * グリッドトポロジ * を選択します。
-
[site *>*_Storage Node>*SSM*>*Services] を選択します。
リカバリ可能なエンドポイントエラーとリカバリ不能なエンドポイントエラー
エンドポイントの作成後に、さまざまな理由からプラットフォームサービス要求のエラーが発生することがあります。一部のエラーは、ユーザが対処することでリカバリできます。たとえば、リカバリ可能なエラーは次のような原因で発生する可能性があります。
-
ユーザのクレデンシャルが削除されたか、期限切れになっています。
-
デスティネーションバケットが存在しません。
-
通知を配信できません。
StorageGRID でリカバリ可能なエラーが発生した場合は、成功するまでプラットフォームサービス要求が再試行されます。
その他のエラーはリカバリできません。たとえば、エンドポイントが削除されるとリカバリ不能なエラーが発生します。
StorageGRID でリカバリ不能なエンドポイントのエラーが発生すると、 Grid Manager で Total Events ( SMTT )のレガシーアラームが生成されます。Total Events レガシーアラームを表示するには、次の手順を実行します
-
サポート * > * ツール * > * グリッドトポロジ * を選択します。
-
_site * > * _node_name > * SSM * > * Events * を選択します。
-
表の一番上に Last Event が表示されます。
イベント・メッセージは /var/local/log/bycast-err.log にも表示されます
-
SMTT アラームに記載されている指示に従って問題 を修正します。
-
イベントカウントをリセットするには、 * Configuration * タブを選択します。
-
プラットフォームサービスメッセージが配信されていないオブジェクトについてテナントに通知します。
-
テナントで、オブジェクトのメタデータまたはタグを更新することで、失敗したレプリケーションまたは通知を再度トリガーするよう指定します。
テナントでは、既存の値を再送信し、不要な変更を回避できます。
プラットフォームサービスメッセージを配信できません
デスティネーションでプラットフォームサービスメッセージの受信を妨げる問題 が検出された場合、バケットに対する処理は成功しますが、プラットフォームサービスメッセージは配信されません。たとえば、デスティネーションでクレデンシャルが更新されたため StorageGRID がデスティネーションサービスを認証できなくなった場合に、このエラーが発生することがあります。
リカバリ不能なエラーによってプラットフォームサービスメッセージを配信できない場合は、 Grid Manager で Total Events ( SMTT )のレガシーアラームが生成されます。
プラットフォームサービス要求のパフォーマンスが低下します
要求が送信されるペースがデスティネーションエンドポイントで要求を受信できるペースを超えると、 StorageGRID ソフトウェアはバケットの受信 S3 要求を調整する場合があります。スロットルは、デスティネーションエンドポイントへの送信を待機している要求のバックログが生じている場合にのみ発生します。
明らかな影響は、受信 S3 要求の実行時間が長くなることだけです。パフォーマンスが大幅に低下していることが検出されるようになった場合は、取り込み速度を下げるか、容量の大きいエンドポイントを使用する必要があります。要求のバックログが増え続けると、クライアント S3 処理( PUT 要求など)が失敗します。
通常、 CloudMirror 要求には、検索統合やイベント通知の要求よりも多くのデータ転送が含まれるため、デスティネーションエンドポイントのパフォーマンスによる影響を受ける可能性が高くなります。
プラットフォームサービス要求が失敗しました
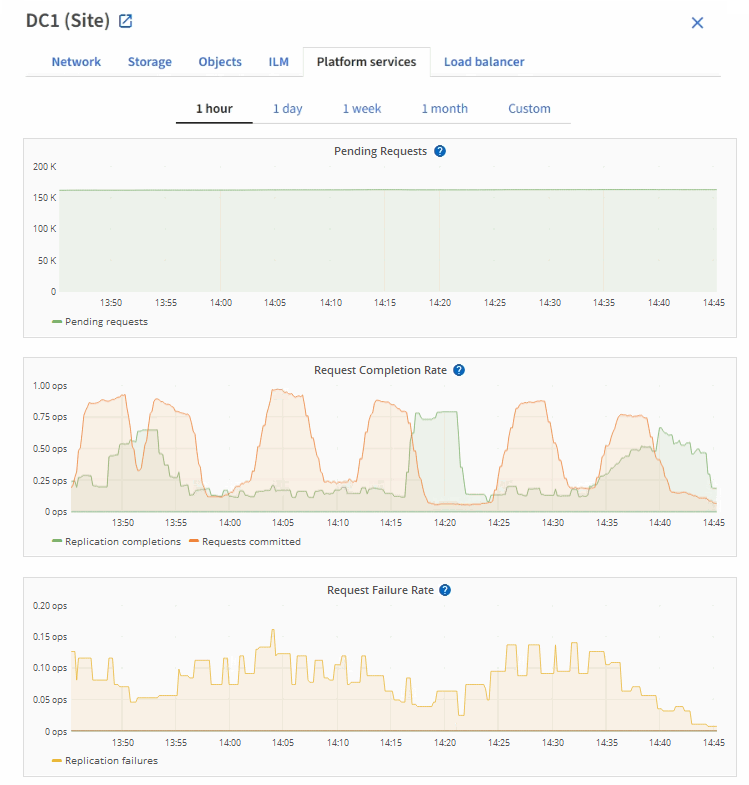
プラットフォームサービスの要求の失敗率を表示するには、次の手順を実行します。
-
[* nodes (ノード) ] を選択します
-
[_site *>*Platform Services] を選択します。
-
エラー率のリクエストチャートを表示します。
Platform services unavailable アラート
「 * Platform services unavailable * 」アラートは、実行中または使用可能な RSM サービスがあるストレージノードが少なすぎるために、サイトでプラットフォームサービスの処理を実行できないことを示しています。
RSM サービスは、プラットフォームサービス要求がそれぞれのエンドポイントに確実に送信されるようにします。
このアラートを解決するには、サイトのどのストレージノードに RSM サービスが含まれているかを特定します( RSM サービスは、 ADC サービスがあるストレージノードにあります)。 そのあと、それらのストレージノードの過半数が稼働していて使用可能であることを確認します。
|
|
RSM サービスを含む複数のストレージノードでサイトで障害が発生すると、そのサイトに対する保留中のプラットフォームサービス要求はすべて失われます。 |
プラットフォームサービスエンドポイントに関するその他のトラブルシューティングガイダンス
プラットフォームサービスエンドポイントのトラブルシューティングに関する追加情報 の手順については、を参照してください テナントアカウントを使用する。