

アプライアンスストレージボリュームの再マウントと再フォーマット(「手動手順」)
 変更を提案
変更を提案
2 つのスクリプトを手動で実行して、保持されているストレージボリュームを再マウントし、障害ストレージボリュームを再フォーマットする必要があります。最初のスクリプトは、 StorageGRID ストレージボリュームとして適切にフォーマットされているボリュームを再マウントします。2 番目のスクリプトは、マウントされていないボリュームを再フォーマットし、必要に応じて Cassandra データベースを再構築して、サービスを開始します。
-
障害が発生したストレージボリュームのうち、必要と判断した場合はハードウェアを交換しておく必要があります。
sn-remount-volumes スクリプトを実行すると ' さらに障害が発生したストレージ・ボリュームを特定するのに役立ちます
-
ストレージノードの運用停止処理が進行中でないこと、またはノードの手順 の運用停止処理が一時停止されていることを確認しておきます( Grid Manager で、 * maintenance * > * Tasks * > * Decommission * を選択します)。
-
拡張が進行中でないことを確認しておきます( Grid Manager で、 * maintenance * > * Tasks * > * Expansion * を選択します。)

|
複数のストレージノードがオフラインの場合、またはこのグリッド内のストレージノードが過去 15 日以内に再構築されている場合は、テクニカルサポートにお問い合わせください。sn-recovery-postinstall.sh スクリプトは実行しないでください15 日以内に複数のストレージノードで Cassandra を再構築すると、データが失われることがあります。 |
この手順 を完了するには、次の作業を行います。
-
リカバリされたストレージノードにログインします。
-
sn-remount-volumes スクリプトを実行して ' 適切にフォーマットされたストレージ・ボリュームを再マウントしますこのスクリプトを実行すると、次の処理が行われます。
-
各ストレージボリュームをマウントしてアンマウントし、 XFS ジャーナルをリプレイします。
-
XFS ファイルの整合性チェックを実行します。
-
ファイルシステムに整合性がある場合は、ストレージボリュームが適切にフォーマットされた StorageGRID ストレージボリュームであるかどうかを確認します。
-
ストレージボリュームが適切にフォーマットされている場合は、ストレージボリュームを再マウントします。ボリューム上の既存のデータはそのまま維持されます。
-
-
スクリプトの出力を確認し、問題を解決します。
-
sn-recovery-postinstall.sh スクリプトを実行しますこのスクリプトを実行すると、次の処理が実行されます。

リカバリ中にストレージ・ノードを再起動しないでください再フォーマットして ' 障害ストレージ・ボリュームをリストアするために 'sn-recovery-postinstall.sh (手順 4 )を実行する前に ' そのストレージ・ノードを再起動しないでくださいsn-recovery-postinstall.sh が完了する前にストレージ・ノードをリブートすると ' サービスの開始を試み StorageGRID アプライアンス・ノードが保守モードを終了するようになるエラーが発生します -
sn-remount-volumes スクリプトがマウントできなかったストレージ・ボリューム ' または適切にフォーマットされなかったストレージ・ボリュームを再フォーマットします

ストレージボリュームを再フォーマットすると、そのボリューム上のデータはすべて失われます。複数のオブジェクトコピーを格納するように ILM ルールが設定されている場合は、グリッド内の他の場所からオブジェクトデータをリストアするために追加の手順 を実行する必要があります。 -
必要に応じて、ノードの Cassandra データベースを再構築します。
-
ストレージノードのサービスを開始します。
-
-
リカバリしたストレージノードにログインします。
-
次のコマンドを入力します。 ssh admin@_grid_node_name
-
「 passwords.txt 」ファイルに記載されたパスワードを入力します。
-
root に切り替えるには、次のコマンドを入力します
-
「 passwords.txt 」ファイルに記載されたパスワードを入力します。
root としてログインすると、プロンプトは「 $` 」から「 #」 に変わります。
-
-
最初のスクリプトを実行し、適切にフォーマットされたストレージボリュームを再マウントします。
すべてのストレージボリュームが新規でフォーマットが必要な場合、またはすべてのストレージボリュームで障害が発生した場合は、この手順を省略して 2 つ目のスクリプトを実行し、マウントされていないストレージボリュームをすべて再フォーマットします。 -
スクリプト「 sn-remount-volumes 」を実行します
データが格納されたストレージボリュームでこのスクリプトを実行すると、数時間かかることがあります。
-
スクリプトの実行時に、出力と回答 のプロンプトを確認します。
必要に応じて 'tail -f コマンドを使用して ' スクリプトのログ・ファイルの内容を監視できます (/var/local/log/sn-remount-volumes .log')ログファイルには、コマンドラインの出力よりも詳細な情報が含まれています。 root@SG:~ # sn-remount-volumes The configured LDR noid is 12632740 ====== Device /dev/sdb ====== Mount and unmount device /dev/sdb and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sdb: Mount device /dev/sdb to /tmp/sdb-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12632740, volume number 0 in the volID file Attempting to remount /dev/sdb Device /dev/sdb remounted successfully ====== Device /dev/sdc ====== Mount and unmount device /dev/sdc and checking file system consistency: Error: File system consistency check retry failed on device /dev/sdc. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID Webscale will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policy. Do not continue to the next step if you believe that the data remaining on this volume cannot be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sdd ====== Mount and unmount device /dev/sdd and checking file system consistency: Failed to mount device /dev/sdd This device could be an uninitialized disk or has corrupted superblock. File system check might take a long time. Do you want to continue? (y or n) [y/N]? y Error: File system consistency check retry failed on device /dev/sdd. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID Webscale will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policy. Do not continue to the next step if you believe that the data remaining on this volume cannot be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sde ====== Mount and unmount device /dev/sde and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sde: Mount device /dev/sde to /tmp/sde-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12000078, volume number 9 in the volID file Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
この出力例では、 1 つのストレージボリュームが正常に再マウントされ、 3 つのストレージボリュームでエラーが発生しています。
-
/dev/sdb は、 XFS ファイルシステムの整合性チェックに合格し、ボリューム構造が有効なため、正常に再マウントされました。スクリプトによって再マウントされたデバイスのデータは保持されています。
-
/dev/sdc は ' ストレージ・ボリュームが新規または破損していたため 'XFS ファイル・システムの整合性チェックに失敗しました
-
ディスクが初期化されていないか ' ディスクのスーパーブロックが破損しているため '/dev/sdd をマウントできませんでしたスクリプトは、ストレージボリュームをマウントできない場合、ファイルシステムの整合性チェックを実行するかどうかを確認するメッセージを表示します。
-
ストレージ・ボリュームが新しいディスクに接続されている場合は、回答 * N * をプロンプトに表示します。新しいディスクのファイルシステムをチェックする必要はありません。
-
ストレージ・ボリュームが既存のディスクに接続されている場合は、回答 * Y * がプロンプトに表示されます。ファイルシステムのチェックの結果を使用して、破損の原因を特定できます。結果は /var/local/log/sn-remount-volumes .log ログファイルに保存されます
-
-
/dev/sde は XFS ファイル・システムの整合性チェックに合格し ' ボリューム構造が有効でしたが 'volid' ファイル内の LDR ノード ID が ' このストレージ・ノードの ID (最上部に表示される Configured LDR noid )と一致しませんでしたこのメッセージは、このボリュームが別のストレージノードに属していることを示しています。
-
-
-
スクリプトの出力を確認し、問題を解決します。
ストレージボリュームが XFS ファイルシステムの整合性チェックに合格できなかった場合、またはストレージボリュームをマウントできなかった場合は、出力のエラーメッセージをよく確認してください。これらのボリュームに対して sn-recovery-postinstall.sh スクリプトを実行した場合の影響を理解する必要があります -
想定しているすべてのボリュームのエントリが結果に含まれていることを確認します。表示されていないボリュームがある場合は、スクリプトを再実行します。
-
マウントされたすべてのデバイスのメッセージを確認します。ストレージボリュームがこのストレージノードに属していないことを示すエラーがないことを確認します。
この例では、 /dev/sde の出力に、次のエラーメッセージが含まれています。
Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
あるストレージボリュームが別のストレージノードに属していると報告される場合は、テクニカルサポートにお問い合わせください。sn-recovery-postinstall.sh スクリプトを実行すると、ストレージボリュームが再フォーマットされ、原因 データが失われる可能性があります。 -
マウントできなかったストレージデバイスがある場合は、デバイス名をメモし、デバイスを修理または交換します。
マウントできなかったストレージデバイスはすべて修理または交換する必要があります。 デバイス名を使用してボリューム ID を検索しますボリューム ID は 'repair-data' スクリプトを実行してオブジェクトデータをボリューム(次の手順 )にリストアするときに必要な入力です
-
マウントできないデバイスをすべて修復または交換したら 'sn-remount-volumes スクリプトを再度実行して ' 再マウントできるすべてのストレージ・ボリュームが再マウントされたことを確認します
ストレージボリュームをマウントできない場合、またはストレージボリュームが適切にフォーマットされなかった場合に次の手順に進むと、ボリュームとそのボリューム上のデータが削除されます。オブジェクトデータのコピーが 2 つあった場合、次の手順 (オブジェクトデータのリストア)が完了するまでコピーは 1 つだけになります。
障害が発生したストレージ・ボリュームに残っているデータをグリッド内の他の場所から再構築できないと考えられる場合は 'sn-recovery-postinstall.sh スクリプトを実行しないでください(たとえば 'ILM ポリシーでコピーを 1 つだけ作成するルールが使用されている場合や ' 複数のノードでボリュームに障害が発生した場合など)代わりに、テクニカルサポートに問い合わせてデータのリカバリ方法を確認してください。 -
-
sn-recovery-postinstall.sh スクリプトを実行します :sn-recovery-postinstall.sh
このスクリプトは、マウントできなかったストレージボリューム、または適切にフォーマットされていないストレージボリュームを再フォーマットし、必要に応じてノードの Cassandra データベースを再構築して、ストレージノードのサービスを開始します。
次の点に注意してください。
-
スクリプトの実行には数時間かかることがあります。
-
一般に、スクリプトの実行中は、 SSH セッションは単独で行う必要があります。
-
SSH セッションがアクティブになっている間は、 * Ctrl+C キーを押さないでください。
-
このスクリプトは、ネットワークの中断が発生して SSH セッションが終了した場合にバックグラウンドで実行されますが、進行状況はリカバリページで確認できます。
-
ストレージノードで RSM サービスを使用している場合は、ノードサービスの再起動時にスクリプトが 5 分間停止しているように見えることがあります。この 5 分間の遅延は、 RSM サービスが初めて起動するときに発生します。
RSM サービスは、 ADC サービスが含まれるストレージノードにあります。
一部の StorageGRID リカバリ手順では、 Reaper を使用して Cassandra の修復を処理します。関連サービスまたは必要なサービスが開始されるとすぐに修理が自動的に行われます。スクリプトの出力には、「 reaper 」または「 Cassandra repair 」が含まれていることがあります。 修復が失敗したことを示すエラーメッセージが表示された場合は、エラーメッセージに示されたコマンドを実行します。 -
-
sn-recovery-postinstall.sh スクリプトが実行されると 'Grid Manager の Recovery ページを監視します
Recovery ページの Progress バーと Stage カラムは 'sn-recovery-postinstall.sh スクリプトの高レベルのステータスを提供します
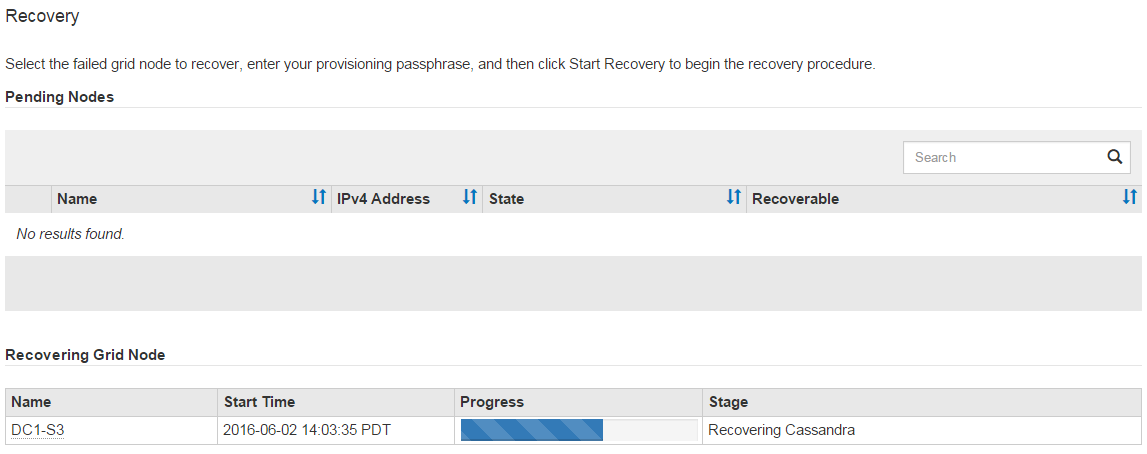
ノード上で sn-recovery-postinstall.sh スクリプトがサービスを開始したら、次の手順 で説明するように、スクリプトでフォーマットされたストレージボリュームにオブジェクトデータをリストアできます。